JVM 标准规范及运行时数据区
JVM 是一种规范,不是Java独有的虚拟机。 java 文件 -> 编译器 -> class文件 -> JVM -> 机器码。 JVM可以识别.class文件,并且解析它的指令,最终调用系统的函数,完成操作。 JVM虚拟机和Java语言没有直接关系,JVM只是和规定的class文件有所关联,class文件中包含JVM虚拟机指令集(bytecodes)和符号表。不管什么语言,只要通过编译器编译成JVM规定的class文件中的指令集都可以在JVM中执行。
JVM 是一种规范,对于汇编语言规范和处理,而上层的高级语言实际上可以理解为就是一堆字符串。
在Java的JDK中默认的虚拟机:Hotspot虚拟机,而在Android中的虚拟机是Dalvik虚拟机是由Google开发的,本质上没有遵循JVM规范,基于寄存器结构(移动端要绑定设备)指令集而不是JVM栈结构指令集,在Android上执行的是dex文件,执行效率较高,在Android5.0之后被ART 虚拟机替换了。
dex 是怎么形成的?为什么使用dex?
- 寄存器指令集架构
- 一次性执行多个指令,例如:

- 栈一次处理一个指令
- 基于x86二进制指令集(16位)
- 依赖于硬件,可移植性差
- 但是性能和执行更加高效
- 花费更少的时间执行一个操作
- 基于寄存器架构指令集往往都以1-3地址指令为主,而基于栈则省却地址指令操作,都基于栈区完成
- 栈指令集架构
- 设计与实现简单,适用于资源受限的系统
- 一次只能执行一个指令
- 指令流中的指令操作过程基于栈,且位数小8位
- 不需要硬件支持,可移植性好
其实从上述可以看到在移动端更多的和设备相关,这也是为什么Google开发了Dalvik虚拟机主要用在移动端的设备上。而对于Hotspot虚拟机来说是基于系统来开发的,二者还是存在很多区别的,至于存在什么样的差异在后面详细讲解。
JVM 构成组件
- 类加载器:将编译好的class文件加载到JVM进程中
- 运行时数据区:存放系统执行过程中产生的数据
- 执行引擎:用来执行汇编及当前进程内所要完成的一些具体内容
首先要了解运行时数据区: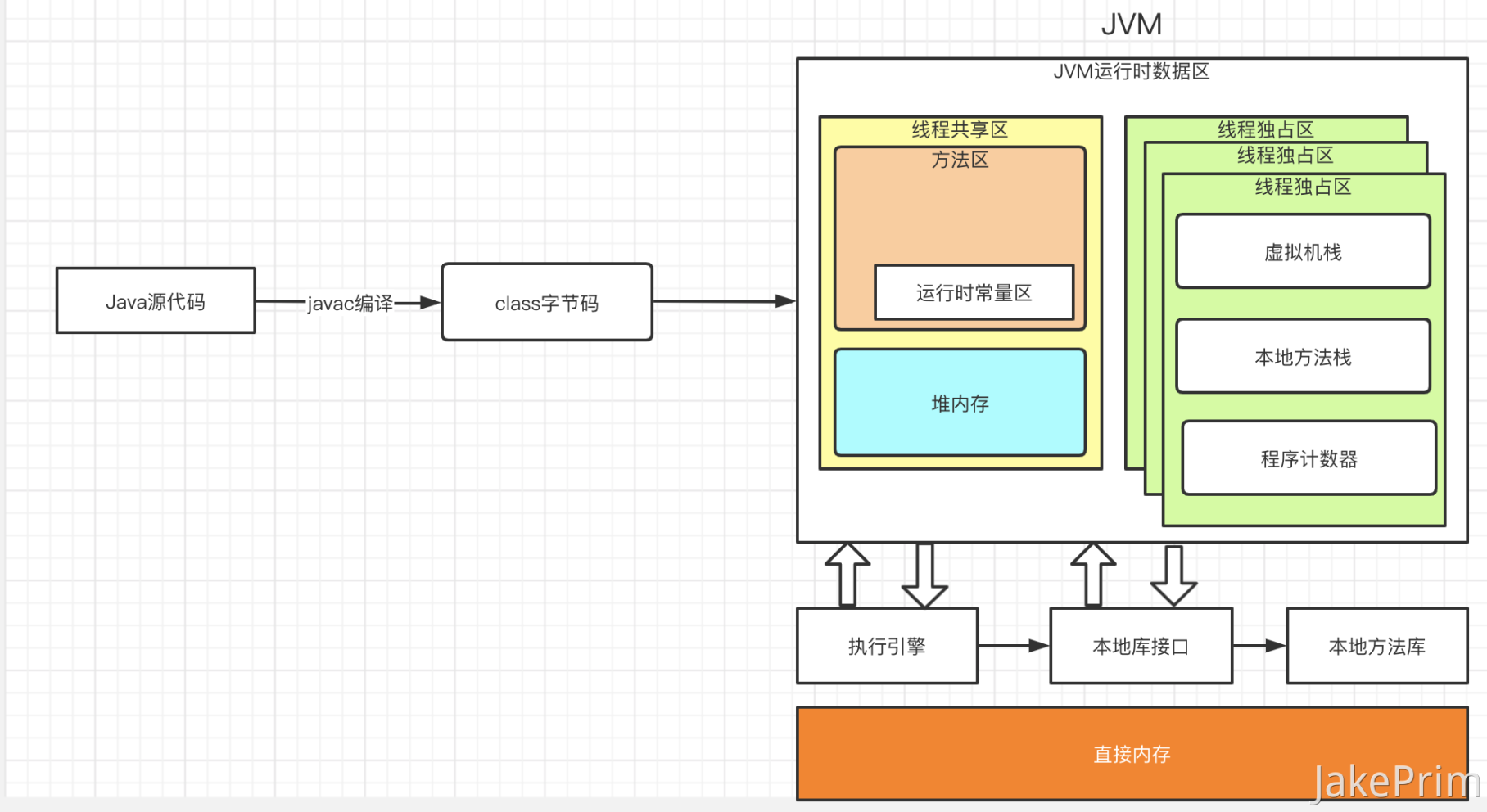
JVM 是Java虚拟机,类似一个操作系统,class就是指令,比如一个操作系统有8G的内存,其中3G为虚拟内存(运行时数据区)剩下的5G可以理解为JVM的直接内存,这个虚拟内存就是JVM的运行时数据区域,另外还有一个直接内存不是运行时数据区域的一部分,但是会频繁使用。
运行时数据区
堆和栈在内存中的职责: 栈是运行时的处理单元,堆是运行时的存储单元。 栈是用来解决程序运行问题,程序如何运行、如何处理数据、方法如何执行等。 堆是用来解决数据存储问题,数据放哪里,怎么放?
