1. 概述
内存管理不外乎三个层面,用户程序层,C 运行时库层,内核层。allocator 正是值 C 运行时库的内存管理模块, 它响应用户的分配请求, 向内核申请内存, 然后将其返回给用户程序。为了保持高效的分配, allocator 一般都会预先分配一块大于用户请求的内存, 并通过某种算法管理这块内存. 来满足用户的内存分配要求, 用户 free 掉的内存也并不是立即就返回给操作系统, 相反, allocator 会管理这些被 free 掉的空闲空间, 以应对用户以后的内存分配要求. 也就是说, allocator 不但要管理已分配的内存块, 还需要管理空闲的内存块, 当响应用户分配要求时, allocator 会首先在空闲空间中寻找一块合适的内存给用户, 在空闲空间中找不到的情况下才分配一块新的内存。
业界常见的库包括:ptmalloc(glibc 标配)、tcmalloc(google)、jemalloc(facebook)
1.1. Linux 内存布局
先了解一下内存布局,以 x86 32 位系统为例:
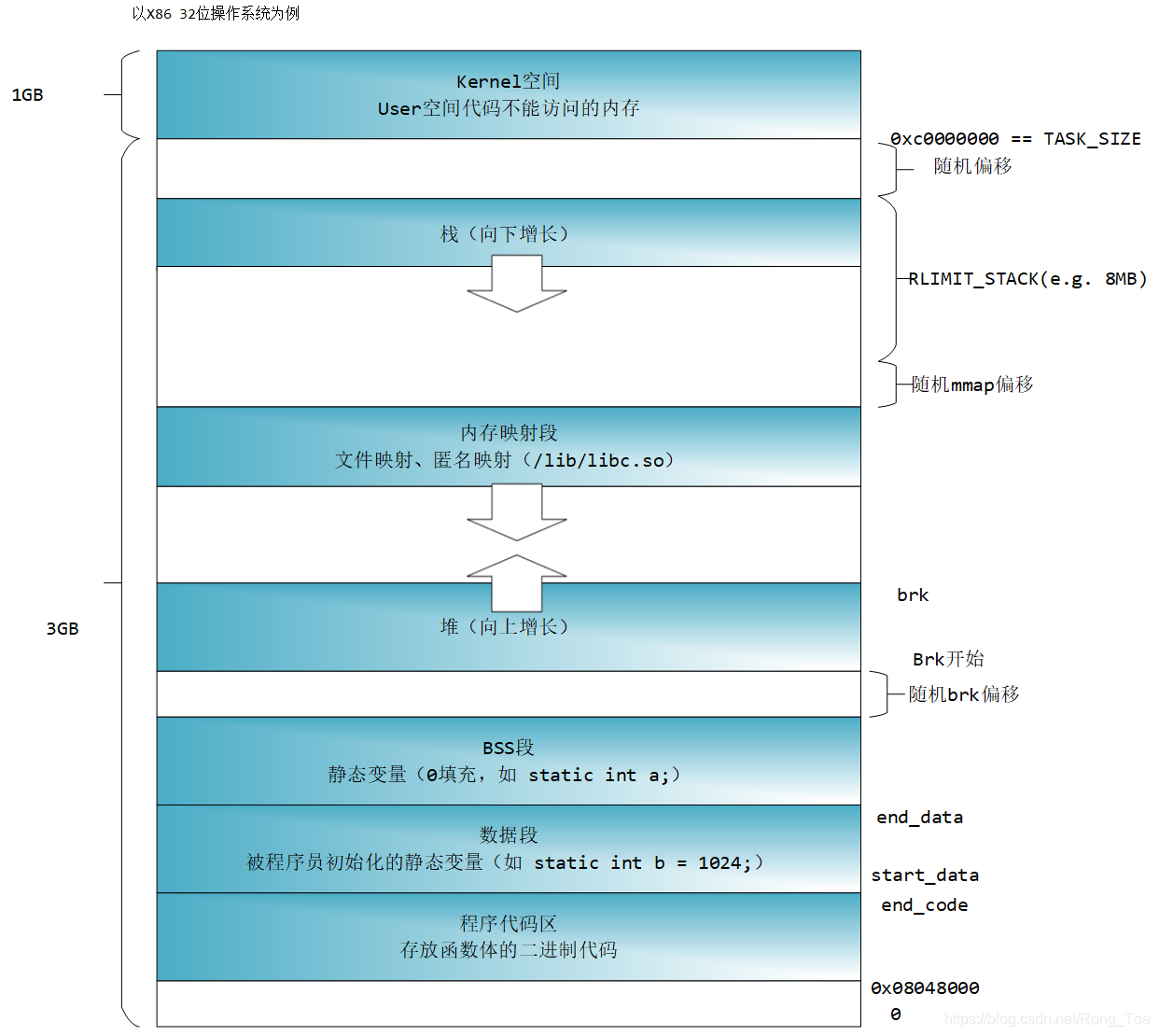
栈自顶向下扩展,堆至底向上扩展,mmap 映射区域至顶乡下扩展。mmap 映射区和堆相对扩展,直至耗尽虚拟地址空间中的剩余区域,这种结构便于 C 语言运行时库使用 mmap 映射区域和堆进行内存分配。
1.2. 系统调用
1.2.1. brk() sbrk()
#include <unistd.h>int brk(void *addr);void *sbrk(intptr_t increment);
扩展 heap 的上界,brk()设置新的上界地址,sbrk()返回新的上界地址。
1.2.2. mmap()
#include <sys/mman.h>void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);int munmap(void *addr, size_t length);
- 用法 1:映射磁盘文件到内存;
- 用法 2:向映射区申请一块内存;
2. ptmalloc(Glibc)
GNU Libc 的内存分配器 (allocator)—ptmalloc,起源于 Doug Lea 的 malloc。由 Wolfram Gloger 改进得到可以支持多线程。
- 在 Doug Lea 实现的内存分配器中只有一个主分配区(main arena),每次分配内存都必须对主分配区加锁,分配完成后释放锁,在 SMP 多线程环境下,对主分配区的锁的争用很激烈,严重影响了 malloc 的分配效率。
ptmalloc增加了动态分配区(dynamic arena),主分配区与动态分配区用环形链表进行管理。每一个分配区利用互斥锁(mutex)使线程对于该分配区的访问互斥。ptmalloc每个进程只有一个主分配区,但可能存在多个动态分配区(非主分配区),ptmalloc 根据系统对分配区的争用情况动态增加动态分配区的数量,分配区的数量一旦增加,就不会再减少了。ptmalloc主分配区在二进制启动时调用 sbrk 从 heap 区域分配内存,Heap 是由用户内存块组成的连续的内存域。ptmalloc动态分配区每次使用mmap()向操作系统 “批发”HEAP_MAX_SIZE大小的虚拟内存,如果内存耗尽,则会申请新的内存链到动态分配区 heap data 的 “strcut malloc_state”。ptmalloc如果用户请求的大小超过HEAP_MAX_SIZE,动态分配区则会直接调用mmap()分配内存,并且当free的时候调用munmap(),该类型的内存块不会链接到任何 heap data。ptmalloc用户请求分配内存时,内存分配器将缓存的内存切割成小块 “零售” 出去。从用户空间分配内存,减少系统调用,是提高内存分配速度的好方法,毕竟前者要高效的多。
2.1. 系统层面
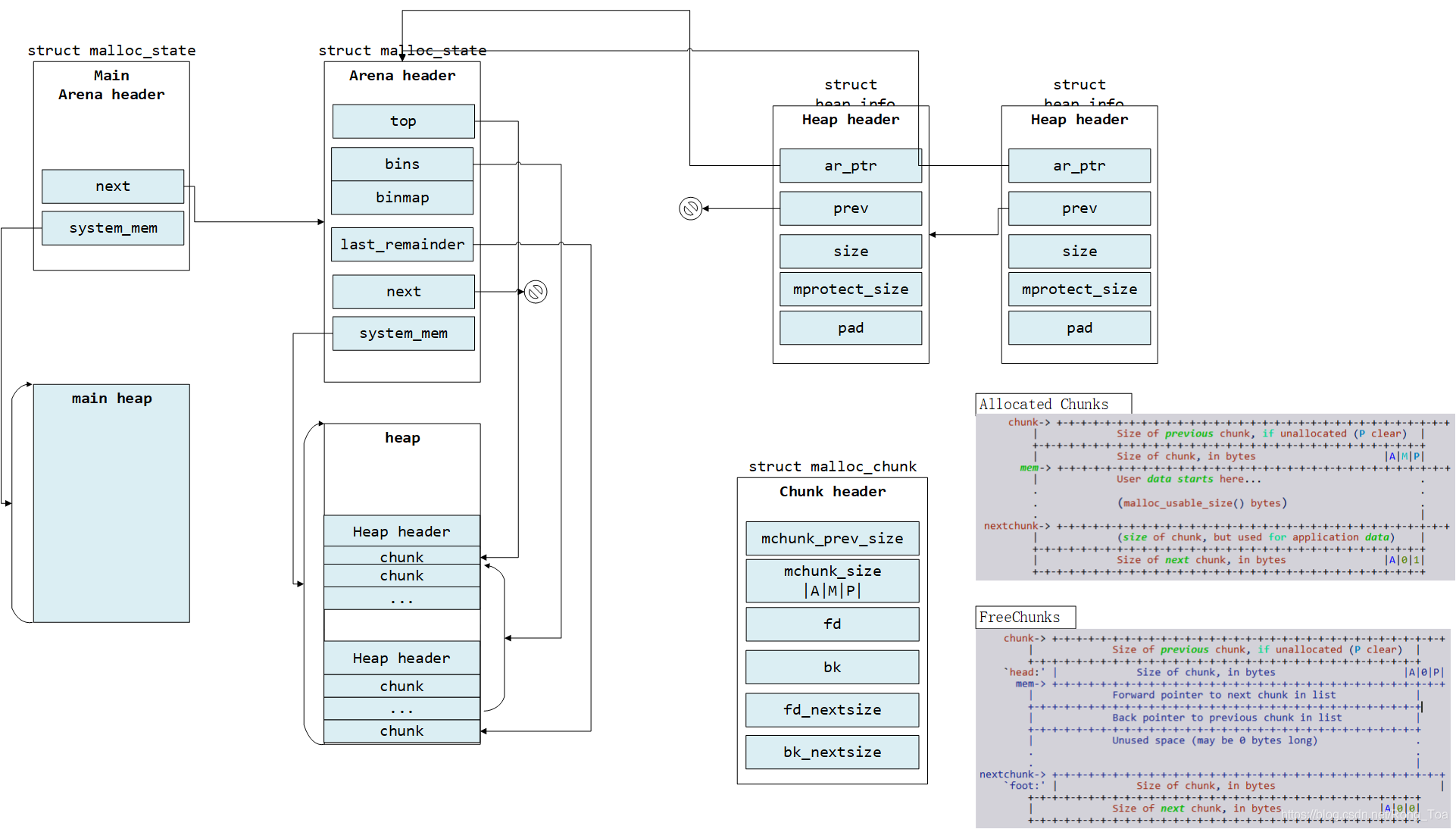
在「glibc malloc」中主要有 3 种数据结构:
malloc_state(Arena header):一个 thread arena 可以维护多个堆,这些堆共享同一个 arena header。Arena header 描述的信息包括:bins、top chunk、last remainder chunk 等;
heap_info(Heap Header):每个堆都有自己的堆 Header(注:也即头部元数据)。当这个堆的空间耗尽时,新的堆(而非连续内存区域)就会被 mmap 当前堆的 aerna 里;
malloc_chunk(Chunk header):根据用户请求,每个堆被分为若干 chunk。每个 chunk 都有自己的 chunk header。内存管理使用 malloc_chunk,把 heap 当作 link list 从一个内存块游走到下一个块。
