背景
使用 GPU 训练时, 一次训练任务无论是模型参数还是中间结果都需要占用大量显存. 为了避免每次训练重新开辟显存带来计算之外的开销, 一般框架的做法是在真正的训练任务开始前, 将每个节点的输入和输出, 以及模型参数的 shape 计算出来并全局开辟一次, 例如 Caffe 就是这种做法. 随着深度学习模型的发展和迭代, 不仅模型训练的数据 shape 可能发生变化, 就连模型本身在训练过程中也可能发生变化, 那么按照固定 shape 一次开辟显存的做法就不能满足需求了. 为此, TensorFlow 重新设计了较为灵活的显存管理机制, 它使用了名为 BFC 的分配算法, 并通过 BFC Allocator 为每个 Tensor 分配满足需求的显存. 本节我们将一起窥探 BFC Allocator 的设计思想.
从 Tensor 的创建谈起
为 Tensor 分配存储区的时机
在进入主题之前, 让我们先思考一个问题: TensorFlow 中的 Tensor 究竟是何时拿到所需存储区的呢? 答案是在 Tensor 对象被创建时就立即进行分配. 在 TensorFlow 的一轮训练结束后, 所有的 Tensor 都已经被释放, 下一轮计算开始后会按照需求重新创建 Tensor, 并为其分配新的存储空间. 下面的代码片段中我们可以看到 Tensor 创建时, 使用 Allocator 分配存储区的代码段.
在创建 Tensor 对象时需要传入一个 Allocator, 这个 Allocator 可以是任何实现类, 在 GPU 上使用的就是 BFCAllocator.
Tensor::Tensor(Allocator* a, DataType type, const TensorShape& shape): shape_(shape), buf_(nullptr) {set_dtype(type);CHECK_NOTNULL(a);if (shape_.num_elements() > 0 || a->ShouldAllocateEmptyTensors()) {CASES(type, buf_ = new Buffer<T>(a, shape.num_elements()));}if (buf_ != nullptr && buf_->data() != nullptr && LogMemory::IsEnabled()) {LogMemory::RecordTensorAllocation("Unknown", LogMemory::UNKNOWN_STEP_ID,*this);}}
上面代码的第 6 行创建了 Buffer 对象, 它就是 Tensor 对象的实际存储区, 让我们看看其构造函数的实现内容.
emplate <typename T>Buffer<T>::Buffer(Allocator* a, int64 n,const AllocationAttributes& allocation_attr): BufferBase(a, a->Allocate<T>(n, allocation_attr)), elem_(n) {}
上面的代码段重点在于第 4 行, 因为在此处调用了 Allocate 函数, 此时 Buffer 真正获得了一片实际的存储区. 这已经能够说明存储区分配的时机是在一个 Tensor 对象被创建时立即发生的.
遇到的问题——显存分配与回收的性能需求
Tensor 在每次创建时会得到存储区域, 而每一轮训练都要重新创建新的 Tensor, 那么这里面临的一个问题: 如此频繁的分配和回收存储区, 如何才能做的高效? 试想对于 GPU 来说, 如果 Allocate 函数直接封装 CUDA 中昂贵的 cudaMalloc 函数, 当 Tensor 被释放时直接调用 cudaFree 函数, 那么训练速度将会因为这些 overhead 大打折扣.
解决问题的基本思路——存储池
如果你对操作系统这门课比较熟悉, 那么应该很容易想到解决办法: 将显存按照不同的大小一次性开辟出来, 并组成存储池, 每次调用 Allocate 函数时从存储池中获取, Tensor 回收时将显存重新挂到存储池中. 这样做确实可以满足性能需求, 但是需要为此设计一个相对复杂的存储管理器. BFC Allocator 就是 TensorFlow 中管理 GPU 显存的存储管理器.
好了, 需求和背景都已经了解了, 接下来可以进入正题了, 让我们先从原理开始说起.
