HTTP的原理与工作机制
为什么我们要深入理解HTTP协议呢?在互联网的时代,网络之间的传输就是靠HTTP协议进行应用层的传输,完成从客户端到服务端的一系列的流程。在工作中经常和HTTP打交道:例如HTTPS为什么是安全的、HTTP的运行机制、TCP/IP协议、通过JSON传递数据等等。
HTTP(HyperText Transfer Protocol) 超文本传输协议,HTTP协议最早的设计是用于Web浏览器上用户Web文档的传输协议,主要解决文本传输的难题,到现在HTTP协议已经超出了Web这个框架的局限,被运用到各种场景里。
- 超文本:就是HTML
- Transfer Protocol:传输协议会找到对应的HTML文本
HTTP最直观的表现例如:https://github.com/ 就是展示GITHUB页面(HTML)
那么在HTTP协议中客户端请求访问文本或图像等资源的一端;服务端提供资源响应的一端.
HTTP 协议规则
HTTP协议是按照一定的规则进行请求和响应,分别是请求报文和响应报文。请求报文是由客户端进行发送,响应报文是由服务端进行发送。
请求报文:请求方法、请求URI、协议版本、可选的请求首部字段(Header)、内容实体(Body)构成
例如请求:http:api.github.com/user?gender=male 使用了POST进行请求
请求行:方法 URI 协议版本
POST /user HTTP/1.1
请求首部字段: (关于首部字段的各个含义和作用在后面详细讲解)
Host:api.github.comConnection: keep-aliveContent-Type: application/x-www-form-urlencodedContent-Length:11
内容实体:
gender=male
响应报文:协议版本、状态码(表示请求成功或失败的数字代码)、状态码原因短语(状态信息)、可选的响应首部字段、实体内容构成
响应行:协议版本 状态码 状态码信息
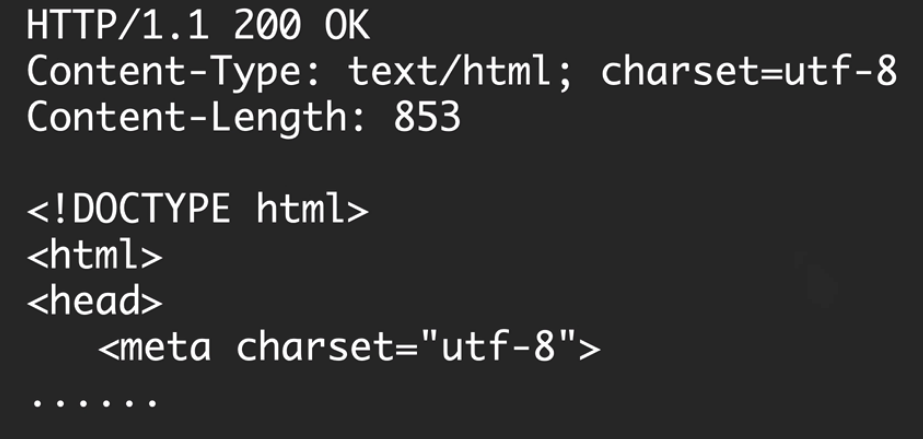
HTTP/1.1 200 OK
响应首部字段:
Date: Tue, 10 Jul 2012 01:10:01Content-Length: 362Content-Type: text/html
内容实体:(HTML会被浏览器进行渲染)
<html>......
HTTP的请求方法和状态码
请求方法
在Android开发中经常会通过GET、POST等请求方法进行请求,那么在HTTP协议中每个请求方法的作用是什么呢?通过Retrofit的具体的例子来了解HTTP的请求方法
例如在Retrofit中经常会遇到如下的方式:
- GET请求
@Path 和 @Query有什么区别呢?
