主要任务
提取加购操作生成加购表,并将字典表中的相关维度退化到加购表中,写出到Kafka 对应主题。
思路分析
1**)维度关联(维度退化)实现策略分析**
本章业务事实表的构建全部使用FlinkSQL 实现,字典表数据存储在MySQL 的业务数据库中,要做维度退化,就要将这些数据从MySQL 中提取出来封装成FlinkSQL 表,Flink 的JDBC SQL Connector 可以实现我们的需求。
2**)知识储备**
(1)JDBC SQL Connector
JDBC 连接器可以让Flink 程序从拥有JDBC 驱动的任意关系型数据库中读取数据或将数据写入数据库。
如果在Flink SQL 表的DDL 语句中定义了主键,则会以upsert 模式将流中数据写入数据库,此时流中可以存在UPDATE/DElETE(更新/删除)类型的数据。否则,会以 append 模式将数据写出到数据库,此时流中只能有INSERT(插入)类型的数据。
DDL 用法实例如下。
CREATE TABLE MyUserTable (id BIGINT,name STRING,age INT,status BOOLEAN,PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://localhost:3306/mydatabase','table-name' = 'users');
(2)Lookup Cache
JDBC 连接器可以作为时态表关联中的查询数据源(又称维表)。目前,仅支持同步查询模式。默认情况下,查询缓存(Lookup Cache)未被启用,需要设置 lookup.cache.max-rows 和lookup.cache.ttl 参数来启用此功能。Lookup 缓存是用来提升有JDBC 连接器参与的时态关联性能的。默认情况下,缓存未启用,所有的请求会被发送到外部数据库。当缓存启用时,每个进程(即TaskManager)维护一份缓存。收到请求时,Flink 会先查询缓存,如果缓存未命中才会向外部数据库发送请求,并用查询结果更新缓存。如果缓存中的记录条数达到了lookup.cache.max-rows 规定的最大行数时将清除存活时间最久的记录。如果缓存中的记录存活时间超过了lookup.cache.ttl 规定的最大存活时间,同样会被清除。缓存中的记录未必是最新的,可以将lookup.cache.ttl 设置为一个更小的值来获得时效性更好的数据,但这样做会增加发送到数据库的请求数量。所以需要在吞吐量和正确性之间寻求平衡。(3)Lookup JoinLookup Join 通常在Flink SQL 表和外部系统查询结果关联时使用。这种关联要求一张表(主表)有处理时间字段,而另一张表(维表)由Lookup 连接器生成。Lookup Join 做的是维度关联,而维度数据是有时效性的,那么我们就需要一个时间字段来对数据的版本进行标识。因此,Flink 要求我们提供处理时间用作版本字段。此处选择调用PROCTIME() 函数获取系统时间,将其作为处理时间字段。该函数调用示例如下
