好吧,我开始写这东西基本上是由于太闲。朋友介绍我来知乎本来就是让我科普一些东西的,但是我以为知乎只是一个问答式的系统,刚刚才发现有这个直接写文章的地方… 因为手机端上一直找不到这个。发这篇文是由于,一来本身就是想科普,二来在知乎看到很多对 isa,cpu 架构的误解。先说明关于本文的几点:
- 既然是科普向,那不是专门写给专业人员看的,专业人员都喜欢看那些非常严肃,定义严谨的教科书,我本人是一个不大喜欢教科书式教育的人,所以这篇也不会是那种各种专业词语乱飞的文章。但是我没有在国内学习过 cpu 架构,所以有些名字我的确不喜欢或者不知道中文翻译,会用英语原文。尽量不用这种文绉绉的语气,多点用调侃或者比较非正式的话语。
- 在这边的公司面试的时候,我遇到过一个比较有趣的问题是:你要设计 cpu,你怎么向你奶奶解释你现在的工作。首先,我奶奶已经去世了,也没办法向她解释。其实,这是一个非常有趣的问题,为什么面试的时候回经常问?因为 cpu 设计行业里面,很多专业的知识,别说一般市民,即使是公司里面的其他员工,随时是跨领域的对话,所以,必须会用比较简单的例子来解释复杂的问题。我当时回答是用厨房煮菜的过程来解释 cpu 的流水线,这篇文当然也会常常用到类似的比喻,不是因为我喜欢做菜或者我是吃货,是因为我当时只想到厨房。
- 一篇全是文字的科普向文章是非常非常沉闷的,为了让读者不睡着,我会偶尔讲冷笑话,如果太冷了,本人水平有限。我会偶尔插入一些无关的猫咪图片(比如这个)

让读者有个视觉的错觉,能让读者稍微放松一下。而我并不是猫奴,已经没和猫一起住快半年了。
那么开始吧。
什么是 isa?
isa, instruction set architecture. 中文就是,指令,集合,架构。在计算机里面,什么是 isa 呢?就是 xx 定义的一个指令集,这里的 xx 可以指任何东西。比如你只会做加法,你就定义一个叫假发 isa(不是假发,是桂),这个指令集只做加法,这也是一个 isa。任何一个 isa 对于另外一个 isa 都没有根本意义上的 “先进”,isa 之间的对比是非常复杂的。你只会做加法,我只会做乘法,你说我们谁先进?我见得比较多的是争吵 x86 isa 比 arm isa 先进的,我往往一脸懵逼,好像他们比我懂,我是不是不应该插一腿进去…
x86 isa 现在是 Intel 和 AMD 共同拥有,也就是说如果你要开新的 x86cpu 公司你必须向这两者付版权费用,而且必须两者都同意你才能获得完整的 isa,如果你只获得一部分不完整的 isa,那就和完全没拿到 isa 一样。ISA 在 cpu 里面,就想是字典,用厨房的比喻就是菜谱,菜谱定义了你这个厨房会做什么菜,这个菜做出来是什么样什么味道,那么顾客在这家连锁店的任何一间都能叫到相同的菜,吃到相同的味道。
ARM isa 当然是 ARM 公司所有的,当时 ARM 公司是定菜单的,并且给出试菜的人,说你们每家店都要做出这个味才算 ARM。而做店的则是不同的公司,像 qualcomn 啦,他们中间喜欢怎么做菜是他们的自由,但是必须会那几道菜,必须做出这个味。

各家的菜单都一样,所以顾客不需要知道是谁做的菜,只要是这个菜单,做出来肯定一个味。因为操作系统根本不需要知道你 cpu 是怎么设计的,操作系统只要知道,我需要运行这些指令,你知道怎么运行就行了,每个不同牌子的 cpu,只要你运行出来结果都一样,就行了。如果 isa 定义 1+1=9,那么这个是定义下来的,所有人都这样错,就没错。如果 isa 定义了 1+1=9,你要纠正他,我的 cpu 是 1+1=2,那么你做出来的 cpu 虽然数学上正确,但是所有软件,系统,就突然不知道怎么办了。你说这么愚蠢的错误 cpu 不可能犯是吧?自行百度一下苹果 75-37.5 bug(虽然不一定是 cpu 或者 isa 上的错误,也许是软件上的)
然后又有人说 ISA 是铁定下来的,x86 的良好生态环境是因为他的 ISA 一直有 legacy 支持。legacy 直接翻译就是遗产。x86 的 legacy 支持的意思就是,世界上第一个 x86cpu 支持的东西,今年你发明的 x86 cpu 也支持,以后的也要支持。的确从某个角度上来说,农企和 Intel 都非常努力的去支持很多已经没什么人的东西,就是餐馆里菜谱里面有些菜基本上你都不会去试的。你说你都不用了,农企 Intel 还在那里浪费设计是吧?你不用不代表没人用啊,X 国很多军用的设备还是 Windows95 啊,甚至还是服役中的 Windows3.1 啊,银行的 atm 还有用 Windows98 的。别问我为什么他们要那样,如果他们肯花钱找些软件工程师重新写那些程序,就可以用最新的东西,很多没有注释,现在没有人学的语言,或者算法诡异的程序,很多军事设备还在用啊。原因大概是:这种语言连学都没人学,我自己都看不懂,我看你怎么破解我的坦克系统!
但是实际上 x86 又不是完全 100%legacy 支持的,至少 isa 上面没有这样定义,农企和 Intel 也没有官方明文定义。x86 里面有一个指令叫 cpuid,系统 / 编译器运行它的时候,它会给出一些数据,就是告诉系统 / 编译器,这个 cpu 支持什么东西,这个 cpu 有些什么新东西之类的。所以,理论上可以设计一个 cpu,不支持那些非常少用的指令,以降低 cpu 的设计复杂程度,也更省电省事。(对不起,你想吃的这个菜,我们不卖了,你找另外一家试试)