栈区:
- 虚拟机栈
- 程序计数器
- 本地方法栈
程序计数器:
指向当前线程正在执行的字节码的指令地址
:::tips
程序计数器是唯一不会发生OOM的内存溢出
:::
程序计数器是一块很小的内存空间,主要用来记录各个线程执行的字节码的地址,例如:分支、循环、跳转、异常、线程恢复等都依赖于计数器。
为什么要有程序计数器这个东西呢?
JVM中的程序计数器 映射了操作系统:CPU时间片轮转机制。
由于Java是多线程语言,当执行的线程数量超过CPU核数时,线程之间会根据时间片轮询争夺CPU资源。如果一个线程的时间片用完了,或者是其他原因导致这个线程的CPU资源被提前抢夺,那么这个退出的线程就需要单独一个程序计数器,来记录下一条的运行的指令.
如下图,需要程序计数器来记录运行的指令。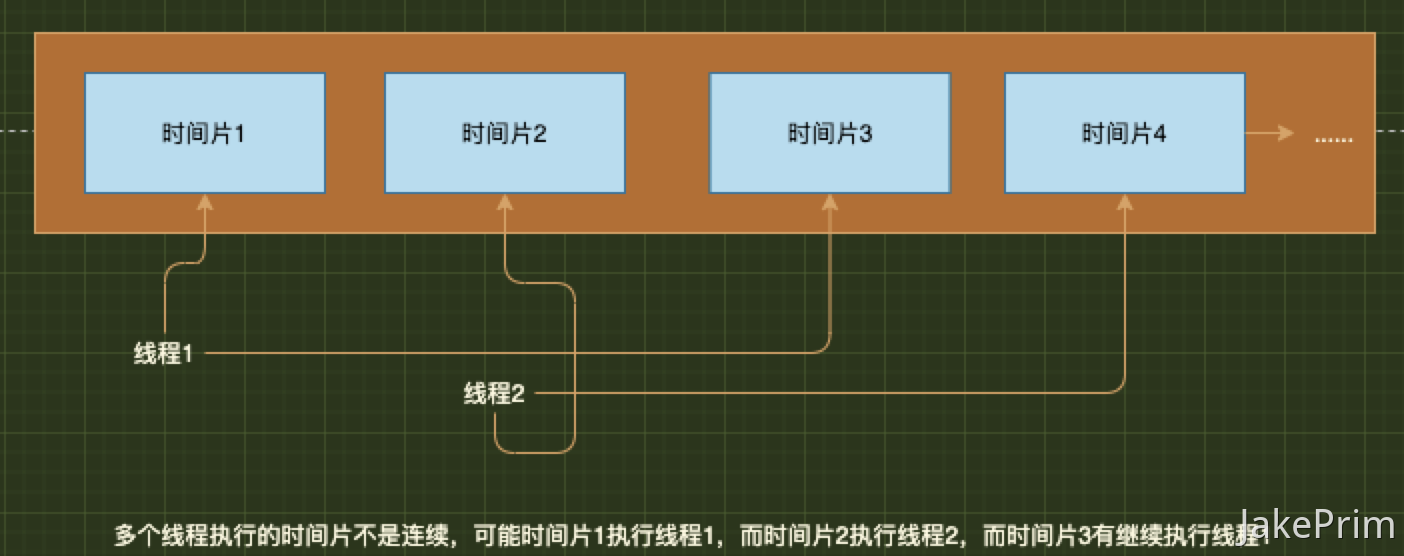
因为 JVM 是虚拟机,内部有完整的指令与执行的一套流程,所以在运行 Java 方法的时候需要使用程序计数器(记录字节码执行的地址或行号),
如果是遇到本地方法(native 方法),这个方法不是 JVM 来具体执行,所以程序计数器不需要记录了,这个是因为在操作系统层面也有一个程序计数器.
这个会记录本地代码的执行的地址,所以在执行 native 方法时,JVM 中程序计数器的值为空(Undefined)。
虚拟机栈:
承载方法调用的过程中产生的数据容器,随线程开辟,为线程私有。主要管理java方法运行过程中所产生的值变量、运算结果、方法的调用与返回等信息管理:局部变量、计算结果。 虚拟机栈的作用:栈结构的应用能产生一种快速有效的分配方案,访问速度仅次于程序计数器操作只有入栈和出栈,不需要有GC设定。
虚拟机栈中入栈和出栈的是栈帧,而栈帧包括:局部变量、操作数栈、动态链接、完成出口
- 局部变量表:变量和引用变量 :::tips 局部变量表,用于存放局部变量就是方法中的变量,首先它是一个32位的长度,主要存放Java的八大基础数据类型,如果是64位的就使用高低位占用两个也可以存放下,如果是局部的一些对象,只需要存放它的一个引用地址即可。
- 默认会有一个this当前类的对象的引用.