@GET("group/{id}/users")//group/1/userCall<List<User>> groupList(@Path("id") int groupId);@GET("group/{id}/users")//group/1/users?sort=1Call<List<User>> groupList(@Path("id") int groupId, @Query("sort") String sort);
- POST请求
@FormUrlEncoded 是起到了什么作用
@Body 和 @Field 有什么区别
@POST("users/new")Call<User> createUser(@Body User user);@FormUrlEncoded@POST("user/edit")Call<User> updateUser(@Field("first_name") String first, @Field("last_name") String last);
- 上传文件
@Multipart 起到了什么作用,@Part 是干什么的?
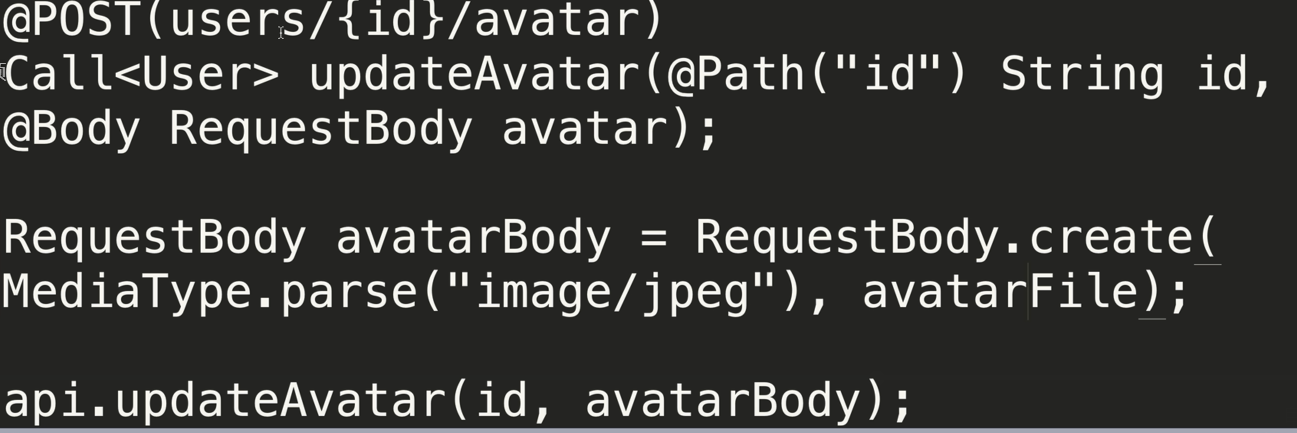
@Multipart@PUT("user/photo")Call<User> updateUser(@Part("photo") RequestBody photo, @Part("description") RequestBody description);
首先将请求方法,关于注解的含义在Content-Type的内容进行讲解。
| 请求方法 | 作用 |
|---|---|
| GET | 获取资源,没有Body,当给GET请求传递Body是Retrofit会给出提示,具有幂等性(无论获取多少次结果是不变的) |
| POST | 增加/修改资源,有Body,不具有幂等性 |
| PUT | 修改资源,有Body,具有幂等性 |
| DELETE | 删除资源,没有Body,具有幂等性 |
| HEAD | 请求和GET一致,响应没有Body,作用:提前感知资源,例如进行下载某个资源,通过head请求,下查询资源信息,在header中返回,判断资源状态是否进行下载 |
状态码
HTTP 状态码负责表示客户端HTTP请求的返回结果、标记服务器端的处理是否正常、通知出现的错误等工作。状态码非常多有60余种,没有必要全部记住,只需要记住状态的类别即可。
| 类别 | 原因短语 | |
|---|---|---|
| 1XX | 信息性状态码 | 表示临时性的消息,接收的请求正在处理。例如101:协议切换当请求可选首部字段设置了Upgrade: h2c 询问是否支持HTTP2.0,如果支持则返回101进行协议切换到HTTP2.0版本,不支持则正常请求。100 表示客户端没有发送完毕继续发送,可以用于向服务器发送大文件 |
