使用EM算法对王者荣耀数据进行聚类
首先我们知道聚类的原理是“人以群分,物以类聚”。通过聚类算法把特征值相近的数据归为一类,不同类之间的差异较大,这样就可以对原始数据进行降维。通过分成几个组(簇),来研究每个组之间的特性。或者我们也可以把组(簇)的数量适当提升,这样就可以找到可以互相替换的英雄,比如你的对手选择了你擅长的英雄之后,你可以选择另一个英雄作为备选。
我们先看下数据长什么样子: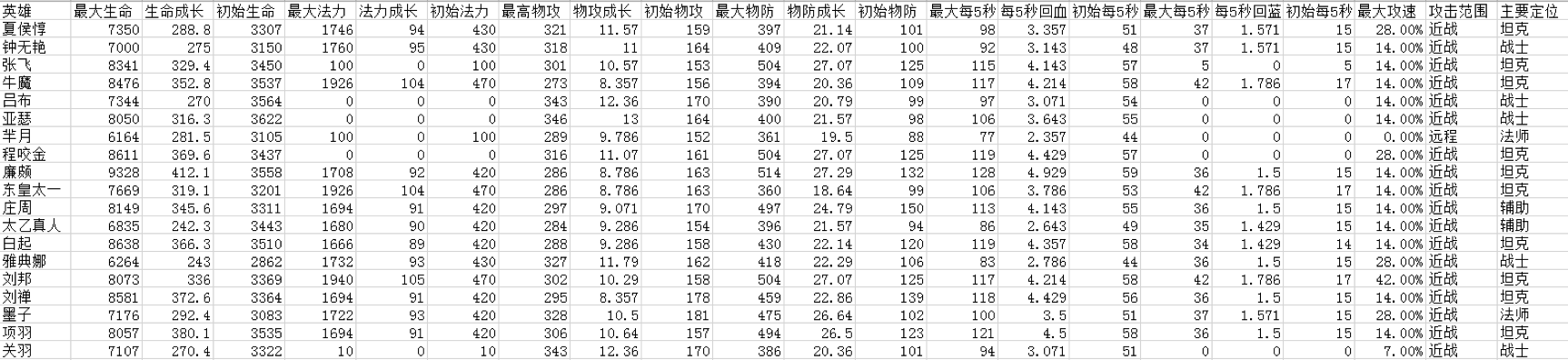
这里我们收集了 69 名英雄的 20 个特征属性,这些属性分别是最大生命、生命成长、初始生命、最大法力、法力成长、初始法力、最高物攻、物攻成长、初始物攻、最大物防、物防成长、初始物防、最大每 5 秒回血、每 5 秒回血成长、初始每 5 秒回血、最大每 5 秒回蓝、每 5 秒回蓝成长、初始每 5 秒回蓝、最大攻速和攻击范围等。
现在我们需要对王者荣耀的英雄数据进行聚类,我们先设定项目的执行流程:
- 首先我们需要加载数据源;
- 在准备阶段,我们需要对数据进行探索,包括采用数据可视化技术,让我们对英雄属性以及这些属性之间的关系理解更加深刻,然后对数据质量进行评估,是否进行数据清洗,最后进行特征选择方便后续的聚类算法;
- 聚类阶段:选择适合的聚类模型,这里我们采用 GMM 高斯混合模型进行聚类,并输出聚类结果,对结果进行分析。
完整代码
```python import pandas as pd import csv import matplotlib.pyplot as plt import seaborn as sns from sklearn.mixture import GaussianMixture from sklearn.preprocessing import StandardScaler from sklearn.metrics import calinski_harabaz_score
import warnings warnings.filterwarnings(‘ignore’)
def load_data():
# 数据加载,避免中文乱码问题data_ori = pd.read_csv('../data/em_data/heros.csv', encoding='gb18030')features = [u'最大生命', u'生命成长', u'初始生命', u'最大法力', u'法力成长', u'初始法力', u'最高物攻', u'物攻成长', u'初始物攻', u'最大物防', u'物防成长',u'初始物防',u'最大每5秒回血', u'每5秒回血成长', u'初始每5秒回血', u'最大每5秒回蓝', u'每5秒回蓝成长', u'初始每5秒回蓝', u'最大攻速', u'攻击范围']data = data_ori[features]plt_headmap(data, features)# 相关性大的属性保留一个,因此可以对属性进行降维features_remain = [u'最大生命', u'初始生命', u'最大法力', u'最高物攻', u'初始物攻', u'最大物防', u'初始物防', u'最大每5秒回血', u'最大每5秒回蓝',u'初始每5秒回蓝',u'最大攻速', u'攻击范围']data = data_ori[features_remain]data[u'最大攻速'] = data[u'最大攻速'].apply(lambda x: float(x.strip('%')) / 100)data[u'攻击范围'] = data[u'攻击范围'].map({'远程': 1, '近战': 0})return data_ori, data
def plt_headmap(data, features):
