sklearn中的EM算法
在 Python 中有第三方的 EM 算法工具包。由于 EM 算法是一个聚类框架,所以你需要明确你要用的具体算法,比如是采用 GMM 高斯混合模型,还是 HMM 隐马尔科夫模型。
from sklearn.mixture import GaussianMixture
我们看下如何在 sklearn 中创建 GMM 聚类。
首先我们使用 gmm = GaussianMixture(n_components=1, covariance_type=‘full’, max_iter=100) 来创建 GMM 聚类,其中有几个比较主要的参数(GMM 类的构造参数比较多,我筛选了一些主要的进行讲解),我分别来讲解下:
- n_components:即高斯混合模型的个数,也就是我们要聚类的个数,默认值为 1。如果你不指定 n_components,最终的聚类结果都会为同一个值。
- covariance_type:代表协方差类型。一个高斯混合模型的分布是由均值向量和协方差矩阵决定的,所以协方差的类型也代表了不同的高斯混合模型的特征。协方差类型有 4 种取值
- covariance_type=full,代表完全协方差,也就是元素都不为 0;
- covariance_type=tied,代表相同的完全协方差;
- covariance_type=diag,代表对角协方差,也就是对角不为 0,其余为 0;
- covariance_type=spherical,代表球面协方差,非对角为 0,对角完全相同,呈现球面的特性。
- max_iter:代表最大迭代次数,EM 算法是由 E 步和 M 步迭代求得最终的模型参数,这里可以指定最大迭代次数,默认值为 100。
创建完 GMM 聚类器之后,我们就可以传入数据让它进行迭代拟合。
我们使用 fit 函数,传入样本特征矩阵,模型会自动生成聚类器,然后使用 prediction=gmm.predict(data) 来对数据进行聚类,传入你想进行聚类的数据,可以得到聚类结果 prediction。
你能看出来拟合训练和预测可以传入相同的特征矩阵,这是因为聚类是无监督学习,你不需要事先指定聚类的结果,也无法基于先验的结果经验来进行学习。只要在训练过程中传入特征值矩阵,机器就会按照特征值矩阵生成聚类器,然后就可以使用这个聚类器进行聚类了。
二维高斯分布
多维变量 的联合概率密度函数为:
的联合概率密度函数为:
其中:
-  :变量维度。对于二维高斯分布,有d=2;
:变量维度。对于二维高斯分布,有d=2;
-  :各位变量的均值;
:各位变量的均值;
-  :协方差矩阵,描述各维变量之间的相关度。对于二维高斯分布,有:
:协方差矩阵,描述各维变量之间的相关度。对于二维高斯分布,有:
数据解析
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.patches import Ellipsefrom scipy.stats import multivariate_normalplt.style.use('seaborn')
