前言
这段时间关注到微软开发的一个内存分配器mimalloc,感觉很厉害,从官方的 benchmark 看,比 tcmalloc 提升了 7%, 比 jemalloc 提升了 14%,而且它的核心代码只有几千行,看起来是值得好好研究一下。
在研究之前,我专门看了一些内存分配的算法,虽然对这些算法都有了解,但系统学习下来还是获益良多。所以在这篇文章里,我打算先介绍这些基础算法,然后在下一篇再来分析 mimalloc 的实现。
linear allocator
它的思路是预先创建内存块,然后在内存块上一直分配内存,这些分配出去的内存不用释放,到最后再一次性把内存块回收。
这种分配算法有很大的限制,但在一些特定场景里却很有用,比如一些局部逻辑,你需要创建大量的小对象,而这些对象会在使用完毕后一起释放掉,此时用 linear allocator 就能极大的提高分配效率。
它的核心代码非常简单,只有几十行,如下所示:
// 大的内存块typedef struct linear_block {struct linear_block *next;} linear_block_t;// 线性分配器typedef struct linear_allocator {linear_block_t *header; // 内存块链表头uint8_t *end;size_t blksz; // 内存块的大小,包含头结构的} linear_allocator_t;// 最小的块大小#define LINEAR_MIN_BLOCK_SIZE 1024// 内存块头大小#define HEADER_SIZE sizeof(linear_block_t)// 取内存块的Buffer#define LINEAR_BUFFER(b) ((uint8_t*)(b) + HEADER_SIZE)// 初始化static void linear_init(linear_allocator_t *a, size_t size) {a->blksz = size + HEADER_SIZE < LINEAR_MIN_BLOCK_SIZE ? LINEAR_MIN_BLOCK_SIZE : size + HEADER_SIZE;a->header = NULL;a->end = (uint8_t*)HEADER_SIZE; // 此举是为了在分配时减少一次判断}// 分配内存器static inline linear_block_t* _linear_new_block(size_t size) {return (linear_block_t *)malloc(size);}// 分配内存static void* linear_alloc(linear_allocator_t *a, size_t size) {if (a->end - LINEAR_BUFFER(a->header) < size) { // 内存不足,分配新的内存块if (size + HEADER_SIZE > a->blksz) {// 如果请求的大小比默认内存块大,则尝试创建更大的内存块linear_block_t *block = _linear_new_block(HEADER_SIZE + size);uint8_t *buffer = LINEAR_BUFFER(block);if (a->header != NULL) {// 如果头结点存在,则加到头结点后面去,这样头结点的内存块下次还能使用block->next = a->header->next;a->header->next = block;} else {// 如果头结点不存在,则成为头结点block->next = NULL;a->header = block;a->end = buffer;}return buffer;} else {// 否则正常分配内存块,并成为链表头linear_block_t *block = _linear_new_block(a->blksz);block->next = a->header;a->header = block;a->end = (uint8_t*)block + a->blksz;}}a->end -= size;return a->end;}// 终止static void linear_term(linear_allocator_t *a) {linear_block_t *block = a->header;linear_block_t *temp;while (block) {temp = block;block = block->next;free(temp);}}
代码中有少量注释,仔细看应该不难理解;这个分配器的核心结构可以用下图来表示:
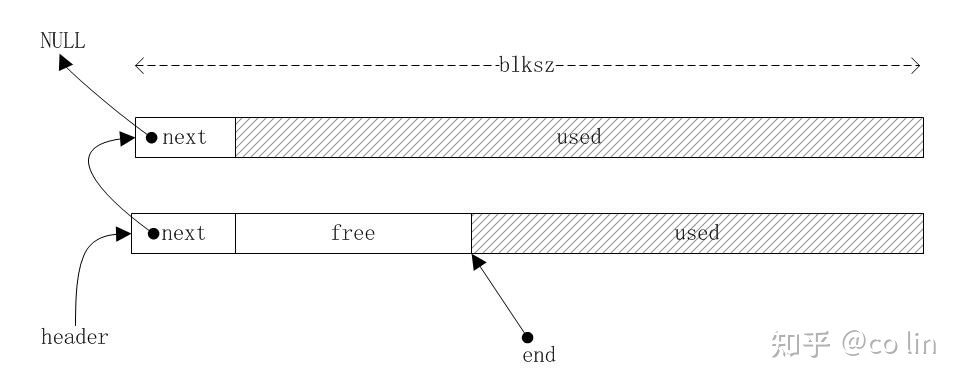
header 总是指向当前可分配的内存块,end 指向可用内存的结束点,在分配内存时有两种情况:
- 如果可用内存足够,只需要把 end 向前移动 size,然后把 end 返回就可以了。
- 如果不够分配,则需要创建一个新的内存块,此时也有两种情况要处理:
- 请求的内存比默认的 buffer 小:创建一个 blksz 大小的内存块,将其插入到链表头,将 end 指向内存块尾;然后跳回第 1 步。
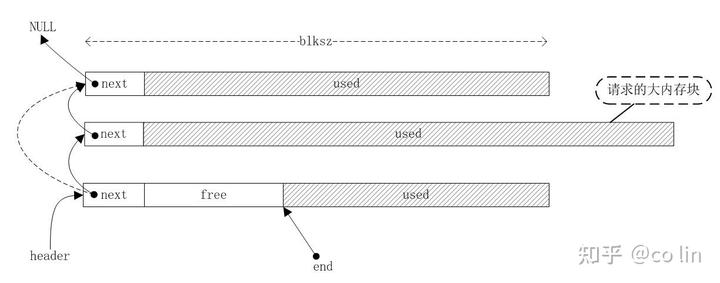
- 请求的内存比默认的 buffer 大:创建一个足够大的内存块,将其插入到链表头的下一个;然后直接返回这个内存块。这种情况用下图表示:
fixed size allocator
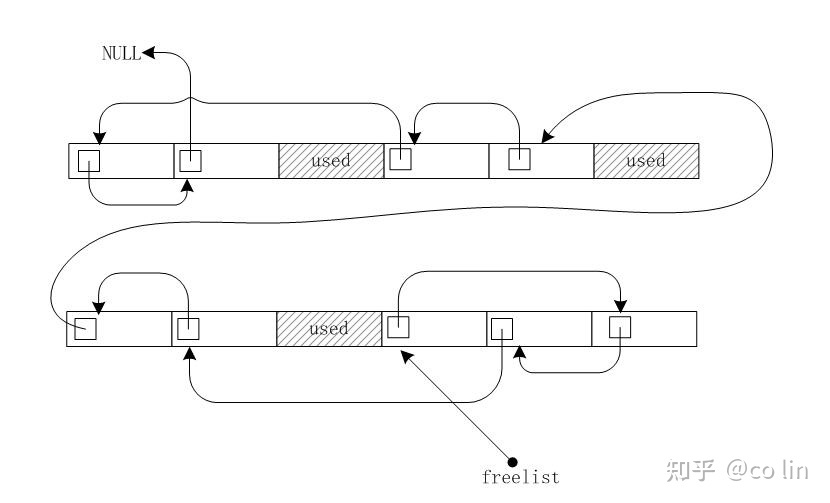
fixed size allocator顾名思议,只能分配和释放固定大小的内存,其用途要比linear allocator广得多,它的核心思想是预创建内存块,然后将内存块切割成多个固定大小的小块,并将它们链接起来形成一个freelist;分配的时候从 freelist 取出小块返回;释放的时候将小块重新链接回 freelist;如果 freelist 没有多余内存就再创建一个内存大块;如此重复,最终的内存布局像下面这样:
代码也不复杂,甚至比上面的还要简单:
// 内存项typedef struct fixed_item {struct fixed_item *next;} fixed_item_t;// 内存块typedef struct fixed_block {struct fixed_block *next;} fixed_block_t;// 内存块头大小#define FIXED_HEADER sizeof(fixed_block_t)// 取内存块的Buffer#define FIXED_BUFFER(b) ((uint8_t*)(b) + FIXED_HEADER)// 固定大小分配器typedef