Best-Fit with Coalescing 与 dlmalloc
BFC 的全称是 Best-Fit with Coalescing. 从 TensorFlow 源码注释中得知, BFC 算法并非 TensorFlow 完全原创, 而是 dlmalloc 的一个简单实现版本. dlmalloc 是一款优秀的存储分配器, 它以 Doug Lea 的名字命名, 这个站点包含了 dlmalloc 的详细说明, 有兴趣的同学可以去看一看. 之所以在 TensorFlow 中引入一个简单版本的 dlmalloc 算法, 是因为该算法可以非常高效的按需分配和回收存储区, 并尽可能减少存储碎片.
BFC Allocator 基本原理
核心在于将存储区划分成块, 并挂入存储池中进行管理. 将存储区划分成存储块时要满足以下要求.
- 块内地址是连续地址
- 存储池中的块要以每个块基地址升序排列,并组织成双向链表
- 高地址块的 size 大于低地址块的 size
TensorFlow 将存储块以及相应的块信息抽象为一种叫做 Chunk 的数据结构.
核心数据结构
Chunk
Chunk 是 BFC 最核心的数据结构之一, 在 TensorFlow 源码中是以 struct 来描述的. 具体来说, 一个 Chunk 代表一段连续的存储空间, BFC 要求各个 Chunk 要按照基地址升序排列并组织成双向链表, 下图展示了 Chunk 的结构以及 Chunk 之间的连接关系. 初始时, 每个 Chunk 都有自己的 size, 并且这些 size 都是以 256 字节为模. 应当注意, 每个 Chunk 或者完全被标记为使用, 或者完全标记为空闲, 不存在该 Chunk 内只有部分空间被使用的情况.
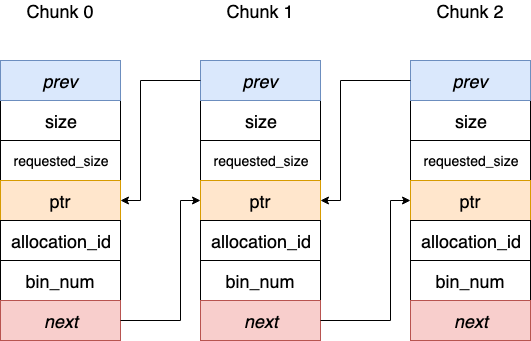
prev, next: 这两个变量起到指针作用, 分别指向前驱和后继 Chunk. 因为在 BFC Allocator 模块中多个 chunk 都被放入了 vector 中, 所以这两个指针实际上就是前驱和后继的 index
ptr: 该 Chunk 的起始存储地址, 或者叫基地址
size: 该 Chunk 描述存储区的实际总大小, 每个 Chunk 的 size 是不同的, 但都以 256 字节为模
requested_size: 该 Chunk 描述存储区的使用大小, 代表了用户请求使用的大小, 它一定小于等于 size. 因为 Chunk 不能被部分使用, 所以即使用户实际只使用 requested_size, 那么也只能将整个大小为 size 的 Chunk 全部分配出去, 显然这可能会造成一些碎片的浪费
allocation_id: 该值如果不为 0, 则代表已经被标记为使用, 反之则是空闲
bin_num: 代表该 Chunk 所在 Bin 的 Index. Bin 是另一个核心数据结构, 下面将会做详细介绍
Bin
如果我们想查询某一块符合条件的空闲 Chunk 并取出, 那么只能对双向链表做遍历, 显然这个效率不是很高. 为了加速查询某块 Chunk 的速度, 可以在创建 Chunk 链表时按一定顺序排列, 并将整个有序链表在逻辑上切分成多个段, 为每个段记录所包含的 Chunk 的范围, 这种结构就是 Bin, 它相当于一种索引. 因此, Bin 结构是为了方便 Chunk 的查询而出现的. 在 BFC Allocator 中, 每个段中 Chunk 的顺序是按照 size 和基地址升序排序的, 每个 Bin 都设有自己的 bin_size, 该 bin_size 表示该段包含的最小 Chunk 的 size. 这样一来, 用户端就可以根据所需要申请的 Memory 大小直接找到对应的 Bin, 然后在该 Bin 中遍历寻找适合的 Chunk. 为了能够根据 bin_size 直接定位到 Bin, 规定 bin_size 与 bin_num 的大小关系为: bin_size=256 * 2bin_num. 用户在申请 Memory 时, 会将实际大小映射到最适合的 bin_size 上, 然后再根据 bin_size 与 bin_num 的关系找到对应的 Bin, 进而在该段中遍历搜索.