# 对英雄属性之间的关系进行可视化分析# 设置plt正确显示中文plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 用热力图呈现features_mean字段之间的相关性corr = data[features].corr()plt.figure(figsize=(14, 14))# annot=True显示每个方格的数据sns.heatmap(corr, annot=True)plt.show()
def build_model(data):
# 构造GMM聚类gmm = GaussianMixture(n_components=30, covariance_type='full')return gmm
if name == ‘main‘: data_ori, data = load_data()
# 采用Z-Score规范化数据,保证每个特征维度的数据均值为0,方差为1ss = StandardScaler()data = ss.fit_transform(data)gmm = build_model(data)gmm.fit(data)# 训练数据prediction = gmm.predict(data)print(prediction)# 指标分数越高,代表聚类效果越好,也就是相同类中的差异性小,不同类之间的差异性大。print("Calinski-Harabaz : ",calinski_harabaz_score(data, prediction))# 将分组结果输出到CSV文件中data_ori.insert(0, '分组', prediction)data_ori.to_csv('./hero_out.csv', index=False, sep=',')
运行结果<br />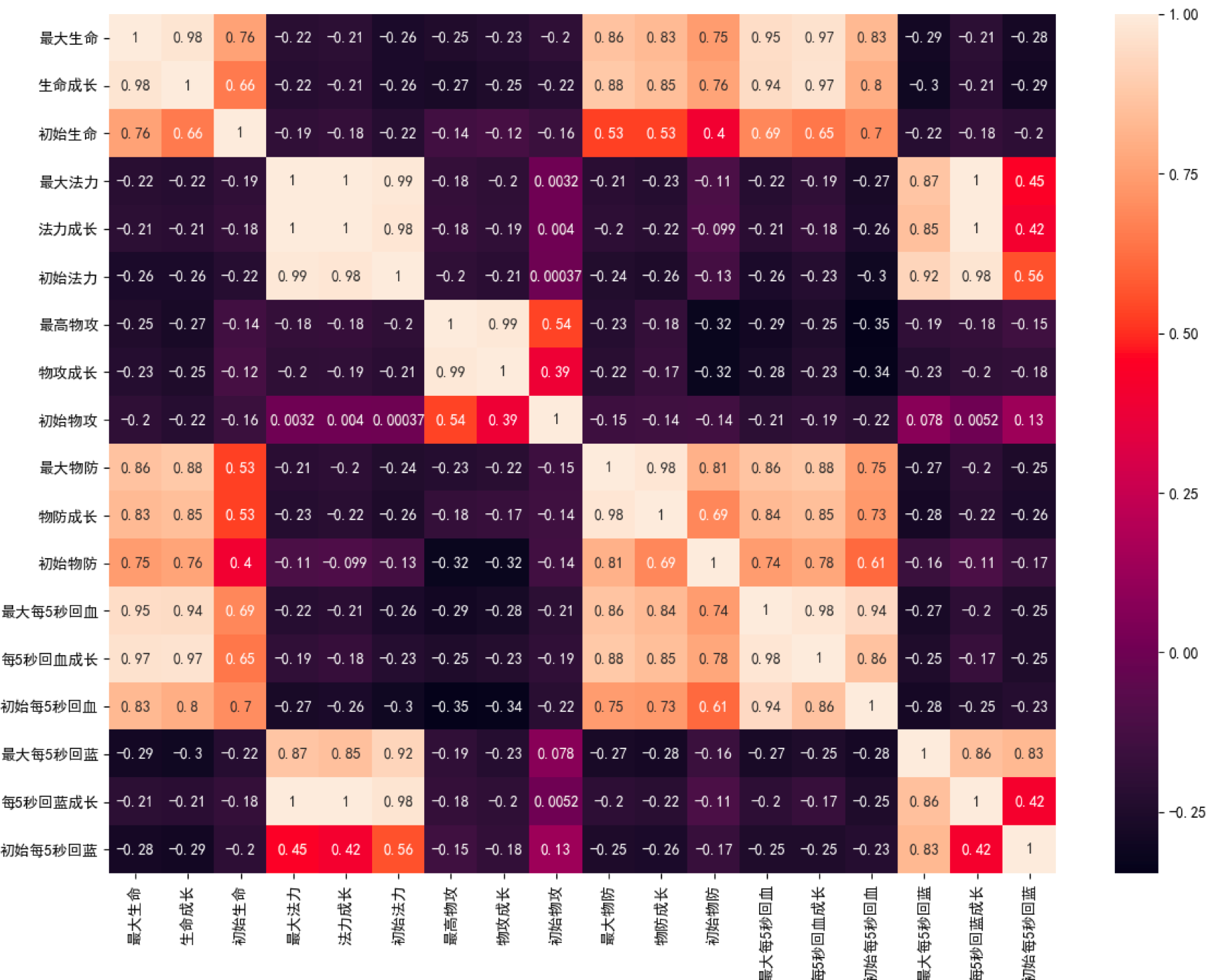```python[28 14 8 9 5 5 15 8 3 14 18 14 9 7 16 18 13 3 5 4 19 12 4 1212 12 4 17 24 2 7 2 2 24 2 2 24 6 20 22 22 24 24 2 2 22 14 2014 24 26 29 27 25 25 28 11 1 23 5 11 0 10 28 21 29 29 29 17]
同时你也能看到输出的聚类结果文件 hero_out.csv(它保存在你本地运行的文件夹里,程序会自动输出这个文件,你可以自己看下)。
聚类评价指标
聚类和分类不一样,聚类是无监督的学习方式,也就是我们没有实际的结果可以进行比对,所以聚类的结果评估不像分类准确率一样直观,那么有没有聚类结果的评估方式呢?这里我们可以采用 Calinski-Harabaz 指标,代码如下:
from sklearn.metrics import calinski_harabaz_scoreprint(calinski_harabaz_score(data, prediction))
指标分数越高,代表聚类效果越好,也就是相同类中的差异性小,不同类之间的差异性大。当然具体聚类的结果含义,我们需要人工来分析,也就是当这些数据被分成不同的类别之后,具体每个类表代表的含义。

若有收获,就点个赞吧
0 人点赞
