下载附件得到: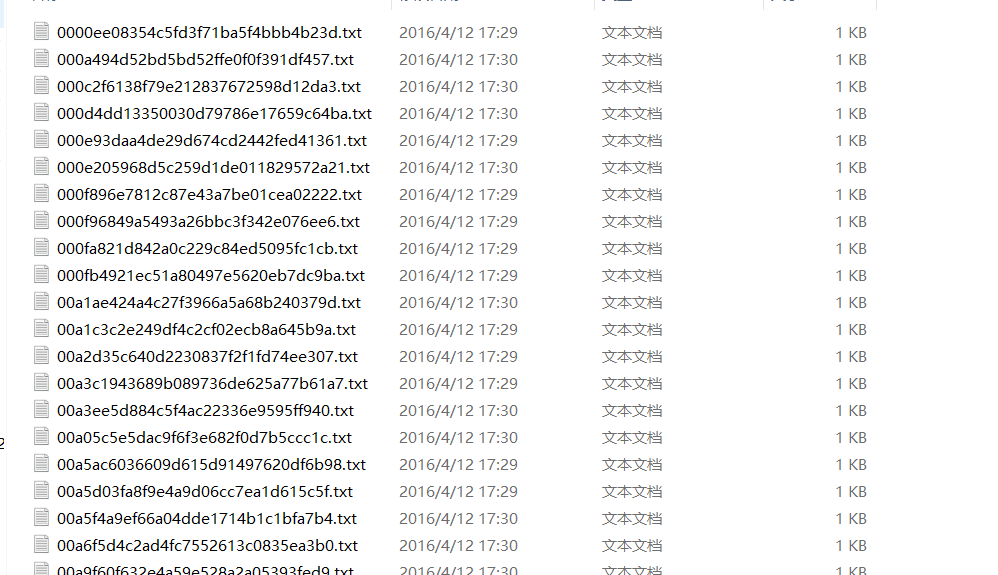

大体看出来题目的想法了,依次从这些txt中读取数据,然后转成16进制,写入文件。
看文件头是个zip。
这里说个写脚本时的坑,有的txt里面的数据转成16进制后是3位,大部分的都是4位,3位的肯定不符合格式,需要进行补零,这里文件读取read后一系列转换后的数据类型还是str,然后就索性用了str补零的方法(zfill)。当然对于别的类型补零对齐的方法也有很多,比如format函数,这里就先不整理了。