struct fixed_allocator {fixed_block_t *block; // 内存块链表size_t blocksize; // 内存块大小size_t itemsize; // 内存项大小fixed_item_t *freelist; // 可用的内存项链表} fixed_allocator_t;#define FIXED_MIN_BLOCK_SIZE 256#define MIN_ITEM_SIZE 16// 初始化static void fixed_init(fixed_allocator_t *a, size_t blocksize, size_t itemsize) {assert(itemsize + FIXED_HEADER < blocksize);a->block = NULL;a->blocksize = blocksize > FIXED_MIN_BLOCK_SIZE ? blocksize : FIXED_MIN_BLOCK_SIZE;a->itemsize = itemsize > MIN_ITEM_SIZE ? itemsize : MIN_ITEM_SIZE;a->freelist = NULL;}// 结束static void fixed_term(fixed_allocator_t *alloc) {fixed_block_t *block = alloc->block;fixed_block_t *temp;while (block) {temp = block->next;free(block);block = temp;}}// 分配内存项,由于是固定大小,所以不用指定大小static void* fixed_alloc(fixed_allocator_t *a) {if (a->freelist == NULL) {// 没有可用内存,新建一个大块,加入链表fixed_block_t *block = (fixed_block_t*)malloc(a->blocksize);block->next = a->block;a->block = block;// 初始化可用项size_t i;size_t size = a->blocksize - FIXED_HEADER;fixed_item_t *item;for (i = 0; i + a->itemsize <= size; i += a->itemsize) {item = (fixed_item_t*)(FIXED_BUFFER(block) + i);item->next = a->freelist;a->freelist = item;}}// 分配内存fixed_item_t *item = a->freelist;a->freelist = a->freelist->next;return item;}// 释放内存项static void fixed_free(fixed_allocator_t *a, void *item) {fixed_item_t *bitem = (fixed_item_t *)item;bitem->next = a->freelist;a->freelist = bitem;}// 取地址偏移static uintptr_t _get_offset(fixed_allocator_t *a, fixed_item_t *item) {fixed_block_t *block = a->block;uint8_t *p = (uint8_t*)item;while (block) {if (FIXED_BUFFER(block) <= p && p < (uint8_t*)block + a->blocksize)return p - FIXED_BUFFER(block);block = block->next;}return 0;}static void fixed_print(fixed_allocator_t *a) {printf("========================================\n");fixed_item_t *item = a->freelist;while (item) {uintptr_t offset = _get_offset(a, item);printf("(%lu--%lu), ", offset, offset+a->itemsize-1);item = item->next;}printf("\n");}
由于只能分配固定大小的内存,它的功能也是受限的。但它却是很多现代内存管理器的重要组成部分,这些管理器会创建很多不同 size class 的 freelist,这样就能快速创建不同大小的小对象。
buddy allocator
另外一种分配器叫伙伴分配器,它比 fixed size allocator 的限制小一些,可以分配不同大小的内存,不过这些大小必须是 2 的幂;在释放内存的时候,如果这块内存的伙伴内存也处于释放状态,分配器会将两块内存合并起来变成大一倍的内存,并且这个过程会一直重复,直到没有释放的伙伴内存为止。
那么伙伴内存究竟是什么东西呢,可以想象成二叉树里的左右子结点,对于左结点来说右结点就是它的伙伴,对于右结点来说左结点就是它的伙伴。这两个伙伴有一样的大小,且内存连续,所以可以合并成大内存。这就是伙伴分配器的核心思想。
我先贴出代码,能通过代码理解这个算法当然最好,如果不能理解也没关系,后面会通过一些图例来分析。
// 最小的内存池大小#define MIN_POOL_SIZE 1024// 最小可分配的块大小#define MIN_BLOCK_SIZE 16// 最小可分配块的级别#define MIN_LEVEL 4// 内存块typedef struct buddy_block {struct buddy_block *next;} buddy_block_t;typedef buddy_block_t* buddy_block_p;// 伙伴分配器typedef struct buddy_allocator {uint8_t *pool; // 内存池uint8_t *base; // 内存池可分配的起始地址buddy_block_p *freelist; // freelist数组,每一个slot存放一个freelist,内存块尺寸=2^i,i即是slot的索引。