def plot_cluster(X, Mu_true, Var_true, color, ang = 0):plt.figure(figsize=(10, 8))plt.axis([-10, 15, -5, 15])ax = plt.gca()plt.scatter(X[:, 0], X[:, 1], s=5, c=color)plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': color, 'alpha': 0.5}ellipse = Ellipse(Mu_true, 3 * Var_true[0], 3 * Var_true[1], angle=ang, **plot_args)ax.add_patch(ellipse)plt.show()nums = [400, 600, 1000, 500]true_Mu = [[0.5, 0.5], [5.5, 2.5], [1, 7], [9, 4.5]]true_Var = [[1, 3], [2, 2], [6, 2], [1, 3]]var = [np.diag(true_Var[0]), np.diag(true_Var[1]),np.diag(true_Var[2]),np.array([[1,-1],[-1,3]])]
第一个例子
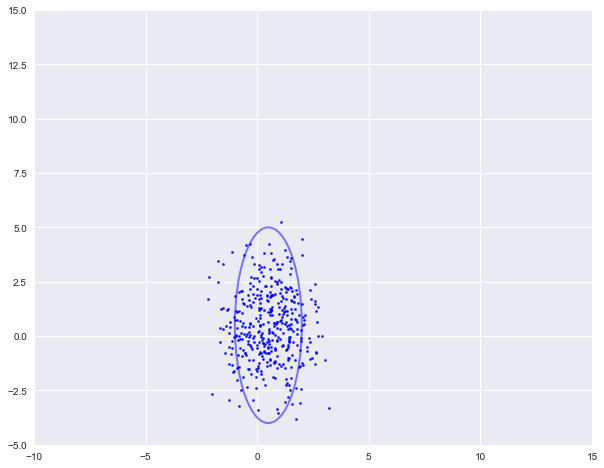
num1, mu1, var1 = nums[0], true_Mu[0], true_Var[0]X1 = np.random.multivariate_normal(mu1, var[0], num1)plot_cluster(X1, [0.5, 0.5], [1, 3], 'b')
第二个例子
num2, mu2, var2 = nums[1], true_Mu[1], true_Var[1]X2 = np.random.multivariate_normal(mu2, var[1], num2)plot_cluster(X2, [5.5, 2.5], [2,2], 'g')

第三个例子
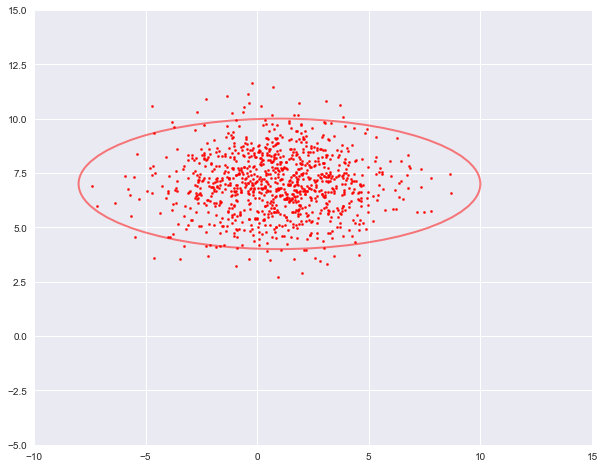
num3, mu3, var3 = nums[2], true_Mu[2], true_Var[2]X3 = np.random.multivariate_normal(mu3, var[2], num3)plot_cluster(X3, [1, 7], [6, 2], 'r')
第四个例子
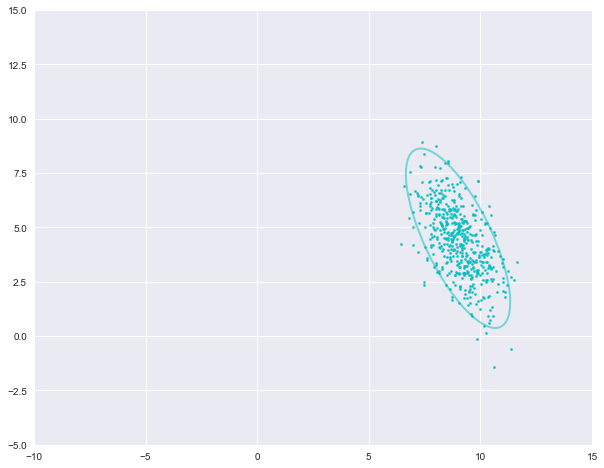
num4, mu4, var4 = nums[3], true_Mu[3], true_Var[3]X4 = np.random.multivariate_normal(mu4, var[3], num4)plot_cluster(X4, [9, 4.5], [1, 3], 'c', 25)