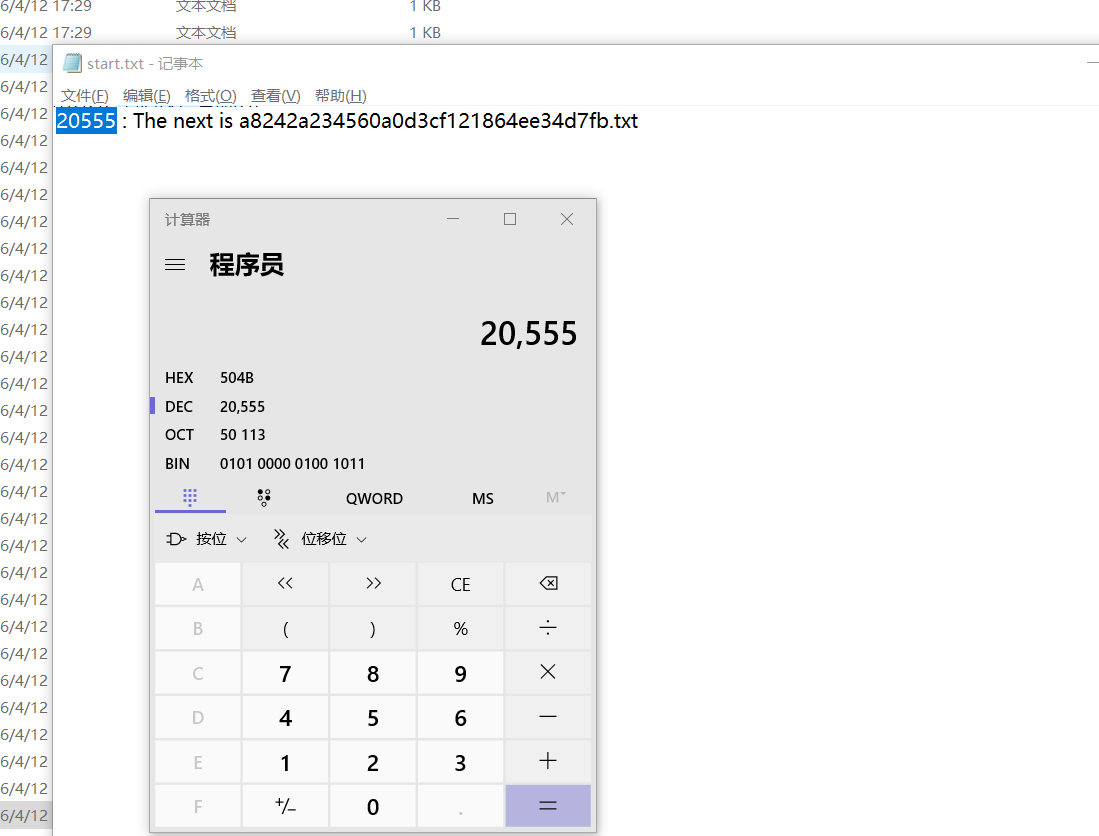
import binasciihex_data = ''with open('D://Firefox download//files//start.txt') as f:data = f.read()next = data[-36:]# print(next)hex_data += hex(int(data[0:data.find(':')-1]))[2:]# print(hex_data)while True:try:with