使用re模块+正则来爬取豆瓣网中电影数据
这次通过正则表达式来匹配网页源代码进行爬取
涉及知识:
re模块的使用,正则表达式的使用,字典打包,CVS的使用
1.分析网页结构
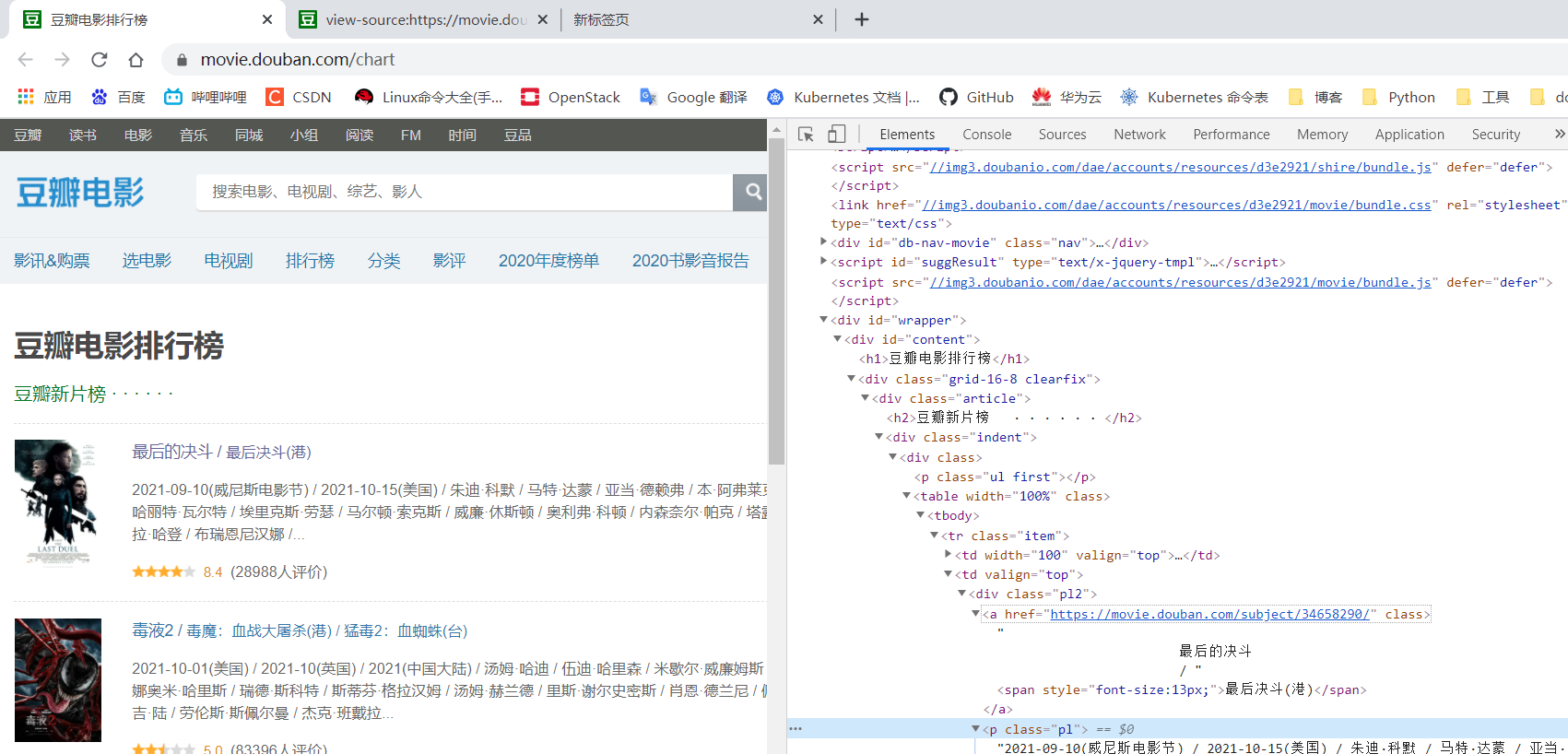
通过查看网页源代码发现可以通过tr标签开始进行进入
想要爬取的数据有电影名称,导演演员,豆瓣平分等信息,明确信息在源代码中的位置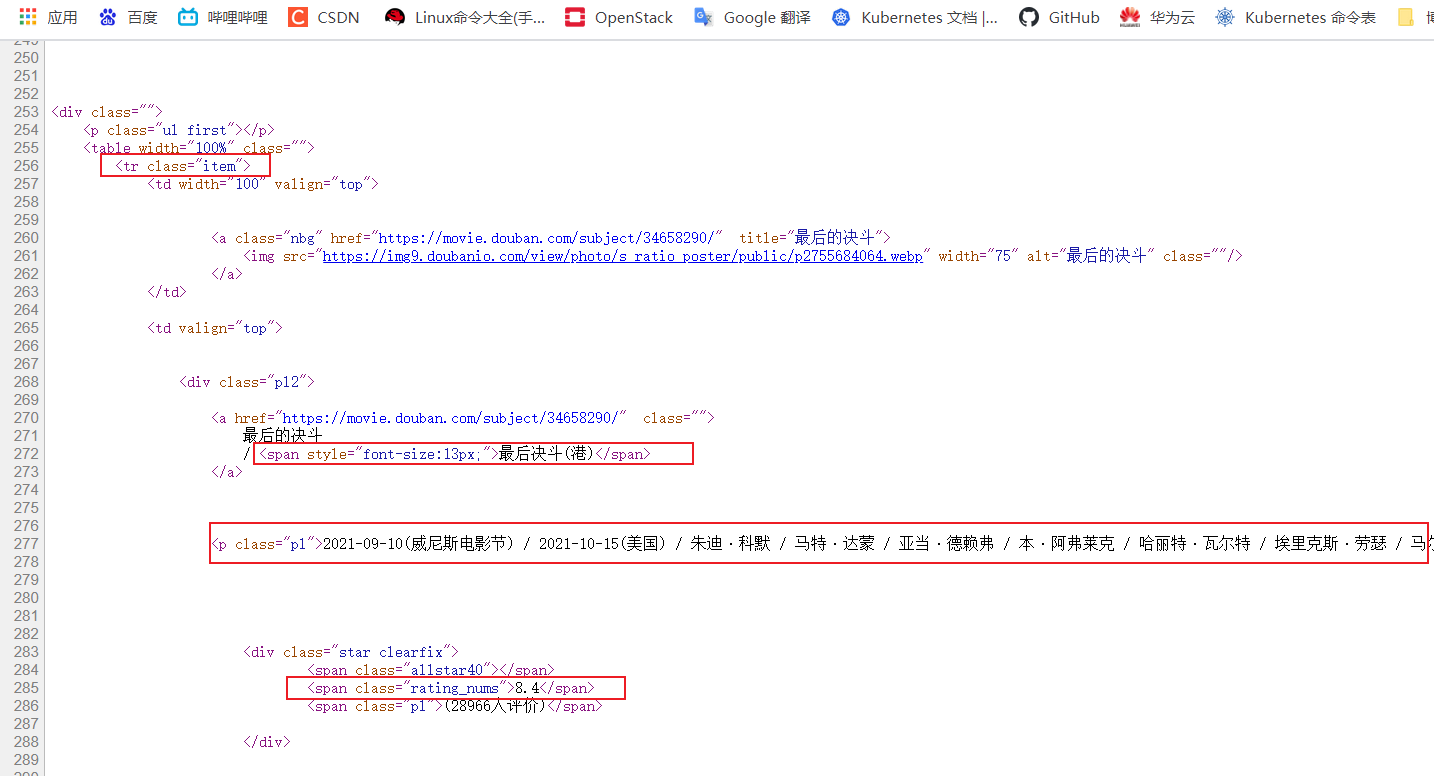
2.编写程序+调试正则表达式
import re,requests,json,csvurl = "https://movie.douban.com/chart"headers= {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}rsp = requests.get(url,headers=headers)file = rsp.text#定义一个re.compile,重要的是对源代码的寻找obj = re.compile(r'<tr class="item">.*?<span style="font-size:13px;">(?P<name>.*?)</span>.*?'r'<span class="rating_nums">(?P<num>.*?)</span>.*?'r' <p class="pl">(?P<data>.*?)</p>',re.S)#利用re.compile查找内容s = obj.finditer(file)#查找出来的是迭代对象所以要循环列出for i in s:print(i.group("name"))print(i.group("num"))print(i.group("data"))print("over")
