xpath是什么呢?
xpath是xml路径语言(xml path language),他是一种用来确定xml文档中部分位置语言,xml是一种标准的树状结构
xpath要搞明白两个概念
- 相对路径
- 绝对路径
xpath分析:
- 首先确定一个离要抓取的元素最近的唯一父节点
- 从这个父节点定位直至找到想要的元素
- 在Chrome里调试好利用lxml库来抓取
一般都是通过xpath解析DOM树的时候会使用lxml的etree,可以很方便的从html源码中得到自己想要的内容
- etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成_Element对象。作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法。
- 如果想通过xpath获取html源码中的内容,就要先将html源码转换成_Element对象,然后再使用xpath()方法进行解析。
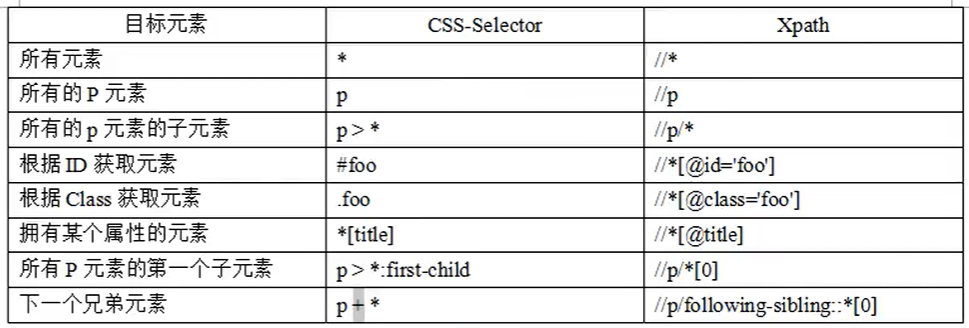
常见相对路径引用
(1)查找页面根元素的表达式为//。
(2)查找页面上所有的 a 元素的表达式为//a
(3)查找页面上 ul 元素下的第一个 li 元素(使用绝对路径表示,用“/”符号)的表达式为// ul / li [1]
(4)查找页面上 ul 元素下的所有子 li 元素(不管嵌套了多少个其他标签,使用相对路径表示,用“//”符号)的表达式为//ul// li 而由于所有 li 元素都是 ul 元素的直接子元素,因此其绝对路径表示的表达式为//ul/ i
(5)查找页面上 ul 元素下的最后一个 li 元素的表达式为//ul// li last()方法,用//ul//li[1]即可获取第一个元素)。
(6)查找页面上第一个 ul 元素的表达式为//ul[1]。如果页面上只有一个 ul 元素,则可以不加后面的索引。
(7)查找页面上 id 属性为 nav 的 div 元素的表达式为//div[@ id =’ nav ‘]
(8)查找页面上 class 属性为 collapse navbar-collapse 的 div 元素的表达式为//div[@class=’collapsenavbar-collappse’]
(9)
xpath的路径以“/”开始表示下xpath解析器从文档的根节点开始解析,当xpath以“//”开始时解析器从任意符合条件的节点开始解析
(10当“/”出现在xpath中表示寻找父节点直接子节点;当“//”出现在xpath路径时表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级
xpath语法
路径表达式
路径表达式/ 根节点,节点分隔符,// 任意位置. 当前节点.. 父级节点
通配符
* 任意元素@* 任意属性node() 任意子节点(元素,属性,内容)
谓语
//a[n] n为大于零的整数,代表子元素排在第n个位置的<a>元素//a[last()] last() 代表子元素排在最后个位置的<a>元素//a[last()-] 和上面同理,代表倒数第二个//a[position()<3] 位置序号小于3,也就是前两个,这里我们可以看出xpath中的序列是从1开始//a[@href] 拥有href的<a>元素//a[@href='www.baidu.com'] href属性值为'www.baidu.com'的<a>元素//book[@price>2] price值大于2的<book>元素
下面来提取http://www.woniuxy.com/中的一个字符串