open('D:\\Firefox download\\files\\'+next,'r+') as k:data = k.read()next = data[-36:]hex_data += (hex(int(data[0:data.find(':') - 1]))[2:]).zfill(4)except IOError:breakwith open('output.txt','wb') as n:n.write(hex_data.encode(encoding = "utf-8"))
还有个注意点是拼接路径: with open(‘D:\Firefox download\files\‘+next,’r+’) as k:
这个地方也是卡了很长时间,开始遇到的问题是无法访问这个路径下的文件,后来找到这样解决路径拼接的问题,最后本是写入zip,发现好出错,也没再修改,就先输入到txt里面,使用010Editor进行转换一下得到最终的压缩包: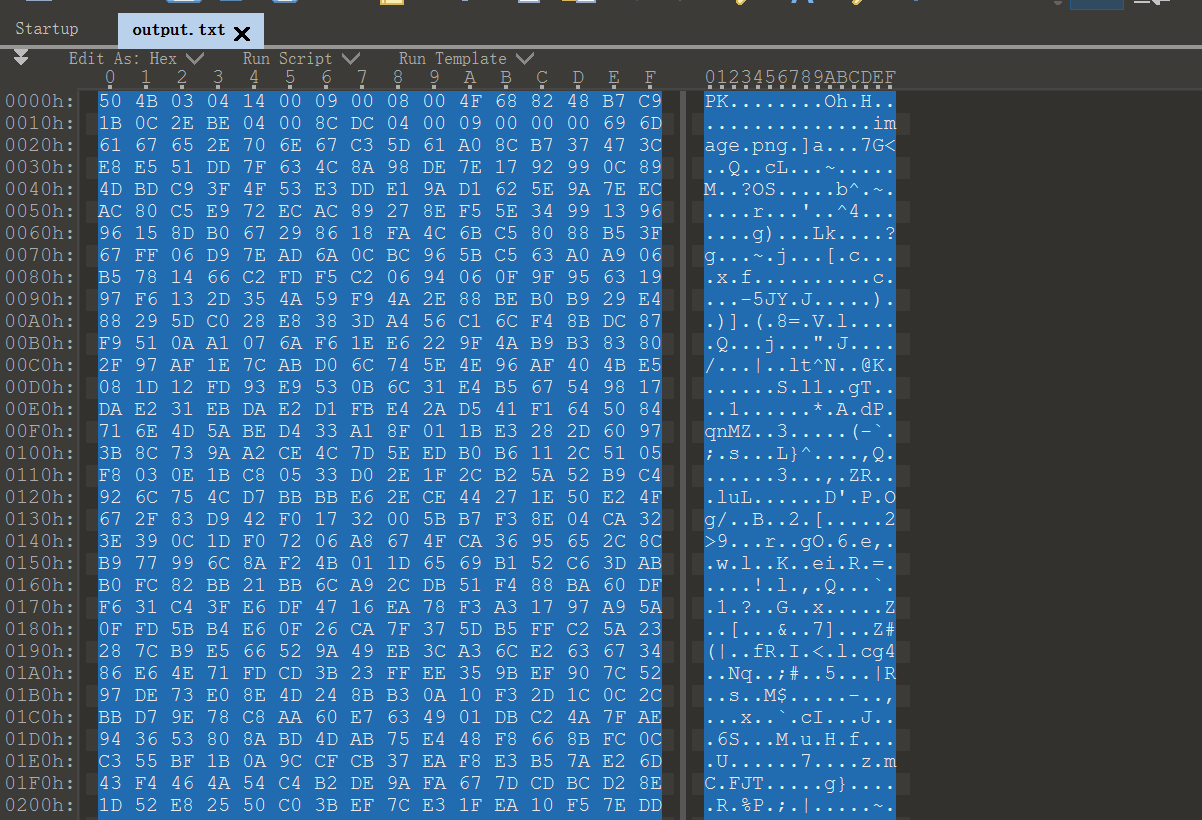
得到最终的压缩包加密了,以为是伪加密结果发现不是,那就爆破一下:
爆破数字一半天没出来,属实有点坑,