//基于GLibc-2.32/*have_fastchunks indicates that there are probably some fastbin chunks.It is set true on entering a chunk into any fastbin, and cleared early inmalloc_consolidate. The value is approximate since it may be set when thereare no fastbin chunks, or it may be clear even if there are fastbin chunksavailable. Given it's sole purpose is to reduce number of redundant calls tomalloc_consolidate, it does not affect correctness. As a result we can safelyuse relaxed atomic accesses.*/struct malloc_state{/* Serialize access. */__libc_lock_define (, mutex);/* Flags (formerly in max_fast). */int flags;/* Set if the fastbin chunks contain recently inserted free blocks. *//* Note this is a bool but not all targets support atomics on booleans. */int have_fastchunks;/* Fastbins */mfastbinptr fastbinsY[NFASTBINS];/* Base of the topmost chunk -- not otherwise kept in a bin */mchunkptr top;/* The remainder from the most recent split of a small request */mchunkptr last_remainder;/* Normal bins packed as described above */mchunkptr bins[NBINS * 2 - 2];/* Bitmap of bins */unsigned int binmap[BINMAPSIZE];/* Linked list */struct malloc_state *next;/* Linked list for free arenas. Access to this field is serializedby free_list_lock in arena.c. */struct malloc_state *next_free;/* Number of threads attached to this arena. 0 if the arena is onthe free list. Access to this field is serialized byfree_list_lock in arena.c. */INTERNAL_SIZE_T attached_threads;/* Memory allocated from the system in this arena. */INTERNAL_SIZE_T system_mem;INTERNAL_SIZE_T max_system_mem;};/* A heap is a single contiguous memory region holding (coalesceable)malloc_chunks. It is allocated with mmap() and always starts at anaddress aligned to HEAP_MAX_SIZE. */typedef struct _heap_info{mstate ar_ptr; /* Arena for this heap. */struct _heap_info *prev; /* Previous heap. */size_t size; /* Current size in bytes. */size_t mprotect_size; /* Size in bytes that has been mprotectedPROT_READ|PROT_WRITE. *//* Make sure the following data is properly aligned, particularlythat sizeof (heap_info) + 2 * SIZE_SZ is a multiple ofMALLOC_ALIGNMENT. */char pad[-6 * SIZE_SZ & MALLOC_ALIGN_MASK];} heap_info;/*This struct declaration is misleading (but accurate and necessary).It declares a "view" into memory allowing access to necessaryfields at known offsets from a given base. See explanation below.*/struct malloc_chunk {INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */struct malloc_chunk* fd; /* double links -- used only if free. */struct malloc_chunk* bk;/* Only used for large blocks: pointer to next larger size. */struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */struct malloc_chunk* bk_nextsize;};
