思路
爬取蜗牛网站下的多个文章
- 找出网站跳转规律 ,一般通过浏览器上的网站变化判断
- 找出对应的xpath路径
- 进到一篇文章内找出想要爬下来的内容
- 组合代码
1.首先爬取网站的所有链接
爬蜗牛网站内多个文档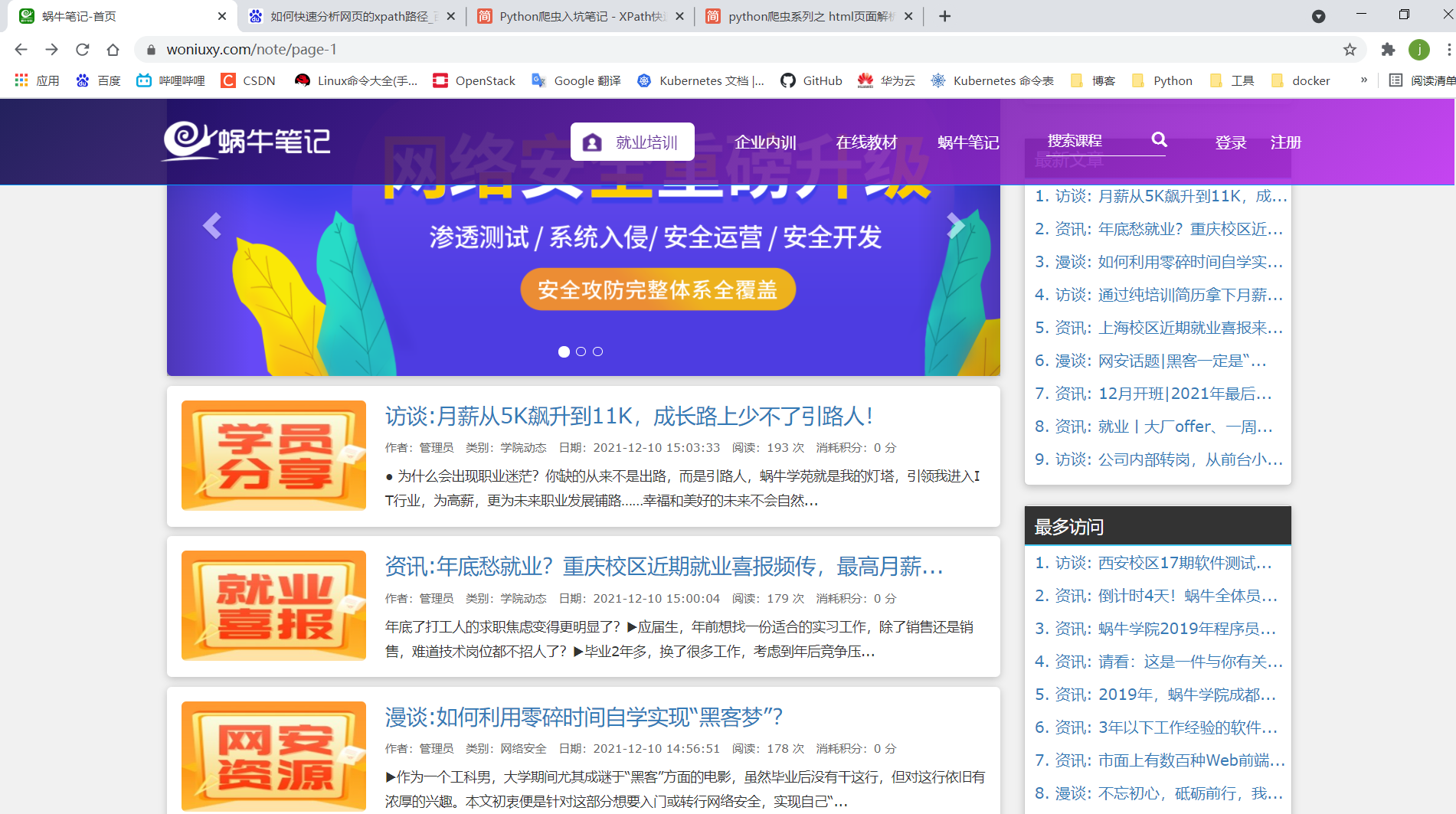
#导入所需的库import requests,jsonfrom lxml import etreefrom bs4 import BeautifulSoupimport refrom urllib.parse import urljoinbase_url = "https://www.woniuxy.com/"url = 'https://www.woniuxy.com/note/page-1' #要爬取的网站headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'}rsp = requests.get(url,headers=headers) #向网站发起请求html = etree.HTML(rsp.text) #将获取的请求用etree中HTML转化为HTML格式woniu_urls = html.xpath('//div[@class="title"]/a') #通过xpath获取所有子链接for url in woniu_urls: #if循环列出爬取的链接full_url = urljoin(base_url, url.get('href')) #将爬取下来的不是完整的链接,所有要合并成完整的链接print(full_url)---------------------------------------------------------------------------------输出效果展示:D:\学习软件工具\pycharm\openstack-api\venv\Scripts\python.exe D:/学习软件工具/pycharm/openstack-api/venv/flavor/flavor003.pyhttps://www.woniuxy.com/note/820https://www.woniuxy.com/note/819https://www.woniuxy.com/note/818.................