输出展示:
D:\学习软件工具\pycharm\openstack-api\venv\Scripts\python.exe D:/学习软件工具/pycharm/openstack-api/venv/flavor/re_mokuai.py最后决斗(港)8.42021-10-01(美国) / 2021-10(英国) / 2021(中国大陆) / 汤姆·哈迪 / 伍迪·哈里森 / 米歇尔·威廉姆斯 / 娜奥米·哈里斯 / 瑞德·斯科特 / 斯蒂芬·格拉汉姆 / 汤姆·赫兰德 / 里斯·谢尔史密斯 / 肖恩·德兰尼 / 佩吉·陆 / 劳伦斯·斯佩尔曼 / 杰克·班戴拉...滴答,滴答……轰隆隆 / 梦想期限(港)8.32021-11-05(美国) / 汤姆·汉克斯 / 卡赖伯·兰德里·琼斯 / 希默斯 / 洛拉·玛汀内斯-康宁安 / 玛丽·瓦根曼 / 斯基特·乌尔里奇 / 萨米拉·威利 / 美国 / 米格尔·萨普什尼克 / 115分钟 / 芬奇 / 剧情 / 科幻 / 克雷格·勒克 Craig Luck / Ivor Powell...眼见为虚 / Knock Knock6.7.........
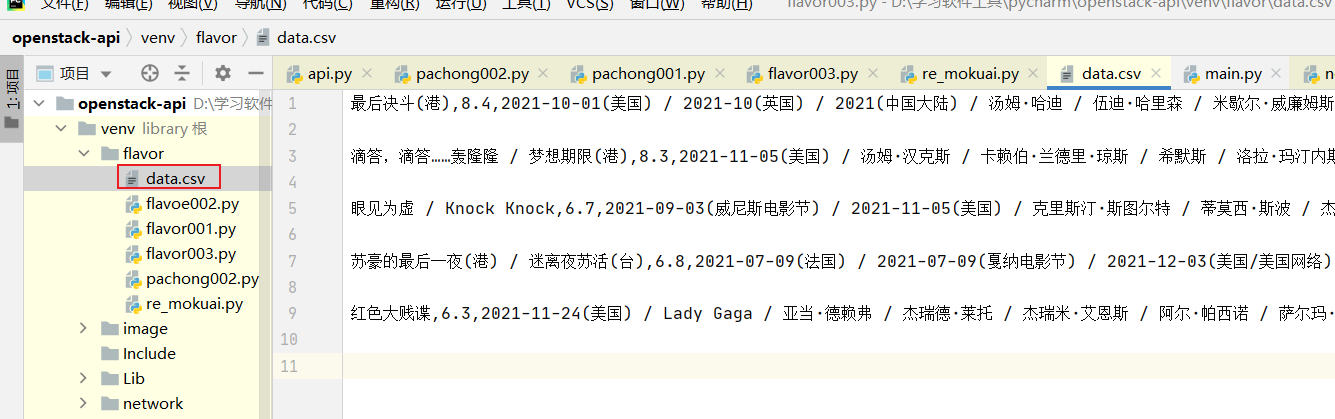
3.将爬取的数据打包成CSV数据
将爬取的数据封装成字典并导入到csv文件中
import re,requests,json,csvurl = "https://movie.douban.com/chart"headers= {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"}rsp = requests.get(url,headers=headers)file = rsp.textobj = re.compile(r'<tr class="item">.*?<span style="font-size:13px;">(?P<name>.*?)</span>.*?'r'<span class="rating_nums">(?P<num>.*?)</span>.*?'r' <p class="pl">(?P<data>.*?)</p>',re.S)s = obj.finditer(file)#创建一个名称为data.csv的文件,模式为write,字符编码为UFF-8f = open("data.csv",mode="w",encoding="utf-8")#再往csvwrite内写东西的时候就会写到csv.writeer(f)内csvwrite = csv.writer(f)for i in s:#将获取的数据 i 封装成字典 dicdic = i.groupdict()csvwrite.writerow(dic.values()) #把字典dis的值数据都写入到csvwrite内用weiteow,把字典内的values写入出去f.close() #把打开的文件关掉print("over")

若有收获,就点个赞吧
0 人点赞
