主要任务
1**)从退款表中提取退款成功数据,并将字典表的dic_name **维度退化到表中
2**)从订单表中提取退款成功订单数据**
3**)从退单表中提取退款成功的明细数据**
退款成功需求
思路分析
1**)设置 **ttl
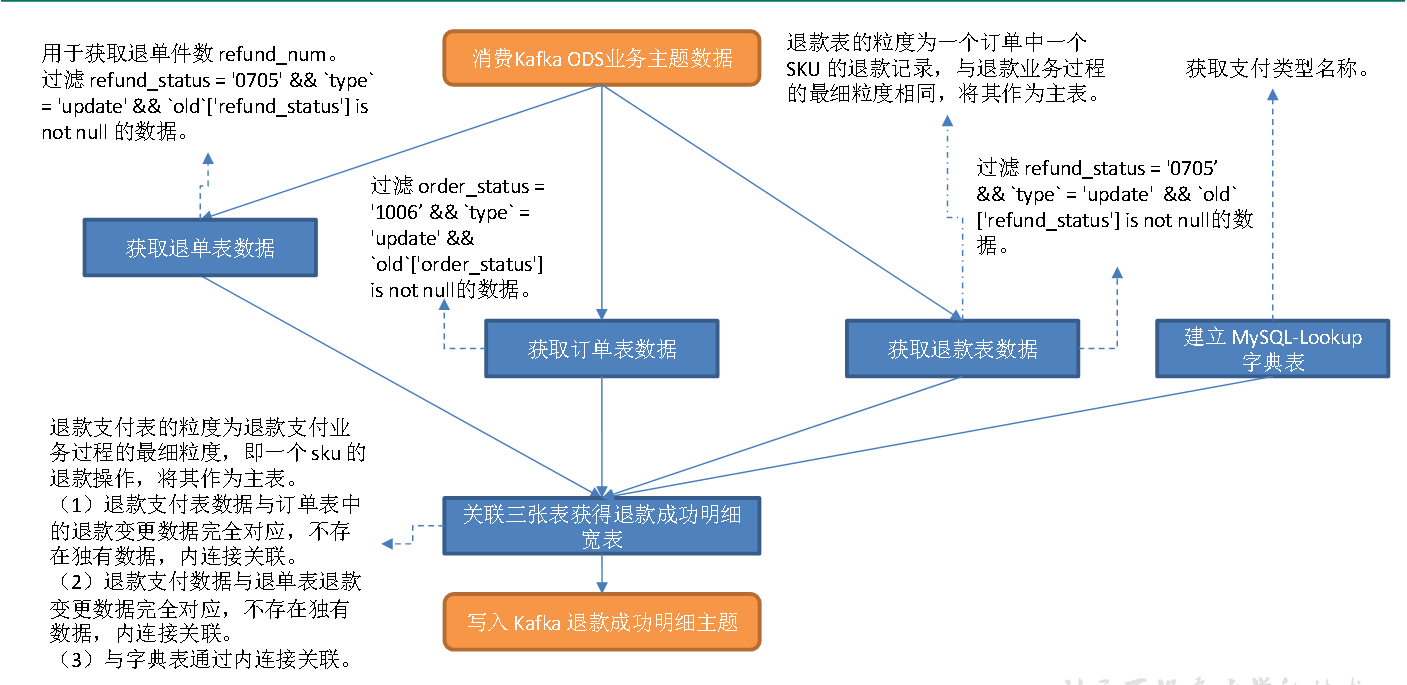
一次退款支付操作成功时,refund_payment 表会新增记录,订单表order_info 和退单表order_refund_info 的对应数据会发生修改,几张表之间不存在业务上的时间滞后。与字典表的关联分析同上,不再赘述。因而,仅考虑可能的数据乱序即可。将ttl 设置为5s。
1**)建立MySQL-Lookup **字典表
获取支付类型名称。
2**)读取退款表数据,筛选退款成功数据**
退款表refund_payment 的粒度为一个订单中一个SKU 的退款记录,与退款业务过程的最细粒度相同,将其作为**主表**。退款操作发生时,业务数据库的退款表会先插入一条数据,此时refund_status 状态码应为0701(商家审核中),callback_time 为null,而后经历一系列业务过程:商家审核、买家发货、退单完成。退单完成时会将状态码由 0701 更新为0705(退单完成),同时将callback_time 更新为退款支付成功的回调时间。由上述分析可知,退款成功记录应满足三个条件:(1)数据操作类型为 update;(2)refund_status 为0705;(3)修改的字段包含 refund_status。
3**)读取订单表数据,过滤退款成功订单数据**
用于获取user_id 和province_id。退款操作完后时,订单表的 order_status 字段会更新为1006(退款完成),因此退单成功对应的订单数据应满足三个条件:(1)操作类型为 update;
(2)order_status 为1006;(3)修改了 order_status 字段。
order_status 值更改为1006 之后对应的订单表数据就不会再发生变化,所以只要满足前两个条件,第三个条件必定满足。
4**)筛选退款成功的退单明细数据**
用于获取退单件数refund_num。退单成功时 order_refund_info 表中的refund_status 字段会修改为0705(退款成功状态码)。因此筛选条件有三:(1)操作类型为 update;(2)refund_status 为0705;(3)修改了refund_status 字段。筛选方式同上。
5**)关联四张表并写出到Kafka **退款成功主题
退款支付表的粒度为退款支付业务过程的最细粒度,即一个sku 的退款操作,将其作为主表。
(1)退款支付表数据与订单表中的退款变更数据完全对应,不存在独有数据,内连接关联。
(2)退款支付数据与退单表退款变更数据完全对应,不存在独有数据,内连接关联。
(3)与字典表通过内连接关联。
图解
代码编写
测试
创建 dwd_trade_refund_pay_suc 主题
bin/kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --create --replication-factor 1 --partitions 1 --topic dwd_trade_refund_pay_suc
消费 dwd_trade_refund_pay_suc主题
启动 DwdTradeRefundPaySuc 类
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic dwd_trade_refund_pay_suc
开始启动


若有收获,就点个赞吧
0 人点赞
