环境说明
| name | ip | 备注 |
|---|---|---|
| redis1 | 192.168.44.100 | 主节点 |
| redis2 | 192.168.44.200 | 从节点 |
redis服务介绍
(1)Redis 简介
Remote Dictionary Server(Redis)远程字典服务器是完全开源免费的,用 C 语言编写的,遵守 BSD 开源协议,是一个高性能的(key/value)分布式内存数 据库,基于内存运行,并支持持久化的 NoSQL 数据库,它也通常被称为数据结构 服务器,因为值(value)可以是字符串(String),哈希(Map),列表(list), 集合(sets)和有序集合(sorted sets)等类型。 与传统数据库不同的是 Redis 的数据是存在内存中的,所以存写速度非常快, 因此 Redis 被广泛应用于缓存方向。Redis 为分布式缓存,在多实例的情况下, 各实例共用一份缓存数据,缓存具有一致性。 Redis 与其他 key-value 缓存
产品有以下三个特点: ① Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时 候可以再次加载进行使用。 ② Redis有丰富的数据类型,Redis不仅仅支持简单的key-value类型的数据, 同时还提供 Strings、Lists、Hashes、Sets 及 Ordered Sets 等数据结构的存储。 ③ Redis 支持数据的备份,即 master-slave 模式的数据备份。 (2)Redis 使用场景 Redis 使用场景,查询出的数据保存到 Redis 中,下次查询的时候直接从 Redis 中拿到数据。不用和数据库进行交互。用户访问 Redis 缓存如图 1-1 和图 1-2 所 示。 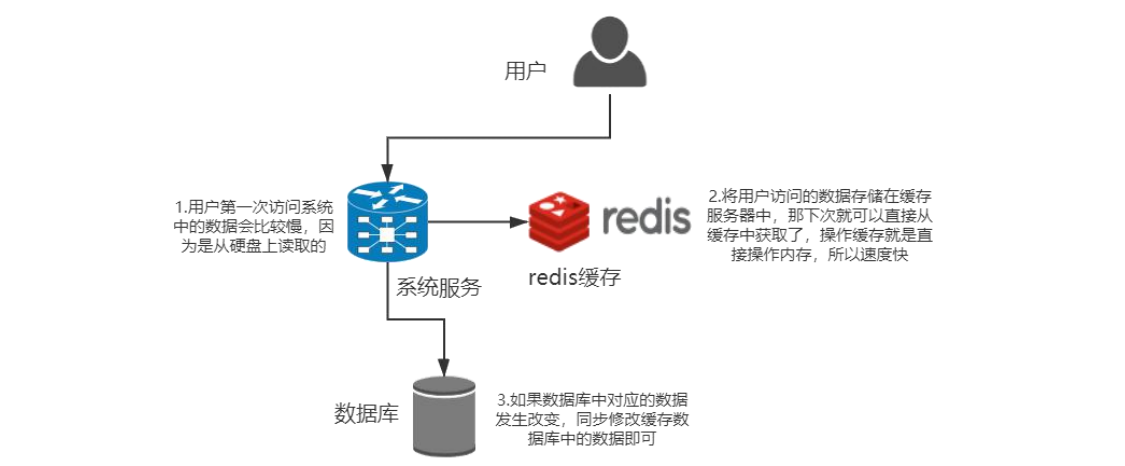
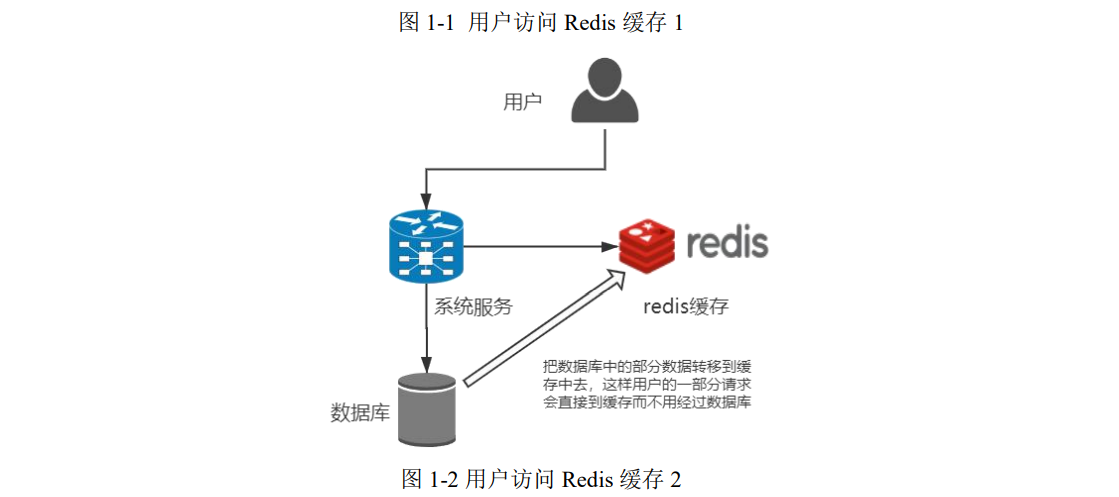
什么数据会存到 Redis 数据库中?主要是热点数据,不会经常改变的,一般 是常量。比如登录验证的 Cookie,购物车,历史浏览记录。(只要具有一定时 间的生命周期)比如首页的商品信息,一般不会变。比如秒杀的商品信息,一般 也不会变。比如地图的经纬度信息,一般也不会变。 用户的关注列表,粉丝列表,消息列表等功能都可以用 Redis 的 List 结构来 实现。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能(Set 类似与列表,但可自动排重的)。 Redis不但提供了无需集合(Sets),还很体贴的提供了有序集合(Sorted Sets), 因此,各种排行榜数据基本上都会使用 Redis 提供的 Sorted Sets 来实现
(3)Redis 的优势
① 性能极高——Redis 能读的速度是 110000 次/s,写的速度是 81000 次/s 。 ② 丰富的数据类型——Redis 支持二进制案例的 Strings、Lists、Hashes、Sets 及 Ordered Sets 数据类型操作。 ③ 原子性——Redis 的所有操作都是原子性的,意思就是要么成功执行要么 失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。 ④ 丰富的特性——Redis 还支持 publish/subscribe、通知、key 过期等特性。
(4)为什么要使用 Redis
有 memcached 使用经验的读者可能知道,用户只能用 APPEND 命令将数据 添加到已有字符串的末尾。memcached 的文档中声明,可以用 APPEND 命令来 管理元素列表。用户可以将元素追加到一个字符串的末尾,并将那个字符串当作 列表来使用。但随后如何删除这些元素呢?memcached 采用的办法是通过黑名单 (blacklist)来隐藏列表里面的元素,从而避免对元素执行读取、更新、写入(包 括在一次数据库查询之后执行的 memcached 写入)等操作。相反地,Redis 的 LIST 和 SET 允许用户直接添加或者删除元素。 使用 Redis 而不是 memcached 来解决问题,不仅可以让代码变得更简短、更 易懂、更易维护,而且还可以使代码的运行速度更快(因为用户不需要通过读取 数据库来更新数据)。除此之外,在其他许多情况下,Redis 的效率和易用性也 比关系数据库要好得多。 数据库的一个常见用法是存储长期的报告数据,并将这些报告数据用作固定 时间范围内的聚合数据(aggregates)。收集聚合数据的常见做法是:先将各个 行插入一个报告表里面,之后再通过扫描这些行来收集聚合数据,并根据收集到 的聚合数据来更新聚合表中已有的那些行。