涉及知识:
re模块的使用,字符编码,字典的使用
案例目标:
 ```python
import requests,json,re
```python
import requests,json,reurl = “https://www.dydytt.net/index2.htm“ host = “https://www.dydytt.net“ headers = { “User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36”, “Referer”: “https://www.dydytt.net/“ } domain = requests.get(url,headers=headers) domain.encoding = “gb2312” #字符编码 file = domain.text
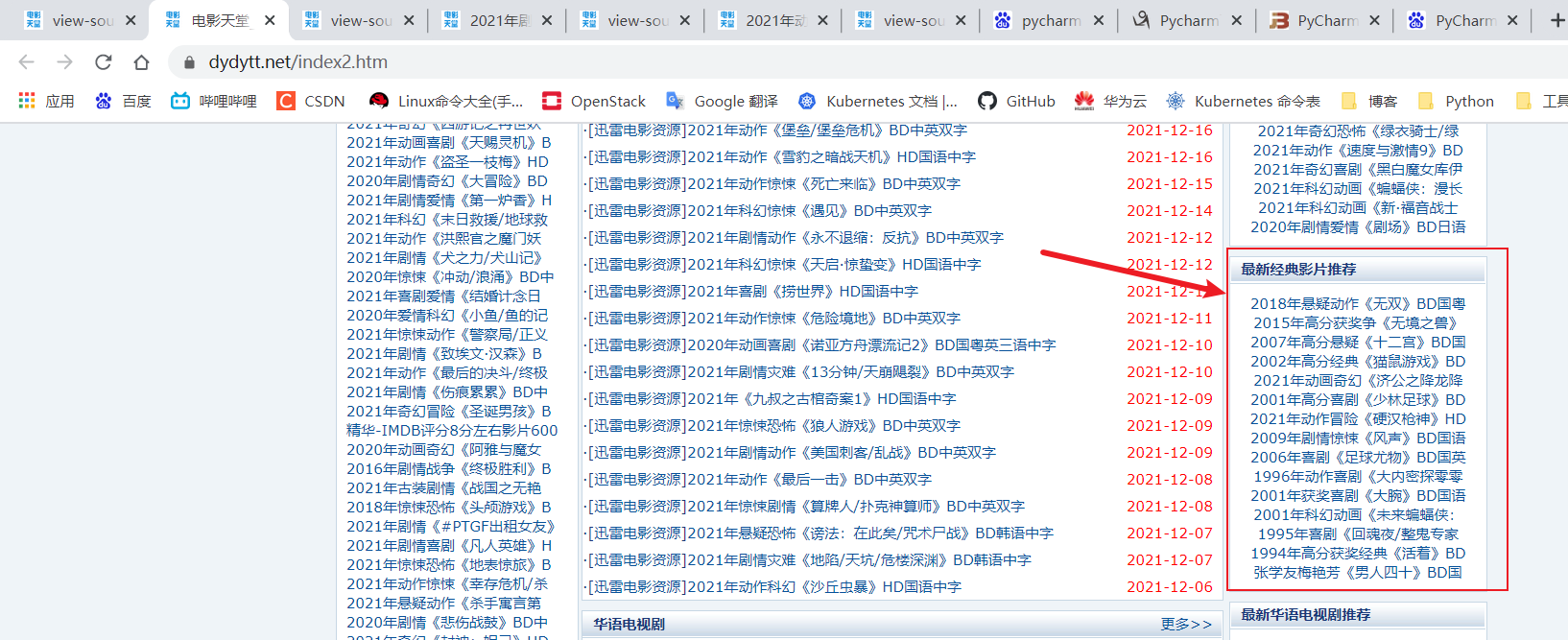
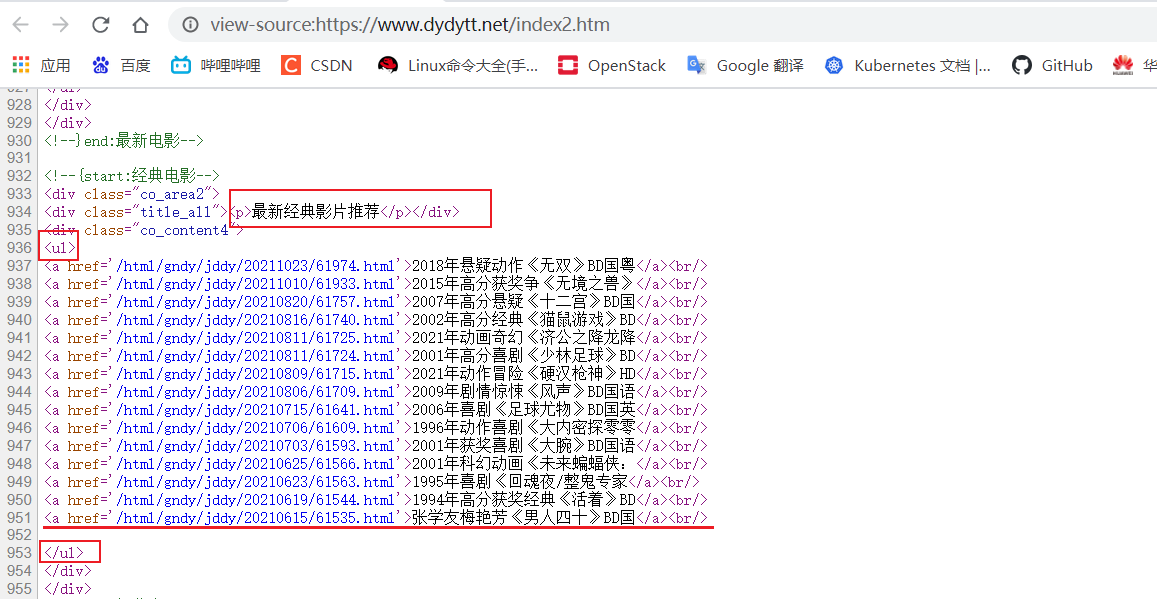
定义获取电影天堂的主页面位置的“最新经典影片推荐”
obj = re.compile(r”最新经典影片推荐.?