int maxlv; // 最大级int minlv; // 最小级} buddy_allocator_t;// 取块的级别,级别存在块的前一个字节处#define GET_LEVEL(b) (*((uint8_t*)(b) - 1))// 计算级别代表的内存大小#define LEVEL_2_SIZE(lv) (1 << (lv))// 地址偏移#define GET_OFFSET(a, b) ((uintptr_t)(b) - (uintptr_t)(a)->base)// 向上取整到2的幂static inline uint64_t _roundup_pot(uint64_t v) {v--;v |= v >> 1;v |= v >> 2;v |= v >> 4;v |= v >> 8;v |= v >> 16;v |= v >> 32;return ++v;}// 计算大小代表的级别static inline int _calc_level(size_t size) {int lv = MIN_LEVEL;size_t sz = 1 << lv;while (size > sz) {sz <<= 1;lv++;}return lv;}// 取一个内存块的伙伴内存块:// |<---block--->|<---buddy--->|// |<---buddy--->|<---block--->|static inline buddy_block_t* _get_buddy(buddy_allocator_t *a, buddy_block_t *block, int lv) {// 取相对地址uintptr_t offsetaddr = GET_OFFSET(a, block);// 通过xor即可以取到伙伴的地址,比如:// 从左孩子取右孩子:offsetaddr=10000, lv=3: buddyaddr = 10000 ^ (1 << 3) = 10000^1000 = 11000// 从右孩子取左孩子:offsetaddr=11000, lv=3: buddyaddr = 11000 ^ (1 << 3) = 11000^1000 = 10000uintptr_t buddyaddr = offsetaddr ^ (1 << lv);// 取绝对地址return (buddy_block_t*)((uintptr_t)a->base + buddyaddr);}// 初始化static void buddy_init(buddy_allocator_t *a, size_t poolsz, size_t minsz) {poolsz = poolsz > MIN_POOL_SIZE ? poolsz : MIN_POOL_SIZE;minsz = minsz > MIN_BLOCK_SIZE ? minsz : MIN_BLOCK_SIZE;assert(minsz < poolsz);poolsz = (size_t)_roundup_pot(poolsz);minsz = (size_t)_roundup_pot(minsz);a->maxlv = _calc_level(poolsz);a->minlv = _calc_level(minsz);// 这里多分配了一个sizeof(void*),用于将level放到每个分配的block中a->pool = (uint8_t*)calloc(poolsz + sizeof(void*), 1);a->base = a->pool + sizeof(void*);a->freelist = (buddy_block_p*)calloc(a->maxlv + 1, sizeof(buddy_block_p));a->freelist[a->maxlv] = (buddy_block_t*)a->base;}// 结束static void buddy_term(buddy_allocator_t *a) {free(a->freelist);free(a->pool);}// 分配static void* buddy_alloc(buddy_allocator_t *a, size_t size) {size += 1; // 多1个字节,用于存放levelint lv = _calc_level(size); // 得到该块的级别// 向后查找可用的内存块,越往后内存块越大int i = lv;for (;; ++i) {if (i > a->maxlv) return NULL;if (a->freelist[i]) break;}// 从链表取出内存块buddy_block_t *block = a->freelist[i];a->freelist[i] = a->freelist[i]->next;// 将内存块一级一级分割,并放入相应的freelistbuddy_block_t *buddy;while(i-- > lv) {buddy = _get_buddy(a, block, i);a->freelist[i] = buddy;}// 记录该内存块的level,在free的时候会用到// 这个level是放在block的前一个字节的GET_LEVEL(block) = lv;return block;}// 释放static void buddy_free(buddy_allocator_t *a, void *p) {buddy_block_t *block = (buddy_block_t*)p;int i = GET_LEVEL(block);buddy_block_t *buddy;buddy_block_t **list;for (;; ++i) {// 取当前块的buddy块buddy = _get_buddy(a, block, i);// 判断buddy块是否有在freelist中list = &a->freelist[i];while ((*list != NULL) && (*list != buddy))list = &(*list)->next;if (*list != buddy) {// 如果没找到buddy块,将block加入freelistblock->next = a->freelist[i];a->freelist[i] = block;return;} else {// 如果找到,将block和buddy合并成大块block = block < buddy ? block : buddy;// 从链表删除,然后继续循环合并块*list = (*list)->next;}}}// 打印内存情况static void buddy_print(buddy_allocator_t *a) {printf("========================================\n");for (int i = a->minlv; i <= a->maxlv; ++i) {buddy_block_t *block = a->freelist[i];size_t sz = LEVEL_2_SIZE(i);printf("Lv %-2d (%lu) : ", i, sz);while (block) {uintptr_t offset = GET_OFFSET(a, block);printf("(%lu--%lu), ", offset, offset + sz - 1);block = block->next;}printf("\n");}}