之所以使用插入行的方式来存储,是 因为对于大部分数据库来说,插入行操作的执行速度非常快(插入行只会在硬盘 文件末尾进行写入)。不过,对表里面的行进行更新却是一个速度相当慢的操作 因为这种更新除了会引起一次随机读(random read)之外,还可能会引起一次随 机写(random write)。而在 Redis 里面,用户可以直接使用原子的(atomic)INCR 命令及其变种来计算聚合数据,并且因为 Redis 将数据存储在内存里面,而且发 送给 Redis 的命令请求并不需要经过典型的查询分析器(parser)或者查询优化 6 器(optimizer)进行处理,所以对 Redis 存储的数据执行随机写的速度总是非常 迅速的。 使用 Redis 而不是关系数据库或者其他硬盘存储数据库,可以避免写入不 必要的临时数据,也免去了对临时数据进行扫描或者删除的麻烦,并最终改善程 序的性能。
redis主从服务介绍
(1)什么是主从复制
和 MySQL 主从复制的原因一样,Redis 虽然读取写入的速度都特别快,但 是也会产生读压力特别大的情况。为了分担读压力,Redis 支持主从复制,Redis 的主从结构可以采用一主多从或者级联结构,Redis 主从复制可以根据是否是全 量分为全量同步和增量同步。
(2)什么是全量同步
Redis 全量复制一般发生在 Slave 初始化阶段,这时 Slave 需要将 Master 上 的所有数据都复制一份。具体步骤如下: ① 从服务器连接主服务器,发送 SYNC 命令; ② 主服务器接收到 SYNC 命名后,开始执行 BGSAVE 命令生成 RDB 文件 并使用缓冲区记录此后执行的所有写命令; ③ 主服务器 BGSAVE 执行完后,向所有从服务器发送快照文件,并在发送 期间继续记录被执行的写命令; ④ 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照; ⑤ 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令; ⑥ 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器 缓冲区的写命令。 完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此 时可以接收来自用户的读请求。
(3)什么是增量同步
Redis 增量复制是指 Slave 初始化后开始正常工作时主服务器发生的写操作 同步到从服务器的过程。 增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相 同的写命令,从服务器接收并执行收到的写命令。
(4)主从同步策略
Redis 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。 当然,如果有需要,slave 在任何时候都可以发起全量同步。Redis 策略是,无论 如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
注意: 如果多个 Slave 断线了,需要重启的时候,因为只要 Slave 启动,就会发送 sync 请求和主机全量同步,当多个同时出现的时候,可能会导致 Master IO 剧 增宕机。 Redis 主从复制的配置十分简单,它可以使从服务器是主服务器的完全拷贝。
(5)需要清除 Redis 主从复制的几点重要内容:
① Redis 使用异步复制。但从 Redis 2.8 开始,从服务器会周期性的应答从 复制流中处理的数据量。 ② 一个主服务器可以有多个从服务器。 ③ 从服务器也可以接受其他从服务器的连接。除了多个从服务器连接到一 个主服务器之外,多个从服务器也可以连接到一个从服务器上,形成一个树状结 构。 ④ Redis 主从复制不阻塞主服务器端。也就是说当若干个从服务器在进行初 始同步时,主服务器仍然可以处理请求。 ⑤ 主从复制也不阻塞从服务器端。当从服务器进行初始同步时,它使用旧 版本的数据来应对查询请求,假设你在 redis.conf 配置文件是这么配置的。否则 的话,你可以配置当复制流关闭时让从服务器给客户端返回一个错误。但是,当 初始同步完成后,需要删除旧的数据集和加载新的数据集,在这个短暂的时间内, 从服务器会阻塞连接进来的请求。 ⑥ 主从复制可以用来增强扩展性,使用多个从服务器来处理只读的请求(比 如,繁重的排序操作可以放到从服务器去做),也可以简单的用来做数据冗余。 ⑦ 使用主从复制可以为主服务器免除把数据写入磁盘的消耗:在主服务器 的 redis.conf 文件中配置“避免保存”(注释掉所有“保存”命令),然后连接 8 一个配置为“进行保存”的从服务器即可。但是这个配置要确保主服务器不会自 动重启。
1.安装redis服务