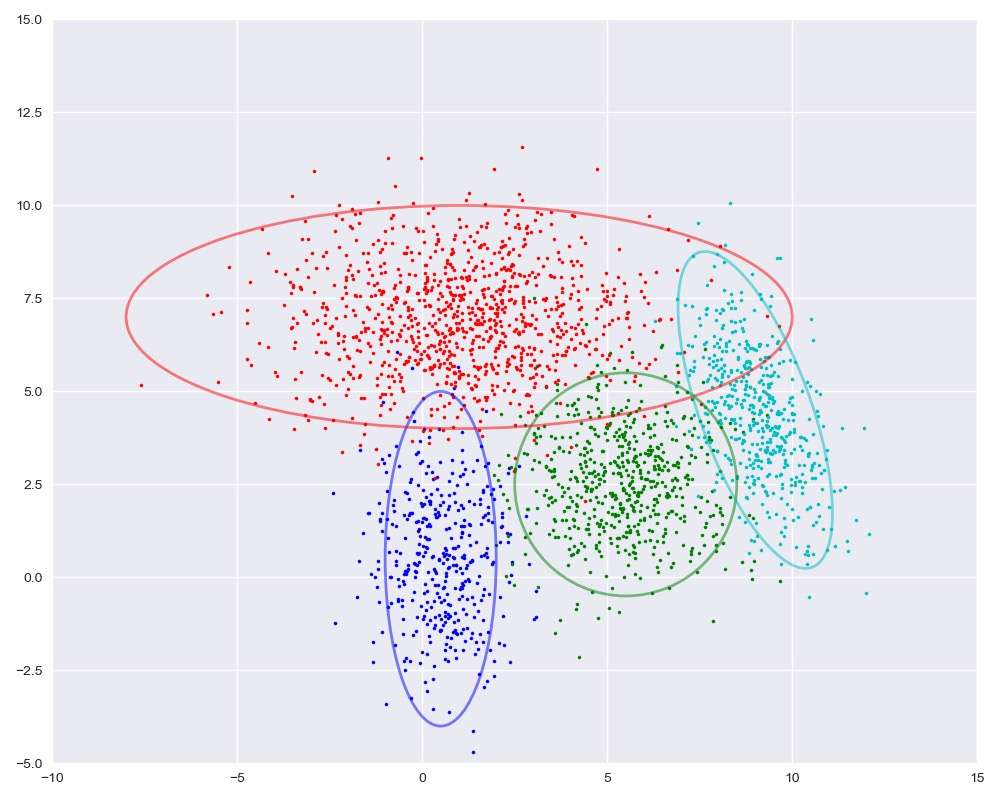
变量初始化
首先要对GMM模型参数以及隐变量进行初始化。通常可以用一些固定的值或者随机值。
- n_clusters是GMM模型中聚类的个数,和K-Means一样我们需要提前确定。这里我们除去倾斜的蓝色数据,所以聚类个数为3。
- n_points是样本点的个数。
- Mu是每个高斯分布的均值。
- Var是每个高斯分布的方差,为了过程简便,我们这里假设协方差矩阵都是对角阵。
- W是上面提到的隐变量,也就是每个样本属于每一簇的概率,在初始时,我们可以认为每个样本属于某一簇的概率都是1/3。
Pi是每一簇的比重,可以根据W求得,在初始时,Pi = [1/3, 1/3, 1/3]
n_clusters = 3n_points = len(X)Mu = [[0, -1], [6, 0], [0, 9]]Var = [[1, 1], [1, 1], [1, 1]]Pi = [1 / n_clusters] * 3W = np.ones((n_points, n_clusters)) / n_clustersPi = W.sum(axis=0) / W.sum()
如何确定GMM中的聚类个数
方法一:BIC

L是likelihood,k是component的个数,n是样本的个数。
- 方法二:cross validation
另一个方法是根据split test的结果(或者说cross validation的结果),先用训练集得到GMM的参数,然后再在测试集上计算log-likelihood。两者明显分叉的地方就是component个数的最佳候选。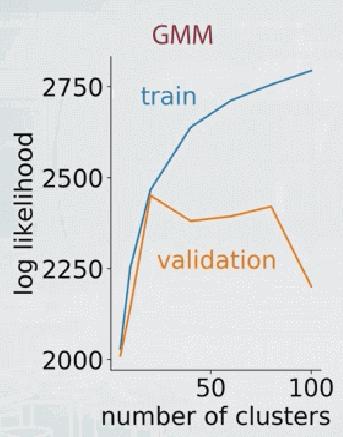
参考:https://scikit-learn.org/stable/auto_examples/mixture/plot_gmm_selection.html#sphx-glr-auto-examples-mixture-plot-gmm-selection-py
E步骤

E步骤中,我们的主要目的是更新W。第i个变量属于第m簇的概率为(这里的$\pi{m}$就是隐变量,我们最开始设置其为1/3,也就代表在当前的均值和方差的情况下,我们隐变量$\pi{m}的先验概率为1/3$):
根据W,我们就可以更新每一簇的占比$\pi{m}$,

def update_W(X, Mu, Var, Pi):n_points, n_clusters = len(X), len(Pi)pdfs = np.zeros(((n_points, n_clusters)))for i in range(n_clusters):# multivariate_normal.pdf:多元正态分布的概率密度函数pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))W = pdfs / pdfs.sum(axis=1).reshape(-1, 1)return Wdef update_Pi(W):Pi = W.sum(axis=0) / W.sum()return Pi