2.1.1. main_arena
/* There are several instances of this struct ("arenas") in thismalloc. If you are adapting this malloc in a way that does NOT usea static or mmapped malloc_state, you MUST explicitly zero-fill itbefore using. This malloc relies on the property that malloc_stateis initialized to all zeroes (as is true of C statics). */static struct malloc_state main_arena ={.mutex = _LIBC_LOCK_INITIALIZER,.next = &main_arena,.attached_threads = 1};
2.2. 用户层面
- 当某一线程需要调用 malloc() 分配内存空间时,该线程先查看线程私有变量中是否已经存在一个分配区;
- 如果存在,尝试对该分配区加锁,如果加锁成功,使用该分配区分配内存;
- 如果失败,该线程搜索循环链表试图获得一个没有加锁的分配区。
- 如果所有的分配区都已经加锁,那么 malloc() 会开辟一个新的分配区,把该分配区加入到全局分配区循环链表并加锁,然后使用该分配区进行分配内存操作。
- 在释放操作中,线程同样试图获得待释放内存块所在分配区的锁,如果该分配区正在被别的线程使用,则需要等待直到其他线程释放该分配区的互斥锁之后才可以进行释放操作。
2.2.1. 线程中内存管理
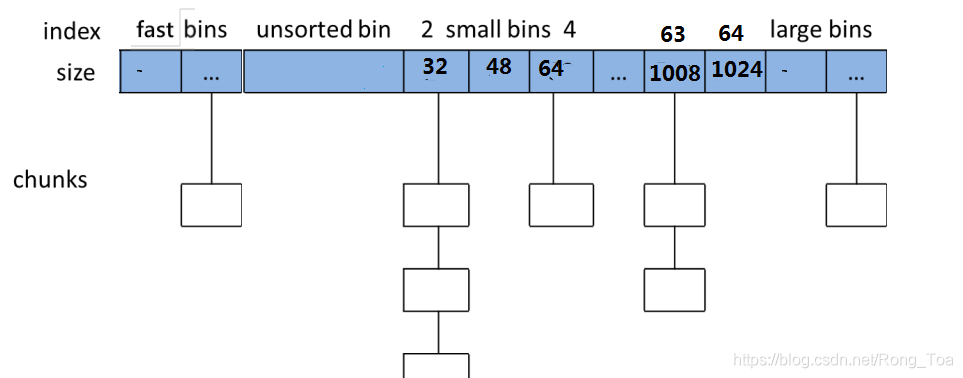
对于空闲的 chunk,ptmalloc 采用分箱式内存管理方式,每一个内存分配区中维护着[bins]的列表数据结构,用于保存free chunks。
根据空闲 chunk 的大小和处于的状态将其放在四个不同的 bin 中,这四个空闲 chunk 的容器包括 fast bins,unsorted bin, small bins 和 large bins。
从工作原理来看:
Fast bins是小内存块的高速缓存,当一些大小小于 64 字节的 chunk 被回收时,首先会放入 fast bins 中,在分配小内存时,首先会查看 fast bins 中是否有合适的内存块,如果存在,则直接返回 fast bins 中的内存块,以加快分配速度。Unsorted bin只有一个,回收的 chunk 块必须先放到 unsorted bin 中,分配内存时会查看 unsorted bin 中是否有合适的 chunk,如果找到满足条件的 chunk,则直接返回给用户,否则将 unsorted bin 的所有 chunk 放入 small bins 或是 large bins 中。Small bins用于存放固定大小的 chunk,共 64 个 bin,最小的 chunk 大小为 16 字节或 32 字节,每个 bin 的大小相差 8 字节或是 16 字节,当分配小内存块时,采用精确匹配的方式从 small bins 中查找合适的 chunk。Large bins用于存储大于等于 512B 或 1024B 的空闲 chunk,这些 chunk 使用双向链表的形式按大小顺序排序,分配内存时按最近匹配方式从 large bins 中分配 chunk。
从作用来看:
Fast bins可以看着是 small bins 的一小部分 cache,主要是用于提高小内存的分配效率,虽然这可能会加剧内存碎片化,但也大大加速了内存释放的速度!Unsorted bin可以重新使用最近 free 掉的 chunk,从而消除了寻找合适 bin 的时间开销,进而加速了内存分配及释放的效率。Small bins相邻的 free chunk 将被合并,这减缓了内存碎片化,但是减慢了 free 的速度;Large bin中所有 chunk 大小不一定相同,各 chunk 大小递减保存。最大的 chunk 保存顶端,而最小的 chunk 保存在尾端;查找较慢,且释放时两个相邻的空闲 chunk 会被合并。
其中fast bins保存在malloc_state结构的fastbinsY变量中,其他三者保存在malloc_state结构的 bins 变量中。
2.2.2. Chunk 说明
一个 arena 中最顶部的 chunk 被称为「top chunk」。它不属于任何 bin 。当所有 bin 中都没有合适空闲内存时,就会使用 top chunk 来响应用户请求。
当 top chunk 的大小比用户请求的大小小的时候,top chunk 就通过 sbrk(main arena)或 mmap( thread arena)系统调用扩容。
「last remainder chunk」即最后一次 small request 中因分割而得到的剩余部分,它有利于改进引用局部性,也即后续对 small chunk 的 malloc 请求可能最终被分配得彼此靠近。
当用户请求 small chunk 而无法从 small bin 和 unsorted bin 得到服务时,分配器就会通过扫描 binmaps 找到最小非空 bin。
