创建执行环境
27行——44行
Kafka工具类封装
过滤脏数据
46——65行
配置表
本层的任务是将业务数据直接写入到不同的 HBase 表中。那么如何让程序知道流中的哪些数据是维度数据?维度数据又应该写到 HBase 的哪些表中?为了解决这个问题,我们选择在 MySQL 中构建一张配置表,通过 Flink CDC 将配置表信息读取到程序中。
配置表实体类
Flink CDC
https://blog.csdn.net/weixin_45417821/article/details/126465210
配置表设计
1**)字段解析**
我们将为配置表设计五个字段
Ø source_table:作为数据源的业务数据表名
Ø sink_table:作为数据目的地的 Phoenix 表名
Ø sink_columns:Phoenix 表字段
Ø sink_pk:Phoenix 表主键
Ø sink_extend:Phoenix 建表扩展,即建表时一些额外的配置语句
将 source_table 作为配置表的主键,可以通过它获取唯一的目标表名、字段、主键和建表扩展,从而得到完整的 Phoenix 建表语句。
2**)在Mysql中创建数据库建表并开启**Binlog
(1)创建数据库 gmall-config ,注意:和 gmall-flink 业务库区分开
[root@hadoop102 db_log]$ mysql -uroot -p000000 -e"create database gmall-config charset utf8 default collate utf8_general_ci"
(2)在gmall-config 库中创建配置表table_process
CREATE TABLE `table_process` (`source_table` varchar(200) NOT NULL COMMENT '来源表',`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表',`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',PRIMARY KEY (`source_table`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(3)在MySQL配置文件中增加gmall-config 开启Binlog
vim /etc/my.cnf
启用binlog的数据库,需根据实际情况作出修改
binlog-do-db=gmall-flink
binlog-do-db=gmall-config
重启MySQL :systemctl restart mysqld
校验:cd /var/lib/mysql ,查看最后一个文件,当前大小是154,下面我们做一个测试
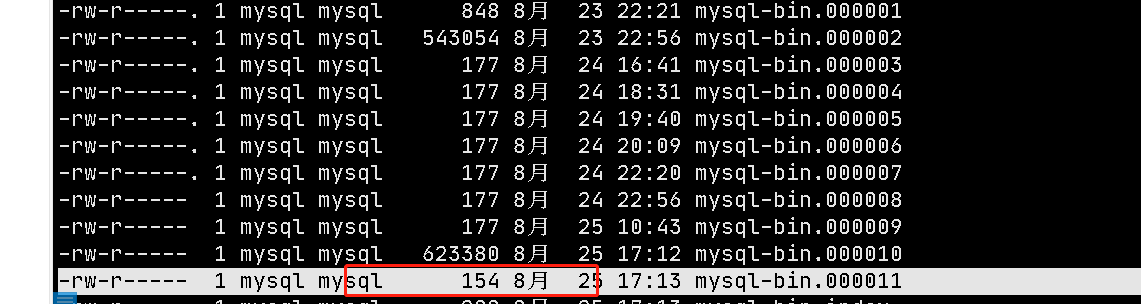
在table_process表中添加数据再次查看
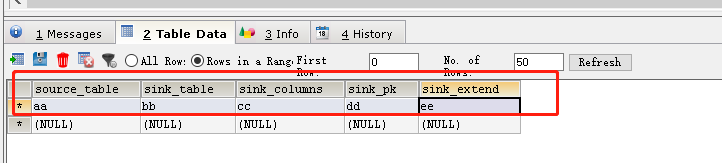

