正则项
l1正则与l2正则的特点是什么,各有什么优势? - Andy Yang的回答 - 知乎 https://www.zhihu.com/question/26485586/answer/616029832
https://www.cnblogs.com/ying-chease/p/10573356.html
[视频讲解]史上最全面的正则化技术总结与分析—part1 - 深度眸的文章 - 知乎 https://zhuanlan.zhihu.com/p/35429054
加正则项的意义
加正则项,相当于加一个“惩罚项”,不含正则项的损失函数称之为经验风险函数,加了正则化的损失函数被称之为结构风险函数。
为什么加正则项可以防止过拟合
过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
函数的Wi参数越小效果越好;
L1和L2正则化有什么区别
从几何解释:
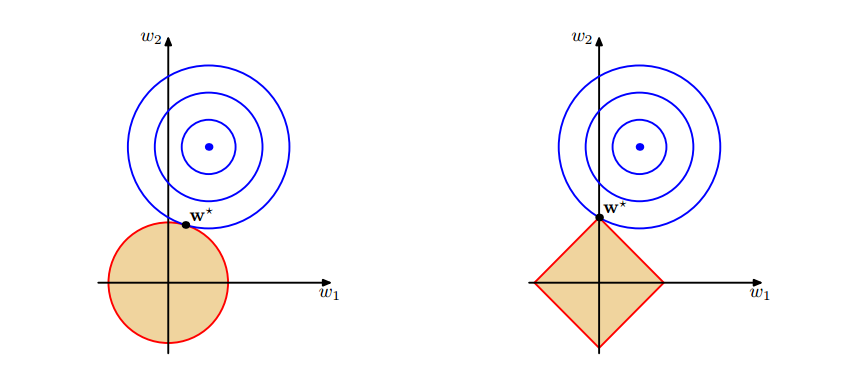
图1 上面中的蓝色轮廓线是没有正则化损失函数的等高线,中心的蓝色点为最优解,左图、右图分别为L2、L1正则化给出的限制。
可以看到在正则化的限制之下,L2正则化给出的最优解 w∗w∗是使解更加靠近原点,也就是说L2正则化能降低参数范数的总和,使得模型的解偏向于 norm 较小的 W,通过限制 W 的 norm 的大小实现了对模型空间的限制,从而在一定程度上避免了 overfitting 。不过 L2正则化并不具有产生稀疏解的能力,得到的系数 仍然需要数据中的所有特征才能计算预测结果,从计算量上来说并没有得到改观。
L1正则化给出的最优解w∗w∗是使解更加靠近某些轴,而其它的轴则为0,所以L1正则化能使得到的参数稀疏化。稀疏的解除了计算量上的好处之外,更重要的是更具有“可解释性”。比如说,一个病如果依赖于 5 个变量的话,将会更易于医生理解、描述和总结规律,但是如果依赖于 5000 个变量的话,基本上就超出人肉可处理的范围了。
因此正则化是通过约束参数的范数使其不要太大,使其在一定程度上减少过拟合情况。

若有收获,就点个赞吧
0 人点赞