tableEnv.sqlQuery("select PROCTIME() proc_time").execute().print();// 结果+----+-------------------------+| op | proc_time |+----+-------------------------+| +I | 2022-04-09 15:45:50.752 |+----+-------------------------+1 row in set
(4)JDBC SQL Connector 参数解读
Ø connector:连接器类型,此处为jdbc
Ø url:数据库url
Ø table-name:数据库中表名
Ø lookup.cache.max-rows:lookup 缓存中的最大记录条数
Ø lookup.cache.ttl:lookup 缓存中每条记录的最大存活时间
Ø username:访问数据库的用户名
Ø password:访问数据库的密码
Ø driver:数据库驱动,注意:通常注册驱动可以省略,但是自动获取的驱动是com.mysql.jdbc.Driver,Flink CDC 2.1.0 要求mysql 驱动版本必须为8 及以上,在mysql-connector -8.x 中该驱动已过时,新的驱动为com.mysql.cj.jdbc.Driver。省略该参数控制台打印的警告如下
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'.The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
**(5)Kafka Connector
需要从Kafka 读取数据封装为Flink SQL 表,并将Flink SQL 表的数据写入Kafka,而整个过程的数据操作类型均为 INSERT,使用 Kafka Connector 即可。
Kafka Connector 参数如下
Ø connector:指定使用的连接器,对于 Kafka,只用 ‘kafka’
Ø topic:主题
Ø properties.bootstrap.servers:以逗号分隔的Kafka broker 列表。注意:可以通过properties. 的方式指定配置项,的位置用 Kafka 官方规定的配置项的key 替代。并不是所有的配置都可以通过这种方式配置,因为Flink 可能会将它们覆盖,如:’key.deserializer’ 和’value.deserializer’
Ø properties.group.id:消费者组ID
Ø format:指定Kafka 消息中value 部分的序列化的反序列化方式,’format’ 和’value.format’ 二者必有其一
Ø scan.startup.mode:Kafka 消费者启动模式,有四种取值
Ø ‘earliest-offset’:从偏移量最早的位置开始读取数据
Ø ‘latest-offset’:从偏移量最新的位置开始读取数据
Ø ‘group-offsets’:从Zookeeper/Kafka broker 中维护的消费者组偏移量开始读取数据
Ø ‘timestamp’:从用户为每个分区提供的时间戳开始读取数据
Ø ‘specific-offsets’:从用户为每个分区提供的偏移量开始读取数据
