一、数据类型
1.数据分类
1.1数值型
-
1.2字符型
character:加了引号都是。”a”、”1”、”a+1”、’?’
1.3逻辑型
1.3.1 表现形式
-
1.3.2 来源
比较运算的结果:== 、<、>、!=
-
2.数据的判断和转换
2.1 判断
class()#判断数据类型,向量返回元素的数据类型,数据框返回 ,矩阵返回 ,列表返回 。is.numeric()#is族函数,返回值为T/F
2.2转换
转换规律:数值型→字符型;逻辑型→字符型;逻辑型→数值型
as.numeric()#as族函数,将数据转换为数值型
二、数据结构
1. 向量 vector
只能包含一种数据类型 x <- c(1,3,5,1);x x:变量名 1:元素
1.1 向量的生成:
-
1.2 向量的筛选:[]
将TURE筛选出来,FALSE丢弃;x[x%in%y]
- []中可以是向量,如,x[1:4] x[c(1,5)] ,1:4和c(1,5)都是向量;
- 也可以是向量中元素的下标,如,x[-4];
也可以是逻辑值,如,x[x%in%y],与x等长的逻辑值向量
1.3 向量的修改``
-
1.4 向量的简单做图
-
1.5 参考价值的习题
kids <- c("a",'b','c','d','e')scores <- c('3','4','5','1','2')kids1 <- c("a","c","d","b","e")score[order(scores)] ##sort(x)=x[order(x)]kids[order(scores)] ##以scores的从低到高给kids排序x[match(y,x)] ##y是模板,给x调整顺序scores[match(kids1,kids)];scores ##以kids1模板调整kids的顺序的元素的下标改变来调整scores的顺序
1.6 代码总结
paste0()/paste()/paste(x,y,sep="") ##将两个向量组合在一起无/有空格/分隔符 paste0(rep("x",3),1:3) = paste0("x",1:3) ##与位置有关的函数会循环补齐x==y ##一一对应比较,生成等长向量,循环补齐,以长的为主x%in%y ##检验x中的每个元素是否存在于y中,返回的是x等长的逻辑向量length(x) ##计算向量里面元素的个数unique(x) ##去重复 ,保留第一次出现的元素duplicated(x) ##判断元素在之前是否已经出现过,判断,未出现过F,出现过T !duplicated()table(x) ##重复值统计sort(x) ##默认从小到大排序 sort(x,decreasing=T)从大到小rev() ##逆转 rev(sort(x))从大到小排序identical(y1,y2) ##确认y1和y2是否完全一致intersect(x,y) union() setdiff(x,y) ##x中有y中无 #取交集,并集,差集round(a,2) ##保留a的2位小数rnorm(n=10,mean=0,sd=18) ##取随机数rep(,times=) ##重复序列seq(from=,to=,by=) ##有规律序列
2. 数据框 data.frame
一列只包含一个向量,即一列为同一种数据类型。如果将数据框转换为矩阵,将对其中的数据类型进行转换,详见数据转换规律。
2.1 数据框生成
直接输入,或读取文件:df2 <- read.csv(‘gene.csv’)
2.2 数据框属性
dim() ##有几行几列
- nrow(df) ##几行 ncol(df) ##几列