| 2XX | 成功状态码 | 表示请求正常处理完毕,常见的有200、204服务器处理成功,但是返回的响应报文中不含实体的主体部分例如浏览器对于204状态不会进行页面更新,适用于只需要通知服务器的业务、206 客户端进行了范围请求响应报文中包含了Content-Range指定范围的实体内容 |
| 3XX | 重定向状态码 | 需要进行附加操作以完成请求 |
| 4XX | 客户端错误状态码 | 服务器无法处理请求,例如常见的404服务器没有请求的资源、401认证错误、400请求报文中存在语法错误、403 请求资源的访问被服务器拒绝了 |
| 5XX | 服务器错误状态码 | 服务器处理请求出错,常见的500错误、503 服务器暂时处于超负载或正在进行停机维护 |
Header&Body
Header: HTTP 消息的元数据(metadata 数据里面的数据,关于数据的数据)
host: 目标主机地址
GET /users/1/ HTTP/1.1Host: api.github.DNS 查询 Domain Name System 域名(Host: api.github.com)系统,DNS服务器通过域名查找对应的IP地址
Content-Length: 内容的长度(字节)- POST /user/1 HTTP/1.1
- Host: api.github.com
- Content-Length: 21 (Body的长度)
- Body: name=jake&gender=male (可以传递二进制数据,而不是以某个符号作为结束符,在发送之前计算发送内容的长度)
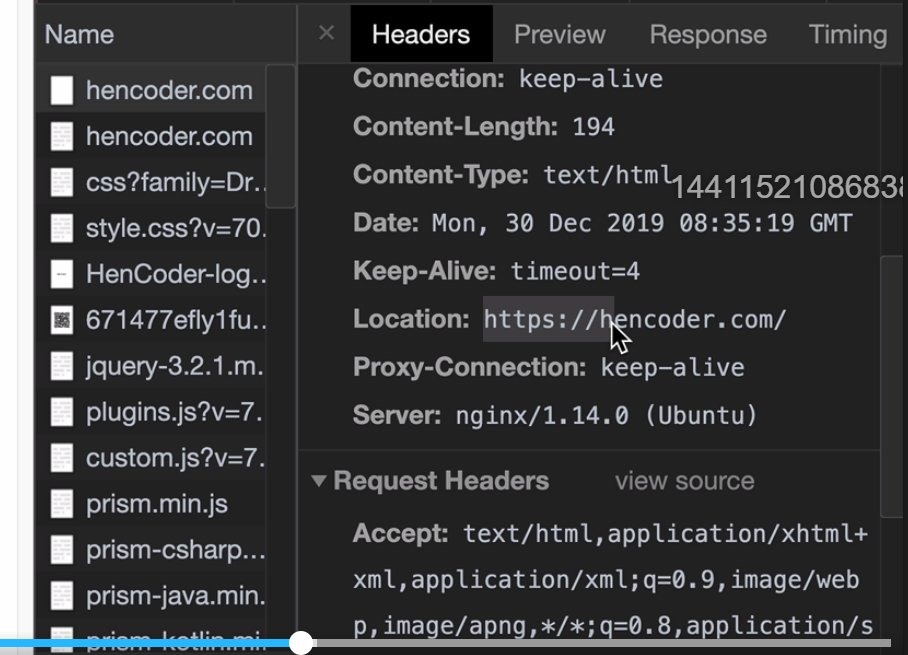
Location: 重定向目标的URLuser-agent: 用户代理Transfer-Encoding:chunked分块传输编码,不知道Content-Length 的内容长度- Body长度无法确定,Content-Length不能使用

Range/Accept-Range: 分段加载,指定body的内容范围- Range: bytes=0-1111 分段加载 实现断点续传,指定Body的内容范围
- Accept-Ranges : bytes 支持分段加载
- Content-Ranges: bytes 0-2323232