大小变了,说明校验成功。
配置表建表及数据导入 SQL 文件如下。
FlinkCDC读取配置信息
引入依赖
<!--Flink对接MySQL依赖--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.version}</artifactId><version>${flink.version}</version></dependency><!--Flink CDC 依赖--><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>2.1.0</version></dependency><!-- 如果不引入 flink-table 相关依赖,则会报错:Caused by: java.lang.ClassNotFoundException:org.apache.flink.connector.base.source.reader.RecordEmitter引入以下依赖可以解决这个问题(引入某些其它的 flink-table相关依赖也可)--><!--Flink Table 依赖--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.12</artifactId><version>1.13.0</version></dependency>
67行——79行
构建广播流与主流连接
81行——90行
连接流逻辑分析
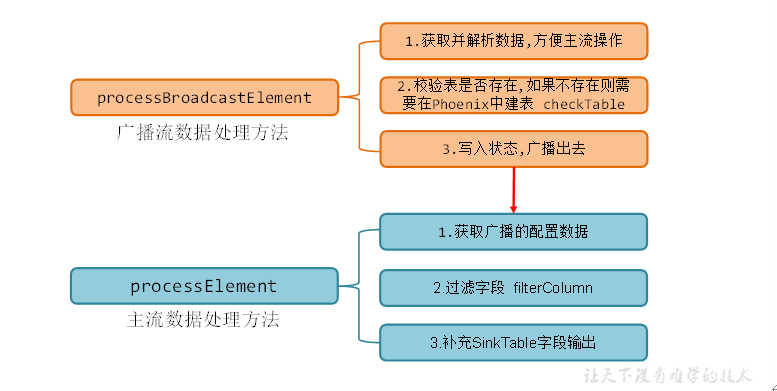
广播流和主流的底层逻辑
测试
测试前的准备工作
开启hdfs,zookeeper,hbase,kafka,maxwell(如果在此期间新建了个数据库,则删除重新创建MySQL中的maxwell库),phoenix等工作
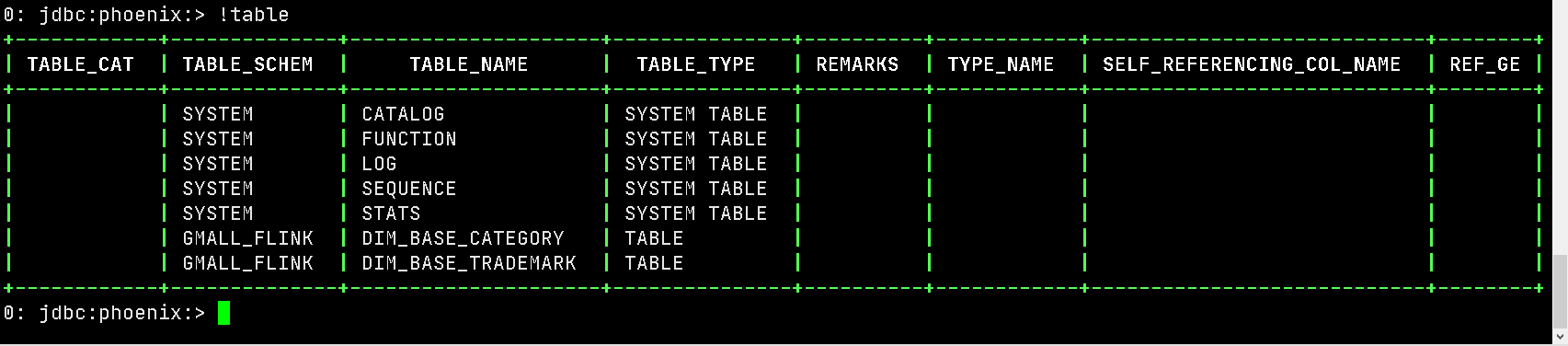
查看phoenix表:

在 gmall-config 库中的 table_process 表中添加如下数据

创建phoenix数据库 :create schema GMALL_FLINK;
注意:将97行注释
运行idea查看
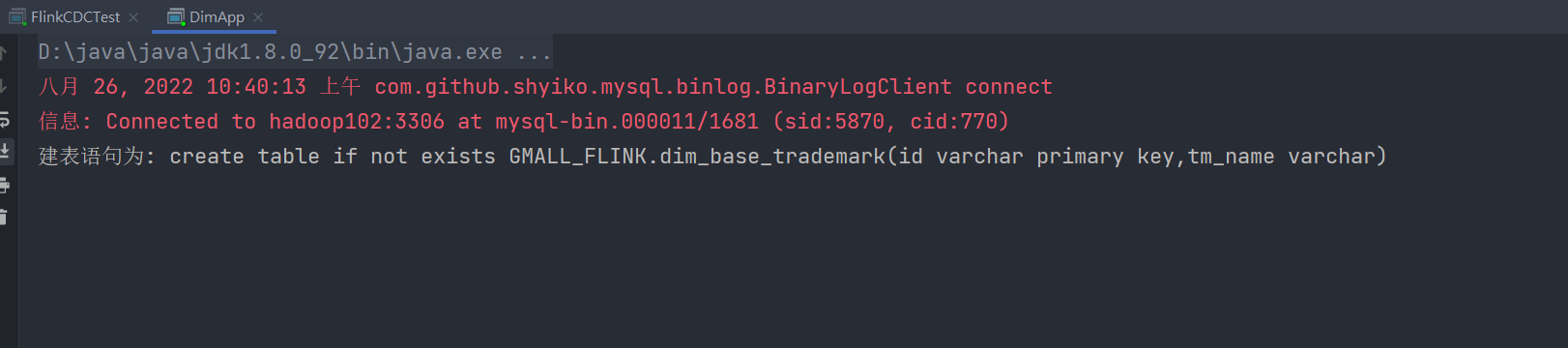
这时候已经成功了。