-
2.3 数据框取子集
取一个:df[2,3] ##第2行第3列
- 取一列:df$gene df[,2]
- 取一行:df[2,]
- 取几行几列:df[c(),1:2]
- 按名字:df[,”gene”] df[,c(“a”,”b”)]
按条件:df$gene[df%score<0] ##筛选df数据的score>0对应的gene df[df$score>0,] ##筛选df中score>0的行
2.4 数据框添加、删除
df$aa<-c() ##注意要和原有数据框的列长度相等
-
2.5 数据框修改
改一个/改一行/改一列: df$p.value<-c(0.1,0.2,0.3,0.4,0.5)
改行名列名 : rownames(df)<-c() colnames(df)[2]=”change”改一个列名一个行名
2.6 数据框进阶
head(iris,3) ##看Iris的前3行str(df) ##看数据类型,几行几列,具体内容 5 obs. of 2 variables,5行2列na.omit(df) ##去除含有缺失值的行cbind ##按列连接 rbind ##按行连接merge(test1,test2,by="name") ##两个表格的连接,取两者的交集合并成1个数据merge(test1,test2,by.x="name",by.y="NAME")
2.7 参考价值的习题
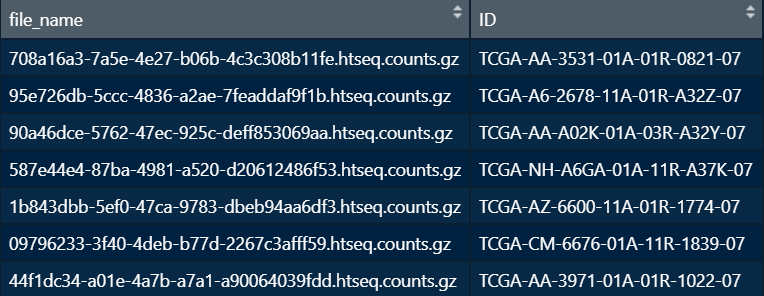
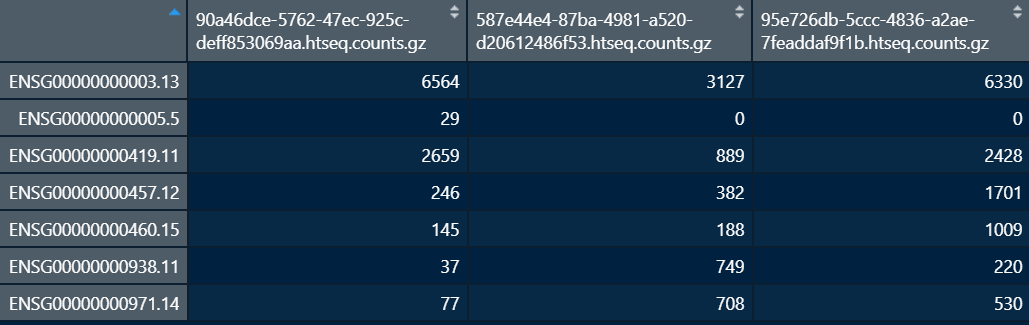
x y :将y的列名改成TCGA-ID
identical(colnames(y),x$file_name)) F:identical是一一对应比较
colnames(y) <- x$ID[match(colnames(y),x$file_name)] ##注意检查一下结果是否一一对应3. 矩阵 matrix
-
3.1 矩阵新建
-
3.2 矩阵取子集
-
3.3矩阵的转秩和转换
转秩:t(m)行名会转成列名
-
3.4 画热图:
heatmap::pheatmap(m),自动进行聚类操作。
如果不想聚类的进行画热图heatmap::pheatmap(m,cluster_cols=F,cluster_rows=F)
4. 列表 list
-
4.1 新建列表
x<-list(m=matris(1:9,nrow=3),df= x= ) ##可以是向量,数据框和矩阵的集合,l的元素的名字分别是m,df,x。
l <- list(m=matrix(1:9, nrow = 3),df=data.frame(gene = paste0("gene",1:3),sam = paste0("sample",1:3),exp = c(32,34,45)),x=c(1,3,5))
4.2 列表取子集
m[[2]]取第2个元素 m$df
- m[2]和m[[2]]的区别在于数据结构,用class()判断。
- m[2] 取的是列表中的第2个元素,数据类型仍然是列表list;
m[[2]]取的是列表第2个元素里面的内容,数据类型:向量=数据类型,数据框data.frame,矩阵matrix
4.3 列表元素的名字
向量里面每个元素的名字names()
- x <- list(a= ,b= ) 将给列表的元素附上名字
names(x) <- c(‘a’,’b’) ##给列表x中的2个元素分别命名为a和b
4.4 删除变量
rm(l)删除1个,删除多个rm(df,m), 删除全部 rm(list=ls()) ,清空控制台ctrl+l
