如果大家能对我的文章推荐一下,关注一下本人博客,那就更开心了,我今后也会更多的写一些计算机系统 / 原理类的文章,以飨各位读者。再次谢谢。前段时间看了 周志明的那本 《深入理解 java 虚拟机》。对于平台无关性问题,有了一些新的认识。所以特写一篇博客来进行总结。
这是我的第一篇不针对具体技术,而只针对计算机系统和原理的博客文章,而这种话题,总是比较宽泛,而我本人的水平有限,所以我也只能泛泛的写写,思考的不对的地方,还望读者不吝批评。
C 为什么不能跨平台
咱们先来讨论一下,C 语言的执行过程,从而搞清楚为什么 C 语言不能跨平台。
#include <stdio.h>int main(){printf("Hello, World!");return 0;}
以上就是广大人民群众 都知道的hello world程序。最终执行的结果 就是在 console 上输出一行字符串, hello world!。
大学时,谭浩强的 C 语言教材,
main方法的返回值是void,但这是错误的。实质上应该返回int来告诉操作系统执行结果。(当然,后来学习的深入了,才知道谭的教材有不少错误的地方,但是我对这本教材依旧印象很好,因为那是我编程的启蒙教材)。
我们知道,计算机只认识 0 和 1(就是二进制),换句话说,不管我们在计算机上干了什么事情,运行了多么复杂的程序,从 ps 绘图,到 qq 聊天,再到听音乐,最终到了 CPU 的执行层面,其实就是 一串串的 0 和 1 组成的指令罢了。 当然,到了硬件层面,那就是与或非门的领域了。但是,上面的那个 hello world程序是怎么转换为 0 和 1 的呢。
一般情况下,对于我们使用的是 IDE,比如 Visual Studio, CodeBlocks 之类的,就是点击个运行按钮那么简单,或者你就是使用了 gcc 命令行来进行编译,也可以一行命令 gcc -o hello hello.c, 就 输出了最后的编译结果。但是实际上,hello world的编译过程是这样的:
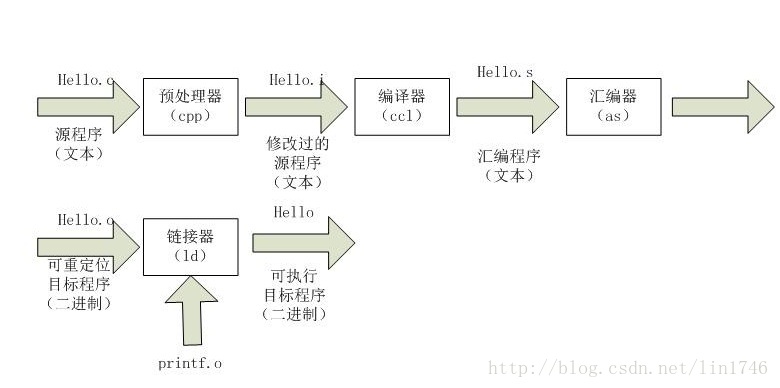
我们分阶段来讨论:
- 预处理阶段。预处理器 (cpp) 来把 代码中
#开头的行进行展开, 比如头文件,宏等内容,修改最初的 C 文件。 - 编译阶段。编译器 (ccl) 将修改后的 C 文件,翻译成了 另一文本文件,
hello.s,这就是我们所说的汇编程序了。 打开这个文本文件内容 类似下面的格式:
section .datamsg db 'Hello, world!',0xAlen equ $-msgsection .textglobal _start_start:mov edx,lenmov ecx,msgmov ebx,1mov eax,4int 0x80mov ebx,0mov eax,1int 0x80
当然,不同 CPU 和平台环境,编译输出的汇编代码也不同,我们这里仅作为示例。
- 汇编阶段。汇编器 (as) 将
hello.s翻译成机器语言指令。 把这些命令打包成一种叫做可重定位目标程序 (relocatable object program) 的格式,此时的输出格式就是hello.o了。这其实就是二进制文件了。 - 链接阶段。编译过程最后还有一个链接阶段 (程序调用了
printf函数),最后的输出结果还是和上一步类似,都是直接二进制文件。
了解了 hello world程序的编译过程,我们就来讨论一下,什么是汇编程序。我们先来看一下维基百科上的定义。(那个维基百科的链接,没 fan 墙的同学应该是打不开的)。
汇编语言(英语:assembly language)是一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。在不同的设备中,汇编语言对应着不同的机器语言指令集。一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。
什么是汇编,相关专业的同学应该都明白,因为计算机只认识 0 和 1(就是二进制),所以在计算机刚开始发明时,那些科学家们就是直接 向计算机输入 0 和 1,来运行计算任务的。(当然,他们是通过穿孔纸带的方式来向计算机输入, 比如有孔代表 1,没孔代表 0)。通过这样的方式,计算机终于能运行了,但是这样的效率实在太慢了。