刚刚我们在gmall-config中添加了 base_trademark 这个表,现在我们在添加一个表,名为base_category1表,查看idea运行情况(不重启任务,不修改代码,因为Flink程序就是 7* 24小时全天运行的)

phoenix非常成功
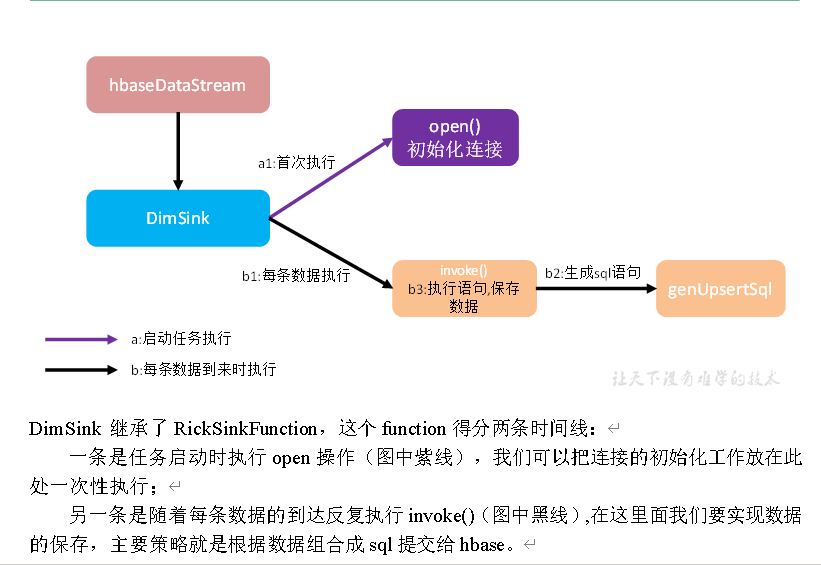
保存维度到HBase(Phoenix)
Phoenix 工具类
自定义JDBC连接池
官方Jdbc适合单表,只能自己定义Jdbc,加入德鲁伊依赖
<!--德鲁伊依赖--><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version></dependency>
配置常量类GmallConfig
自定义Sink
开始入库
生产环境测试
运行idea,之后在sqlyong中 找到 base_trademark ,添加数据
12,佟欢欢 /aaa/bbb
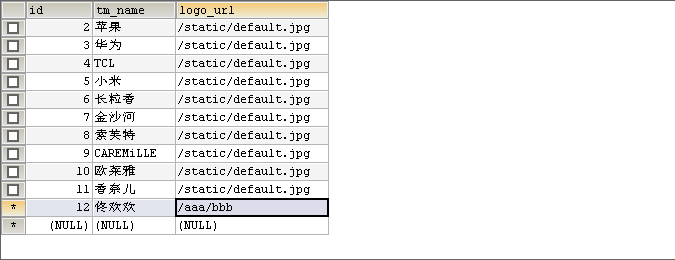
idea 结果 :

Phoenix结果
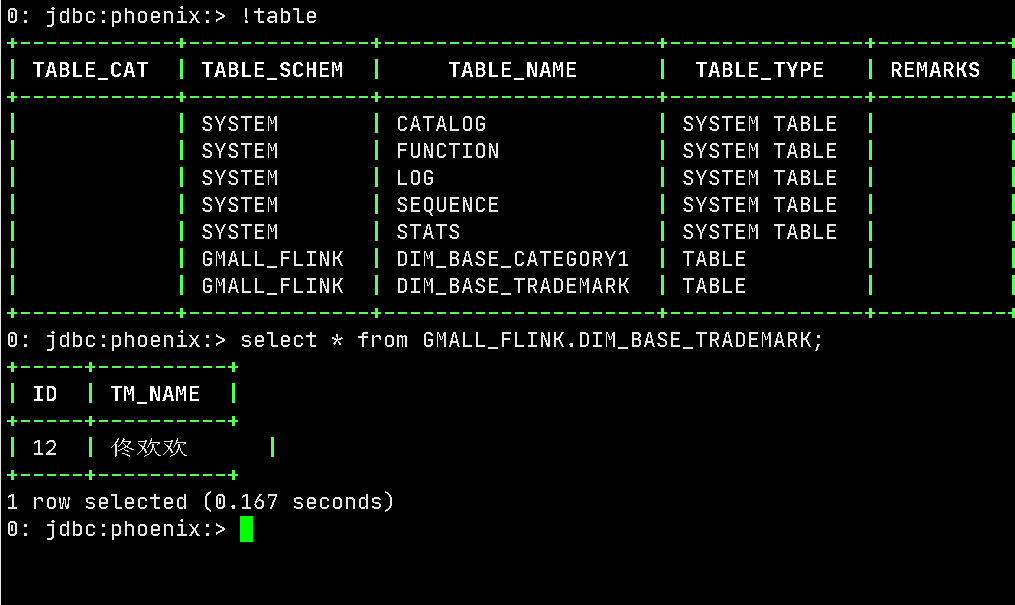
成功入库,测试成功!

若有收获,就点个赞吧
0 人点赞