- 参数也会置入变量表
- 内部所声明的变量
- 32位栈1个slot,引用类型32位,32位以上如64位占2slot 变量槽
- 大小在编译时固定,没有动态分配
- 局部变量表的slot存在复用
:::
长度是作用域范围
- 操作数栈
操作数栈存放Java方法的操作数的,它就是一个栈结构先进后出。操作数栈就是用来操作,操作的元素可以是任意的Java数据类型,所以当一个方法刚刚开始的时候,这个方法的操作数栈就是空的。
操作数栈本质上是JVM执行引擎的一个工作区,也就是所方法在执行,才会对操作数栈进行操作,如果代码不执行,操作数栈其实就是空的。
一般操作系统:需要有这些东西CPU + 主内存 + 缓存
:::tips
JVM是一个模拟版的操作系统,JVM执行引擎(CPU) + 栈、堆等(主内存) + 操作数栈(缓存)
:::
指令:都是有执行引擎来处理的
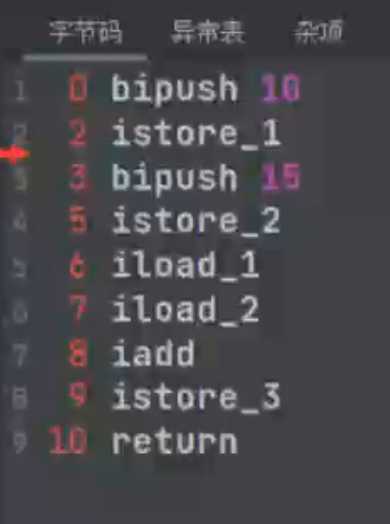
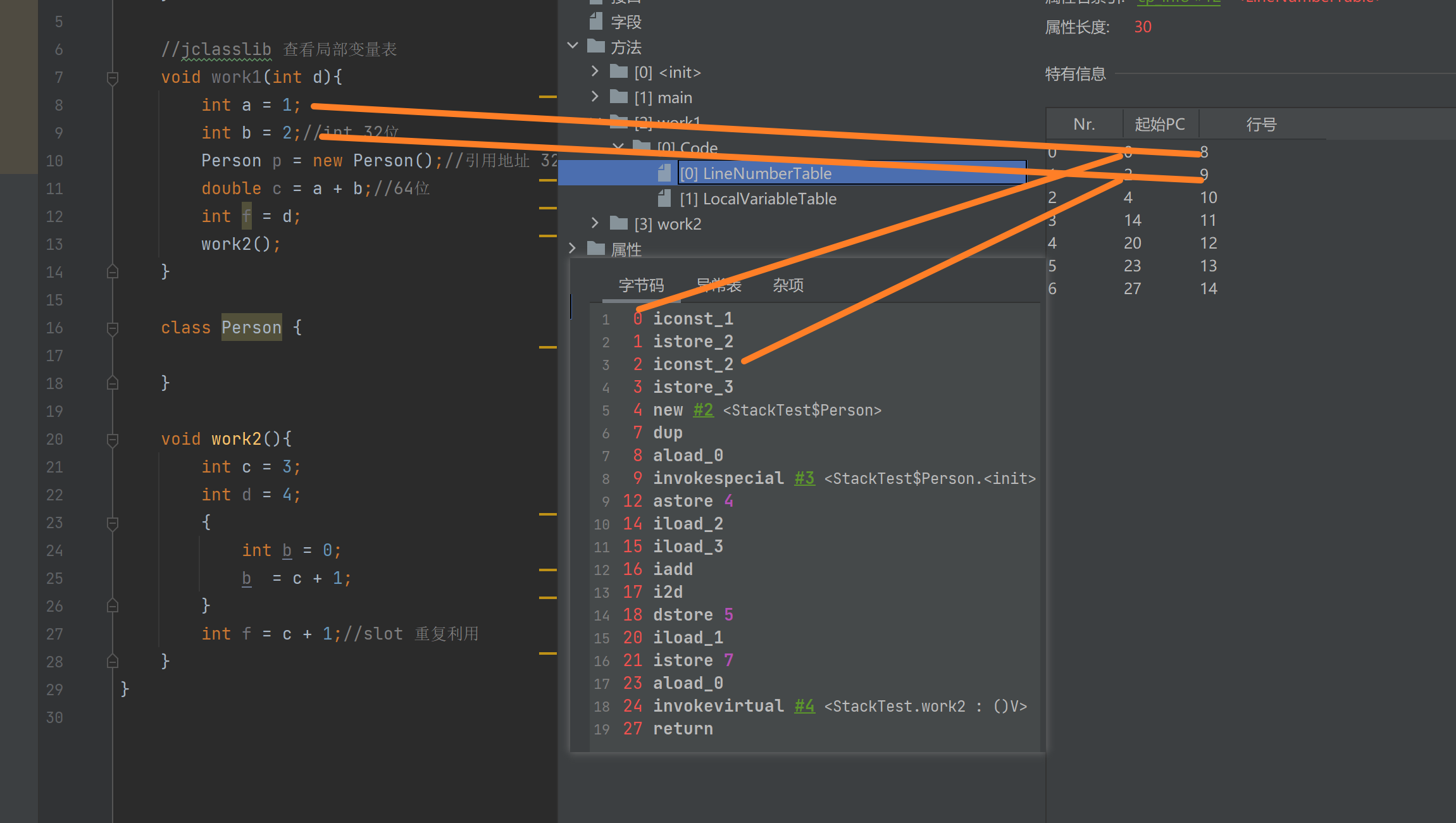
ICONST_0(iconst_<n>) : 将一个常量0(n)压入操作数栈ISTORE 1 (istore_<n>):表示将操作数栈存入到局部变量表 下标为1(n)的位置ILOAD 1 :加载存储指令 将局部变量下标为1的值 加载到操作数栈ILOAD 2 :加载存储指令 将局部变量下标为2的值 加载到操作数栈IADD : 算法指令 两条数据从操作数栈出栈相加(执行引擎进行计算) ,运算后的结果入到操作数栈(why?) 而执行引擎相当于CPU不做数据的存储,操作数栈相当于缓存,可以存储中间数据BIPUSH 10 : 将10常量压入操作数栈IMUL : 算法指令 乘法。 操作数栈出栈,执行引擎计算得到的结果,存入操作数栈ISTORE 3 :操作数栈出栈,存入到局部变量表下标为3的位置ILOAD 3 : 将局部变量下标为3的值 加载到操作数栈IRETURN : 方法的返回指令: 因为执行引擎都是处理操作数栈中的数据
- 动态链接
Java语言的特性多态,具体的会在后面的章节中单独讲解。
- 完成出口 返回地址
正常返回(调用程序计数器中的地址作为返回)、异常的话(通过异常处理器表<非栈帧中的>来确定)
虚拟机栈常见的错误:栈溢出:StackOverflowError 常见的场景:一般无限循环递归会造成这个错误 只有压栈没有弹出栈,虚拟机栈内存也不是无限大的,它是有大小限制的.
:::tips 在每个Java方法被调用的时候,都会创建一个栈帧,并入栈。一旦方法完成响应的调用,则出栈 :::

虚拟机栈的运行过程如下:
本地方法栈:
执行的是native关键字的方法,native的关键字的方法是在C/C++中实现的,例如hashcode()方法,有一个动态链接hashcode.dll,本地方法并不是Java实现的。
为什么会有本地方法栈的原因是:虚拟机规范中规定的。(后续版本中虚拟机栈和本地方法栈合二为一了)
为什么Java要用native方法呢?