Cookie/Set-Cookie: 发送Cookie/设置CookieCache: Cache和Buffer的区别,Cache缓存、Buffer缓冲针对工作流 上流和下流Accept-Charset: 客户端接受的字符集。如utf-8Accept-Encoding: 客户端接受的压缩编码类型。如gzipContent-Encoding:压缩类型。如gzipContent-Type: 内容的类型text/html: html文本,用于浏览器页面响应 如下:application/x-www-form-urlencoded: 普通表单就是HTML中的 标签,encoded URL 格式- 在Retrofit中使用:
@FormUrlEncoded和@Field进行配合使用 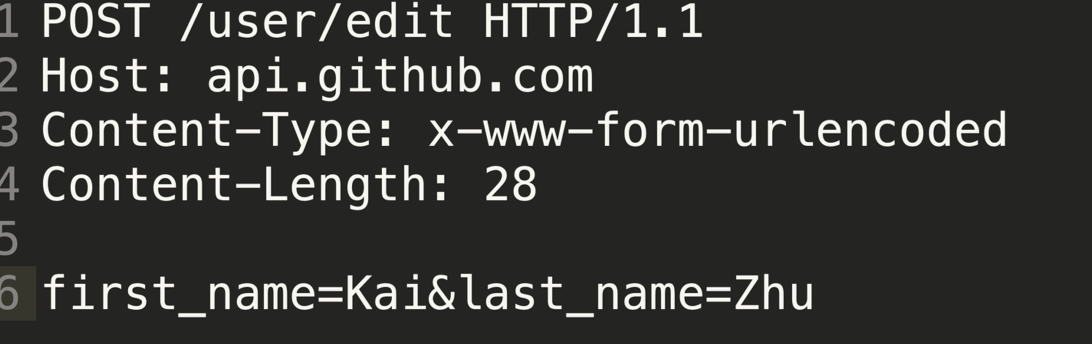
- 在Retrofit中使用:
multipart/form-data: 上传文件,多部分形式,一般用于传输包含二进制内容的多项内容- 上传文件和普通表单一起使用multipart的方式,通过
boundary不会重复的字符串进行划分,普通表单只需要通过&进行划分键值对即可 - 在Retrofit中通过:
@Multipart和@Part进行配合使用 
- 上传文件和普通表单一起使用multipart的方式,通过
application/json: json形式,用于Web Api的响应或POST/PUT请求- 类似如下的请求和响应,这个我们经常在日常开发中使用
- 在Retrofit:
@POST和@Body进行配合 
image/jpeg /application/zip: 单文件- 可以用于上传单张图片或文件,这种格式几乎没有人用

编解码与加解密
密码学 起源于古代战争—古典密码学,通过书信沟通,在战国时期,记得书信的方式通过一发三至,将一封信分成三份发送,收到三封信后通过密码棒进行解密书信缠上密码棒上就可以看到内容了,在写书信时也会通过同样规则的密码棒(移位式加密)书写内容。加密算法:缠绕木棒上书写。密钥:木棒的尺寸规格。

之后出现了替换式加密: 码表: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z B C D E F G H I J K L M N O P Q R S T U V W X Y Z A 密文: J MPWF ZPV 解密:根据码表(密钥)进行解密 I LOVE YOU
加解密
现代的密码学,更多的应用在程序中,让计算机进行加密和解密
对称加密
对称加密的原理:使用密钥和加密算法对数据进行转换,得到无意义数据即为密文;使用密钥和解密算法对密文进行逆向转换得到原数据。 例如:DES(密钥太短被弃用了)、AES是现在主流的对称加密
对称加密和解密原理如下: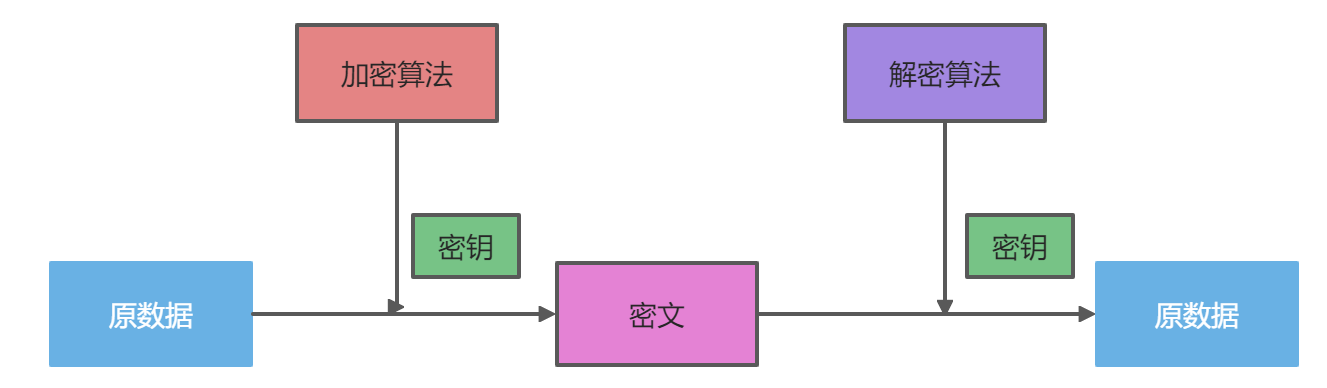
加密和解密是同一个密钥,但是对称加密的密钥对安全性是有问题的,如果传输密钥是存在问题的只要C拿到密钥就能解密密文。A 和 B 将密钥进行传输,某个节点C截取到了密钥,就可以解密密文。