放个网上wp的爆破截图:这是掩码,不是直接爆破,想着看看原压缩包备注啥的有提示不,看了一圈也没有,分离出来的个压缩包竟然和题目附件一样。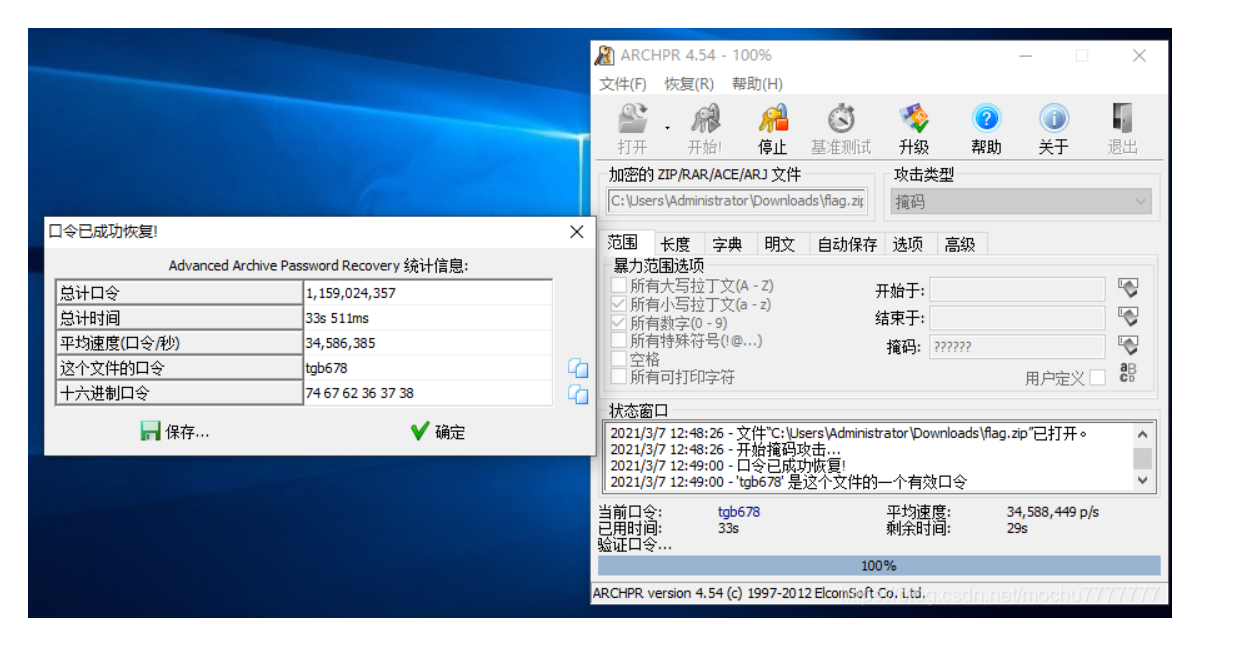
解压完给出一个png图片,但打不开,010Editor发现是jpg: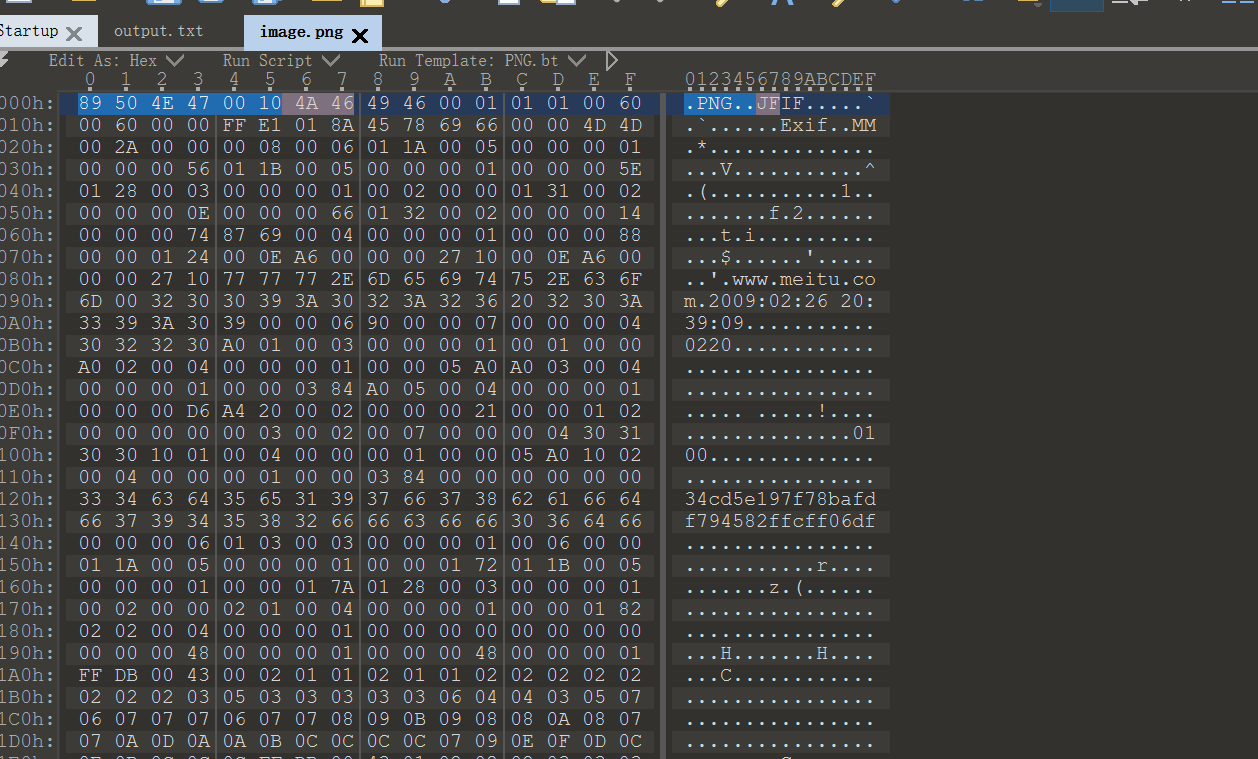
修改后: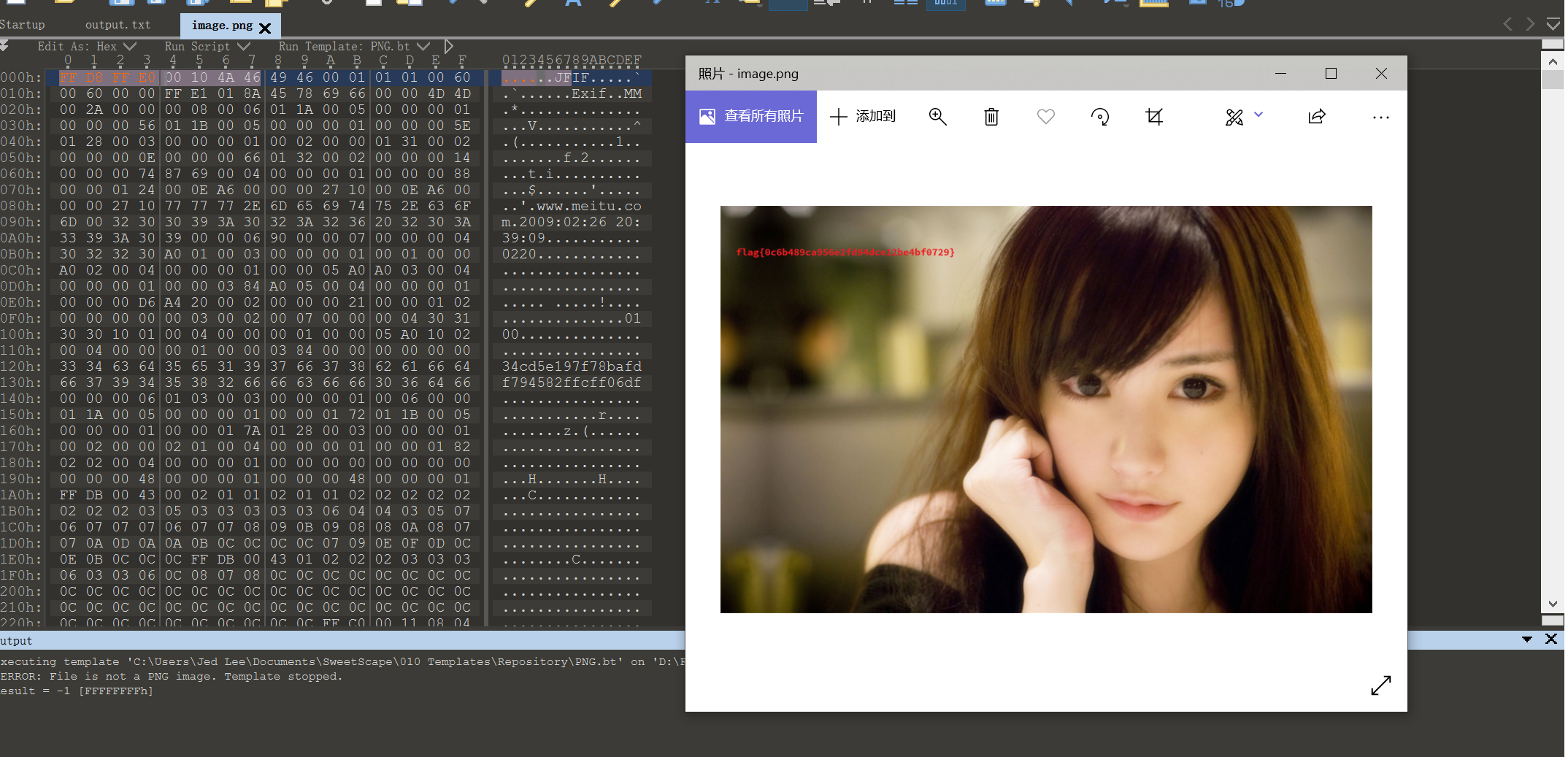

若有收获,就点个赞吧
0 人点赞