历史的一些原因,Java实现不了的用c/c++去实现
本地方法栈和虚拟机栈是非常相似的一个区域,只不过本地方法栈服务的对象时native方法。
JVM栈区:method的调用整体过程的内存变化
:::tips 方法区:存储常量、静态变量、类信息等 :::
:::tips 堆区:分配对象内存和创建 :::
JVM对象分配过程
JVM堆区在对象的内存分配与创建,对象在内存中的表现。
- 一个JVM进程存在一个堆内存,堆是内存管理的核心区域。
- 堆区在JVM启动时被创建,其空间大小也被确定,是JVM管理最大的一块内存(注意:堆内存大小是可以调整的 默认:物理内存/64,最大的内存:物理内存/4)
- 本质上堆是一组物理上不连续的内存空间,但是逻辑上是连续的空间(HSDB window :
java -classpath "%JAVA_HOME%/lib/sa-jdi.jar" sun.jvm.hotspot.HSDB) - 所有线程共享堆,但是堆内对于线程处理还是做了一个线程私有的部分(TALB)
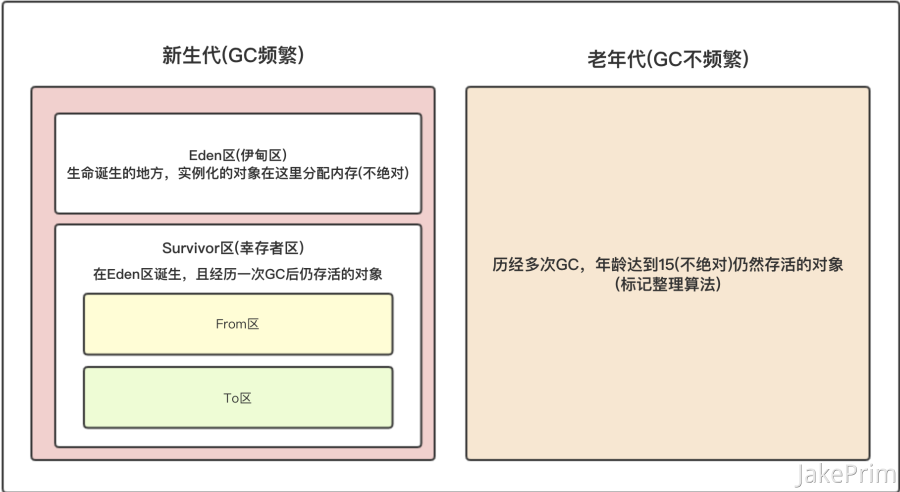
堆区主要划分为:新生代和老年代
- 新生代 GC频繁
Eden区也叫伊甸区,表示声明诞生的地方,实例化的对象在这里分配内存
在Eden区诞生,并且经历一次GC后仍存活的对象 会进入 Survivor幸存者区。也就是From区和To区
- 老年代 GC不频繁
经历多次GC,年龄达到15(不绝对)仍然存活的对象进入老年代
:::tips
分代划分主要是优化GC的性能
:::
public static void main(String[] args) throws InterruptedException {Teacher t1 = new Teacher();t1.setName("Mark");t1.setSexType(MAN_TYPE);t1.setAge(36);// System.gc(); 主动触发GCfor (int i = 0; i < 15; i++) {System.gc();///演示程序 主动触发垃圾回收15次}Teacher t2 = new Teacher();t2.setName("King");t2.setSexType(MAN_TYPE);t2.setAge(18);Thread.sleep(Integer.MAX_VALUE);}