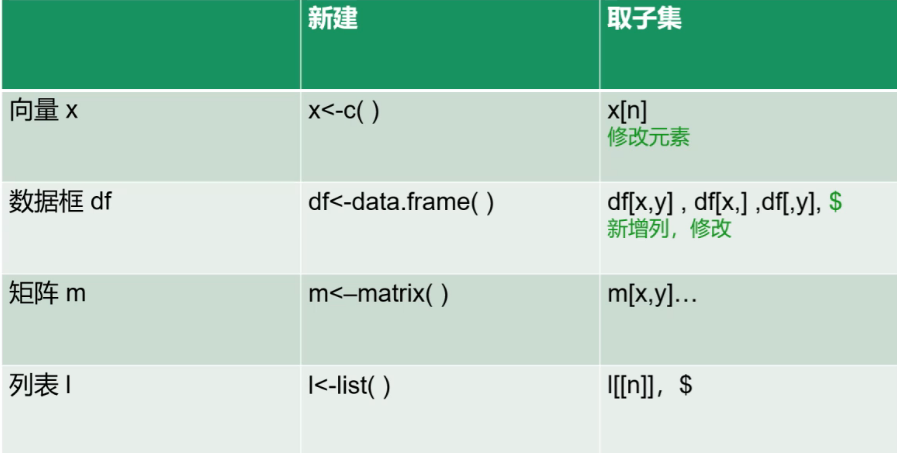
5、数据结构总结
$可以用在data.frame和列表list中
三、函数与R包
1. 函数
1.1 形式参数和实际参数
- 形式参数的默认值:根据标准情况下表现最好的值,为默认值。
- 2为实际参数,可以修改。abm为形式参数,不可修改。
- 括号前的是函数();(括号里等号前的是形式参数=);(=括号里等号后的是实际参数)
![LJ]MQL~M)PVCOOW)Z2Y](V.png
1.2 认清函数和数据
-
1.3习题,学习写函数
a <- function(i){mean(i)+2*sd(i)} ##写一个函数,参数是一个数值型向量,输出结果是该向量的平均值加2倍的标准差a(c(1,3,2,4,5)) ##用户使用该函数的代码
2. R包
2.1 R包的安装
install.library(“ “) ##CRAN
- BiocManager::install(“ “) ##bioconductor
- devtools::install_github(“jmzeng1314/idmap1”) ##github
if(!require(stringr))install.packages(“stringr”) ##
2.2 R包加载
library()
-
2.3 获取帮助
搜索 bioconductor limma等
- 少数R包有cheatsheets
- ?seq
- help(“seq”)
- example(“seq”)
- browseVignettes(“stringr”) ##不是所有的包都有
ls(“package:stringr”) ##列出包有哪些函数
四、文件读写
1. 文件读取
分隔符:逗号 空格 制表符(\t)【txt分隔符为空格,csv 逗号为分隔符,tsv分隔符为 tab】
- 打开方式:excel,记事本,sublime(大文件),R(read.csv(“ “),变量名和文件名不一致,且对数据框进行的修改不会同步到表格文件)
- 可以改的参数:
- header=T 【读取第一行】;
- row.names =1 【第一列当行名使用】
- check.names=F 【列名的特殊字符,如”-“不被读取】
- numerals = 【小数点位数】
- fill = T 【当某一列的行数与其他列的行数不匹配的时候,补齐NA】
sep = “\t” 【分隔符】
read.table(" ") ##读取txt文件read.csv(" ") ##读取csv文件,两个文件的参数不同,具体如下mean(as.numeric(y$gene1)) ##注意读取matrix时,会因为既有数值型,又有字符型,导致数值型数据转换为字符型

2. 文件导出
csv:write.csv(test,file = “aaaa.csv “)
- txt:write.table(test,file = “aaaa.txt “)
-
3.Rdata
save(test,file=”aaaa.Rdata”) ##save生成的就是R.data,不论是否是save(xxx.csv),需要用load打开
- load(“aaaaa.Rdata”) 里面可以包含多个数据
-
4.其他格式
行名无用论
- 读取excel:import( .excel) import_list(读取excel工作簿,sheet1sheet2) export(aaa.csv等格式导出都可以)

五、绘图
六、应用
转自生信技能树

若有收获,就点个赞吧
0 人点赞

{kind=link}