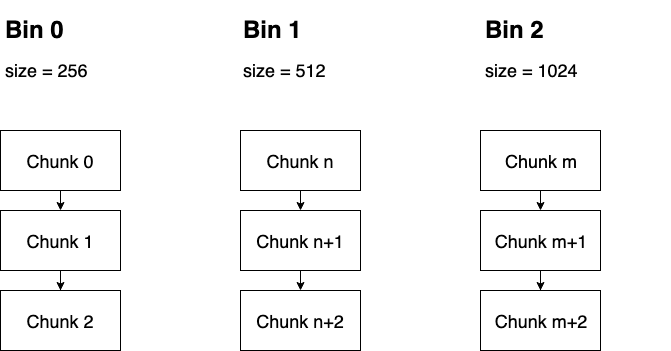
Bin 中 Chunk 的是通过 Set 组织的, 为了能在 Set 中体现双向链表的逻辑, 只需要让 Chunk 在 Set 中按照规则升序排列, 并修正前驱后继指针即可. 指定 Chunk 顺序的 Comparator 代码段定义在 Bin 结构中, 如下所示.
// Sort first by size and then use pointer address as a tie breaker.bool operator()(const ChunkHandle ha,const ChunkHandle hb) const NO_THREAD_SAFETY_ANALYSIS {const Chunk* a = allocator_->ChunkFromHandle(ha);const Chunk* b = allocator_->ChunkFromHandle(hb);if (a->size != b->size) {return a->size < b->size;}return a->ptr < b->ptr;}
辅助工具类
AllocationRegion 与 RegionManager
这两个类是起到辅助作用. BFC Allocator 每次分配存储区时都以 Chunk 为单位, 指向 Chunk 的指针又是 ChunkHandle 类型 (实际为数组下标) , 但分配存储的最终目的是把 Chunk 中指向存储区域的头指针 ptr 分配给请求方. 另外, 当系统回收存储区时, 面对的也是存储区的头指针, 那么如果不能根据头指针找到 Chunk 和 Bin 信息, 回收就不能成功. 因此这里显然应该设计一系列接口和函数: 它能够记录每次分配的 Chunk, 并且能够保存分配存储区的地址 ptr 与 Chunk 之间的映射关系. AllocationRegion 和 RegionManager 就是完成这些功能的接口.
具体而言, AllocationRegion 对应一次存储区分配的记录. 一次存储区分配的信息包括起始地址 ptr 和存储区大小 memory_size, 这可能包括多个 Chunk, 所以该结构要记录此次分配中所包含所有 Chunk 的信息. RegionManager 是 AllocationRegion 的管理器, 它维护了 AllocationRegion 的数组. 在 RegionManager 中, AllocationRegion 数组是需要按照 end_ptr 地址排序的.
利用 RegionManager 查询某个 ptr 所对应的 ChunkHandle 的时序图如下图所示.