正如前文所提及的,如果这样的 bin 找到了,其中最合适的 chunk 就会分割为两部分:返回给用户的 User chunk 、添加到 unsorted bin 中的 Remainder chunk。这一 Remainder chunk 就将成为 last remainder chunk。当用户的后续请求 small chunk,并且 last remainder chunk 是 unsorted bin 中唯一的 chunk,该 last remainder chunk 就将分割成两部分:返回给用户的 User chunk、添加到 unsorted bin 中的 Remainder chunk(也是 last remainder chunk)。因此后续的请求的 chunk 最终将被分配得彼此靠近。
存在的问题
- 如果后分配的内存先释放,无法及时归还系统。因为 ptmalloc 收缩内存是从 top chunk 开始, 如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
- 内存不能在线程间移动,多线程使用内存不均衡将导致内存浪费
- 每个 chunk 至少 8 字节的开销很大
- 不定期分配长生命周期的内存容易造成内存碎片,不利于回收。
- 加锁耗时,无论当前分区有无耗时,在内存分配和释放时,会首先加锁,在多核多线程情况下,对主分配区竞争激烈,严重影响性能。
从上述来看ptmalloc 的主要问题其实是内存浪费、内存碎片、以及加锁导致的性能问题。
备注:glibc 2.26(2017-08-02) 中已经添加了 tcache(thread local cache) 优化 malloc 速度
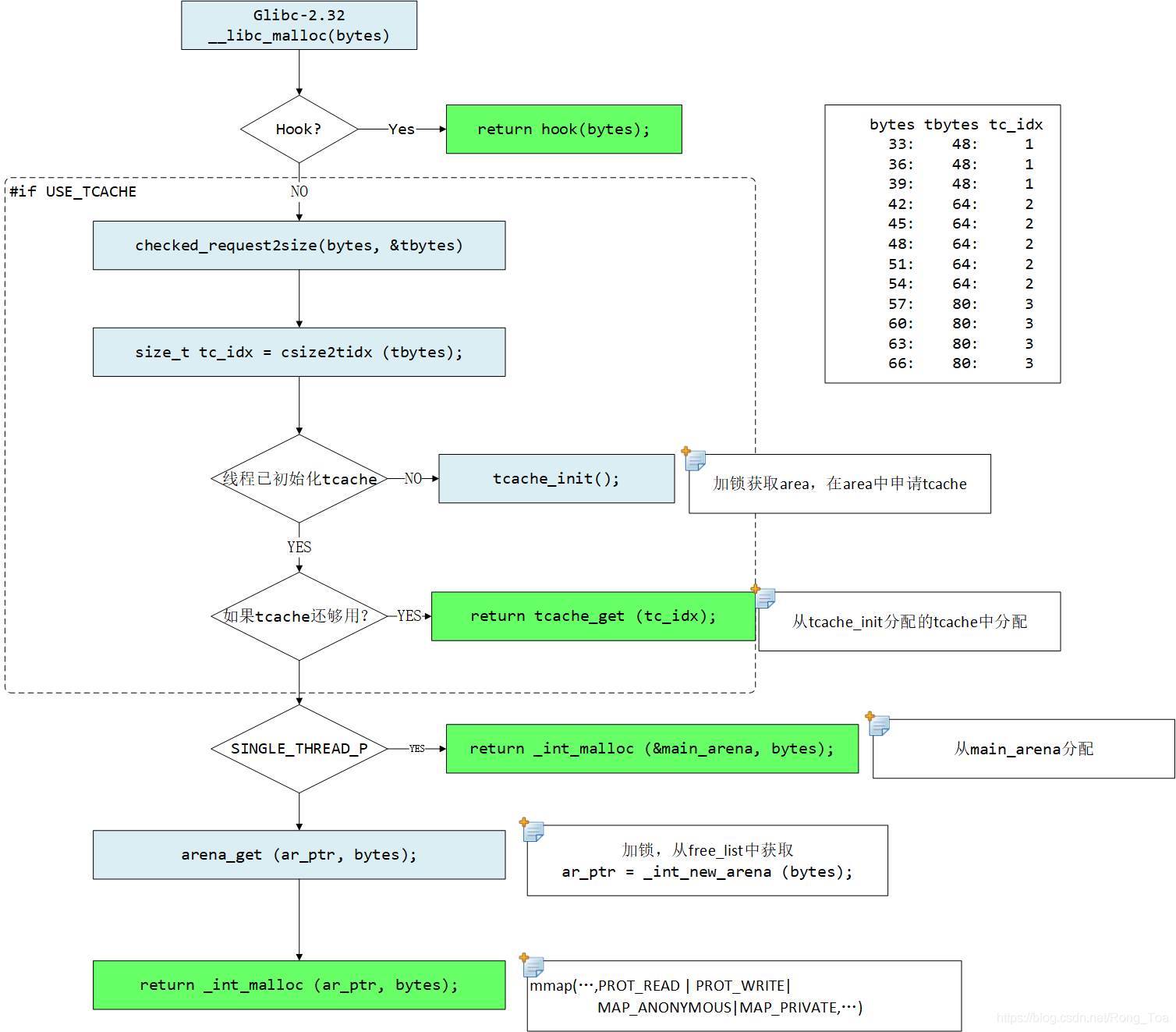
2.3. __libc_malloc(glibc 2.32)
2.4. 主分配去与非主分配区
内存分配器中,为了解决多线程竞争锁的问题,分为主分配去 main_area 和非主分配区 no_main_area。
- 主分配区和非主分配区形成一个链表进行管理。
- 每个分配区利用互斥锁使线程对于该分配区的访问互斥。
- 每个进程只有一个主分配区,允许多个非主分配区。
- ptmalloc 根据系统对分配区的争用动态增加分配区的大小,分配区的数量一旦增加,则不会减少。
- 主分配区可以使用 brk 和 mmap 来分配,非主分配区只能用 mmap 来映射。
- 申请小内存是会产生很多内存碎片,ptmalloc 在整理时也要对分配区做加锁操作。
当一个线程需要 malloc 分配内存:
- 先查看该线程私有变量中是否已经存在一个分配区;
- 若存在,尝试加锁;
- 若加锁成功,使用该分配区分配内存;
- 若失败,遍历循环链表,获取一个未加锁的分配区;
- 若没找到未加锁分配区,开辟新的分配区,加入全局链表并加锁,然后分配内存;
当 free 释放内存:
- 先获取待释放内存块所在的分配区的锁;
- 若有其他线程持有该锁,必须等待其他线程释放该分配区互斥锁;
3. jemalloc(FackBook,FreeBSD,FireFox)
jemalloc 是 facebook 推出的,目前在firefox、facebook服务器、android 5.0等服务中大量使用。 jemalloc 最大的优势还是其强大的多核 / 多线程分配能力.
以现代计算机硬件架构来说, 最大的瓶颈已经不再是内存容量或 cpu 速度, 而是多核 / 多线程下的 lock contention(锁竞争). 因为无论 CPU 核心数量如何多, 通常情况下内存只有一份. 可以说, 如果内存足够大, CPU 的核心数量越多, 程序线程数越多, jemalloc 的分配速度越快。
jemalloc 是通用的 malloc(3)实现,它强调避免碎片和可扩展的并发支持。jemalloc 于 2005 年首次作为FreeBSD libc分配器使用,从那时起,它便进入了许多依赖其可预测行为的应用程序。2010 年,jemalloc 的开发工作扩大到包括开发人员支持功能,例如堆分析和大量的监视 / 调整挂钩。现代的 jemalloc 版本继续被集成回 FreeBSD 中,因此多功能性仍然至关重要。正在进行的开发工作趋向于使 jemalloc 成为各种要求苛刻的应用程序的最佳分配器,并消除 / 减轻对实际应用程序有实际影响的弱点。
3.1. 系统层面
对于一个多线程 + 多 CPU 核心的运行环境, 传统分配器中大量开销被浪费在lock contention和false sharing上, 随着线程数量和核心数量增多, 这种分配压力将越来越大.针对多线程, 一种解决方法是将一把 global lock 分散成很多与线程相关的 lock. 而针对多核心, 则要尽量把不同线程下分配的内存隔离开, 避免不同线程使用同一个 cache-line 的情况. 按照上面的思路, 一个较好的实现方式就是引入 arena. 将内存划分成若干数量的 arenas, 线程最终会与某一个 arena 绑定. 由于两个 arena 在地址空间上几乎不存在任何联系, 就可以在无锁的状态下完成分配. 同样由于空间不连续, 落到同一个 cache-line 中的几率也很小, 保证了各自独立。由于 arena 的数量有限, 因此不能保证所有线程都能独占 arena, 分享同一个 arena 的所有线程, 由该 arena 内部的 lock 保持同步.
