一、单个数据框处理⭐️⭐️⭐️——使用前加载dplyr
1、sort(),order()排序书写太麻烦?试试arrange()吧⭐️⭐️⭐️
> library(dplyr)> arrange(test, Sepal.Length) #按照Sepal.Length列升序排列> arrange(test, desc(Sepal.Length))> arrange(test, desc(Sepal.Width),Sepal.Length)#双排序(若A列相同,再按B列排)Sepal.Length Sepal.Width Petal.Length Petal.Width Species1 5.1 3.5 1.4 0.2 setosa2 6.3 3.3 6.0 2.5 virginica3 6.4 3.2 4.5 1.5 versicolor4 7.0 3.2 4.7 1.4 versicolor5 4.9 3.0 1.4 0.2 setosa6 5.8 2.7 5.1 1.9 virginica
2、新增列——mutate()
test=mutate(test,new=Sepal.Length*Sepal.Width)
3、筛选行、列——filter(),select()
4、管道符号——避免中间变量过多(%>%),理解为”then”
二、将表达矩阵绘制为箱图⭐️⭐️⭐️⭐️(需将数据预处理)
 ——————>
——————> (宽变长)
(宽变长)
set.seed(10086)exp = matrix(rnorm(18),ncol = 6)exp = round(exp,2)#保留两位小数rownames(exp) = paste0("gene",1:3)colnames(exp) = paste0("test",1:6)exp[,1:3] = exp[,1:3]+1 #人工处理使差异明显explibrary(tidyr)library(tibble)library(dplyr)dat = t(exp) %>%as.data.frame() %>%rownames_to_column() %>% #行名变列mutate(group = rep(c("control","treat"),each = 3))pdat = dat%>%pivot_longer(cols = starts_with("gene"),#合并哪些列names_to = "gene",#给新列列名values_to = "count")#未处理的值放入此列library(ggplot2)p = ggplot(pdat,aes(gene,count))+geom_boxplot(aes(fill = group))+geom_jitter()+theme_bw()pp + facet_wrap(~gene,scales = "free") #scales = "free"是作图时x,y轴是否要按比例(默认按比例)
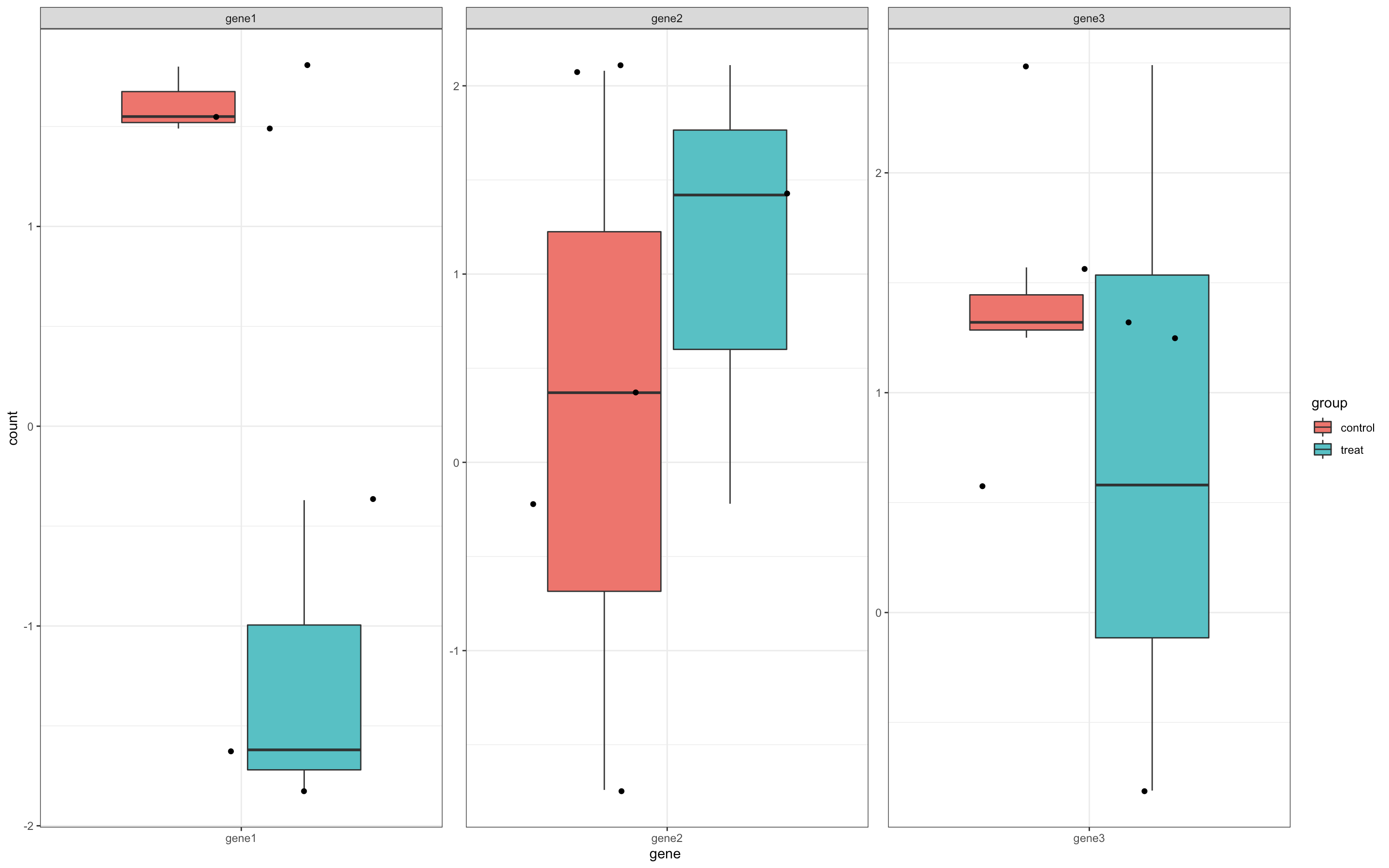
三、缺失值处理⭐️⭐️⭐️——个人认为重要,测序结果有时遇到缺失
> drop_na(X) #把所有有Na值行删除> drop_na(X,X1)#查看特定列缺失值,并去除该行#替换NA> replace_na(X,list(X2=0))#用上一行的值填充NAfill(X,X2) #若NA为第一个值则仍为NA
四、多个数据框处理
> test1 <- data.frame(name = c('jimmy','nicker','Damon','Sophie'),+ blood_type = c("A","B","O","AB"))> test1name blood_type1 jimmy A2 nicker B3 Damon O4 Sophie AB> test2 <- data.frame(name = c('Damon','jimmy','nicker','tony'),+ group = c("group1","group1","group2","group2"),+ vision = c(4.2,4.3,4.9,4.5))> test2name group vision1 Damon group1 4.22 jimmy group1 4.33 nicker group2 4.94 tony group2 4.5> library(dplyr)> inner_join(test1,test2,by="name")#取交集——与merge存在区别name blood_type group vision1 jimmy A group1 4.32 nicker B group2 4.93 Damon O group1 4.2> right_join(test1,test2,by="name")#右连接(保留右表存在信息)name blood_type group vision1 jimmy A group1 4.32 nicker B group2 4.93 Damon O group1 4.24 tony <NA> group2 