由於語法渲染問題而影響閱讀體驗, 請移步博客閱讀~
本文GitPage地址
grep 搜索
grep##Usage: grep [OPTION]... PATTERN [FILE]...##Try 'grep --help' for more information.
**
1. 快速上手
## 创建测试文件echo -e "ab\na\nb\nc\nd\ne\nf\ng\nA\nB\nC" > test.txt## 搜索存在'a'的内容grep a test.txt

2. 常用
$gr
## "."模糊匹配grep a. test.txt

## 显示所在行grep -n a test.txt

## 输出匹配次数(多少行)grep -c a test.txt

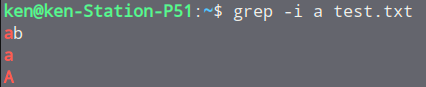
## 忽略大小写grep -i a test.txt
##多项匹配: "|" 分隔开多选必配项。注意,如果我没记错的话,最多可同时匹配1000项grep -E 'a|b' test.txt

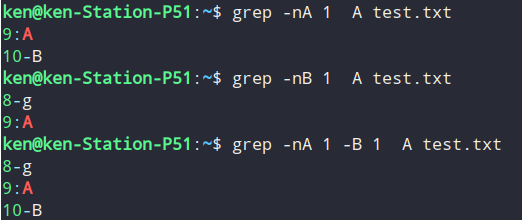
##打印匹配项的上下一行或多行grep -nA 1 A test.txt # 等同于 grep -n -A 1 A test.txt, -n 用于显示行数grep -nB 1 A test.txt # 显示匹配的上一行grep -nA 1 -B 1 A test.txt # 同时显示匹配的上下两行
3. 快速应用:
抓取fasta序列:
测试文件:test.fa.txt
首先,把fasta文件规整成一行ID,一行序列格式。
##通过一系列骚操作,把多行序列转换成单行cat test.fa.txt | tr '\n' '#'| sed 's/#>/\n>/g'|sed 's/#/\n/;s/#//g' > test.fa
3.1,获取所有的fasta ID
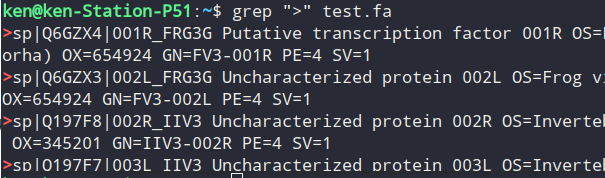
grep ">" test.fa
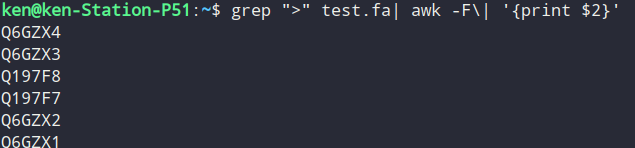
3.2,获取杠内ID
grep ">" test.fa| awk -F\| '{print $2}'
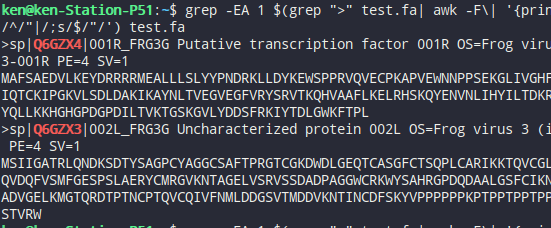
3.3,通过grep 多项匹配,获取前两个ID及其序列
grep -EA 1 $(grep ">" test.fa| awk -F\| '{print $2}'|head -n 2| tr '\n' '|'|sed 's/^/"|/;s/$/"/') test.fa##orgrep -EA 1 $(grep ">" test.fa|\awk -F\| '{print $2}'|\head -n 2|\tr '\n' '|'|\sed 's/^/"|/;s/$/"/') test.fa'''其中,$(grep ">" test.fa| awk -F\| '{print $2}'|head -n 2| tr '\n' '|'|sed 's/^/"|/;s/$/"/') 的结果为的结果为:"|Q6GZX4|Q6GZX3|"因此可以直接被 grep -E 参数识别'''
4. 其他详细请看:
参数解释:https://www.runoob.com/linux/linux-comm-grep.html
复杂正则匹配:https://www.cnblogs.com/keithtt/p/6820540.html
Enjoy~
由於語法渲染問題而影響閱讀體驗, 請移步博客閱讀~
本文GitPage地址
GitHub: Karobben
Blog:Karobben
BiliBili:史上最不正經的生物狗

若有收获,就点个赞吧
0 人点赞