下面我们来分析一下,t1如何进入老年代的。如下图所示:t1在刚创建对象的时候处于新生代的Eden区。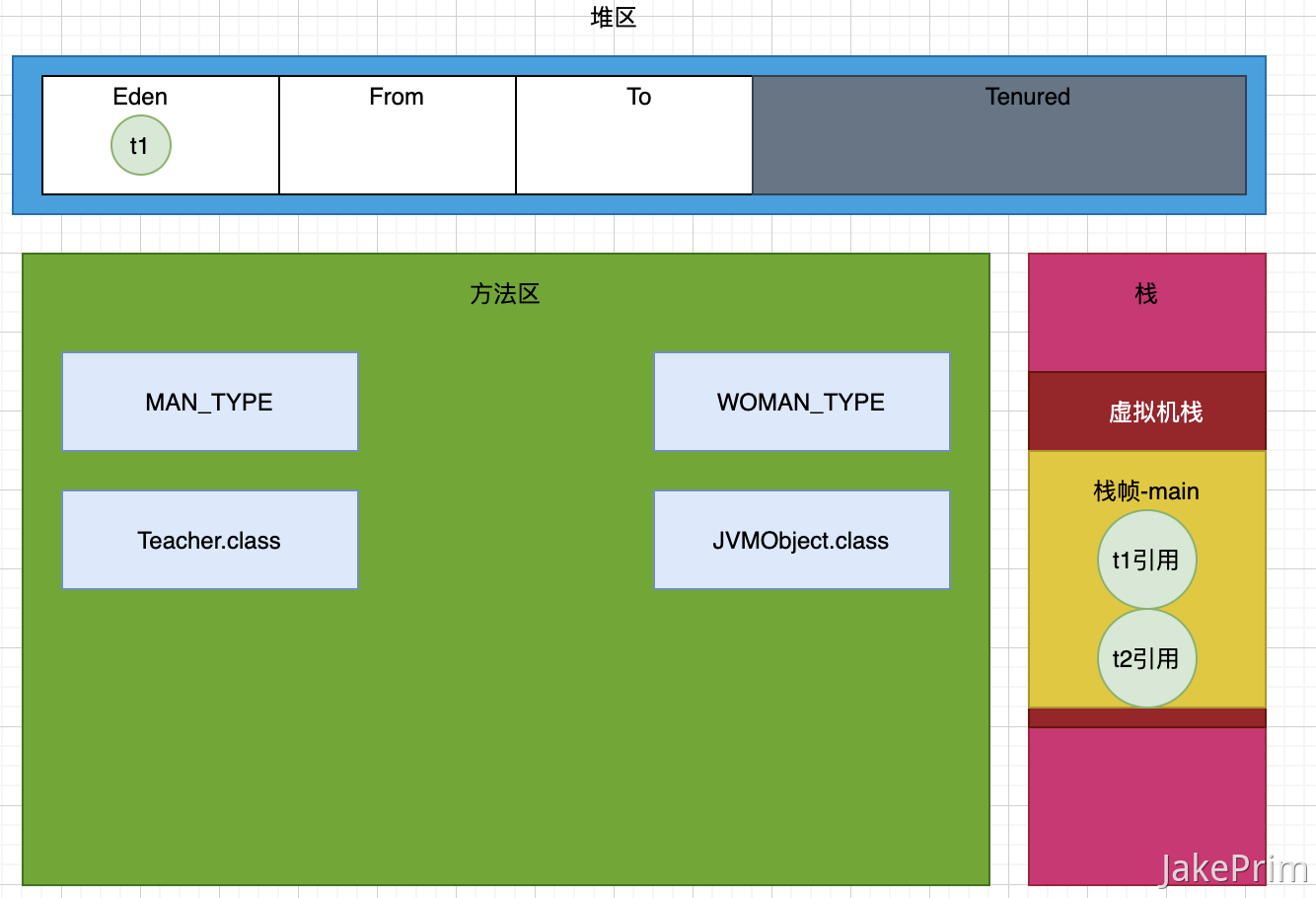
当Eden区满了后会进行一次MinorGC, 存活的对象会进入From区,再次GC Eden区存活的对象和From区的对象会进入To区,然后是From和To 区来回进入。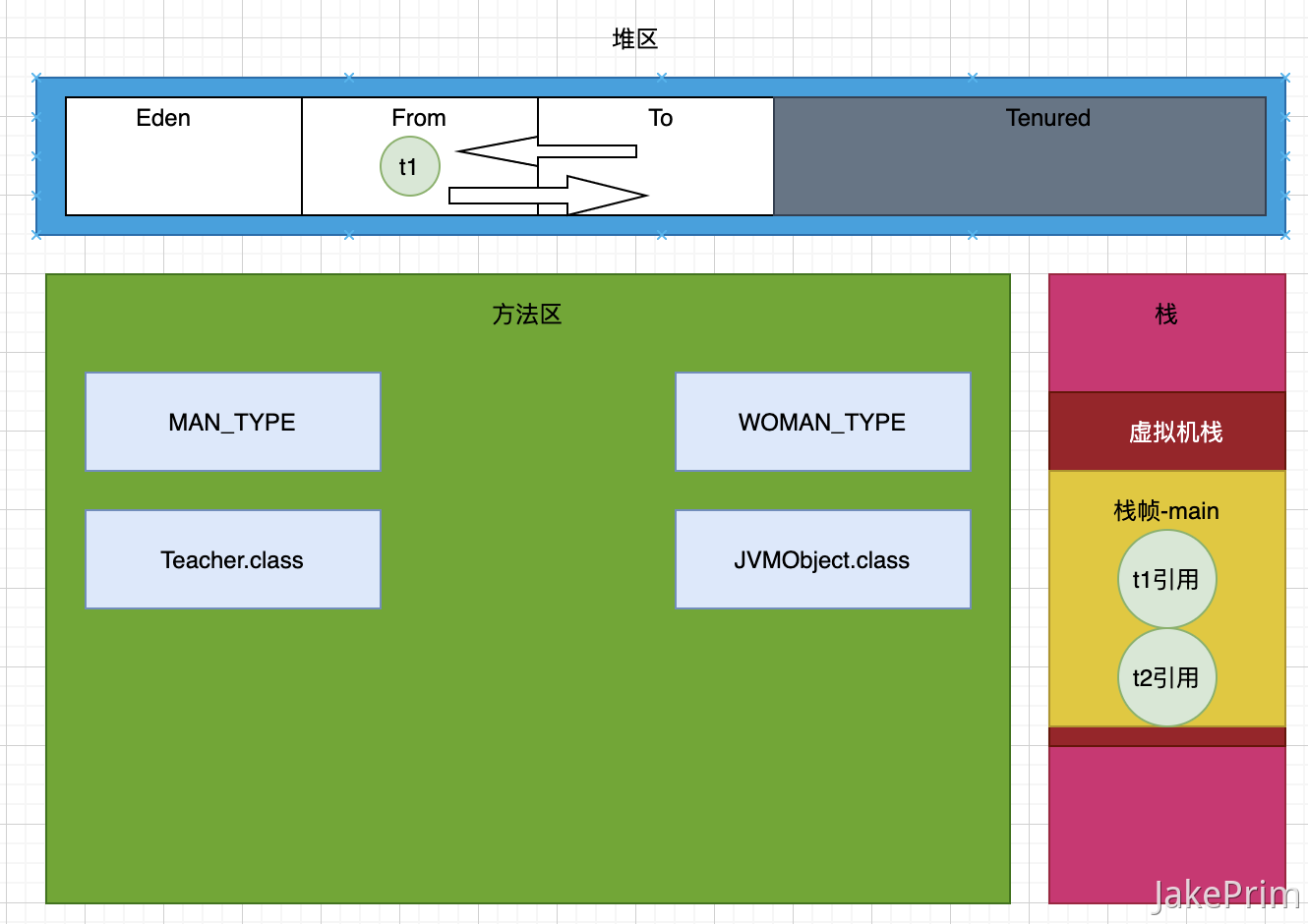
每次进入From和To区都会记录分代年龄,当分代年龄达到15(不绝对)就会进入老年代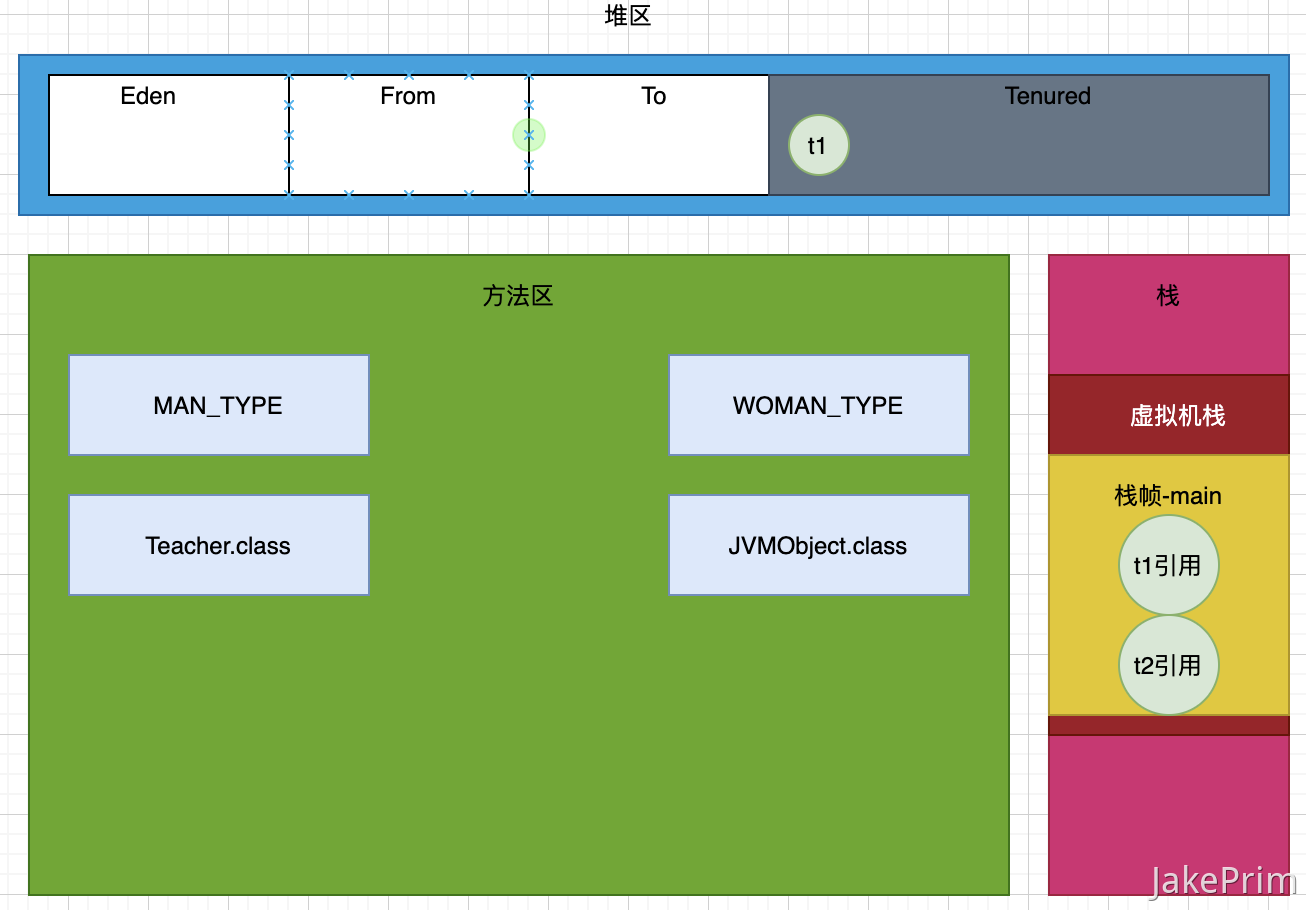 :::tips
不是必须到达15岁才会晋升为老年代,JVM采用动态年龄计算,以防止老年代内存过于宽裕,而新生代内存被撑爆。在Android虚拟机中的阈值是6,不是15.
:::
:::tips
不是必须到达15岁才会晋升为老年代,JVM采用动态年龄计算,以防止老年代内存过于宽裕,而新生代内存被撑爆。在Android虚拟机中的阈值是6,不是15.
:::
使用jdk工具jvisualvm.exe 可视化查询内存分配情况,进行验证堆内存分配情况,内存抖动:频繁的触发GC
通过jvisualvm来监控如下代码在JVM堆内存上的分配情况:
public static void main(String[] args) {ArrayList arrayList = new ArrayList();for (;;){TestGC t = new TestGC();arrayList.add(t);try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}}}public class TestGC {byte[] b = new byte[1024*300];}
需要注意进行VisualVM插件的下载:
jvisualvm默认的下载地址已经无法更新插件了,需要进行修改。修改的具体地址可以在下面的地址中找到https://visualvm.github.io/pluginscenters.html