4.5> full_join(test1,test2,by="name")#全连接(取全集)name blood_type group vision1 jimmy A group1 4.32 nicker B group2 4.93 Damon O group1 4.24 Sophie AB <NA> NA5 tony <NA> group2 4.5> semi_join(test1,test2,by="name")#半连接行(左边取子集,保留右表存在的信息)name blood_type1 jimmy A2 nicker B3 Damon O> anti_join(test1,test2,by="name")#反连接name blood_type1 Sophie AB
五、字符串处理⭐️⭐️⭐️⭐️⭐️⭐️——stringr包
library(stringr)x <- "The birch canoe slid on the smooth planks."#检测字符串长度str_length(x) #标点空格都算[1] 42#字符串拆分——str_splitx2 = str_split(x," ")[[1]];x2#以空格拆分,提取列表中元素(两个[])x2 = str_split(x," ",simplify = T)[1,] #simplify将列表简化为矩阵#字符串连接——str_cstr_c(x2,collapse = " ")#连接str_c(x2,1234,sep = "+")#外部连接#提取字符串的一部分> str_sub(x,5,9)[1] "birch"#字符定位> str_locate(x2,"n")start end[1,] NA NA[2,] NA NA[3,] 3 3[4,] NA NA[5,] 2 2[6,] NA NA[7,] NA NA[8,] 4 4#字符检测!!!!!str_detect(x2,"n")#检测是否含有“n”,并返回T/F[1] FALSE FALSE TRUE FALSE TRUE FALSE FALSE TRUE#与sum和mean连用,可以统计匹配的个数和比例sum(str_detect(x2,"n"))mean(str_detect(x2,"n"))#字符串替换str_replace(x2,"o","A")#默认替换每个字符串中匹配第一个[1] "The" "birch" "canAe" "slid" "An" "the" "smAoth"[8] "planks."str_replace_all(x2,"o","A")#替换全部[1] "The" "birch" "canAe" "slid" "An" "the" "smAAth"[8] "planks."#提取匹配到的字符> str_extract(x2,"o|e")#默认提取每个字符串中匹配第一个,没有返回NA[1] "e" NA "o" NA "o" "e" "o" NA> str_extract_all(x2,"o|e")[[1]][1] "e"[[2]]character(0)[[3]][1] "o" "e"[[4]]character(0)[[5]][1] "o"[[6]][1] "e"[[7]][1] "o" "o"[[8]]character(0)> str_extract_all(x2,"o|e",simplify = T)[,1] [,2][1,] "e" ""[2,] "" ""[3,] "o" "e"[4,] "" ""[5,] "o" ""[6,] "e" ""[7,] "o" "o"[8,] "" ""#字符删除str_remove(x," ")#删除第一个空格字符str_remove_all(x," ")
六、条件语句与循环语句⭐️⭐️⭐️⭐️⭐️⭐️——类似于C语言
1、if条件语句
(1)与else放一起使用


(2)ifelse

(3)多个条件
i = 0if (i>0){print('+')} else if (i==0) {print('0')} else if (i< 0){print('-')}ifelse(i>0,"+",ifelse((i<0),"-","0"))
2、for循环语句
(1)两种循环方式

(2)循环结果保存
s = 0> x <- c(5,6,0,3)> result = list()> for(i in 1:length(x)){+ s=s+x[[i]]+ result[[i]] = c(x[[i]],s)+ }> result[[1]][1] 5 5[[2]][1] 6 11[[3]][1] 0 11[[4]][1] 3 14> do.call(cbind,result)[,1] [,2] [,3] [,4][1,] 5 6 0 3[2,] 5 11 11 14
七、矩阵、数据框的隐式循环——apply函数

八、列表的隐式循环——lapply()、sapply()
#lapply()返回值是列表lapply(test,mean)#sapply 简化结果,直接返回矩阵或向量sapply(test,mean)

若有收获,就点个赞吧
0 人点赞