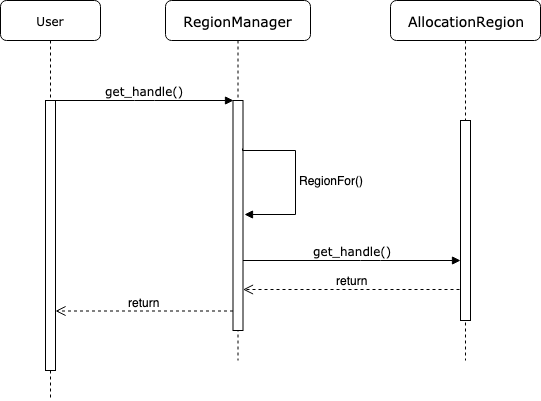
这部分功能较为简单, 所以不再展开代码逻辑, 感兴趣的同学可以阅读这两个类的定义立即就能理解.
BFC 分配与回收策略
介绍完基本结构和 BFC 的设计思想之后, 就可以试着去理解具体的存储区分配和回收过程了.
Allocate 流程
AllocateRawInternal
这是 BFCAllocator 的为用户分配 Chunk 的总体流程. 因为物理设备上实际的空闲存储区已经被事先开辟好, 并以 Chunk 的形式组织成了双向链表, 那么 BFC Allocator 为用户分配存储区时直接从 Chunk 中获取即可. 当双向链表中找不到合适的 Chunk 时, 不得不向物理设备上申请更多存储空间, 并创建新的 Chunk 放入到双向链表中, 并挂入到 B 相应的 Bin 中. 下面的流程图展示了这一过程, 该过程涉及到了几个比较重要的子过程. 它们分别是遍历搜索寻找最佳 Chunk 指针的 FIndChunkPtr 过程, 当 Chunk 链表中不存在合适的 Chunk 以至于不得不向物理设备申请新存储空间的 Extend 过程, 以及分配 Chunk 时为缓解碎片问题而出现的 SplitChunk 过程.
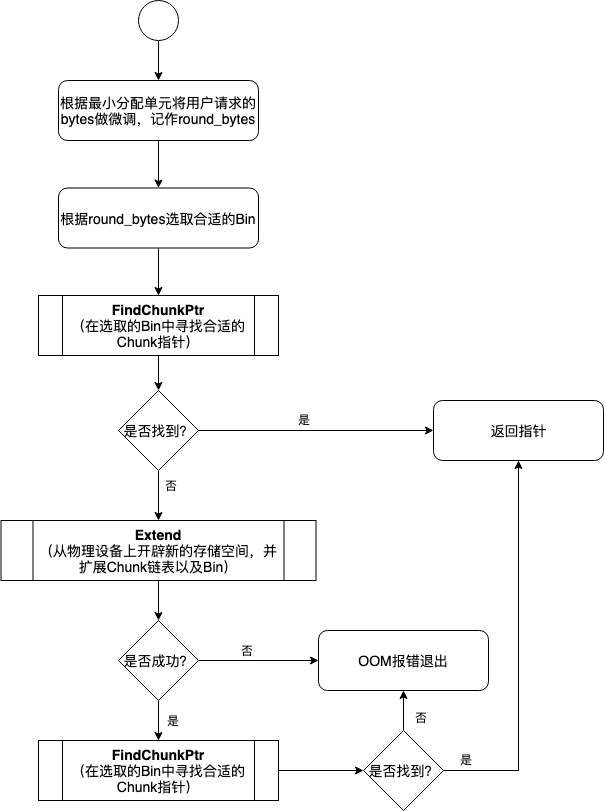
整体流程的代码如下所示.