import requests,jsonfrom lxml import etreeurl = 'http://www.woniuxy.com/'rsp = requests.get(url) #通过url获取网页信息html = etree.HTML(rsp.text) #将获取到的信息转化为HTML格式item = html.xpath("//div[@class='head_left_list']/ul/li[1]/a/span") #通过xpath获取到相应的信息print(type(item)) #查看一下获取内容的类型for i in item: #将获取到的类型以文本类型输出print(i.text)-----------------------------------------------------------------------------------------输出效果C:\Users\井子扬\AppData\Local\Microsoft\WindowsApps\python.exe D:/1-21.py<class 'list'>Java全栈开发
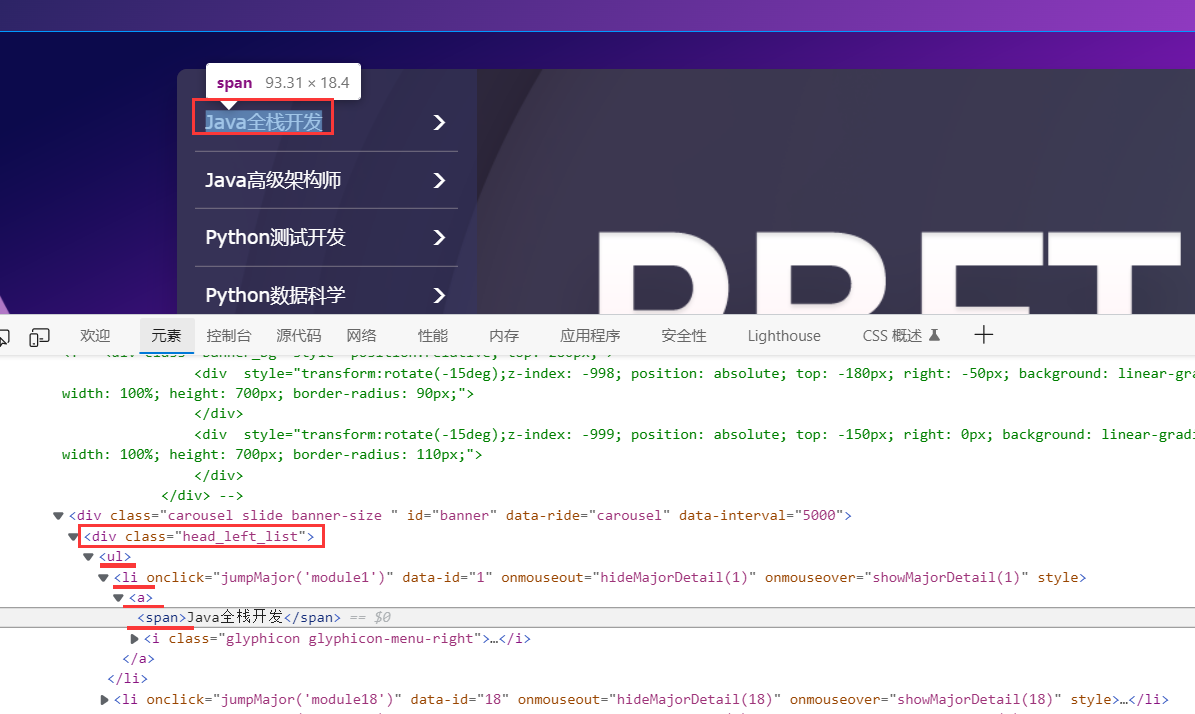
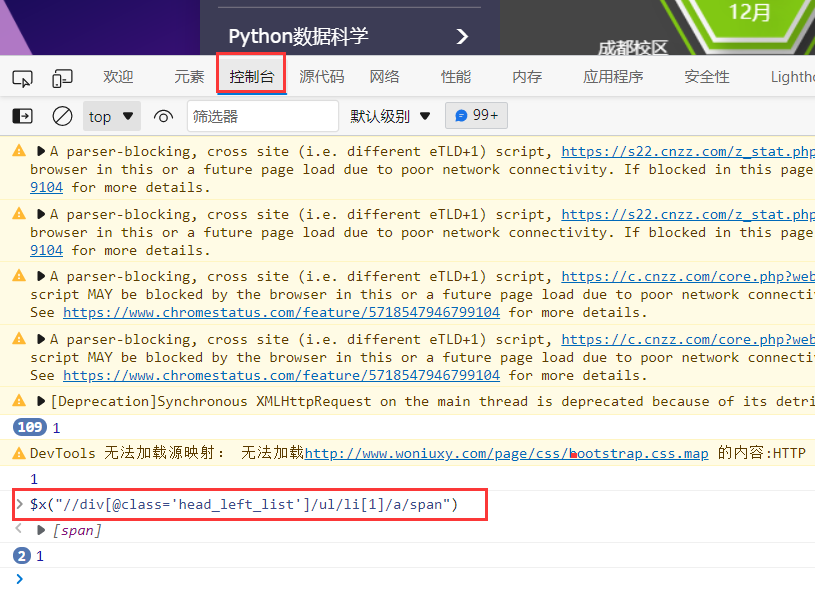
案例:
html文件如下
<!-- hello.html --><div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
按下来,基于上述HTML文档,使用lxml库中的路径表达式技巧,通过调用xpath()方法匹配选取的节点,具体如下:获取任意位置的li节点 可以直接使用“//”从任意位置选取节点li,路径表达式如下:
//li
通过lxml.etree模块的xpath()方法,将hello.html文件中与该路径表达式匹配到的列表返回,并打印输出。具体代码如下:
from lxml import etreehtml=etree.parse('hello.html')# 查找所有的li节点result=html.xpath('//li')# 打印<li>标签的元素集合print(result)# 打印<li>标签的个数print(len(result))# 打印返回结果的类型print(type(result))# 打印第一个元素的类型print(type(result[0]))
程序运行结果如下:
[<Element li at 0x2cc9a48>, <Element li at 0x2cc99c8>, <Element li at 0x2cc9a88>, <Element li at 0x2cc9ac8>, <Element li at 0x2cc9b08>]5<class 'list'><class 'lxml.etree._Element'>
继续获取
在上个表达式的末尾,使用“/”向下选取节点,并使用@选取class属性节点,表达式如下:
//1i/@class
获取
from lxml import etreehtml=etree.parse('hello.html')# 查找位于li标签的class属性result=html.xpath('//li/@class')print(result)
获取倒数第二个元素的内容
从任意位置开始选取倒数第二个
//li[last()-1]/a或者://li[last()-1]/a]/text()
不同的是,第一个表达式需要访问text属性,才能拿到标签的文本,而第二个表达式可直 接获取文本。使用第一 个路径表达式的示例如下:
from lxml import etreehtml=etree.parse('hello.html')# 获取倒数第二个元素的内容result=html.xpath('//li[last()-1]/a')print(result[0].text)
程序运行结果:
fourth item

若有收获,就点个赞吧
0 人点赞