CPU 架构
这个主题,如果你有编程经验,食用效果更佳。
下面这段纯属个人经历,无关主题,可跳过。
如果你有编程经验,你有没有想过,你写的代码是怎么运行的?我当初就是由于这个原因而对 cpu 感兴趣然后不知不觉进了这一行。我和知乎某 czh 用户(据说已成教)是某理工大学同学,我的编程能力远不及他。但是我是这样的一个人,我看到轮子转,我就想知道轮子是怎么转的,我就想拆开马达,拆开电线,然后学物理,学磁感线,然后知道是什么让轮子转。后来由于各种原因我有缘接触汇编,cpu 架构之后,对比起编程,我对 cpu 的运行原理非常兴趣,我是兴趣使动的,然后就花时间去研究了。其实 UIUC 对于半导体,EE 那边的研究更多更有趣,但是那边的教授的所有课让我对 computer architecture 的有浓厚兴趣。我学习过程是这样的,怎么写 c->c 怎么编译会汇编语言 -> 汇编语言怎么在 cpu 里面运行 ->cpu 的组成 ->transistor 的原理 -> 半导体的电子学应用 -> 半导体的工业使用。在学习半导体的时候,对各种光学半导体也曾经非常感兴趣,没有继续学下去的原因是,设备太贵了,里面的数学太难了(对,说的就是数学,很多方程都没有解答方法,很多是以前的数学家通过直接观察式子,然后试答案试出来的,所以很多differential equation要单纯靠记忆,我对背书非常非常不在行,如果有哪一天有数学家发现了可以怎么算,我学了算法也许还能去学一点)!后来就去研究 cpu 怎么才能提高效率。
回归正题,代码是怎样运行的呢?给纯来看科普的读者的厨房比喻,你要组织一个宴会,然后你说了要弄些什么,你就是软件。然后有个人,专门根据你你要求,弄成一份菜单,他就是编译器。然后把这份菜单给厨房,基本上就是:读菜单拿食材(instruction fetch),切菜(decode),煮菜(execute),上盘出餐(load store and writeback)。然后前面就一读菜单,后面就一直工作。