3.1.1. struct arena_s
struct arena_s {/** Number of threads currently assigned to this arena. Each thread has* two distinct assignments, one for application-serving allocation, and* the other for internal metadata allocation. Internal metadata must* not be allocated from arenas explicitly created via the arenas.create* mallctl, because the arena.<i>.reset mallctl indiscriminately* discards all allocations for the affected arena.** 0: Application allocation.* 1: Internal metadata allocation.** Synchronization: atomic.*/atomic_u_t nthreads[2];/* Next bin shard for binding new threads. Synchronization: atomic. */atomic_u_t binshard_next;/* 绑定的新线程的下一个bin 碎片 *//** When percpu_arena is enabled, to amortize the cost of reading /* updating the current CPU id, track the most recent thread accessing* this arena, and only read CPU if there is a mismatch.*/tsdn_t *last_thd;/* 用于跟踪上一次使用的CPU *//* Synchronization: internal. */arena_stats_t stats;/* arena统计信息 *//** Lists of tcaches and cache_bin_array_descriptors for extant threads* associated with this arena. Stats from these are merged* incrementally, and at exit if opt_stats_print is enabled.** Synchronization: tcache_ql_mtx.*/ql_head(tcache_slow_t) tcache_ql;/* tcache指针 */ql_head(cache_bin_array_descriptor_t) cache_bin_array_descriptor_ql;/* cache bin array描述符指针 */malloc_mutex_t tcache_ql_mtx;/* 锁 *//** Represents a dss_prec_t, but atomically.** Synchronization: atomic.*/atomic_u_t dss_prec;/** Extant large allocations.** Synchronization: large_mtx.*/edata_list_active_t large;/* 现存的大块分配内存 *//* Synchronizes all large allocation/update/deallocation. */malloc_mutex_t large_mtx;/* 大块内存的锁 *//* The page-level allocator shard this arena uses. */pa_shard_t pa_shard;/* 页级别分配器碎片 *//** bins is used to store heaps of free regions.** Synchronization: internal.*/bins_t bins[SC_NBINS];/* 存放堆的free regions *//** Base allocator, from which arena metadata are allocated.** Synchronization: internal.*/base_t *base;/* base 分配器 *//* Used to determine uptime. Read-only after initialization. */nstime_t create_time;/* 创建时间 */};