void* BFCAllocator::AllocateRawInternal(size_t unused_alignment,size_t num_bytes,bool dump_log_on_failure,uint64 freed_before) {if (num_bytes == 0) {VLOG(2) << "tried to allocate 0 bytes";return nullptr;}// First, always allocate memory of at least kMinAllocationSize// bytes, and always allocate multiples of kMinAllocationSize bytes// so all memory addresses are nicely byte aligned.size_t rounded_bytes = RoundedBytes(num_bytes);// The BFC allocator tries to find the best fit first.BinNum bin_num = BinNumForSize(rounded_bytes);mutex_lock l(lock_);void* ptr = FindChunkPtr(bin_num, rounded_bytes, num_bytes, freed_before);if (ptr != nullptr) {return ptr;}// Try to extendif (Extend(unused_alignment, rounded_bytes)) {ptr = FindChunkPtr(bin_num, rounded_bytes, num_bytes, freed_before);if (ptr != nullptr) {return ptr;}}// We searched all bins for an existing free chunk to use and// couldn't find one. This means we must have run out of memory,// Dump the memory log for analysis.if (dump_log_on_failure) {LOG(WARNING) << "Allocator (" << Name() << ") ran out of memory trying "<< "to allocate " << strings::HumanReadableNumBytes(num_bytes)<< ". Current allocation summary follows.";DumpMemoryLog(rounded_bytes);LOG(WARNING) << RenderOccupancy();}return nullptr;}
FindChunkPtr 过程
因为 Chunk 在每个 Bin 中都是按照 size 和基地址升序排列, 所以搜索 Chunk 时只需顺序遍历 free_chunks 即可, 首个找到的符合要求的 Chunk 即为所求. 这个过程非常简单, 不再以图的形式描述, 只展示代码如下.
void* BFCAllocator::FindChunkPtr(BinNum bin_num, size_t rounded_bytes,size_t num_bytes, uint64 freed_before) {// First identify the first bin that could satisfy rounded_bytes.for (; bin_num < kNumBins; bin_num++) {// Start searching from the first bin for the smallest chunk that fits// rounded_bytes.Bin* b = BinFromIndex(bin_num);for (auto citer = b->free_chunks.begin(); citer != b->free_chunks.end();++citer) {const BFCAllocator::ChunkHandle h = (*citer);BFCAllocator::Chunk* chunk = ChunkFromHandle(h);DCHECK(!chunk->in_use());if (freed_before > 0 && freed_before < chunk->freed_count) {continue;}if (chunk->size >= rounded_bytes) {// We found an existing chunk that fits us that wasn't in use, so remove// it from the free bin structure prior to using.RemoveFreeChunkIterFromBin(&b->free_chunks, citer);// If we can break the size of the chunk into two reasonably large// pieces, do so. In any case don't waste more than// kMaxInternalFragmentation bytes on padding this alloc.const int64 kMaxInternalFragmentation = 128 << 20; // 128mbif (chunk->size >= rounded_bytes * 2 ||static_cast<int64>(chunk->size) - rounded_bytes >=kMaxInternalFragmentation) {SplitChunk(h, rounded_bytes);chunk = ChunkFromHandle(h); // Update chunk pointer in case it moved}// The requested size of the returned chunk is what the user// has allocated.chunk->requested_size = num_bytes;// Assign a unique id and increment the id counter, marking the// chunk as being in use.chunk->allocation_id = next_allocation_id_++;// Update stats.++stats_.num_allocs;stats_.bytes_in_use += chunk->size;stats_.peak_bytes_in_use =std::max(stats_.peak_bytes_in_use, stats_.bytes_in_use);stats_.largest_alloc_size =std::max<std::size_t>(stats_.largest_alloc_size, chunk->size);VLOG(4) << "Returning: " << chunk->ptr;if (VLOG_IS_ON(4)) {LOG(INFO) << "A: " << RenderOccupancy();}return chunk->ptr;}}}return nullptr;}
SplitChunk 过程
上图中没有展示出 SplitChunk 发生的位置, 其实该过程是在 FindChunkPtr 中发生. 在选取 Chunk 时, 会有一定概率出现请求的 size 比所选的 Chunk 总 size 小很多的情况. 因为每块 Chunk 只有 in use 或 free 两种状态, 所以如果空闲的 size 比请求的 size 大很多, 显然会造成该 Chunk 的实际使用率过低, 这是一种浪费. BFC Allocator 通过调用 SplitChunk 将 Chunk 分割成两部分来缓解这一问题. SplitChunk 的功能顾名思义, 就是将一块大的 Chunk 分割成两个部分. 该过程发生在 FindChunkPtr 中, 我们需要注意触发 SplitChunk 过程的条件, 在代码中我们能看到这一函数的调用条件如下.