而在他们输入的 0 和 1 中,有些代表的是指令,这些是有固定含义和编码的。也是芯片能识别的。而另一些是数据。这些不同的程序的数据自然是不同的。我们前面就说,不管多么复杂的计算机操作,到了 cpu 级别都是 0 和 1,数据虽然多变,但是 指令的数量是有限的。因为 指令是要被芯片固定识别的。芯片中要用 晶体管 (最初是电子管) 组成的与或非门组合来识别这些指令和数据。因为直接输入 0 和 1, 实在太繁琐了,所以他们就发明了汇编语言。来简化 程序的编写。
比如 计算 1+1,两个 数据 1 都 使用 0x0001 来表示,而 加操作,放在 cpu 中,可以是 0xa90df(这个是胡乱写的), 这个二进制代表的加操作能被计算机识别。而因为这个加操作对于 cpu 来说,编码的0xa90df格式是固定的。所以可以直接一个助记符add来表示,这样科学家们写程序就方便多了,而这就是汇编程序的由来。因为汇编程序完成之后,可以再有一个专门的程序(就是要上文中所说的汇编器)来把编写的汇编程序编译成 0 和 1. 这样计算机也可以识别了,而汇编语言本身也方便了程序的编写和阅读。
编写汇编比直接编写二进制方便高效了太多。但是 随着计算任务的复杂,程序的规模越来越庞大,使用汇编程序也很累啊,那么是否有更简单的方式呢?所以科学家们发明了高级语言 (比如 C,lisp等),在编写程序的时候,使用 C 语言等编写,然后再使用 编译器将 C 语言程序翻译成汇编程序,汇编程序再使用汇编器编译成 0 和 1,这样,cpu 能识别的东西没有变化,但是对于编写程序的人,确实方便了很多。
通过以上的描述,我们就知道了高级语言的大概由来。也明白了我们所编写的各种高级语言,到了最后,其实都是转化为二进制执行。
而直接二进制格式的程序,我们称之为本地机器码 (native code)。而类似那些 add之类的 助记符,以及汇编的编写格式或标准,我们称之为 指令集。
但是问题的关键来了。不同公司所生产的 cpu 芯片。他们所使用的指令集不同啊, 这种芯片设计的事情,又不像 TCP/IP 协议那样,有国际统一的标准,甚至像 intel 所代表的复杂指令集,和 arm 为代表的精简指令集,它们指令集的设计思路就是不一样的。
所以 我们 C 语言最后编译出来的的二进制文件,假设是这段93034030930900090222ab2d11cd22dfad(随便写的),不同的 cpu 上识别的意义是不同的。
所以为什么说 C 语言不能实现跨平台运行,就是因为它编译出来的 输出文件的格式,只适用于某种 cpu,其他 cpu 不认识啊。
- 我们所说的跨平台运行,并不是指
hell.c这个文本文件的运行。因为文本文件本身也没办法运行。运行的只是它的编译结果hello,而这个由 0 和 1 组成的编译结果,不同的 cpu 和平台,他们的格式不同。所以C语言编译出来的结果,没办法跨平台运行。
- 甚至在不同的平台下,
hello.c最后所编译出来的文件的格式都不同。比如 linux 下编译出的hello,window 下编译结果是hello.exe, 而 mac 下编译结果是hello.out,(至于单片机上编译结果的后缀是啥子,这个忘记了)。
- 也有些人会讲,为了让 linux 下编写的一段
hello程序运行在window上,我不拿最后的编译结果hello来直接运行,我在 window 环境下重新用 IDE 建立项目,同样的源代码在 window 下重新运行一遍,输出hello.exe,再在 window 上运行,行不行啊?这个答案是No。因为不同环境下,c 语言的标准有差别。例如 int 类型,在有的平台上 可能 16 位表示,而有的平台上则是 32 位表示。所以不同环境下的同一个程序,会存在数据溢出之类的错误。
- 其实还有一点,大家平时写个程序,IDE 上点击个 run/build 之类的,稍等一会就输出结果了,但是实际上,很多大型程序的编译过程是比较长的,比如我第一家公司做手机系统的,编译一个 Android5.0 的系统 rom,在 i7 cpu,16G 内存的电脑上,需要编译运行一个多小时,才能编译成功输出最后的结果。
知道了 C 语言不能跨平台运行,那有没有一种办法,能够 让高级语言实现跨平台的运行呢?
