- c是函数,不要给c赋值
- Sort(x)等于x[order(x)] ##order还能对数据框排序
- x[1,5] Erron 正确的是 x[c(1,5)] 因为”,”是对维度的切割
- 没有赋值等于没发生过
- 命名的时候不要用c=
- aes=映射
- Breaks() ##这个函数为了不让离群值破坏图 例如样本以后表达量分别为(1,2,3,4,5,6,7)做热图时,突然出现一个50那么Breaks的作用就是把50(≥7)在图里显示的颜色=7.
- fill后面只能跟列名
- 取过log的值范围在(1-16),作图时检查数据看是否在(1-16)之间,如果不在就取log,但是有情况是绝大部分在1-16之间,偶尔会有大于16的数据,那么这类数据尽量不要用,或者从原始数据开始分析得到表达矩阵。
- 运行代码不出时的解决方法:1. dev.off 2.dev.new 3.重启R
- STHDA (http://www.sthda.com/english/) 作图代码集合
- 判断数据类型的函数:class(),把要判断的内容写在括号里
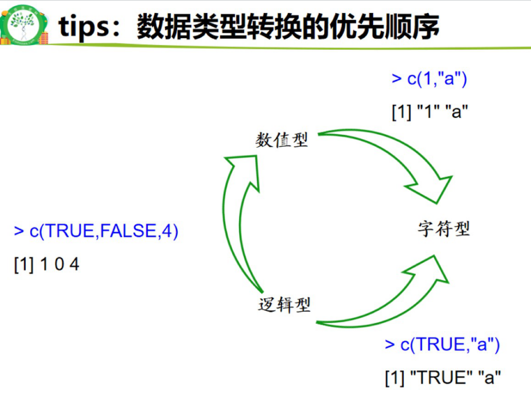
- 数据类型-1:数值型 (1.3,2);2:字符型 (”a”,”nn”);3:逻辑性:(TURE,FALSE,NA).
- tab键自动补全
- 逻辑性数据:!= (不等于的意思)3!= 4 TRUE,逻辑运算的连接:与&、或|、非!。 3<5&4>5 FALSE, 3<5|4>5 TRUE,!(4>5)TRUE。
- is族函数,判断,返回T或F is.numeric(“a”)-FALSE
- as族函数实现数据类型之间转换 as.numeric(“4”)-4
- 连续的数字用冒号“:”,有重复用rep(“x”,times=3),#repetition。有规律的序列用seq(from=3,to=21,by=3),#sequence。随机数用rnorm(n=3),#normrnd正态随机发生器,黏合数据用paste0(rep(“x”,times=3),1:3)。
- 赋值的方法 x=c(1,3,11) #随意,x <- c(1,3,11)#规范的赋值符号x <- c(1,3,5,1)。unique(x) #去重复,duplicated(x) #duplicate()确定vector或数据帧中的哪些元素是具有较小下标的元素的副本,并返回一个逻辑向量,指示哪些元素(行)是副本。sort(x) #对x从小到大排序。
- x %in% y #判断x的每个元素在y中存在么,paste(x,y,sep=”,”) #把x与y通过逗号“,”连接。
- intersect(x,y) 取交集,union(x,y)取并集,setdiff(x,y) 取x在y中没有的集合差,setdiff(y,x),取y在x中没有的集合差。
- x == y 有循环补齐功能,输出逻辑值T,F。
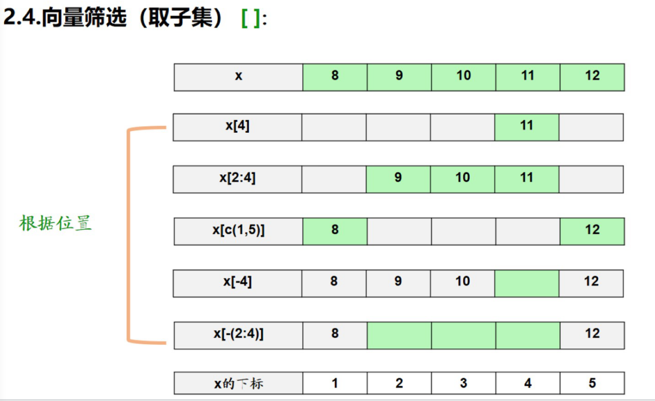
- [] 向量取子集:先判断[]里面的内容返回T或F,然后把T对应的挑选出来,把F对应的弃掉。x[-4]中-的作用是去掉这个下标的数据。
- 修改向量中的某个/某些元素,[]中选下标你要修改的元素,然后赋值你要的数据。
x[4] <- 40。 - R语言里的修改都要赋值,没有赋值就没有发生过。
- mathc:谁在外面,谁就在后面
x <- c("A","B","C","D","E")y <- c("B","D","E","A","C")match(y,x)x[match(y,x)]


若有收获,就点个赞吧
0 人点赞