2.抓取每篇文章的作者等信息
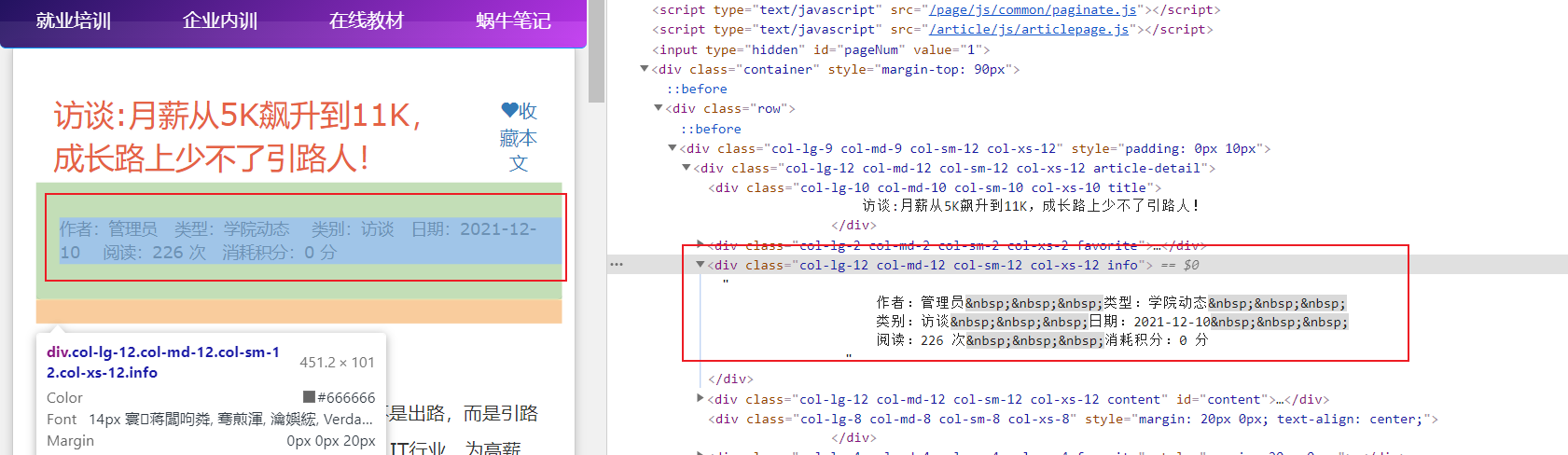
import requests,jsonfrom bs4 import BeautifulSoupfrom lxml import etreeimport reurl = "https://www.woniuxy.com/note/820"r = requests.get(url)html = etree.HTML(r.text)titl_obj = html.xpath("//div[contains(@class, 'info')]")[1]#titl_obj = html.xpath("/html/body/div[8]/div/div[1]/div[1]/div[3]/@class")result = re.findall('作者:(.*?)\s+类型:(.*?)\s+.*日期:(.*?)\s+阅读:(.*?)次', titl_obj.text, re.S)(user, type, date, read_num) = result[0]print("作者:" + user)print("类型:" + type)print("时间:" + date)print("阅读次数:" + read_num)-------------------------------------------------------------------------------------输出展示:D:\学习软件工具\pycharm\openstack-api\venv\Scripts\python.exe D:/学习软件工具/pycharm/openstack-api/venv/pachong/pachong001.py作者:管理员类型:学院动态时间:2021-12-10阅读次数:225

若有收获,就点个赞吧
0 人点赞