非对称加密
非对称加密的原理:使用公钥对数据进行加密得到密文;使用私钥对密文进行解密得到原数据。但是使用的是同一种加密算法,加密和解密密钥是不同的。 非对称加密可以用于:数字签名、RSA、DSA
:::tips
加密密钥和解密密钥是不同的.但是加密算法和解密算法是同一种算法。
:::
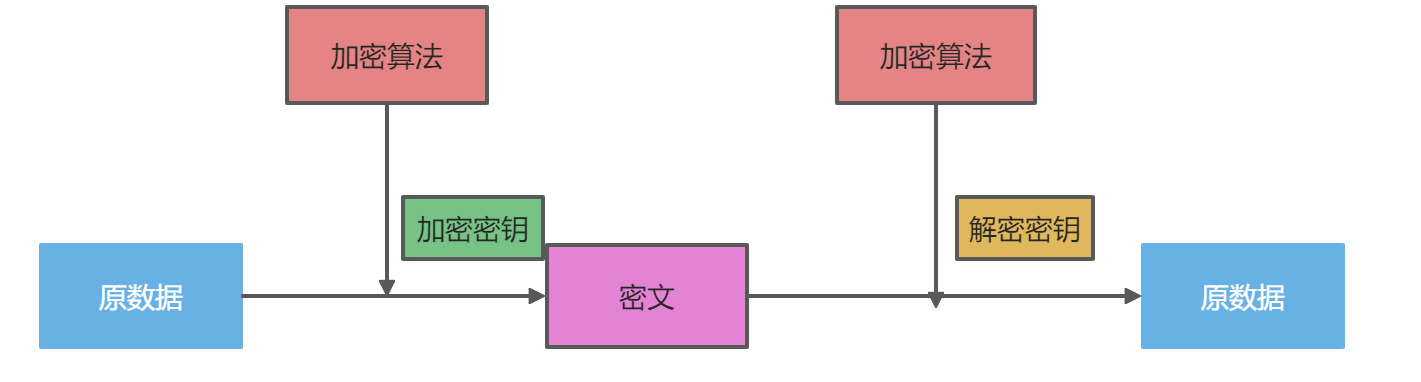
如下图的抽象例子:
A: 110加密密钥: +4密文:554解密密钥: +6去掉十位B: 110
非对称加密就不会存在对称加密的问题,对称加密的密钥可能会存在泄漏的风险,例如:A -> B B -> A 互相将加密密钥给对方,而解密密钥牢牢抓在自己的手中。这时候即便C捕获到了A的加密密钥和B的加密密钥,C没有解密密钥不能够解密。
当A将数据传给B时,A使用B的加密密钥进行加密,B拿到密文后,就可以通过它自己的解密密钥进行解密。同理B将数据传给A也是一样的。

加密密钥A和加密密钥B其实就是常说的公钥,公钥是公开的就算拿到了也没有用。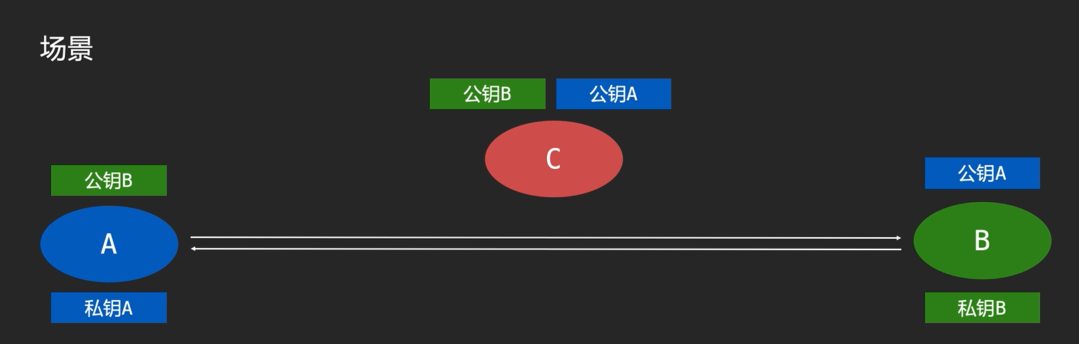
那么非对称加密就如下图所示: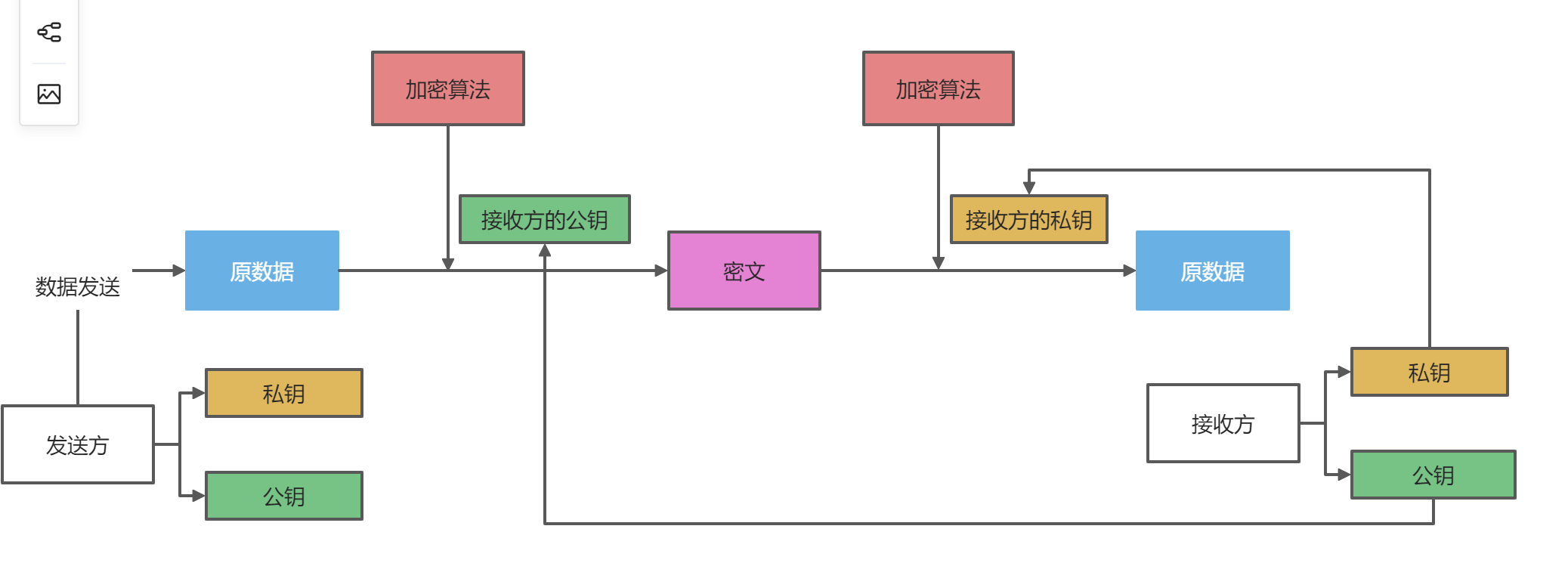
数字签名:数字签名就是使用了非对称加密的原理。
公钥能不能解私钥? 公钥可以解私钥,如下图,两个蓝框都是原数据,假如红框使用私钥进行加密得到蓝框,蓝框通过公钥同样可以加密成红框
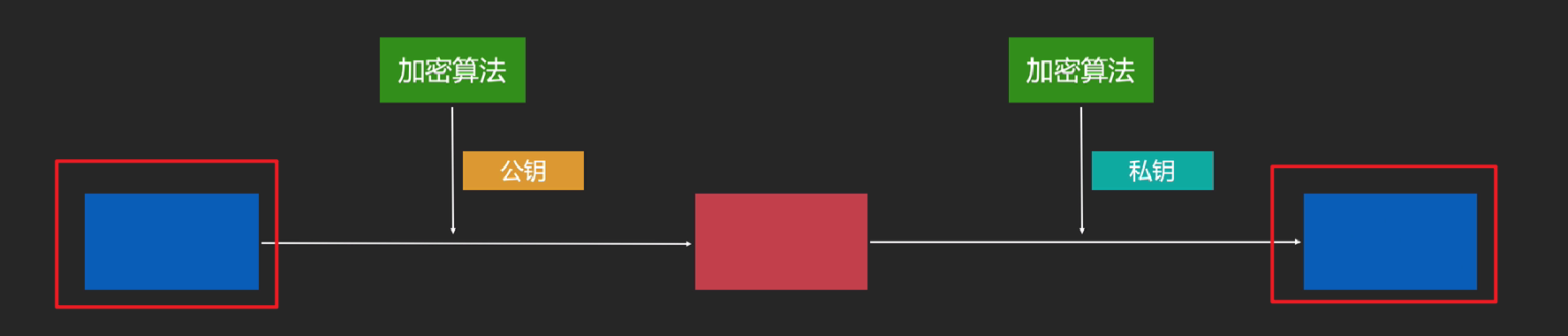
用私钥进行加密,得到一个签名数据,也就是签名只有持有者才会有,通过公钥验证签名数据
A: 110公钥: +4去掉十位密文:554私钥: +6去掉十位B: 110使用私钥对原数据进行加密:原数据:110私钥:+6加密算法:去掉十位签名数据:776公钥:+4加密算法:去掉十位签名数据:776 6+4=10 -> 0 7+4=11 -> 1 7+4=11 ->1原数据:110
签名数据是私钥的持有者才能 造出签名数据,因此签名数据无法被其他人伪造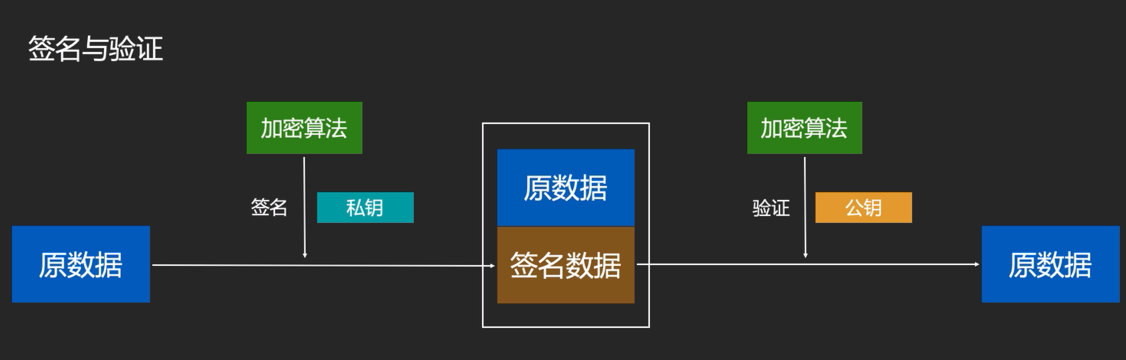
如上图通过私钥进行非对称加密得到了一个签名数据,然后通过公钥进行非对称加密得到原数据,那么表示签名数据验证通过了。原数据+签名数据放在一起,把数据签名部分拿出来加密验证结果和原数据是否一致。
数字签名的重要性,为什么要有数字签名呢?看下图假如C中攻击者,C可以拿到公钥B和A假如,C使用B的公钥伪造消息“转2000元给我”,那么B收到这个伪造消息不能确定这个消息是来自A的。这个也是中间人攻击。
这时候就体现了数字签名的重要性了,分清楚加密的作用:让人看不懂这条消息,签名作用:防止伪造消息。