默认值为group-offsets。要注意:latest-offset 与Kafka 官方提供的配置项latest 不同,Flink 会将偏移量置为最新位置,覆盖掉Zookeeper 或Kafka 中维护的偏移量。与官方提供的latest 相对应的是此处的group-offsets。
3**)执行步骤**
(1)设置表状态的 ttl。ttl(time-to-live)即存活时间。表之间做普通关联时,底层会将两张表的数据维护到状态中,默认情况下状态永远不会清空,这样会对内存造成极大的压力。表状态的 ttl 是Idle(空闲,即状态未被更新)状态被保留的最短时间,假设 ttl 为10s,若状态中的数据在 10s 内未被更新,则未来的某个时间会被清除(故而ttl 是最短存活时间)。ttl 默认值为0,表示永远不会清空状态。字典表是作为维度表被Flink 程序维护的,字典表与加购表不存在业务上的滞后关系,而look up join 是由主表触发的,即主表数据到来后去look up 表中查询对应的维度信息,如果缓存未命中就要从外部介质中获取数据,这就要求主表数据在状态中等待一段时间,此处将ttl 设置为5s,主表数据会在状态中保存至少 5s。而 look up 表的cache 是由建表时指定的相关参数决定的,与此处的ttl 无关。
(2)读取购物车表数据。
(3)建立Mysql-LookUp 字典表。
(4)关联购物车表和字典表,维度退化。
图解
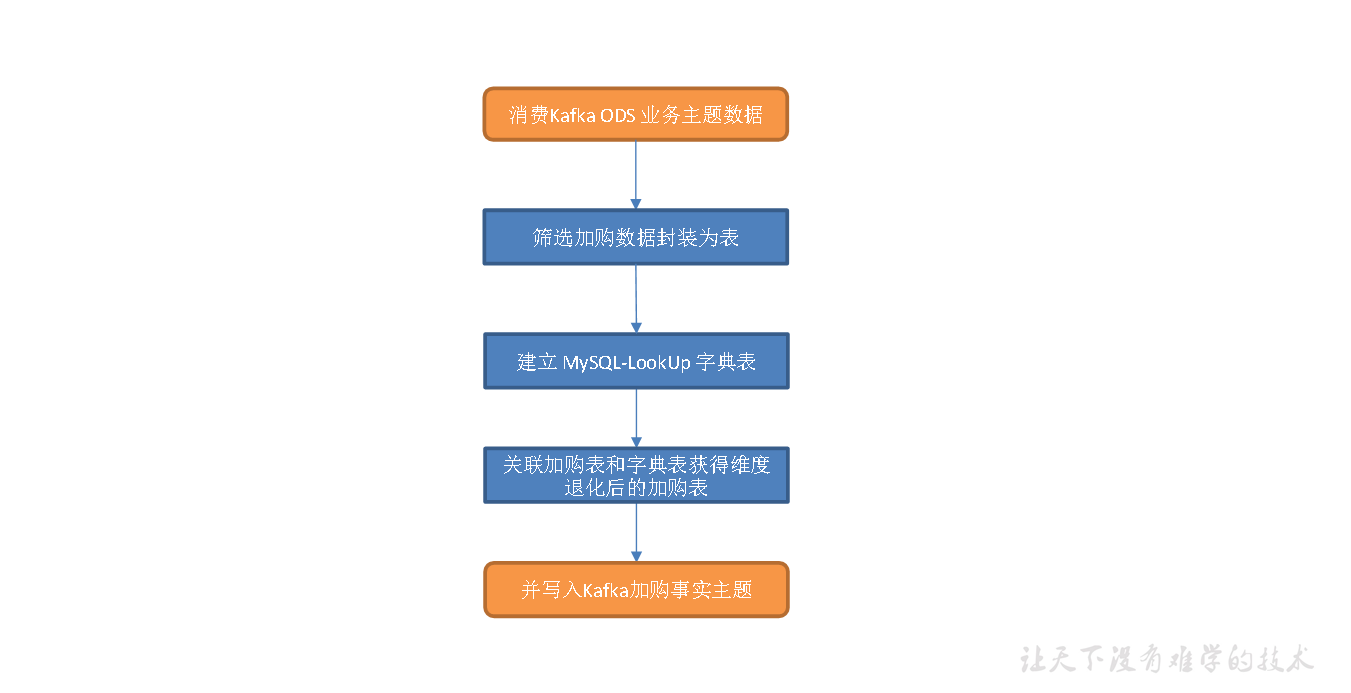
代码编写
1)补充 Flink SQL 相关依赖
要执行Flink SQL 程序,补充相关依赖。JDBC SQL Connector 需要的依赖包含在Flink CDC 需要的依赖中,不可重复引入。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_${scala.version}</artifactId><version>${flink.version}</version></dependency>
2)在KafkaUtil 中补充getKafkaDDL 方法和getKafkaSinkDDL 方法
3)创建 MysqlUtil 工具类
封装mysqlLookUpTableDDL() 方法和getBaesDicLookUpDDL() 方法,用于将MySQL 数据库中的字典表读取为Flink LookUp 表,以便维度退化。
4)主程序
测试代码
创建dwd_trade_cart_add 主题
bin/kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --create --replication-factor 1 --partitions 1 --topic dwd_trade_cart_add
消费dwd_trade_cart_add主题
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic dwd_trade_cart_add
启动 DwdTradeCartAdd 类
测试数据
在cart_info中添加数据
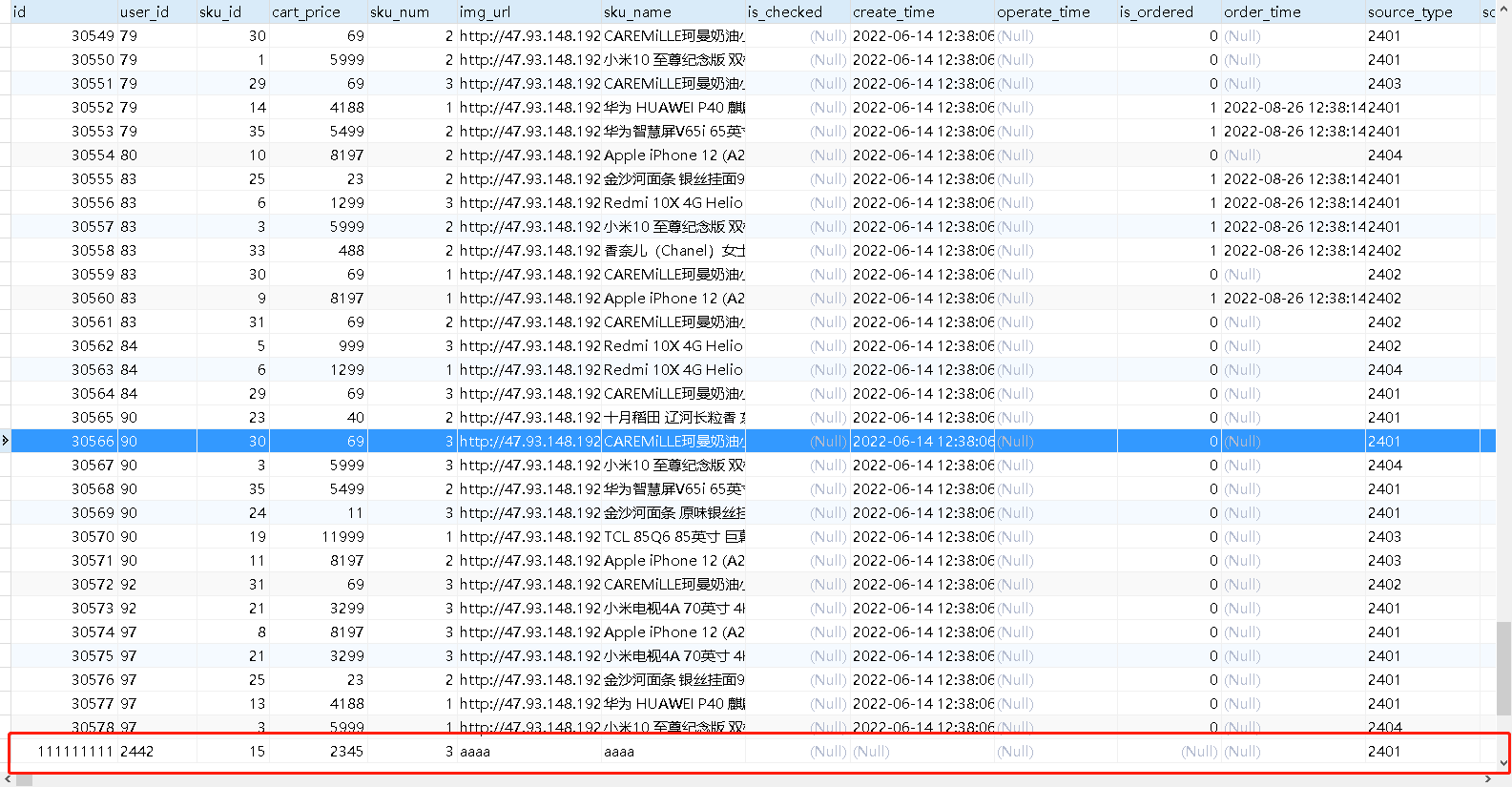
查看消费者

测试成功!

若有收获,就点个赞吧
0 人点赞