如我的jdk版本为1.8.0_121,修改为下面的地址即可:
https://visualvm.github.io/archive/uc/8u40/updates.xml.gz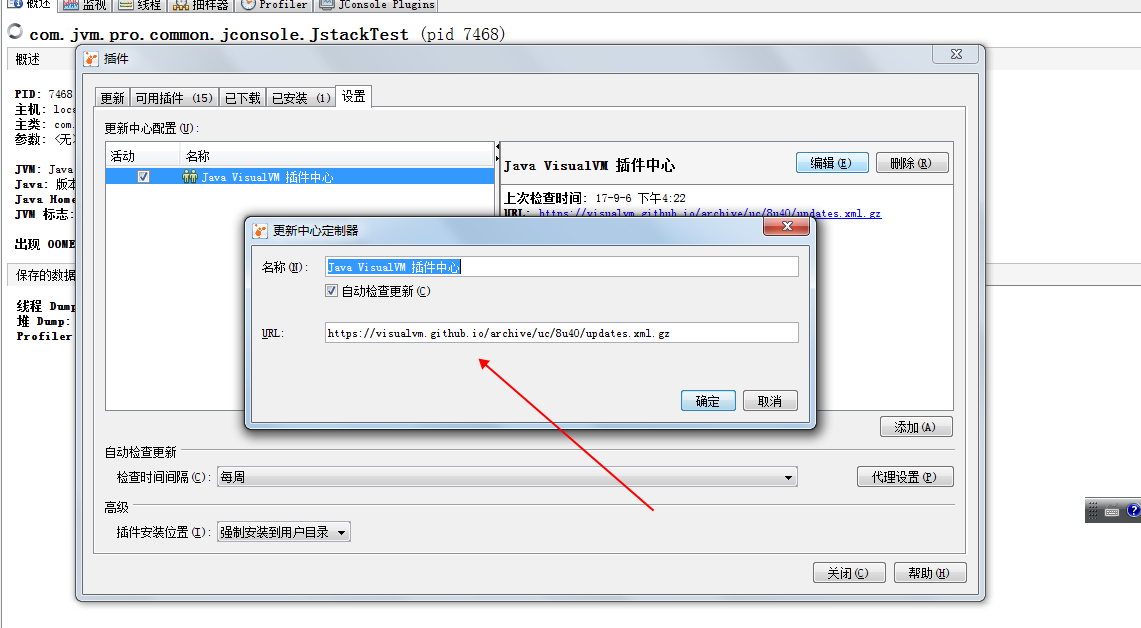
安装Visual GC 插件即可。
然后运行上述的代码,即可在jvisualvm中看到相关的JVM进程:可以清晰的看到GC的变化,在Eden区 From区 To区以及老年代的内存变化,可以非常直观的验证上述所提到的内存分配的理论。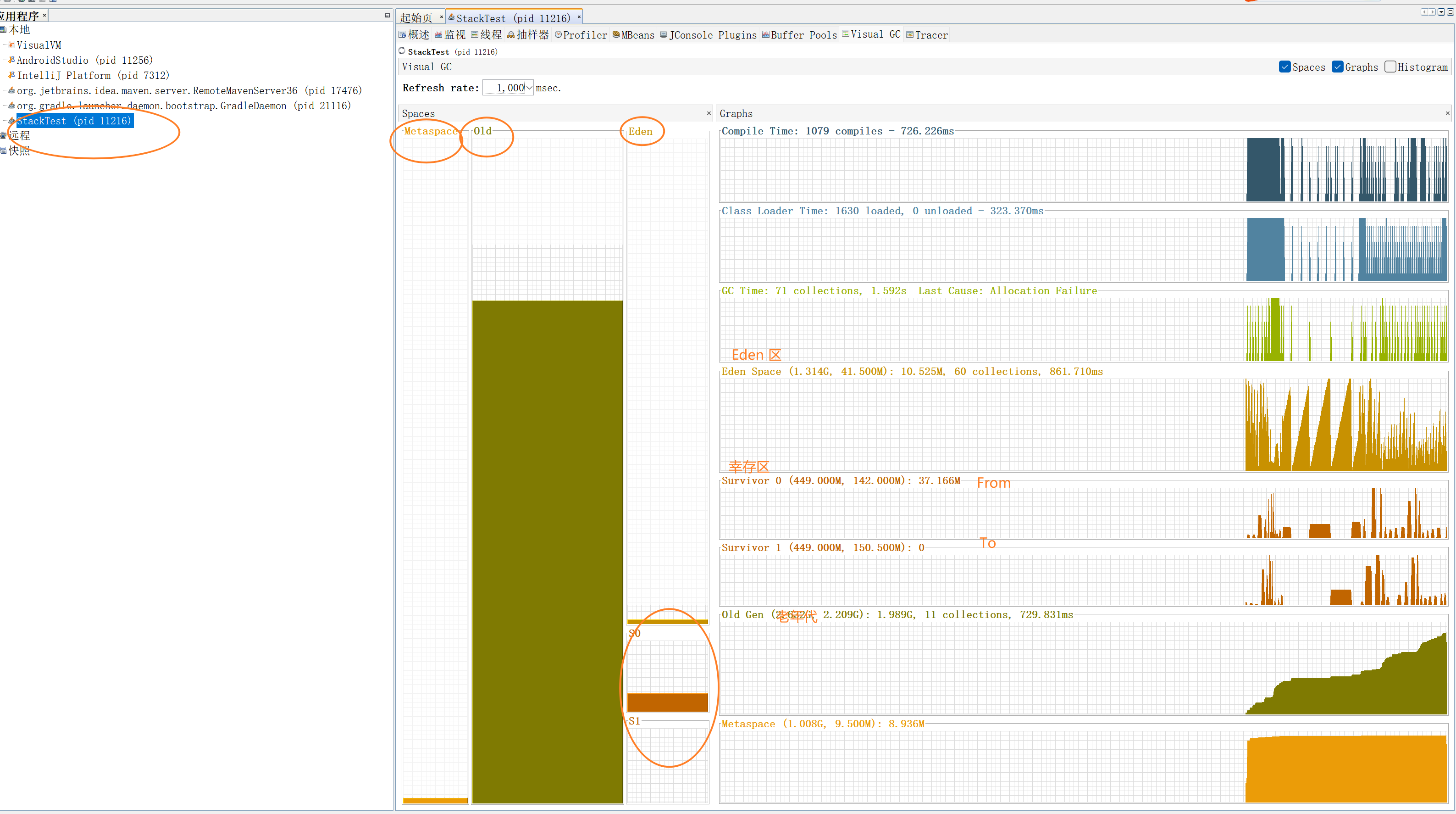
重新整理下堆区中内存分配的流程: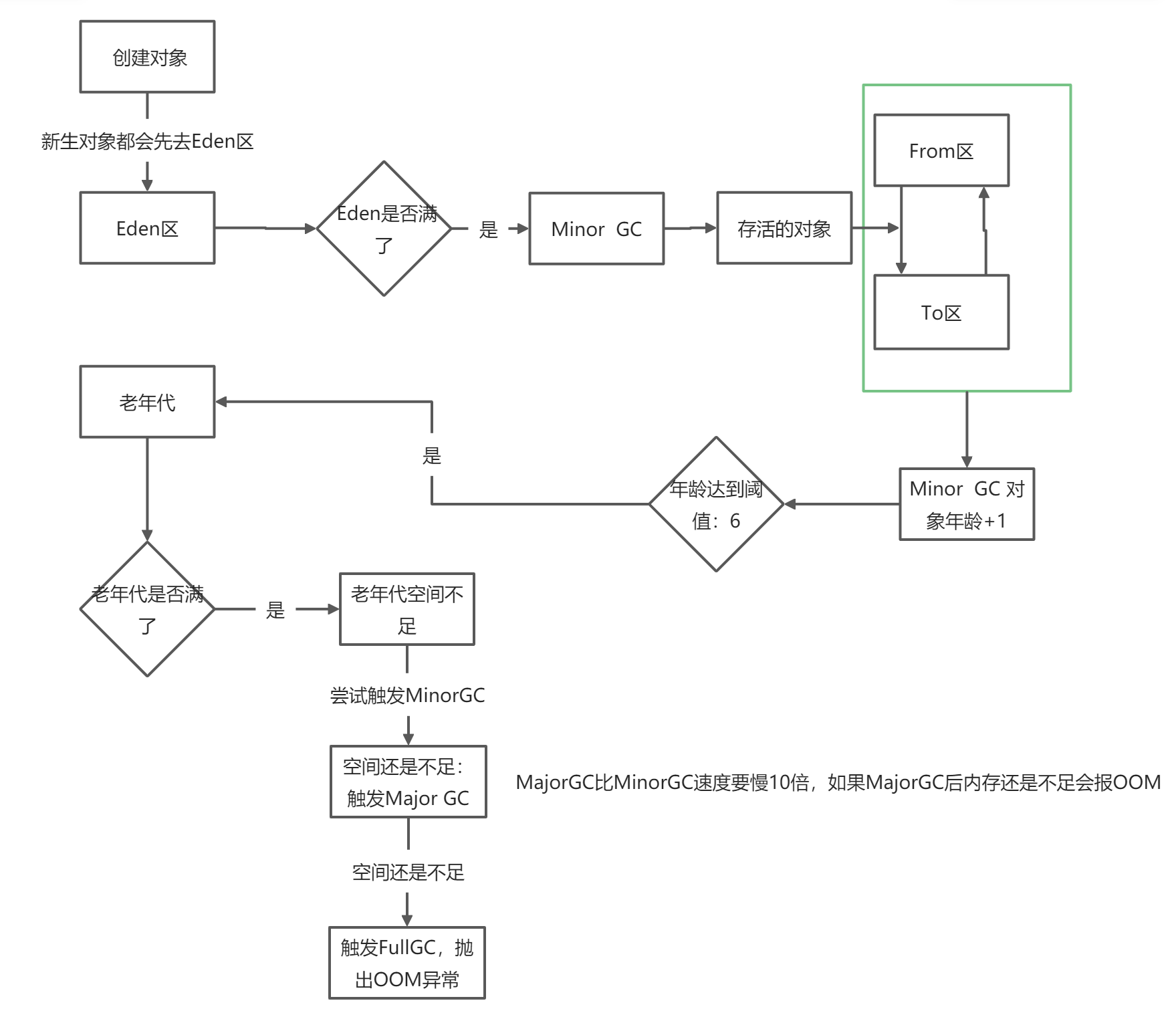
Minor GC 、Major GC 和 Full GC的区别?在垃圾回收算法中详细讲解。
JVM GC 分为两种GC:
JVM在进行GC时,并非每次都对上面三个内存区域一起回收,大部分的只会针对Eden区进行。
- 部分采集
- 新生代采集GC:Minor GC Yong GC
- 老年代采集GC:Major GC Old GC 目前只有CMS会单独采集老年代
- 混合采集GC:Mixed GC 采集新生代与老年代部分数据,目前只有G1使用
- 整体采集
- Full GC收集整个堆与方法区的所有垃圾
年轻代GC触发的机制:当年轻代空间不足时,就会触发Minor GC,当Eden区满了,Java大部分对象时朝生夕死,MinorGC会发生STW行为,暂停其他用户的线程。
- Full GC收集整个堆与方法区的所有垃圾
老年代GC触发机制:当老年代空间不足时会尝试触发MinorGC ,如果空间还是不足则会触发MajorGC,如果MajorGC后空间还是不足则触发FullGC,并且抛出OOM异常。
Full GC触发机制:
- 调用System.gc()
- 老年代空间不足时
- 方法区空间不足时
- 通过MinorGC进入老年代的平均大小大于老年代的可用内存
- 在Eden使用Survivor进行复制时,对象大小大于Survivor的可用内存,则把该对象转入老年代,且老年代的可用内存小于该对象