加上签名之后,攻击人C虽然可以使用公钥B伪造消息,但是A通过私钥A进行数字签名,B会先验证签名通过后才会处理发送的消息,防止了中间人的攻击伪造消息。
如下图所示:分别使用公钥加密原数据得到密文,使用私钥加密原数据得到签名数据,接收方通过私钥解密得到原数据,通过公钥验证签名得到原数据,如果两个原数据一致则通过,假如攻击人C使用公钥进行伪造消息,但是无法伪造签名数据,也就无法进行攻击,即便攻击人截获到了密文+签名数据,及时修改了密文,但是签名数据解密后的原数据和密文解密后的原数据不一致,也不能通过。
但是这不是一个完整的加密+签名的过程,因为攻击人截获了密文和签名数据可以通过公钥去解密签名数据拿到原数据,那么数据还是会泄漏。解决这个漏洞需要对数据进行hash的后面在讲解。
编解码
Base64
将二进制数据转换成由64个字符组成的字符串的编码算法。 什么是二进制数据?二进制数据可以是任何的计算机数据(图片、文本、音视频等等),狭义的可以理解为非文本数据。 用途:让原数据具有字符串所具有的特性,如可以放在URL中传输、可以保存到文本文件、可以通过普通的聊天软件进行传输。 注意:Base64不是加密,不安全的,并且Base64编码后的数据增大了三分之一并不高效。Base58编码被比特币使用去掉了0 o I L等相似的字符,方便手抄
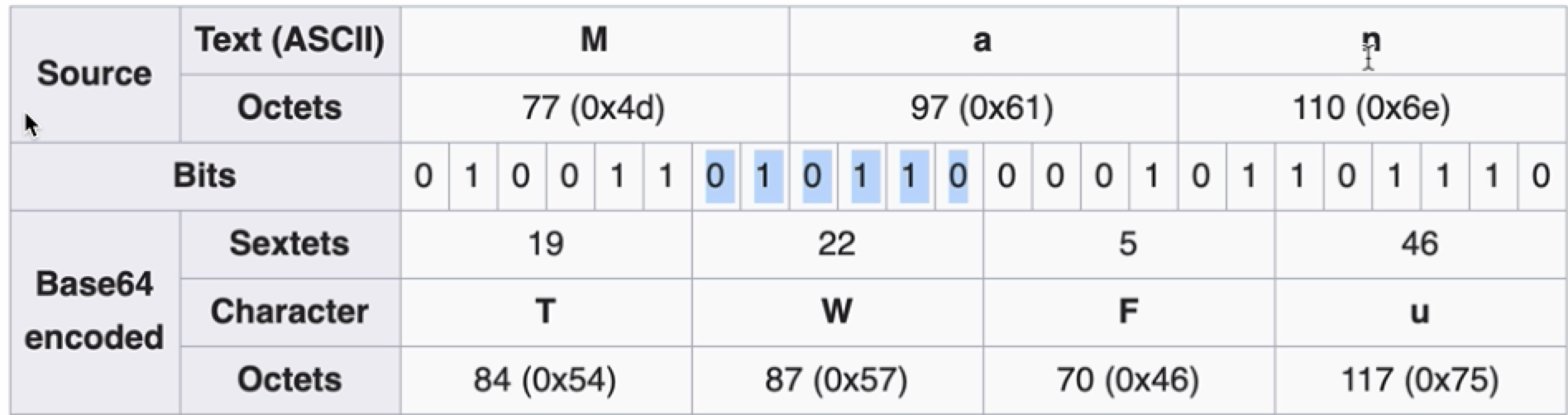
对应的码表如下:

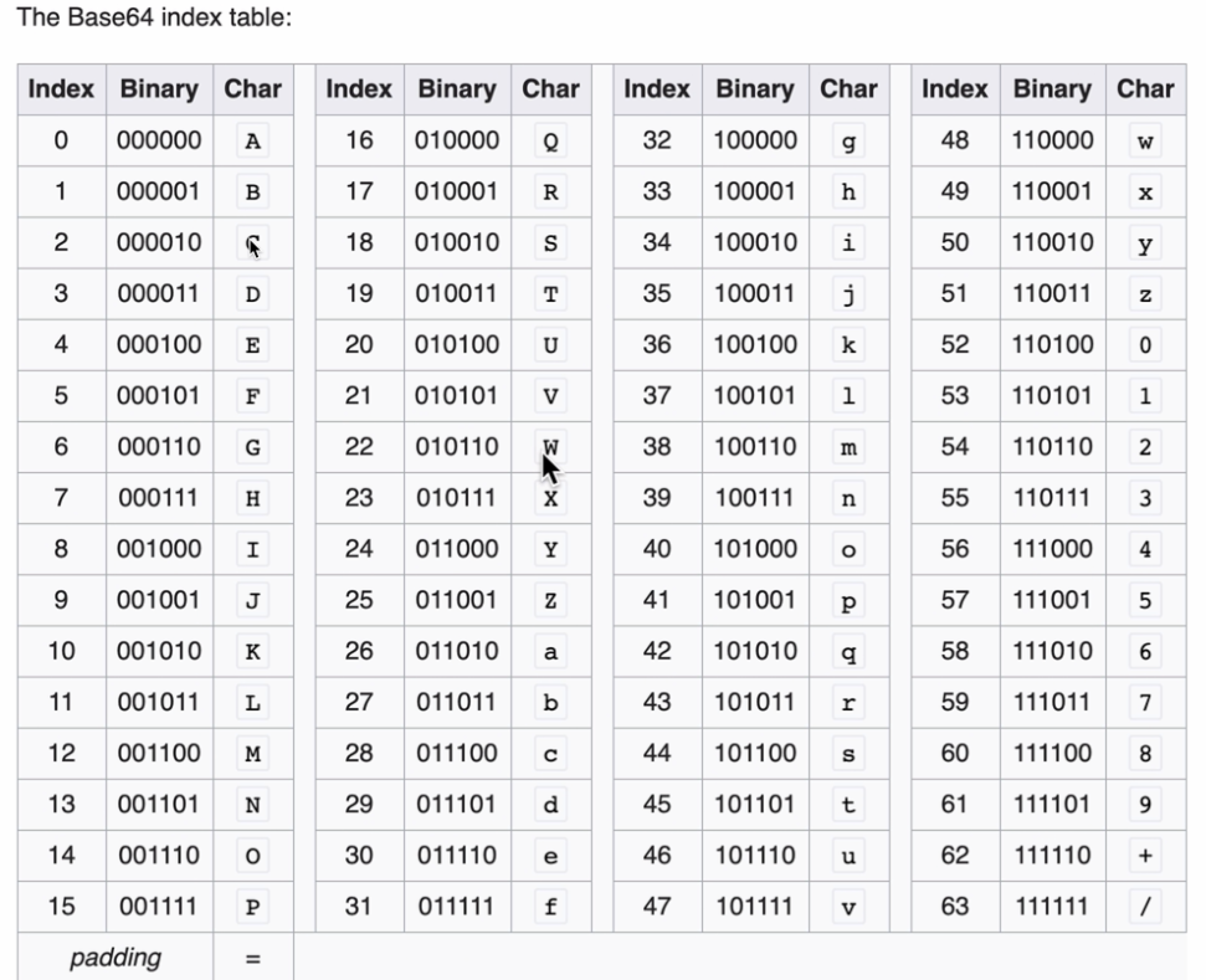
Base64 用途:
- 让原数据具有字符串所具有的特性,如果可以放在URL中传输、可以保存到文本文件、可以通过普通的聊天软件进行文本传输
- 降低偷窥风险
注意:Base64 并不能加密传输图片,而且Base64并不高效。
URLEncoding
URL encoding 编码:将URL中的保留字符使用百分号“%”进行编码
目的:消除歧义,避免解析错误

压缩与解压缩
- 压缩:把数据换一种方式来存储,以减小存储空间
- 解压缩:把压缩后的数据还原成原先的形式,以便使用
- 常见压缩算法:DEFLATE(如zip的压缩算法)、JPEG、MP3
压缩属于编码吗?属于编码,可以根据如下的例子证明,压缩实际上是对原始数据进行了编码,解压缩对编码的数据转为原始数据,这就是编码
例如如下原数据:
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb
压缩后的数据:例如压缩算法:计算a的个数和b的个数,解压缩算法:打印记录的a 和b即可
reng:a:251;b:131
媒体数据的编解码
图片、视频、音频的编解码。
图片的编码:把图像数据写成JPG、PNG等文件的编码格式
图片的解码:把JPG、PNG等文件的数据解析成标准的图像数据