【目前 jemalloc 5.2.1 中已经找不到 chunk 结构了】
chunk 是仅次于 arena 的次级内存结构,arena 都有专属的 chunks, 每个 chunk 的头部都记录了 chunk 的分配信息。chunk 是具体进行内存分配的区域,目前的默认大小是 4M。chunk 以 page(默认为 4K) 为单位进行管理,每个 chunk 的前几个 page(默认是 6 个)用于存储 chunk 的元数据,后面跟着一个或多个 page 的 runs。后面的 runs 可以是未分配区域, 多个小对象组合在一起组成 run, 其元数据放在 run 的头部。 大对象构成的 run, 其元数据放在 chunk 的头部。在使用某一个 chunk 的时候,会把它分割成很多个 run,并记录到 bin 中。不同 size 的 class 对应着不同的 bin,在 bin 里,都会有一个红黑树来维护空闲的 run,并且在 run 里,使用了 bitmap 来记录了分配状态。此外,每个 arena 里面维护一组按地址排列的可获得的 run 的红黑树。

3.2. 用户层面
jemalloc 按照内存分配请求的尺寸,分了 small object (例如 1 – 57344B)、 large object (例如 57345 – 4MB )、 huge object (例如 4MB 以上)。jemalloc 同样有一层线程缓存的内存名字叫 tcache,当分配的内存大小小于 tcache_maxclass 时,jemalloc 会首先在 tcache 的 small object 以及 large object 中查找分配,tcache 不中则从 arena 中申请 run,并将剩余的区域缓存到 tcache。若 arena 找不到合适大小的内存块, 则向系统申请内存。当申请大小大于 tcache_maxclass 且大小小于 huge 大小的内存块时,则直接从 arena 开始分配。而 huge object 的内存不归 arena 管理, 直接采用 mmap 从 system memory 中申请,并由一棵与 arena 独立的红黑树进行管理。
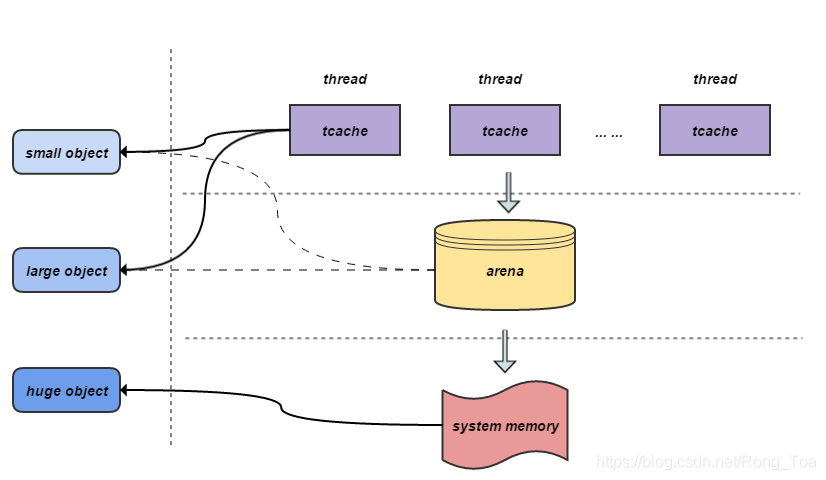
3.3. jemalloc 的优势
多线程下加锁大大减少
4. tcmalloc(Google,Golang)
由于网上介绍的版本与代码版本找不到匹配关系,甚至介绍版本是 C 语言开发,网上下载的代码为 C++ 开发,此处不做详细的源码讲解,只做结构性介绍。
tcmalloc 是 Google 开发的内存分配器,在 Golang、Chrome 中都有使用该分配器进行内存分配。有效的优化了 ptmalloc 中存在的问题。当然为此也付出了一些代价,按下表,先看 tcmalloc 的具体实现。
4.1. 系统层面
tcmalloc 把4kb的连续内存称为一个页 (Page),可以用下面两个常量来描述:
inline constexpr size_t kPageShift = 12;inline constexpr size_t kPageSize = 1 << kPageShift;
对于一个指针 p,p>>kPageShift即是 p 的页地址。
// Information kept for a span (a contiguous run of pages).struct Span {PageID start; // Starting page numberLength length; // Number of pages in spanSpan* next; // Used when in link listSpan* prev; // Used when in link listunion {void* objects; // Linked list of free objects// Span may contain iterator pointing back at SpanSet entry of// this span into set of large spans. It is used to quickly delete// spans from those sets. span_iter_space is space for such// iterator which lifetime is controlled explicitly.char