Core Graphic 是 iOS中 一套 C 的框架,用于一切绘图操作,UIKit 就是基于 Core Graphic 实现的,因此它可以实现比 UIKit 更底层的功能。Core Graphics 使用 Quartz 2D 作为绘图引擎。Quartz 2D 是 iOS 和 macOS 中的二维绘图引擎。我们可以使用 Quartz 2D 的 API 来使用如基于路径的绘图,使用透明的绘图,绘图阴影,透明层,颜色管理,抗锯齿渲染,PDF 文档生成和 PDF 元数据访问等功能。在将多张图片合成一张图片时就需要使用它。
Quartz 坐标系统
由于不同的设备具有不同的基础成像功能,因此必须以与设备无关的方式定义图形的位置和大小。 例如,屏幕显示设备可能能够显示每英寸不超过96像素,而打印机可能能够显示每英寸300像素。 如果在设备级别(例如96像素或300像素)定义坐标系,则在该空间中绘制的对象无法在没有可见变形的情况下在其他设备上进行复制。,它们要不显得太大或太小。
Quartz 的坐标系如下图所示。与我们熟悉的 UIKit 的视图坐标系不同,它的原点位于屏幕的左下角,x轴向右增长,y 轴向上增长。

Quartz 使用当前转换矩阵或 CTM,将独立的坐标系(用户空间)映射到输出设备的坐标系(设备空间)来实现设备独立性的。 当前变换矩阵是一种特殊类型的矩阵,称为仿射变换,可通过应用平移,旋转和缩放操作(移动,旋转和调整坐标系大小的计算)将点从一个坐标空间映射到另一个坐标空间。
某些技术使用与 Quartz 不同的默认坐标系来设置其图形上下文。 相对于 Quartz,此类坐标系是修改后的坐标系,在执行某些 Quartz 绘制操作时必须对其进行补偿。 最常见的修改后的坐标系是将原点放置在上下文的左上角,并将y轴更改为指向页面底部,就像我们熟悉的 UIKit 视图坐标系。
在下面几种情况下会使用此特定坐标系:
NSView的子类重写了isFipped方法,并返回YES。UIView中的绘图上下文。- 在 iOS 中 使用
UIGraphicsBeginImageContextWithOptions函数创建的图形上下文。
下面的代码将一张图片绘制在了 Bitmap 上下文中。由于 Quartz 的默认坐标系统与 UIKit 坐标系统不同,所以最终生成的图看起来是反的。
let ctxSize = UIScreen.main.bounds.sizeguard let ctx = CGContext(data: nil,width: Int(ctxSize.width) ,height: Int(ctxSize.height),bitsPerComponent: 8,bytesPerRow: 0,space: CGColorSpaceCreateDeviceRGB(),bitmapInfo: image.bitmapInfo.rawValue) else {return nil}ctx.draw(image, in: CGRect(origin: .zero, size: size))guard let cgImage = ctx.makeImage() else { return nil }return UIImage(cgImage: cgImage)}
我们可以使用缩放变换取反y坐标会更改 Quartz 绘图中的默认设定。 例如,如果调用 CGContextDrawImage 将图像绘制到上下文中,则在将图像绘制到目标时,图像会通过转换进行修改。 如果修改了坐标系,则结果也会被修改,就像图像在镜子中反射一样。 所以为了能绘制出正确的图像,我们可以使用下面代码来修改 Quartz 默认坐标系:
ctx.translateBy(x: 0, y: ctxSize.height)ctx.scaleBy(x: 1, y: -1)


修改坐标系前 修改坐标系后
合并图片
有了上面的知识后,将多张图片(或文字)合成单张图片就很简单了。总的来说就三步:
- 使用
UIGraphicsBeginImageContextWithOptions创建图形上下文。 - 绘制图片(或文字)。
- 获取图片并结束上下文
UIGraphicsBeginImageContextWithOptions 的第二个参数代表位图是否不透明。 如果我们知道位图是完全不透明的,这个参数应该设置为 true ,以忽略 Alpha 通道,并优化位图的存储(更少的内存占用)。 指定 false 意味着位图必须包含一个 alpha 通道以处理任何部分透明的像素,对于一个完全不透明度图片来说完全是没用必要的。
绘制的节点
在绘制图片(或文字)时我们只需要该图片(或文字)以及其在最终输出图片中的位置和大小。下面代码中 RendererNode 代表了我们需要绘制的节点。
protocol Drawable {func draw()}struct RendererNode: Drawable {enum Element {case image(UIImage)case text(String, attribute: [NSAttributedString.Key: Any]?)}let element: Elementlet frame: CGRectfunc draw() {switch element {case .image(let img):img.draw(in: frame)case let .text(str, attribute: attr):var attr = attrif attr == nil {attr = [ .font: UIFont.systemFont(ofSize: 14), .foregroundColor: UIColor.black]}NSAttributedString(string: str, attributes: attr!).draw(in: frame)}}}
需要注意的是,在绘制图片时我使用的是 UIImage 的 draw(in:) 方法而不是上面示例中的 CGContext 的 draw(, in:) 方法。上面提到过,在使用 UIGraphicsBeginImageContextWithOptions 函数创建的图形上下文会修改 Quartz 的默认坐标系,使其坐标系跟 UIKit 中坐标系一致了,而 CGContext 的 draw(, in:) 方法在将图像绘制到目标时,图像会使用原来的默认坐标系,所以就会导致图片被翻转(相对 UIKit 坐标系而言)。下图就是使用 CGContext 的 draw(, in:) 绘制的结果:

在iOS中 UIImage 对象自动补偿 UIKit 应用的修改后的坐标系。所以上面为了保持坐标一致性我们应该使用 UIImage 的 draw(in:) 方法。
绘制
上面的 RendererNode 定义了需要绘制的节点,接下来就是绘制所有的节点并输出一张图片。 size 属性定义了最终生成的图片的大小。节点的绘制非常简单,只是调用了节点的 draw 方法。下面是所有的代码:
class ImageRenderer {let size: CGSizevar nodes: [Drawable] = []init(size: CGSize, nodes: [RendererNode]) {self.size = sizeself.nodes = nodes}func renderImage(completion: @escaping (UIImage?) -> Void) {DispatchQueue.global(qos: .default).async {UIGraphicsBeginImageContextWithOptions(self.size, true, UIScreen.main.scale)guard let ctx = UIGraphicsGetCurrentContext() else {UIGraphicsEndImageContext()completion(nil)return}ctx.setFillColor(UIColor.white.cgColor)ctx.fill(CGRect(origin: .zero, size: self.size))for node in self.nodes {node.draw()}let image = UIGraphicsGetImageFromCurrentImageContext()UIGraphicsEndImageContext()DispatchQueue.main.async {completion(image)}}}}
合并图片的例子
上面的 RendererNode 和 ImageRenderer 分别定义了绘制的节点以及如何绘制图片。图片最终绘制的样式(每个元素如何排列,例如由一系列的模板定义)则完全由调用方决定。RendererNode 和 ImageRenderer 不应该关心这些。
下面的代码展示了所有图片线性(一个紧接着下一个)绘制的例子:
var y: CGFloat = 0var nodes: [RendererNode] = []for (index, image) in imags.enumerated() {if index > 0 {y = imags[..<index].map { $0.size.height }.reduce(0, +)}let rect = CGRect(origin: CGPoint(x: 0, y: y), size: image.size)let imageNode = RendererNode(element: .image(image), frame: rect)nodes.append(imageNode)}let maxY = nodes.map { $0.frame.maxY }.max() ?? UIScreen.main.bounds.heightlet maxWidth = nodes.map { $0.frame.width }.max() ?? UIScreen.main.bounds.widthlet size = CGSize(width: maxWidth, height: maxY)let renderer = ImageRenderer(size: size, nodes: nodes)

存在的问题
上面绘制最终拼合的图片存在一个问题,就是需要一次创建一个内存大小至少为 宽 * 高 * 3(RGB, 无 Alpha 通道) 字节的图形上下文。如果拼合的图片尺寸过大可能会导致应用崩溃。下图显示了图片绘制瞬间的内存暴涨:
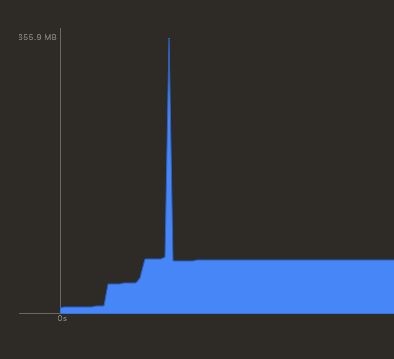
对于内存问题,我们可以采用降低分辨率的办法。比如可以设置一个最大值,当最终输出图片大于该值就进行缩放。下面的代码将最终的图片大小设定为 10 MB 以内:
let maxTotalMB: CGFloat = 10let sourceTotalMB = sourceSize.width * sourceSize.height * 3 / (1024 * 1024)let imageScale = maxTotalMB / sourceTotalMB// 缩放后的目标尺寸let destResolution = CGSize(width: sourceSize.width * imageScale,height: sourceSize.height * imageScale)
下图是将输出图片限定在 10 MB 之内的内存占用: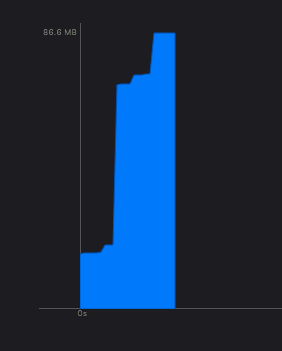
从上面两张图片显示的结果来看,降低输出图片的分辨率的效果还是非常明显的。

若有收获,就点个赞吧
0 人点赞