音频和视频同理,视频是将一帧帧画面转成YUV数据,最终GPU进行渲染。
序列化
序列化:把数据对象(一般是内存中的,例如JVM中的对象)转换成字节序列的过程。把无序的数据变成有序的字节序列 反序列化:把字节序列重新转换成内存中的对象 目的:让内存中的对象可以被存储和传输
age=1name=jakeprim
常见的序列化有JSON序列化,程序中的对象无法在网络中进行传输,需要将对象序列化才能进行,注意序列化并不一定就是Serializable
{"age":1,"name":"jakeprim"}
反序列化,将序列化后的数据,转换成程序中的对象。
Hash
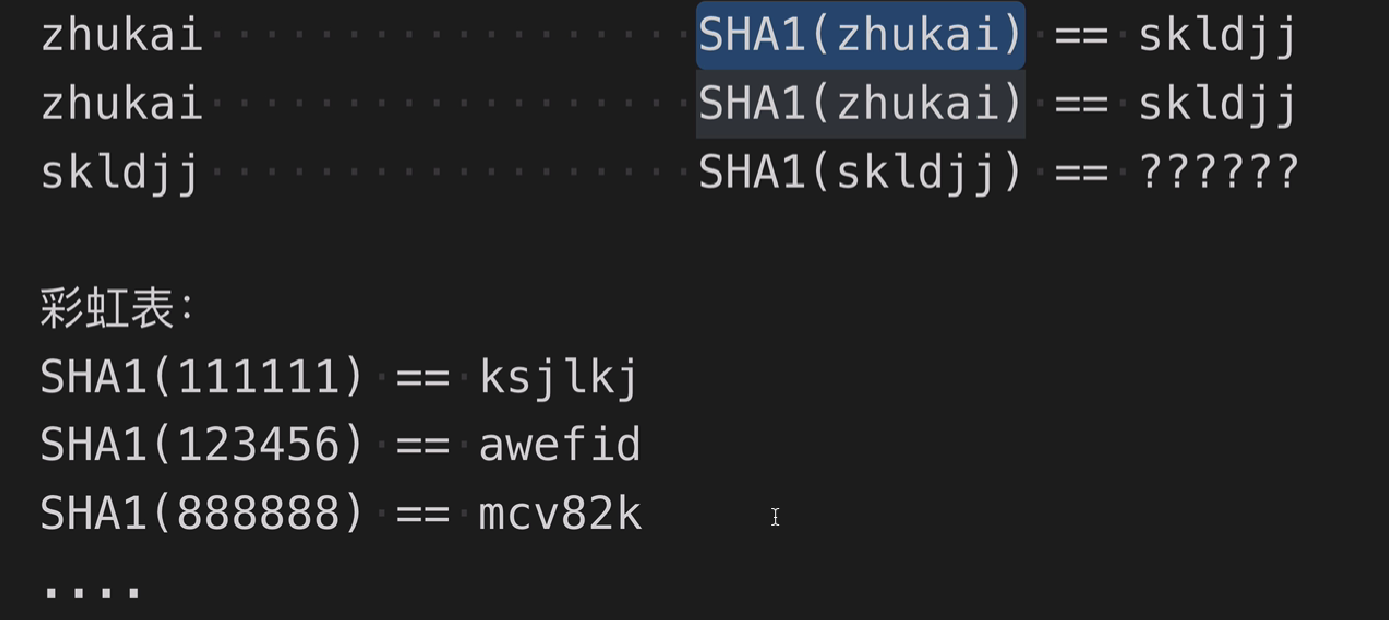
把任意的数据转换成指定大小范围的数据。 作用:摘要、数字指纹 经典算法:MD5、SHA1、SHA256等,MD5并不是加密算法 hash算法,不能让你拿着它的hash值,去找到原数据 Hash用途:数据完整性验证、快速查找:hashCode和HashMap,类似在Java中判断两个对象是否相等,会先判断hashCode是否相等,Hash可以非常快速的大致判断辨别身份,然后才会进行equals方法。还可以用作隐私保护
如下:密码经过Hash得到别人不懂的数据,但是Hash相同的输入经过SHA1都会得到相同的输出,这样是不安全的,可以通过彩虹表来对比Hash后的数据去推断你的密码,可以进行加盐例如(zhukai333) 333就是加盐,这样就不会被彩虹表破解了,即便你的密码是111111经过加盐和SHA1得到的值安全是不可推断的。
Hash是无法逆向计算出原数据的,不可逆的,只能用作数字指纹,Hash不是编码。同样Hash不是加密,MD5同样不是加密
Hash 用到了数字签名,通过hash对原数据拿到摘要,然后对摘要进行签名。通过加密算法+公钥得到待验证的摘要,在对原数据进行hash得到摘要,进行一致性的比对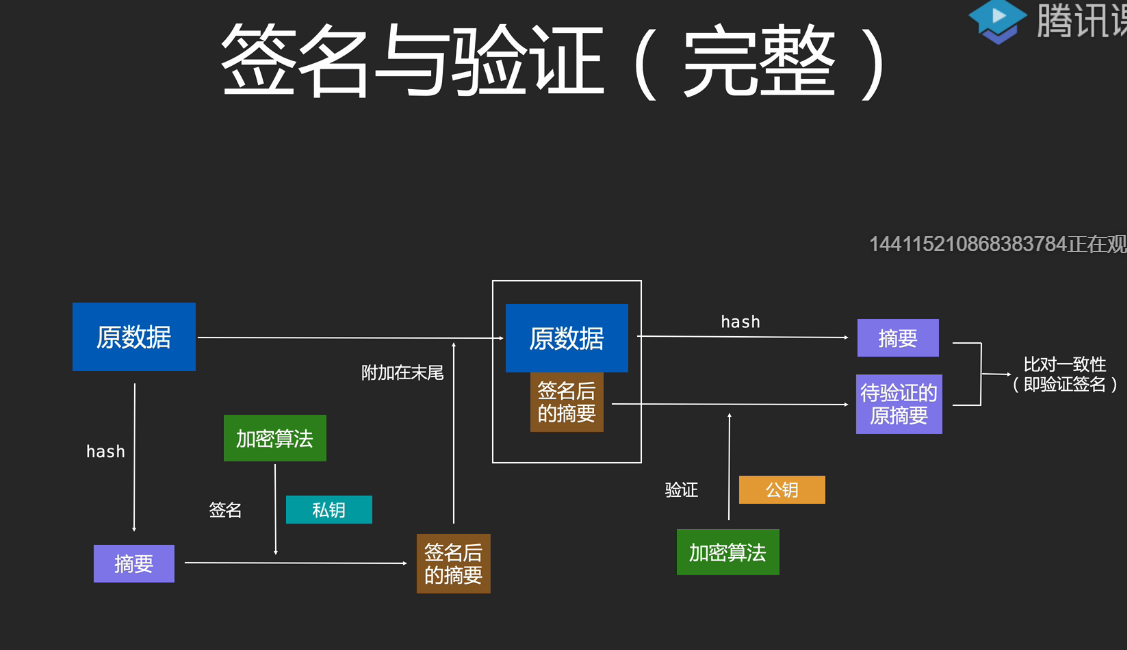
字符集:一个由整数向现实世界中的文字符号的Map 映射集合
ASCII: 128个字符 1 字节
ISO-8859-1: 对ASCII进行扩充
Unicode:13万个字符,多字节
UTF-8 - Unicode的编码分支
UTF-16 - Unicode的编码分支
GBK GB2312 GB18030 : 中国自研标准 字符集 + 编码
登录与授权
Cookie
cookie: 起源于购物车,存在用户本地。
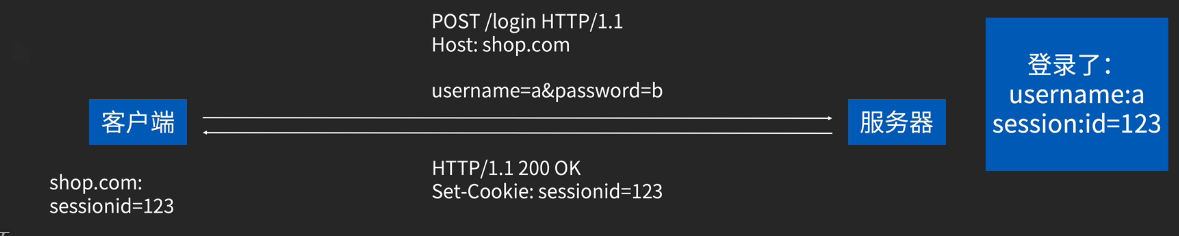
cookie的工作机制:
再加入购物车: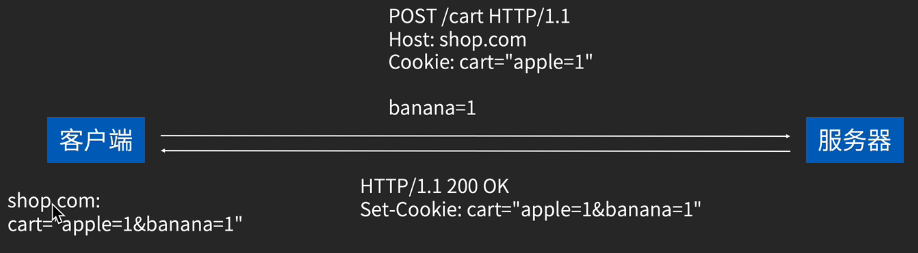
结账:
cookie的作用:
- 会话管理、登陆状态的管理
下一次的请求,直接带上cookie:返回用户的信息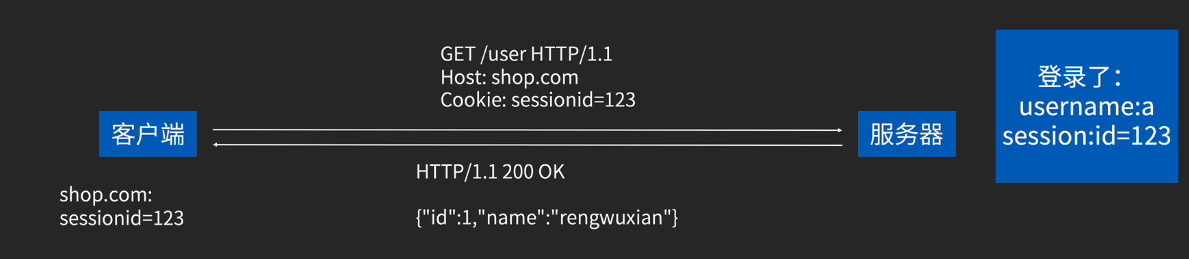
多个cookie的情况: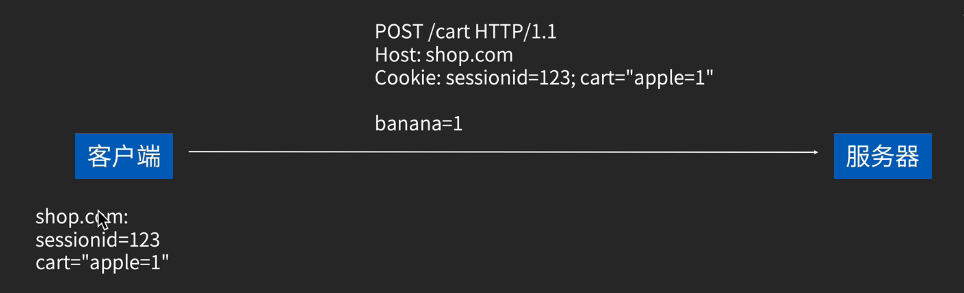
- 用cookie管理用户偏好、主题
- Tracking:分析用户行为
- XSS(Cross-site scriping):HttpOnly
- XSRF(Cross-site request forgery) : Referer
Authorization
Authorization 是目前主流的登录授权方案。cookie是很少使用了,尤其是在移动端几乎都是使用Authorization 的方案进行授权的。
Basic Token
格式如下:
Authorization: Basic<username:password(Base64ed)>
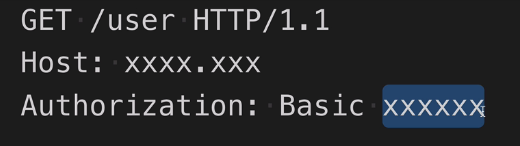
通过用户名:密码 进行Base64 然后通过header传递给服务器,进行认证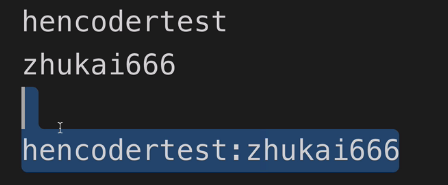
但是这种方案存在问题:Base64是可以解码的是通用的,所以信息会暴露出来。(https 其实可以解决,因为https都进行了加密.手机中的root权限,会窃取到用户的信息。)
Bearer Token
Authorization: Bearer <brarer token>
OAuth2: 三方登录,主要是授权的过程:
OAuth2 流程:关于这个OAuth2的完整流程,其实在真实开发中,有的会直接把Server的部分放到掘金网页或者APP来完成,这样就有可能导致access token泄漏的风险。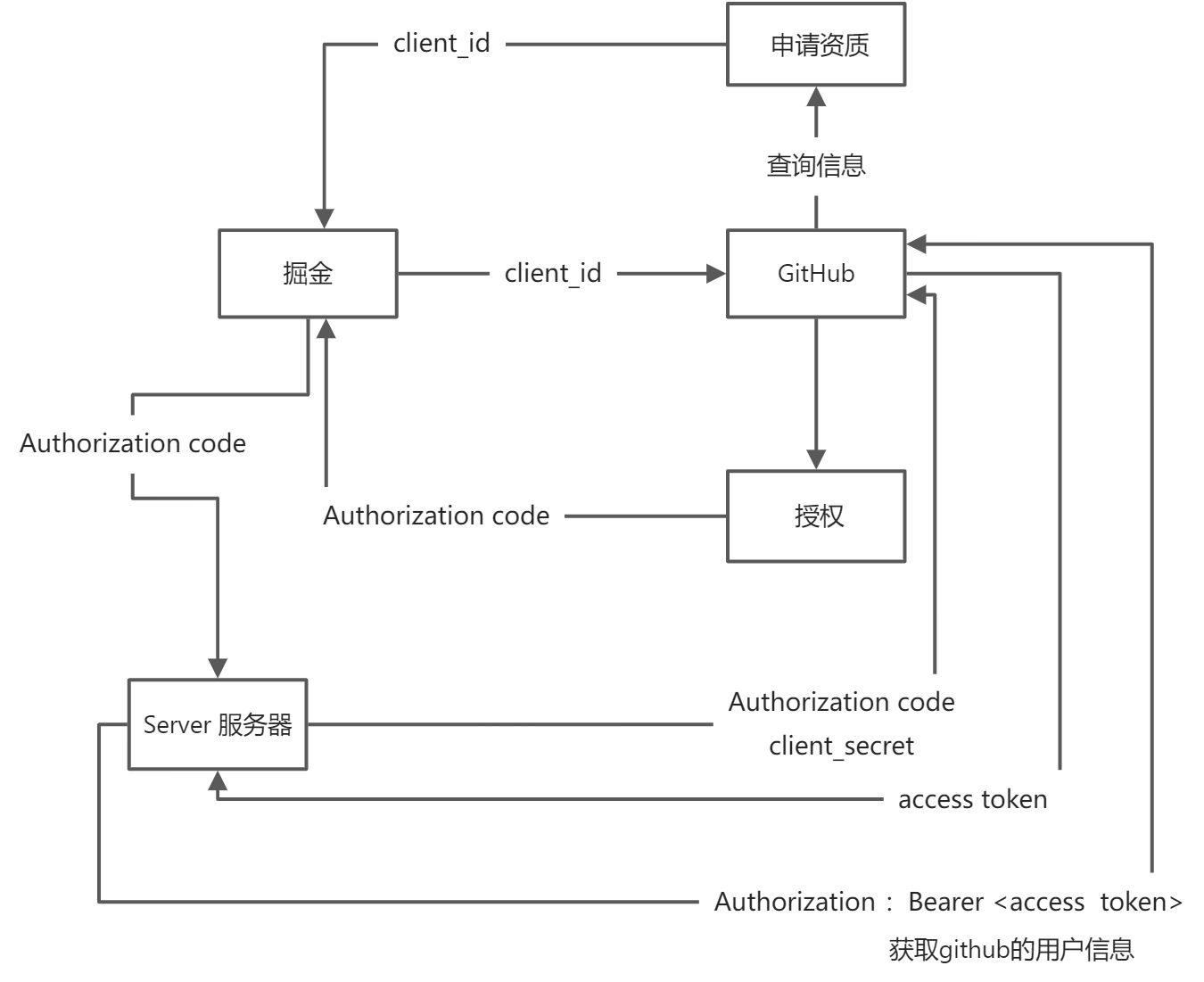
APP使用微信登录,就是一个完整的OAuth2流程:
Authorization code 的引入,把「用户确认授权」和「获取 token」两个步骤拆分开了,其中第二个步骤必须在申请授权方的服务器进行,因此保证了网络中的监听者拿不到真正有用的 access token
自家的bearer token,通过商定好的header发送,类似 jwt:”token”,类似这样进行授权
refresh token
刷新access_token,当 access token 失窃时,可以保证盗窃者在未被发现的情况下也只能在一段时间内使用 token,并且在发现 token 失窃之后可以立即换上新的 token 而无需用户重新授权。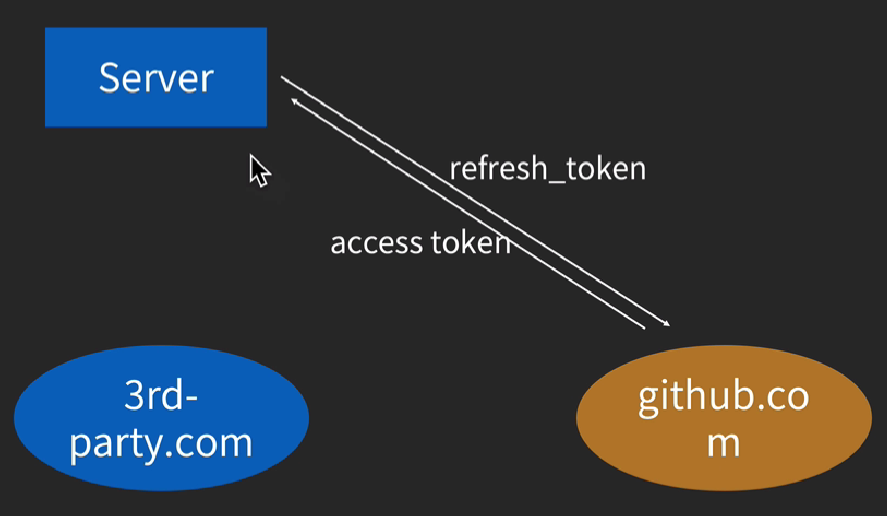

若有收获,就点个赞吧
0 人点赞