以下是计算对数似然函数的logLH以及用来可视化数据的plotclusters。

def logLH(X, Pi, Mu, Var):n_points, n_clusters = len(X), len(Pi)pdfs = np.zeros(((n_points, n_clusters)))for i in range(n_clusters):pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))return np.mean(np.log(pdfs.sum(axis=1)))def plot_clusters(X, Mu, Var, Mu_true=None, Var_true=None):colors = ['b', 'g', 'r']n_clusters = len(Mu)plt.figure(figsize=(10, 8))plt.axis([-10, 15, -5, 15])plt.scatter(X[:, 0], X[:, 1], s=5)ax = plt.gca()for i in range(n_clusters):plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'ls': ':'}ellipse = Ellipse(Mu[i], 3 * Var[i][0], 3 * Var[i][1], **plot_args)ax.add_patch(ellipse)if (Mu_true is not None) & (Var_true is not None):for i in range(n_clusters):plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'alpha': 0.5}ellipse = Ellipse(Mu_true[i], 3 * Var_true[i][0], 3 * Var_true[i][1], **plot_args)ax.add_patch(ellipse)plt.show()
M步骤
M步骤中,我们需要根据上面一步得到的W来更新均值Mu和方差Var。 Mu和Var是以W的权重的样本X的均值和方差。
因为这里的数据是二维的,第m簇的第k个分量的均值,
第m簇的第k个分量的方差,
以上迭代公式写成如下函数update_Mu和update_Var。