// If we can break the size of the chunk into two reasonably large// pieces, do so. In any case don't waste more than// kMaxInternalFragmentation bytes on padding this alloc.const int64 kMaxInternalFragmentation = 128 << 20; // 128mbif (chunk->size >= rounded_bytes * 2 ||static_cast<int64>(chunk->size) - rounded_bytes >=kMaxInternalFragmentation) {SplitChunk(h, rounded_bytes);chunk = ChunkFromHandle(h); // Update chunk pointer in case it moved}
从代码中可以清晰的看到, 当以下两个条件之一满足时, SplitChunk 过程将被触发.
- 当 chunk 的 size 是用户请求的 round size 两倍及以上时(用户请求的 size 会根据最小分配单元做 round 近似)
- 当 chunk 的 size 减去用户请求的 round size 后依然大于等于最大碎片限定时(128MB)
在执行 SplitChunk 时, 需要调整 Chunk 的前驱后继指针, 这就是链表的基本操作, 非常简单. 另外, SplitChunk 会产生新的 Free Chunk, 需要根据它的大小将它插入到对应的 Bin 中.
Extend 过程
上面的流程图已经展示, 只有在双向链表中不能找到合适的 Chunk 时, Extend 过程才会被调用. 它的调用说明现有的存储池中已经没有可以满足需求的存储区了, 需要向物理设备申请, 并创建新的 Chunk, 然后放入 Bin 中. 向物理设备申请存储空间时, 如果因为一次申请的空间较大而失败, 会将请求空间做 0.9 因子的衰退, 下面的代码段展示了这个细节. 申请结束后, 需要向 region_manager 中记录该次申请.
// Try allocating.size_t bytes = std::min(curr_region_allocation_bytes_, available_bytes);void* mem_addr = sub_allocator_->Alloc(alignment, bytes);if (mem_addr == nullptr && !started_backpedal_) {// Only backpedal once.started_backpedal_ = true;static constexpr float kBackpedalFactor = 0.9;// Try allocating less memory.while (mem_addr == nullptr) {bytes = RoundedBytes(bytes * kBackpedalFactor);if (bytes < rounded_bytes) break;mem_addr = sub_allocator_->Alloc(alignment, bytes);}}
Deallocate 流程
因为在回收时只知道存储空间首地址指针, 并不知道其对应的 Chunk, 所以需要先借助 region_manager 等辅助工具获取其所对应的 Chunk 指针, 然后考虑其前驱后继节点是否可以合并. 下面展示了整体流程. 因为 Merge 的过程即使链表合并的过程, 比较简单, 所以在此不再赘述.
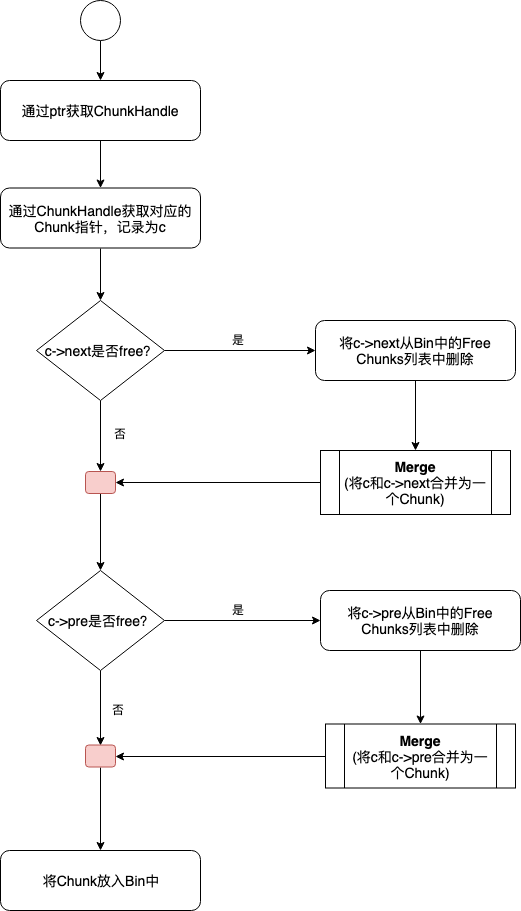
这部分对应的代码逻辑如下图所示.