span_iter_space[sizeof(SpanSet::iterator)];};unsigned int refcount : 16; // Number of non-free objectsunsigned int sizeclass : 8; // Size-class for small objects (or 0)unsigned int location : 2; // Is the span on a freelist, and if so, which?unsigned int sample : 1; // Sampled object?bool has_span_iter : 1; // If span_iter_space has valid// iterator. Only for debug builds.// What freelist the span is on: IN_USE if on none, or normal or returnedenum {IN_USE,ON_NORMAL_FREELIST,ON_RETURNED_FREELIST};}; // We segregate spans of a given size into two circular linked// lists: one for normal spans, and one for spans whose memory// has been returned to the system.struct SpanList {Span normal;Span returned;};// Array mapping from span length to a doubly linked list of free spans//// NOTE: index 'i' stores spans of length 'i + 1'. SpanList free_[kMaxPages];// Sets of spans with length > kMaxPages.//// Rather than using a linked list, we use sets here for efficient// best-fit search.SpanSet large_normal_;SpanSet large_returned_;
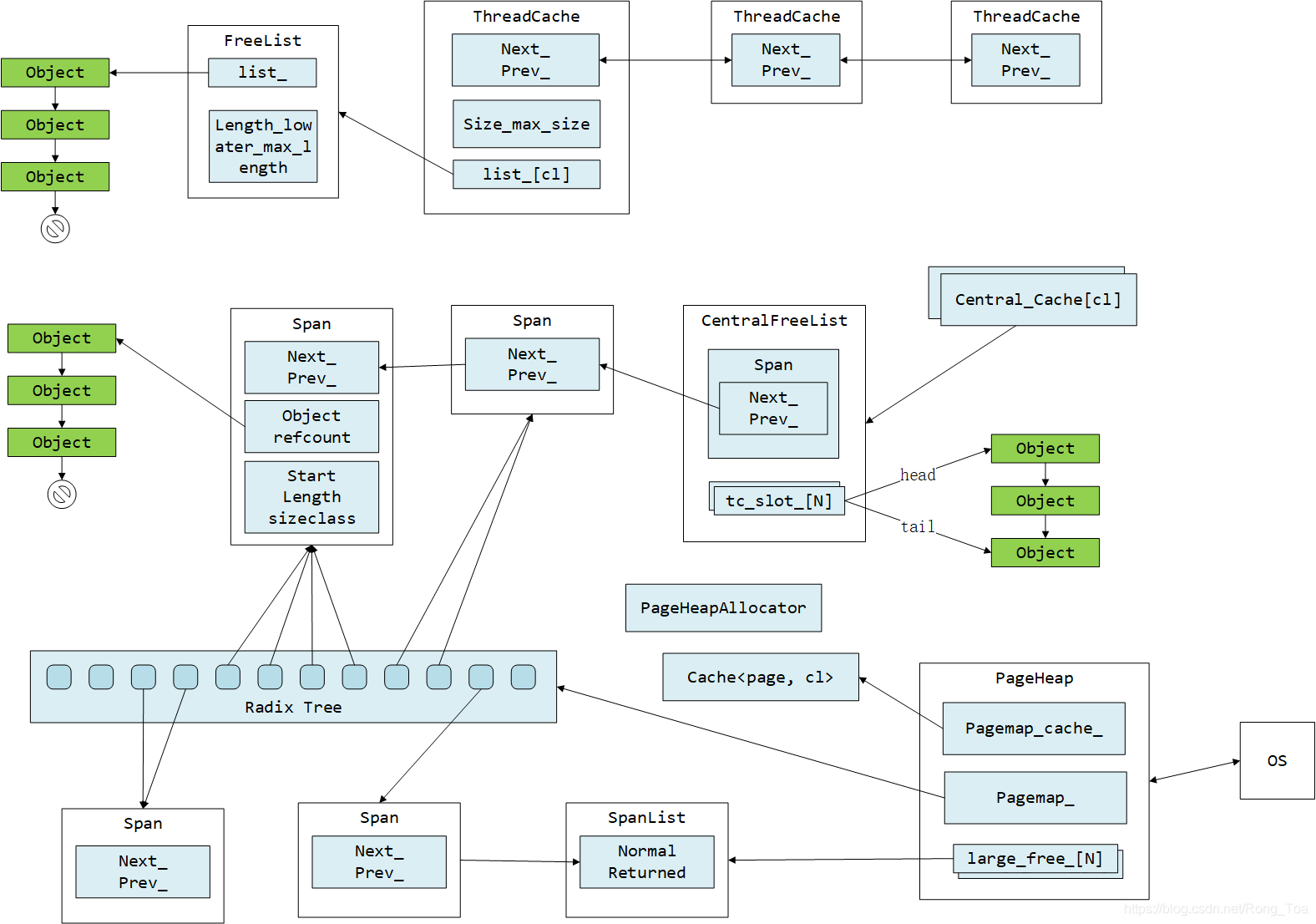
4.2. 用户层面
TCMalloc 是专门对多线并发的内存管理而设计的,TCMalloc 主要是在线程级实现了缓存,使得用户在申请内存时大多情况下是无锁内存分配。
从用户角度看 tcmalloc 架构
整个 tcmalloc 实现了三级缓存,分别是:
- ThreadCache – 线程级别缓存;
- CentralCache - 中央缓存 CentralFreeList;(需要加锁访问)
- PageHeap – 页缓存;(需要加锁访问)
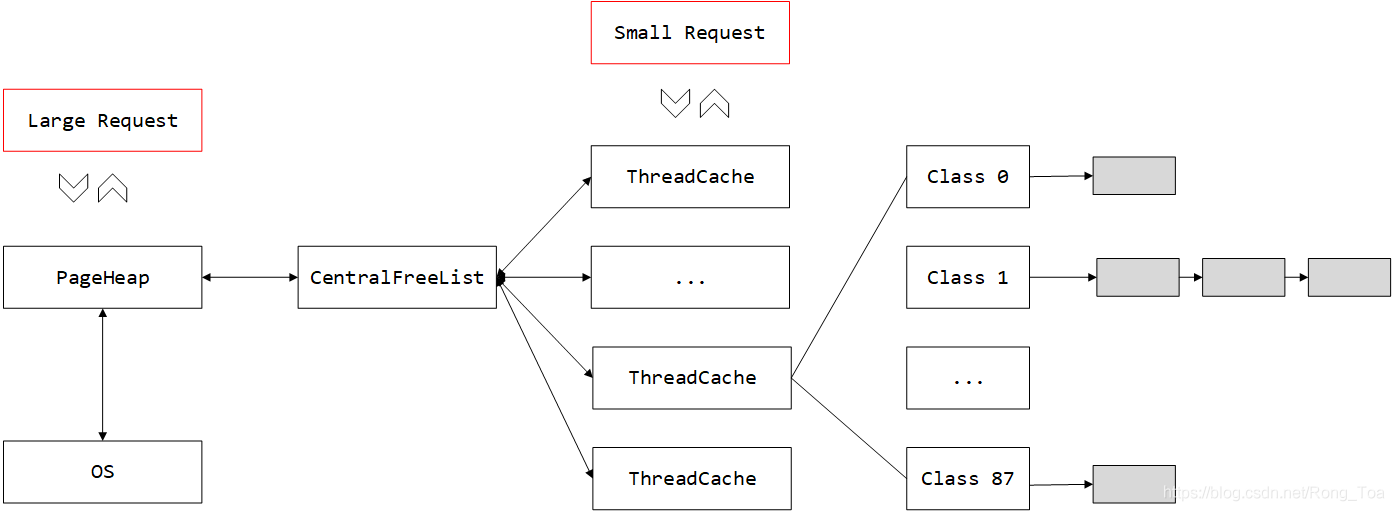
Tcmalloc 分配内存的流程:
- 每个线程都有一个线程局部 ThreadCache,ThreadCache 中包含一个链表数据组 FreeList list_[kNumClasses],维护了不同规格的空闲内存的规则的内存。
- 如果 ThreadCache 对象不够了,就从 CentralCache 中批量分配;
- 如果 CentralCache 依然不够,就从 PageHeap 中申请 Span;
- PageHeap 首先从 free[n,128]中查找,然后到 large set 中查找,目标是为了找到一个最小满足要求的空闲 Span,优先使用 normal 类链表中的 Span。
- 如果找到了一个 Span,则尝试分裂(Carve)这个 Span 并分配出去;如果所有的链表中都没找到 length>=n 的 Span,则只能从操作系统中申请了。
- Tcmalloc 一次最少向 OS 申请 1MB 内存,默认情况下使用是 sbrk(),sbrk() 失败后使用 mmap()。
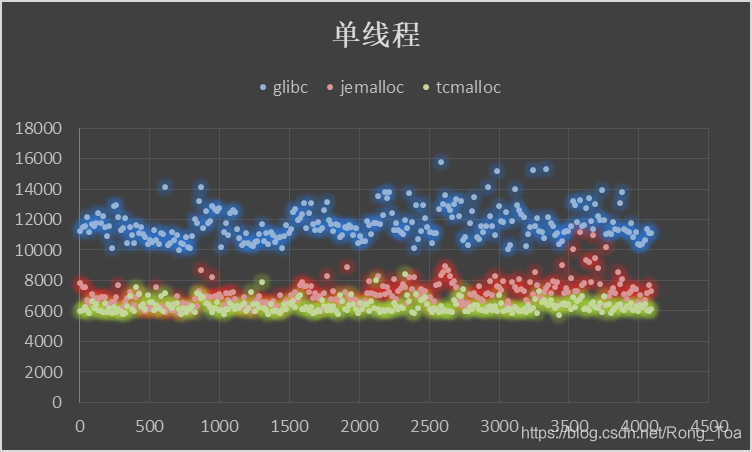
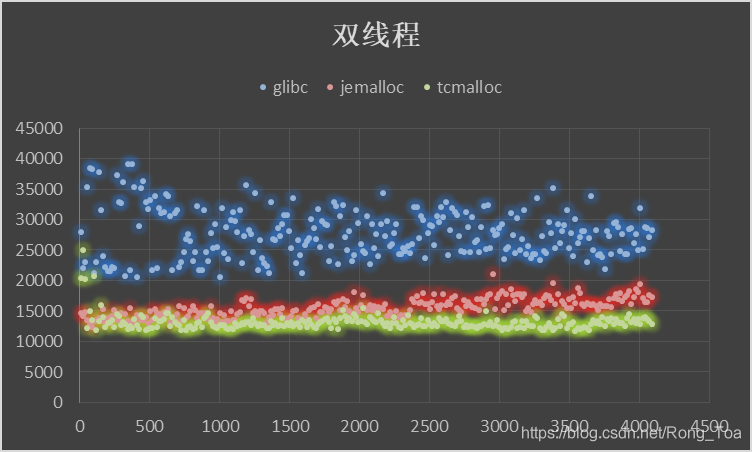
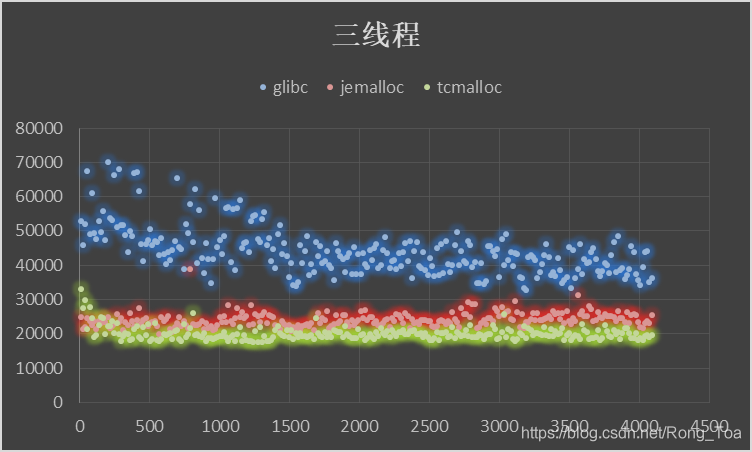
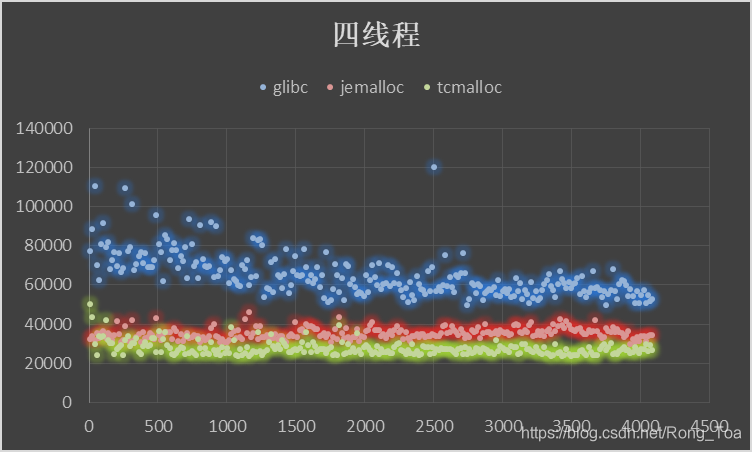
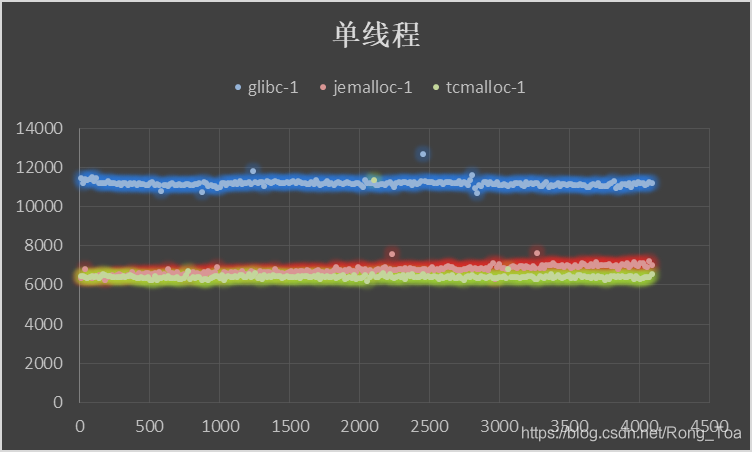