- (?P
定位“最新经典影片推荐”内单个电影界面的链接
obj2 = re.compile(r”.*?
“)
list = obj.finditer(file) #将re的compile定义的正则语句,与re.finditer结合对获取的HTML文件进行查找
for i in list:
url = i.group(“url”) #将输出的url再一次使用re模块记性查找
list2 = obj2.finditer(url)
for o in list2:
full_url = host + o.group(“href”) #将链接拼接
print(full_url)
输出效果展示: D:\学习软件工具\pycharm\openstack-api\venv\Scripts\python.exe D:/学习软件工具/pycharm/openstack-api/venv/flavor/pachong002.py https://www.dydytt.net/html/gndy/jddy/20211023/61974.html https://www.dydytt.net/html/gndy/jddy/20211010/61933.html https://www.dydytt.net/html/gndy/jddy/20210820/61757.html https://www.dydytt.net/html/gndy/jddy/20210816/61740.html https://www.dydytt.net/html/gndy/jddy/20210811/61725.html …….
获取到每个电影的页面链接后再次分析页面的下地址<a name="qXdQO"></a># 3.分析单个电影界面源代码分析当页面源代码后通过正则表达式匹配到下载地址<br />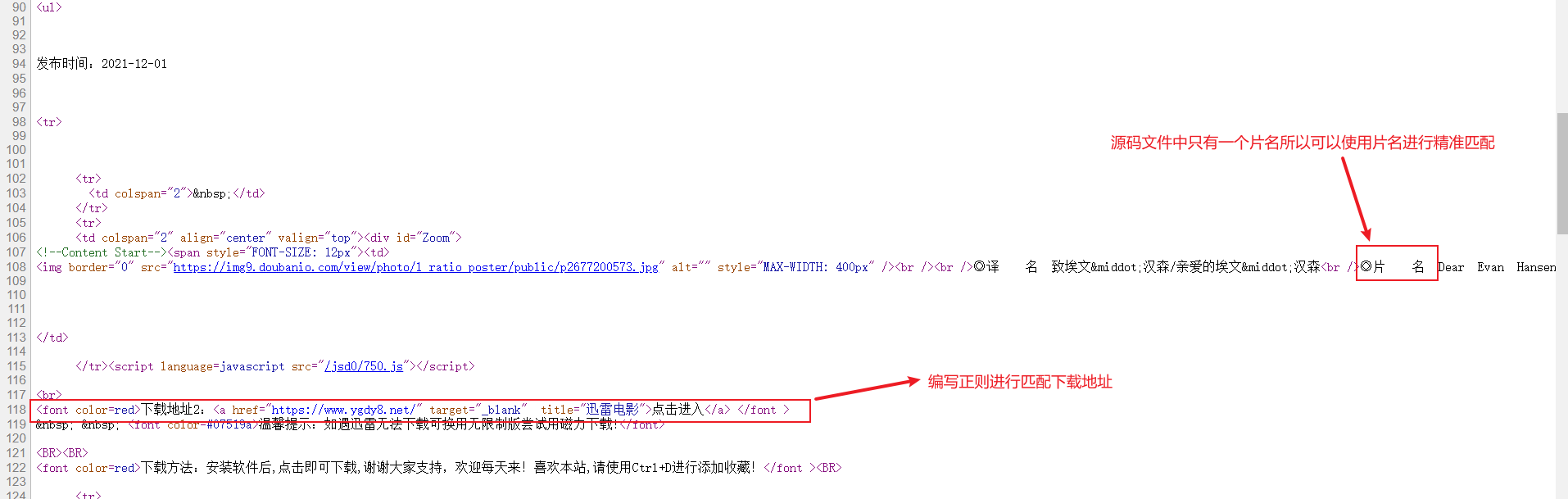```pythonhost = "https://www.dydytt.net"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36","Referer": "https://www.dydytt.net/"}domain = requests.get(url,headers=headers)domain.encoding = "gb2312"file = domain.textobj = re.compile(r"最新经典影片推荐.*?<ul>(?P<url>.*?)</ul>", re.S)obj2 = re.compile(r"<a href='(?P<href>.*?)'>.*?</a><br/>")#匹配单个电影页面下载地址obj3 = re.compile(r'◎片 名 (?P<movie_name>.*?).*?下载地址2:<a href=(?P<movice_download_url>.*?) target="_blank" title="迅雷电影">',re.S)#添加一个空字典movie_url_list = []list = obj.finditer(file)for i in list:url = i.group("url")list2 = obj2.finditer(url)for o in list2:full_url = host + o.group("href")#print(full_url)movie_url_list.append(full_url) #将获取的单个电影页面的链接添加到空字典内for dl in movie_url_list: #将字典内的链接再次遍历取出来rsp = requests.get(dl)rsp.encoding = "gb2312"#print(rsp.text) #这里使用的是re.search模块ll = obj3.search(rsp.text) #通过遍历取出来的单个电影界面通过正则表达式在寻找下载地址print(ll.group("movie_name"))print(ll.group(("movice_download_url")))
输出展示:(由于网页改动所以爬的下载地址是一样的)
D:\学习软件工具\pycharm\openstack-api\venv\Scripts\python.exe D:/学习软件工具/pycharm/openstack-api/venv/flavor/pachong002.py"https://www.ygdy8.net/""https://www.ygdy8.net/"

若有收获,就点个赞吧
0 人点赞