void BFCAllocator::FreeAndMaybeCoalesce(BFCAllocator::ChunkHandle h) {Chunk* c = ChunkFromHandle(h);CHECK(c->in_use() && (c->bin_num == kInvalidBinNum));// Mark the chunk as no longer in use.c->allocation_id = -1;// Optionally record the free time.if (timing_counter_) {c->freed_count = timing_counter_->next();}// Updates the stats.stats_.bytes_in_use -= c->size;ChunkHandle coalesced_chunk = h;// If the next chunk is free, merge it into c and delete it.if (c->next != kInvalidChunkHandle && !ChunkFromHandle(c->next)->in_use()) {// VLOG(8) << "Merging c->next " << ChunkFromHandle(c->next)->ptr// << " with c " << c->ptr;RemoveFreeChunkFromBin(c->next);Merge(h, c->next);}// If the previous chunk is free, merge c into it and delete c.if (c->prev != kInvalidChunkHandle && !ChunkFromHandle(c->prev)->in_use()) {// VLOG(8) << "Merging c " << c->ptr << " into c->prev "// << ChunkFromHandle(c->prev)->ptr;coalesced_chunk = c->prev;RemoveFreeChunkFromBin(c->prev);Merge(c->prev, h);}InsertFreeChunkIntoBin(coalesced_chunk);}
Allow Growth
这是控制 Allocator 的一个选项, 默认是 False, 此时会在设备上开辟最大限度的存储空间, 并且全局只开辟一次. 因为已经开辟了设备上的全部存储空间, 所以若在双向链表中找不到合适的 Chunk, 那么将会直接报错 OOM 退出. 当选项为 True 时, 会经历多次存储空间的开辟, 这完全取决于当前存储池中是否还有符合需求大小的 Chunk. 如果没有, 则不断以 2 的 n 次方为基本大小进行开辟尝试, 直到满足需求为止. 那么这个值有什么用处呢? 这取决于同一个 Device 是否允许被多个程序复用. 比如在云基础设施上, 如果能够开启 Device 复用, 并打开 Device 的空分复用功能, 那么将会大大提高集群资源的利用率.
总结
本文总结了 TensorFlow 中存储管理器——BFC Allocator. 它的设计思路来自于经典来的 dlmalloc 分配算法, 是 Best fit coalecing 的简单实现版本. BFC Allocator 是为了应对 TensorFlow 中频繁分配释放存储空间需求的场景而出现的解决方案, 通过事先将存储空间从物理设备上开辟好, 并将这些空闲存储空间封装成 Chunk, 组织成有序双向链表, 然后利用 Bin 这一种索引结构为 Chunk 的查询做加速, 最终完成了高效的分配算法. 在实际分配时, 可能会遇到 Chunk 链表中不存在符合要求的空闲 Chunk 情况, 这时候就可能需要向物理设备中再次开辟新的存储空间, 这个过程被视为对 Chunk 链表的扩展, 对应的过程是 Extend. 因为是按 Chunk 进行分配, 势必可能造成存储碎片, 为了解决碎片问题, BFC Allocator 设计了 SplitChunk 和 Merge 函数. BFC Allocator 是 TensorFlow 代码中比较精简的一个部分, 该部分的代码难度较低, 并且模块独立性较强, 涉及到的代码量非常小, 但是设计思想和功能却非常全面, 非常适合初学者阅读和学习.
原文: https://www.cnblogs.com/deep-learning-stacks/p/10741859.html

若有收获,就点个赞吧
0 人点赞