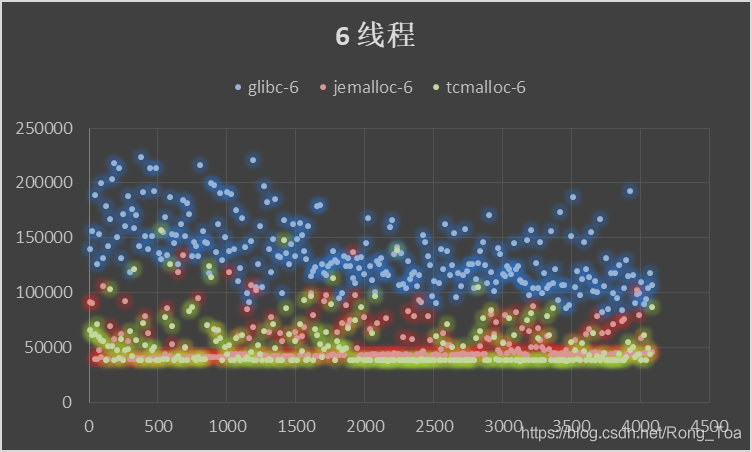
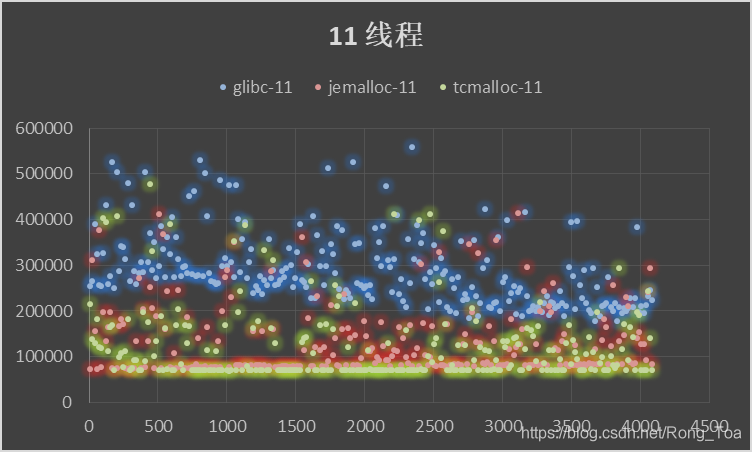
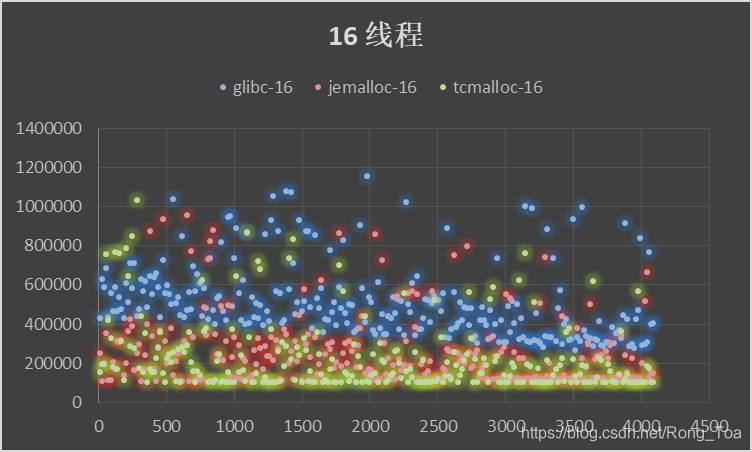
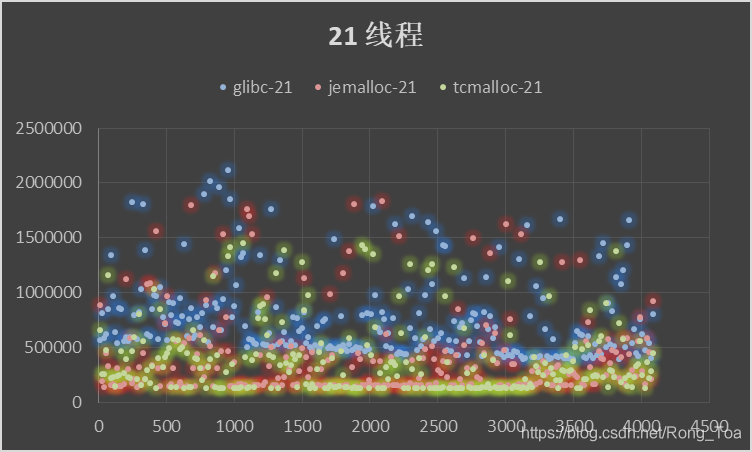
5. 三种分配器的对比测试
内存分配无非需要的是 malloc 和 free 的性能,版本信息如下:
- ptmalloc(
glibc-2.25.1-31.base.el7) - jemalloc(
5.2.1-586-g92e189be8b725be1f4de5f476f410173db29bc7d) - tcmalloc(
gperftools 2.0)
横坐标申请内存块大小malloc()入参,纵坐标为时间[MicroSecond],分别进行循环往复 200000 次的 malloc-free 运算求和。
5.1. 虚拟机
5.2. 服务器
6. 总结
- 作为基础库的 ptmalloc 是最为稳定的内存管理器,无论在什么环境下都能适应,但是分配效率相对较低。
- tcmalloc 针对多核情况有所优化,性能有所提高,但是内存占用稍高,大内存分配容易出现 CPU 飙升。
- jemalloc 的内存占用更高,但是在多核多线程下的表现也最为优异。
在什么情况下我们应该考虑好内存分配如何管理:
- 多核多线程的情况下,内存管理需要考虑:内存分配加锁、异步内存释放、多线程之间的内存共享、线程的生命周期;
- 内存当作磁盘使用的情况下,需要考虑内存分配和释放的效率,是使用内存管理库还是应该自己进行大对象大内存的管理(在搜索以及推荐系统中尤为突出)。
7. 参考文章
- 《jemalloc 简介》
- 《图解 tcmalloc 内存分配器》
- 《TCMalloc:线程缓存 Malloc 以及 tcmalloc 与 ptmalloc 性能对比》
- 《ptmalloc、tcmalloc 与 jemalloc 内存分配器对比分析》
- 《使用 jemalloc 在 Go 中进行手动内存管理》
- 《理解 glibc malloc:主流用户态内存分配器实现原理》
- 《Glibc 内存管理 Ptmalloc2 源代码分析》
- 《TCMalloc 分析 - 如何减少内存碎片》
- 《TCMalloc 分析笔记 (gperftools-2.4)》
- 《jemalloc 源码解析 - 内存管理》
8. 参考链接
- http://mqzhuang.iteye.com/blog/1005909
- https://paper.seebug.org/papers/Archive/refs/heap/glibc%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86ptmalloc%E6%BA%90%E4%BB%A3%E7%A0%81%E5%88%86%E6%9E%90.pdf
- http://core-analyzer.sourceforge.net/index_files/Page335.html
- https://blog.csdn.net/maokelong95/article/details/51989081
- https://zhuanlan.zhihu.com/p/29216091
- https://zhuanlan.zhihu.com/p/29415507
- https://blog.csdn.net/zwleagle/article/details/45113303
- http://game.academy.163.com/library/2015/2/10/17713_497699.html
- https://www.cnblogs.com/taoxinrui/p/6492733.html
- https://blog.csdn.net/vector03/article/details/50634802
- http://brionas.github.io/2015/01/31/jemalloc%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90-%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86/
原文: https://blog.csdn.net/Rong_Toa/article/details/110689404
https://blog.csdn.net/Rong_Toa/article/details/110689404

若有收获,就点个赞吧
0 人点赞