TLAB:在Eden区分的1%的一个空间,Thread Local Allocation Buffer ,由于堆是线程共享的,任何线程都可以访问堆中的数据,而多个线程同时访问一个地址操作,需要加锁,而加锁则会影响内存的分配速度。所以JVM默认在堆区开辟了一块空间,专门服务每一个线程,他为每一个线程分配了一个私有缓存区域,包含在Eden区,就是TLAB,多线程分配内存,使用TLAB可以避免一系列的的非线程安全问题。TLAB会作为内存分配的首选,一旦对象在TLAB空间分配失败,JVM会尝试使用加锁来保证数据操作的原子性,从而直接在Eden中分配。
对象逃逸
堆是分配对象的唯一选择吗?从JVM规范来讲堆是分配对象的唯一选择。 那么什么是逃逸呢?
- 一个对象的作用域仅限于方法区域内部的使用情况下,此种状况叫做非逃逸。
- 一个对象如果被外部其他类调用,或者是作用于属性中,则此种现象被称为对象逃逸
- 此种行为发生在字节码被编译后JIT对于代码的进一步优化
如下代码:
/*** 未产生逃逸*/public static String method1(String str1,String str2){StringBuffer sb = new StringBuffer();sb.append(str1);sb.append(str2);return sb.toString();}/*** 产生逃逸* @param str1* @param str2* @return*/public static StringBuffer method2(String str1,String str2){StringBuffer sb = new StringBuffer();sb.append(str1);sb.append(str2);return sb;}
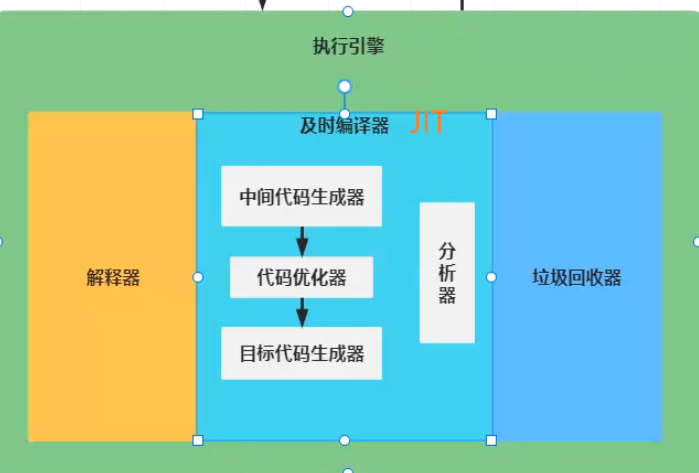
栈上分配:
:::tips
-Xmx1G -Xms1G -XX: +DoEscapeAnalysis -XX:+PrintGCDetails
:::
标量替换: :::tips -Xmx1G -Xms1G -XX: +EliminateAllocations -XX:+PrintGCDetails :::
