熵是接收的每条消息中包含的信息的平均量,又被称为信息熵、信源熵、平均自信息量。所谓的信息熵就是度量一个样本集合”纯度/不确定度”的指标,如何理解呢,我们来举个例子:
假设你在医生办公室的候诊室里和三个病人谈话。 他们三个人都刚刚完成了一项医学测试,经过一些处理,产生了两种可能的结果之一: 疾病要么存在,要么不存在。 他们已经提前研究了特定风险概率,现在急于找出结果,病人a知道,根据统计,他有95%的可能性患有这种疾病。 对于病人b,被诊断为患病的概率是30% 。 相比之下,患者c的概率是50%。
现在我们想集中讨论一个简单的问题。 在其他条件相同的情况下,这三个病人中哪一个面临最大程度的不确定性?
答案很清楚: 病人 c 经历了”最多的不确定性”。 在这种情况下,他所经历的是最大程度的不确定性: 就像抛硬币一样。但是我们如何精确的来计算这种不确定度呢?就有了下面这个公式:
其中 就是第
就是第 个事件发生的概率,也可以看作在整个集合中第类样本所占的比例。规定若
个事件发生的概率,也可以看作在整个集合中第类样本所占的比例。规定若 则
则 。计算出的信息熵最小值为0,最大值为
。计算出的信息熵最小值为0,最大值为 ,当我们计算出的结果越小,代表当前这个数据越纯,也就是不确定度越低。
,当我们计算出的结果越小,代表当前这个数据越纯,也就是不确定度越低。
我们在用一个具体的例子来解释信息熵是如何计算的: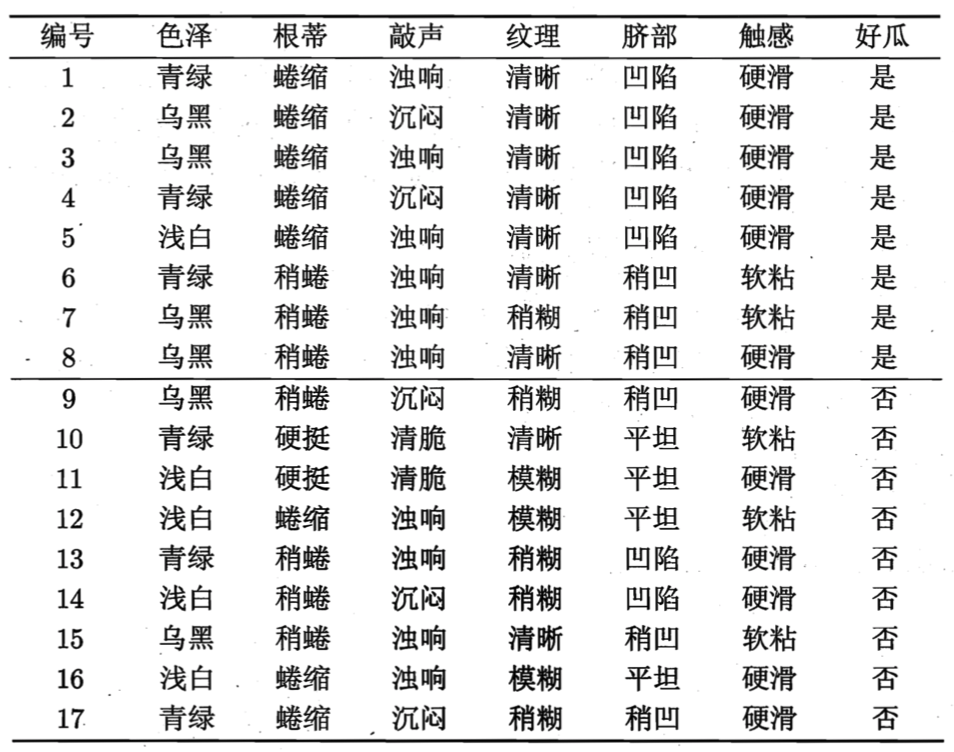
在这个例子中我们数据集共有17条数据,其中包含好瓜和坏瓜两个类别,其中好瓜/正例占 ,坏瓜/负例占
,坏瓜/负例占 。
。
那么现在这个集合的信息熵为:
可以看到我们当前的这个数据集合计算出来的值很大,也就代表当前的数据还是很混乱的,因为正负两个样本基本上各占一半。

若有收获,就点个赞吧
0 人点赞