def update_Mu(X, W):n_clusters = W.shape[1]Mu = np.zeros((n_clusters, 2))for i in range(n_clusters):Mu[i] = np.average(X, axis=0, weights=W[:, i])return Mudef update_Var(X, Mu, W):n_clusters = W.shape[1]Var = np.zeros((n_clusters, 2))for i in range(n_clusters):Var[i] = np.average((X - Mu[i]) ** 2, axis=0, weights=W[:, i])return Var
迭代求解
下面我们进行迭代求解。
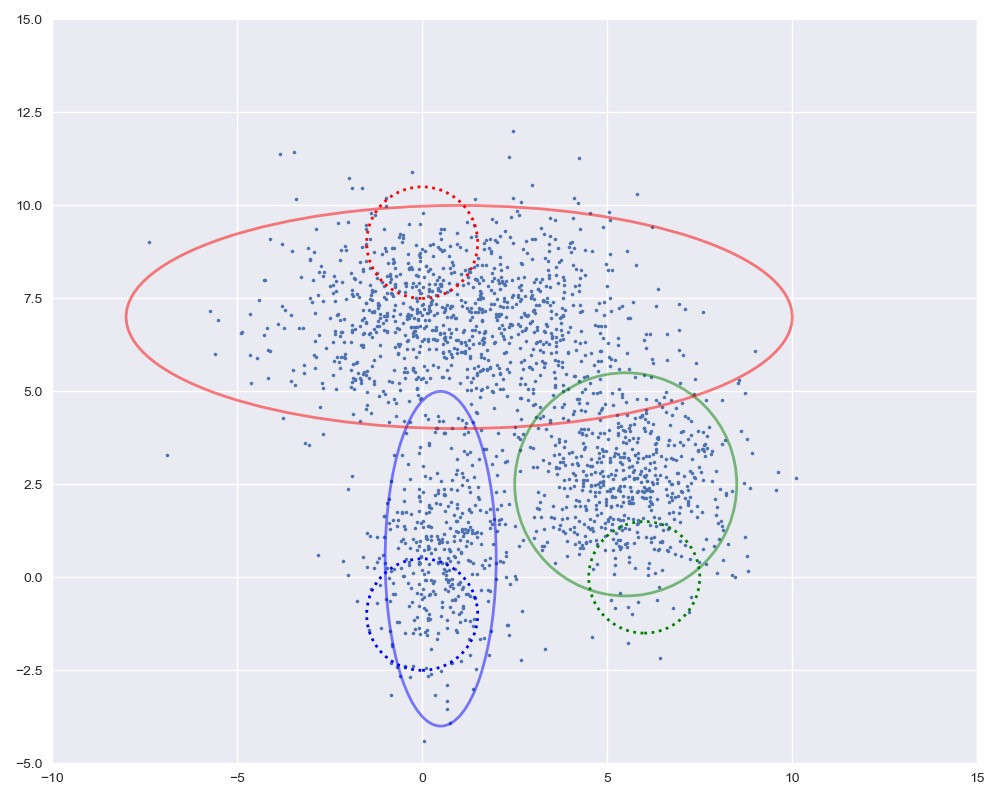
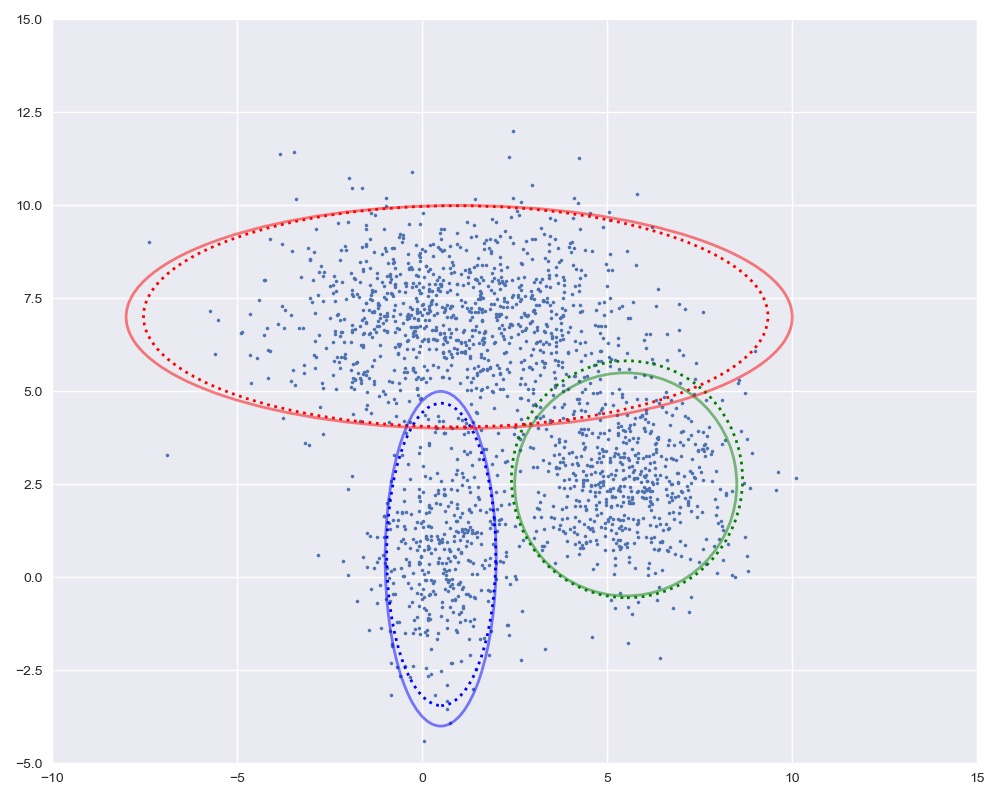
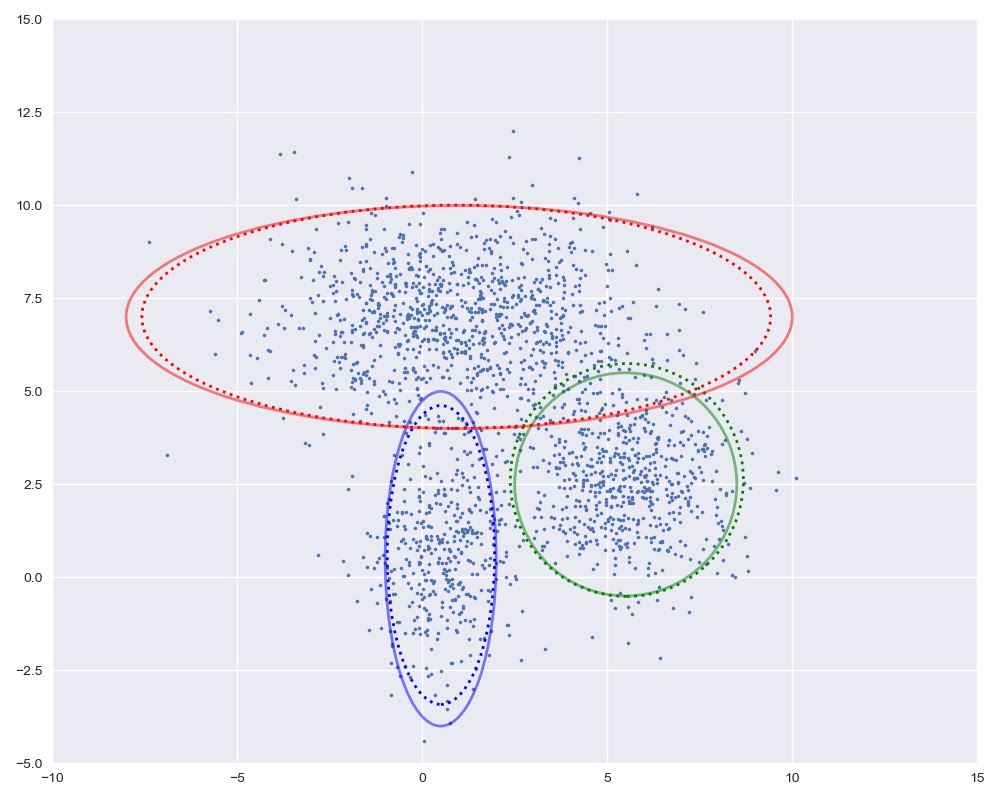
图中实线是真实的高斯分布,虚线是我们估计出的高斯分布。可以看出,经过5次迭代之后,两者几乎完全重合。
loglh = []for i in range(5):plot_clusters(X, Mu, Var, [mu1, mu2, mu3], [var1, var2, var3])loglh.append(logLH(X, Pi, Mu, Var))W = update_W(X, Mu, Var, Pi)Pi = update_Pi(W)Mu = update_Mu(X, W)print('log-likehood:%.3f'%loglh[-1])Var = update_Var(X, Mu, W)
每次迭代的log-likelihood如下
log-likelihood:-8.163log-likelihood:-4.701log-likelihood:-4.698log-likelihood:-4.697log-likelihood:-4.697


完整代码
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.patches import Ellipsefrom scipy.stats import multivariate_normalplt.style.use('seaborn')def generate_X(true_Mu, true_Var):'''生成三个高斯分布数据:param true_Mu: 均值:param true_Var: 方差:return:'''# 第一簇的数据num1, mu1, var1 = 400, true_Mu[0], true_Var[0]X1 = np.random.multivariate_normal(mu1, np.diag(var1), num1)# 第二簇的数据num2, mu2, var2 = 600, true_Mu[1], true_Var[1]X2 = np.random.multivariate_normal(mu2, np.diag(var2), num2)# 第三簇的数据num3, mu3, var3 = 1000, true_Mu[2], true_Var[2]X3 = np.random.multivariate_normal(mu3, np.diag(var3), num3)# 合并在一起X = np.vstack((X1, X2, X3))# 显示数据plt.figure(figsize=(10, 8))plt.axis([-10, 15, -5, 15])plt.scatter(X1[:, 0], X1[:, 1], s=5)plt.scatter(X2[:, 0], X2[:, 1], s=5)plt.scatter(X3[:, 0], X3[:, 1], s=5)plt.show()return X# E步骤更新W,也就是第i个变量属于第m簇的概率# 更新Wdef update_W(X, Mu, Var, Pi):n_points, n_clusters = len(X), len(Pi)pdfs = np.zeros(((n_points, n_clusters)))for i in range(n_clusters):# multivariate_normal.pdf:多元正态分布的概率密度函数pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))W = pdfs / pdfs.sum(axis=1).reshape(-1, 1)return W# 根据更新的W,更新每一簇的占比# 更新pidef update_Pi(W):Pi = W.sum(axis=0) / W.sum()return Pi# 计算log似然函数def logLH(X, Pi, Mu, Var):n_points, n_clusters = len(X), len(Pi)pdfs = np.zeros(((n_points, n_clusters)))for i in range(n_clusters):pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))return np.mean(np.log(pdfs.sum(axis=1)))# 画出聚类图像def plot_clusters(X, Mu, Var, Mu_true=None, Var_true=None):colors = ['b', 'g', 'r']n_clusters = len(Mu)plt.figure(figsize=(10, 8))plt.axis([-10, 15, -5, 15])plt.scatter(X[:, 0], X[:, 1], s=5)ax = plt.gca()for i in range(n_clusters):plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'ls': ':'}ellipse = Ellipse(Mu[i], 3 * Var[i][0], 3 * Var[i][1], **plot_args)ax.add_patch(ellipse)if (Mu_true is not None) & (Var_true is not None):for i in range(n_clusters):plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'alpha': 0.5}ellipse = Ellipse(Mu_true[i], 3 * Var_true[i][0], 3 * Var_true[i][1], **plot_args)ax.add_patch(ellipse)plt.show()# M步根据更新的W和PI来跟新均值Mu与方差Var# 更新Mudef update_Mu(X, W):n_clusters = W.shape[1]Mu = np.zeros((n_clusters, 2))for i in range(n_clusters):Mu[i] = np.average(X, axis=0, weights=W[:, i])return Mu# 更新Vardef update_Var(X, Mu, W):n_clusters = W.shape[1]Var = np.zeros((n_clusters, 2))for i in range(n_clusters):Var[i] = np.average((X - Mu[i]) ** 2, axis=0, weights=W[:, i])return Varif __name__ == '__main__':# 生成数据true_Mu = [[0.5, 0.5], [5.5, 2.5], [1, 7]]true_Var = [[1, 3], [2, 2], [6, 2]]X = generate_X(true_Mu, true_Var)# 初始化n_clusters = 3 #聚类的个数n_points = len(X)Mu = [[0, -1], [6, 0], [0, 9]]Var = [[1, 1], [1, 1], [1, 1]]Pi = [1 / n_clusters] * 3W = np.ones((n_points, n_clusters)) / n_clusters #隐变量Pi = W.sum(axis=0) / W.sum() #每一簇的比重,可以根据W求得# 迭代loglh = []for i in range(5):plot_clusters(X, Mu, Var, true_Mu, true_Var)loglh.append(logLH(X, Pi, Mu, Var))W = update_W(X, Mu, Var, Pi)Pi = update_Pi(W)Mu = update_Mu(X, W)print('log-likehood:%.3f'%loglh[-1])Var = update_Var(X, Mu, W)

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}