标量Scalar:指一个无法再分解成更小的数据的数据,Java中的原始数据类型就是标量 聚合量Aggregate:Java中的聚合量指的是类,封装的行为就是聚合。 标量替换:在未逃逸的情况下,函数内部生成的聚合量在经过JIT优化后将其拆解成标量。
如下代码:
static class Person{int x;int y;}/*** 未产生逃逸* JIT 会优化成将对象优化成局部变量:* int x* int y*/public static void method3(){Person sb = new Person();}
经过逃逸分析,JIT会将其优化标量替换:
static class Person{int x;int y;}/*** 未产生逃逸* JIT 会优化成将对象优化成局部变量:* int x* int y*/public static void method3(){// Person sb = new Person();int x;int y;}
通过逃逸分析技术,其实也是需要优化代码:尽量不要让方法内的对象,被外部其他类调用。
JVM对象创建及内存结构
对象在JVM中的内存结构是怎样的? 对象头当中有什么信息?
对象创建实例的几种方案:
- new
- Class.newInstance 反射
- obj.clone 克隆数据
- 反序列化 : 从文件、网络获取一个对象流
对象创建的过程:
- 判断对象对应类是否加载、链接、初始化
- 为对象分配内存
- 处理并发安全问题
- 初始化分配控件
- 设置对象的对象头
堆区就是一组连续指定的内存地址的逻辑空间,通过逃逸分析,JIT能支撑标量替换,提升性能。
class文件格式
class 字节码的组成:
- 魔数:占用了四个字节
- 版本:00 00 00 34
- 类名:08(表示类名八个字节) 类名 类名 类名 类名 类名 类名 类名 类名
- 属性:02(两个属性) 02(第一个属性两个字节) 属性 属性 04(第二个属性4个字节) 属性 属性 属性 属性
- 方法

垃圾回收算法
JVM与Dalvik Android的虚拟机实现

若有收获,就点个赞吧
0 人点赞