给有一点编程知识的读者:举个例子,c:
int func(){
…
int a = 1;
a = a +3;
…
}
这段编译后,大概就是
sub sp, 4 ; stack point increase 变量都在函数栈里留一个位置,因为是 int 所以留 4
mov ebx, 1 ; ebx 用来存 1,就是你定义 a 了,a=1
; mov [sp], ebx ; 有时候如果需要,就把 ebx 是值存到刚刚预留的栈里
; mov ebx, [sp] ; 需要用的时候再读出来,不是必然会发生的,但是这两步可能发生
add ebx, 3 ; ebx = ebx+3, 当然你可以用其他 register
…
你不需要读得懂,因为我手打的,分分钟错给你看。然后这些东西,就会跑到内存,没错,你运行软件的时候,代码是先去到内存,如果想了解他们怎么从硬盘跑到内存,这是另外一个主题,我这里先不讨论,然后缓存又会把这些代码读取,缓存就已经在 SoC 里面的,cpu 在从缓存里面读取,别问为什么这么麻烦读这么多次,都是为了省钱和稍微加快速度。
由于是举例子,我就随便乱说个 decode。这个是 Intel 公布的 manual,问我为什么不用本家农企是吧?因为我拿到农企那个不是对外公布的,公布版我还要上网找。
Opcode Instruction Op/ En 64-bit Mode Compat/ Leg Mode D
05 id ADD EAX, imm32 I Valid Valid Add imm32 to EAX.
在 cacheline 里面看起来大概是这样的 0x0502_00000003
里面的_代表其他位不详细讲的,大概这个翻译成机械码就是 要做 05(ADD 加法)在 02(ebx 实际上我印象中 ebx 是 02,然而 eax 是 00,不是 01,这些编码乱七八糟的,Intel 决定的,别问我)后面的 00000003 就是 32 为 imm32,就是 add, ebx 03
cpu 读了这条 cacheline 叫 instruction fetch,然后下一步就是把它 decode,解释成 add, ebx 03, 再下一步就是把运行(execute,没错,这么麻烦之后,最后终于要算了),把算得的结果存到 ebx 上,然后再看看需不需要存回去 cacheline 或者内存里面(load/store writeback)。这个就是 cpu 的基本运行原理。
CPU pipeline
有时候会听到 cpu 流水线,如果按照上面的做法,没一个指令都要通过这几部来预算,那么只有一部分电子器件在用的时候,其他部分都在发呆浪费电。就像是,厨房里面,从取菜到上盘全部都一个人做,肯定要累死那个人,但是你炒菜的时候,是不是想,如果有人已经帮你切好菜,我就一直炒菜好了,这样我们厨房工作效率就高了,cpu 也是这样。
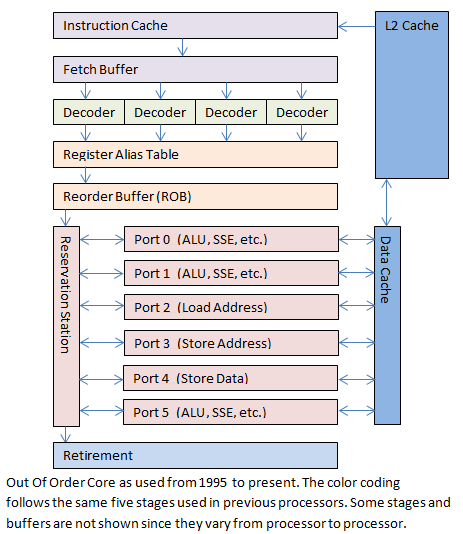
转自 A Journey Through the CPU Pipeline
让你们失望了,这张图不是猫咪。这是一个经典的 cpu 运行流水线。换成厨房理论,就是,一个人专门去食材,一个人专门切菜,一个人专门炒菜,一个人专门上盘,一个人专门给客人下单上菜,是不是现代化很多呢!然而这样不能满足我们 cpu 的工程师,我们还有 branch prediction,什么叫 branch prediction 呢?程序黎里面最耗时间的一个就是 branch,就像 c 里面的 if,你得到答案之前不知道是继续往下走还是进去 if 里面的括号。就像下单的小哥,那些犹豫不决而改菜单的人最讨厌了。于是 cpu 里面有了这个东西,他是怎么用的呢。下单的小哥也不是笨蛋,顾客 a 来了 100 多次了,有 80 次都改单把猪肉改成鸡肉,那么他下单时候,小哥就先说了,改鸡肉,如果顾客 a 觉得还是猪肉吧,就再抄,如果顾客 a 真的改单,那么厨房以及开始做了,而且有 80% 的几率啊,小哥还是挺聪明的吧。cpu 也大概是这样,根据每个 loop 的地址 (顾客) 来训练出一个未卜先知的系统。
上图里面还有 OOO(out of order),x86 里面,real mode 可以用的 general register 只有 8 个,eax,ebx,之类的,64 位之后增加了 8 个。流水线工作,如果
mov eax,1;
add eax,1;
sub eax,2;
你们发现问题了没,eax 用了再用,但是流水线做 add 的时候,eax 是 1,sub 在等 add retire 之前,是不能做的,那么你就不得不等。那么流水线的效率就体现不出来了。因为这里有一个 write after write 的 dependency,就是同一个 register,你两个 pipeline stage 要用同一个 register,而且 x86 在传统模式只有 8 个 register,eax,ebx 等等,64 位模式增加了一些。所以这中情况是非常常见的。为了解决这个问题,就有了 out of order execute, in order commit。就是不按顺序来运行指令,但是按顺序完成指令。
用厨房理论解释就是,有这么一道菜(或者说两道菜),鸡要先煮了然后炸,你煮熟鸡之前不能炸,否则炸了再煮,口感就不同了,顾客肯定骂死你,但是后面又有其他菜在等,锅你是有的,所以在煮鸡的时候,你先做后面的菜,然后鸡煮好了,再炸。出餐的时候,你还是先出了这道鸡肉再出后的菜,那样顾客就不会投诉出餐的顺序不按菜单了。
大概就说这么一通吧,也不知道有没有解释清楚,我中文越来越差了,说话都咬舌头,而且我说方言版本的粤语比较多,普通话有时候也说不准确了 Orz(求别喷,用得少就说不好了)。里面夹杂了一些英文,因为我看了中文的翻译,我觉得那样翻译不好,也不准确,但是我又不想自己想个新词来误导读者,只好用英文了。如果有读者对某些题目有特别的兴趣,我再想想什么时候有空再写点什么吧。
我是学过怎么做引用注释的,但是中文的好像没学过。复制过来试试吧。
引用:
A Journey Through the CPU Pipeline —Bryan Wagstaf**f**
http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-instruction-set-reference-manual-325383.pdf — intel isa manual
百度图片找到的猫咪 — 作者不详
https://zhuanlan.zhihu.com/p/20731557

若有收获,就点个赞吧
0 人点赞