配置好yum源后直接使用yum下载(其他方法也行,注意两台主机是相同版本号)
[root@redis1 ~]# yum install -y redis[root@redis2 ~]# yum install -y redis
2.配置主节点
redis的主配置文件是/etc/redis.conf
修改主配置文件的思路是:
- 将本地循环
- 取消受保护模式
- 开启守护进程
- 添加redis访问密码
- masterauth这个值为主库的密码,设置主库与当前密码同步保证从库提升为主库(主节点认证密码)
- 打开AOF持久化
```
vi /etc/redis.conf
bind 127.0.0.1 #添加成注释
protected-mode no #取消受保护模式
daemonize yes
requirepass foobared #设置redis访问密码
requirepass “000000”
masterauth #设置master认证密码
masterauth “000000”
appendonly yes #开启AOF持久化
配置完成后重启服务
[root@redis1 ~]# systemctl restart redis
<a name="rz6HW"></a># 3.配置从节点修改从节点的思路是:1. 取消本地循环1. 取消受保护模式1. 开启守护进程1. 添加redis访问密码1. 添加主节点信息1. 添加masterauth认证密码1. 打开AOF 持久化
vi /etc/redis.conf
bind 127.0.0.1 #添加成注释
protected-mode no #取消受保护模式
daemonize yes
requirepass foobared #设置redis访问密码
requirepass “000000”
主节点ip 主节点端口
slaveof 192.168.44.100 6379 #在配置文件中添加这样一行格式的内容
masterauth #设置master认证密码
masterauth “000000”
appendonly yes #开启AOF持久化
配置完成后重启服务
[root@redis1 ~]# systemctl restart redis
<a name="bzcFg"></a># 验证:在主节点上查看配置情况
[root@redis1 ~]# redis-cli 127.0.0.1:6379> info replication
Replication
role:master connected_slaves:1 #此处已经显示链接一个 slave0:ip=192.168.44.200,port=6379,state=online,offset=182,lag=0 master_replid:ed7ae25b14a8658cd910d20091b87b8b4928a737 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:182 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:182 127.0.0.1:6379> 127.0.0.1:6379> set name hello-word #在主节点上添加一个名字 OK 127.0.0.1:6379> get name “hello-word”
在从节点查看配置情况
[root@redis2 ~]# redis-cli 127.0.0.1:6379> auth 000000 OK 127.0.0.1:6379> info replication
Replication
role:slave master_host:192.168.44.100 #主节点ip已经连接上 master_port:6379 master_link_status:up #up状态 master_last_io_seconds_ago:7 master_sync_in_progress:0 slave_repl_offset:42 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:ed7ae25b14a8658cd910d20091b87b8b4928a737 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:42 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:42 127.0.0.1:6379> get name #在从节点上课看到这个name “hello-word” 127.0.0.1:6379> exit ``` 这样redis主从就配置成功了

若有收获,就点个赞吧
0 人点赞