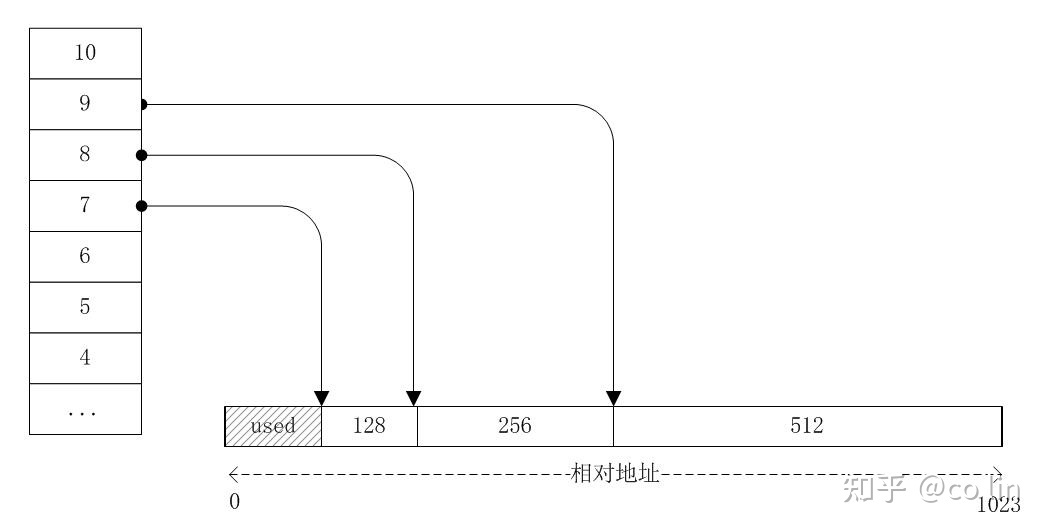
buddy allocator 使用一个 freelist 数组来存放各个 size 的内存块链表。数组的索引决定了内存块的大小,比如索引为 4 的槽位放的是 2^4=16 的内存块链表。假如我们创建的大内存是 1024,那么一开始索引 10 的 freelist 指向了这块内存,其他槽位皆为空:

接下来我们请求分配大小为 100 的内存,因为只能是 2 的幂,所以向上取整为 128,即等于 2^7;这表明该内存要从索引为 7 的 freelist 分配,这个 freelist 现在还是空的,要从更高索引的 freelist 切割内存过来用,经过一翻切割之后,变成下面这样:
重复再分配 3 个 100 的内存之后,变成下面这样:
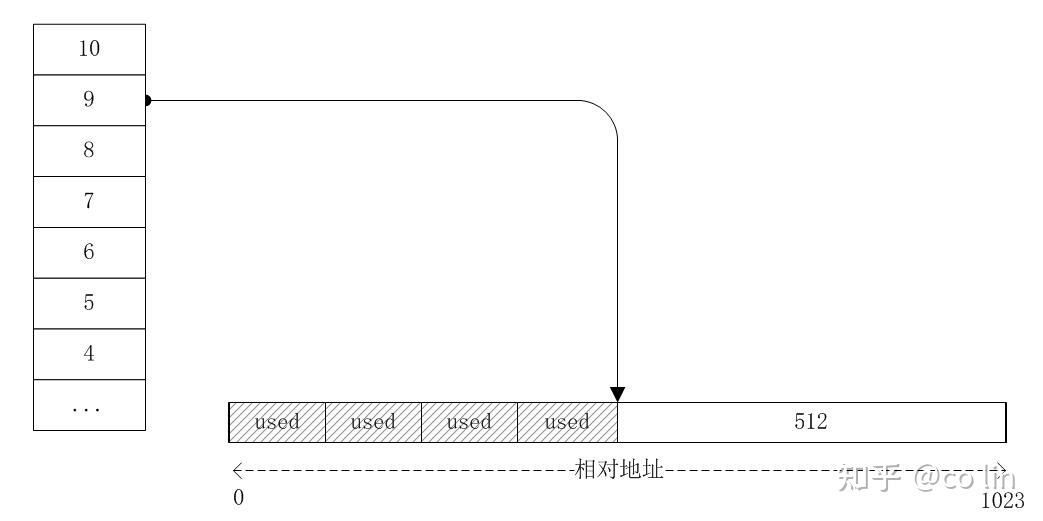
总共分配出去 4 块 128 大小的内存,其中第 2 块和第 3 块使用完毕后回收回来;第 1 块和第 2 块是伙伴,第 3 块和第 4 块是伙伴,所以回收回来的这两个不是伙伴,他们不能合并,只能串成 freelist 放在 7 号索引处:
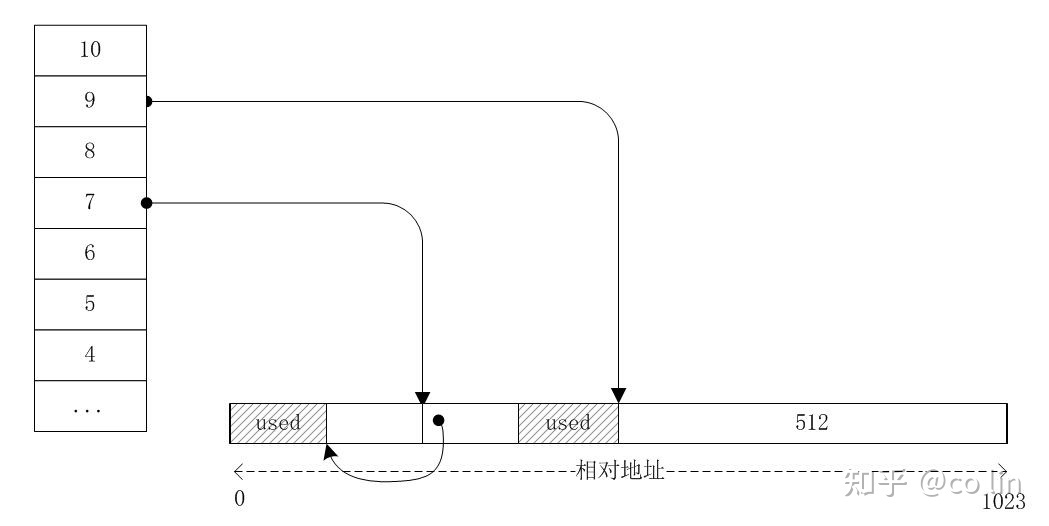
接着第 1 块内存也释放了,它和第 2 块内存是伙伴,这两内存都已经释放,可以将它们合并变成一块 256 的内存,即等于 2^8,最终索引 8 的 freelist 将指向它:
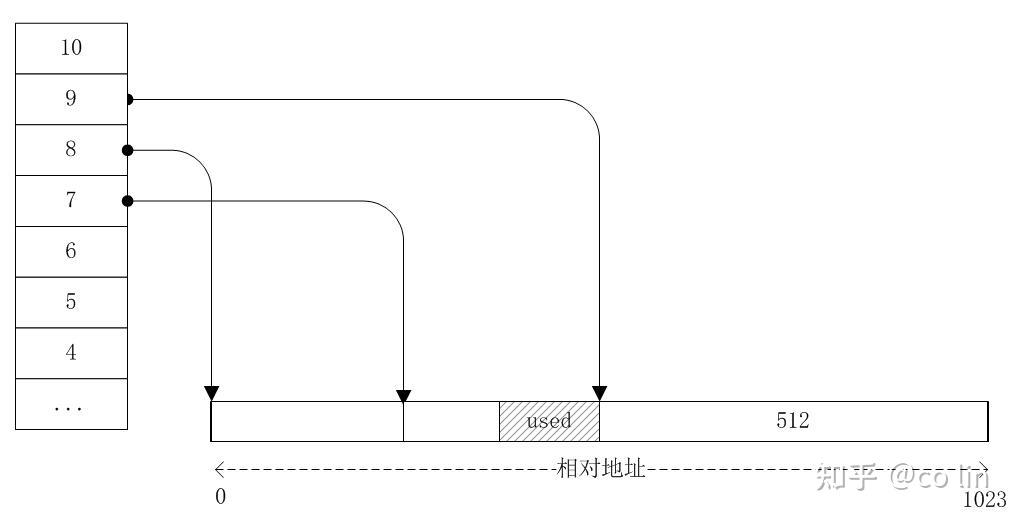
最后第 4 块内存也释放了,它和第 3 块内存是伙伴,3,4 块内存合并成 256 的内存;这块合并完的内存和前面 256 大小的内存是伙伴,所以又合并变成一块 512 的内存;这块内存和最后那块 512 的内存又是伙伴,最终他们神奇的合并回 1024 的内存,并由索引为 10 的 freelist 引用着,也就是最前面那张图的样子。
经过这样的讲解,再结合代码来看是不是一眼了然了呢?代码里还有一些小技巧,比如通过异或得到伙伴的地址,用内存块前面一个字节来存放 Level 等,这些请通过代码和注释慢慢理解。
buddy allocator 有用在一些著名的内存分配器中,比如 jemalloc;另外 Linux 内核似乎也用这个算法来管理空闲的物理页,这足以说明它是一个很重要的算法。
后记
The C Programming Language 第 8.7 节介绍了一个内存分配算法,可以分配任意大小的内存,内存回收之后还能合并相领的内存块,看起来似乎是一个通用的内存分配器。不过这个分配器太慢了,分配的时候必须遍历 freelist 找到合适大小的内存块,释放的时候也须遍历 freelist,找到插入的位置,使内存块地址有序,这样才能合并。祖师爷的本意是想通过这个代码来介绍动态内存分配的核心技术;我们回过头来看看上面三个受限的分配器,也能得出内存分配其实是指针和链表的重度应用,通过自己实现一些分配器,你能更加理解指针和链表的操作。
但是,如果要实现一个通用的,高效的现代内存管理器,要考虑的问题就太多了:要抽象 OS 的内存分配接口,要满足多线程系统的性能要求,还要考虑安全性和可诊断,总之这是一个很有挑战的系统工程。

若有收获,就点个赞吧
0 人点赞