思考实际编程中的一个场景,我们前端需要处理的某个数据是 A 格式,但是后台只能提供 B 格式的数据,那我们怎么办? 很简单啊。写个接口,把 B 格式转化为 A 格式不就行了嘛。这就是设计模式当中的适配器设计模式。
关于跨平台也是一样的道理。cpu 的指令集不同, 不同平台编译出来的结果格式都不同,那么我们可以在各个平台上运行虚拟机,然后我们制定某种编译结果的输出格式,我们的输出了某种格式的结果,直接在虚拟机上运行。这样不就 ok 了嘛。。
这其实就是 java 采取的方式。
Class 文件格式,虚拟机以及 ByteCode
这是 java 版本的helloJava;
public static void main(String[] args) {System.out.println("helloJava");}
这段 java 程序编译出来的结果是 helloJava.class, 换句话说,它输出的结果是 Class 文件格式 (也叫字节码存储格式)。
class 文件的内容大概就像下面那样:
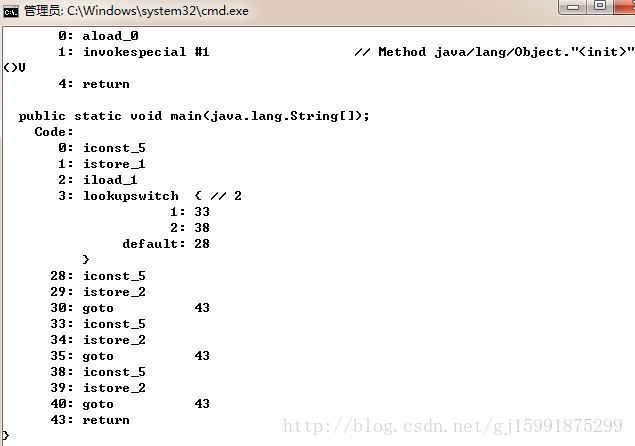
是不是看不懂? 看不懂就对了。这其实就是 java 虚拟机定义的二进制格式,这种我们称之为 字节码 (ByteCode), 是 java 虚拟机所能运行的格式。类似本地机器码可以反编译成汇编,这种二进制也可以反编译成更容易阅读的格式。
类似下面这样。
而各个平台的 java 虚拟机 是不同的。但是我们编写的 java 程序 统一编译成特定格式的 Class 文件格式,然后 Class 文件可以在各个不同平台的 java 虚拟机上运行, 当然运行结果肯定也是一致的,至于各个不同平台之间的差异,这是那些编写 java 虚拟机的人去考虑的事情,我们这些做 java 的程序员,不用去关心这个问题。
通过这种方式,我们的 java 程序就实现了跨平台。
所以 java 也被称为 中间件技术语言。意思就是 中间加一层过度。很好理解。(当然,维基百科上对中间件技术的解释,基本把我看晕了, 也和 java 没关系,不过大家理解这个意思就好)。
平台无关性
而通过 java 虚拟机和 Class 文件格式,我们就实现了平台无关性, 换句话说,这些适应各个不同平台和 cpu 的工作的还是要有人干的。那就是设计 java 虚拟机的人去做这些工作,但是他们的辛苦换来了我们上层程序员的轻松。我们就完全不关心各个平台和 cpu 的差异了。
代码编译的结果,从本地机器码(NativeCode)向字节码 (ByteCode) 的转变,是存储格式的一小步,却是编程语言发展的一大步
虽然说名字是 ByteCode, 但是我觉的,其实和 NaticeCode 都差不多,反正都是定义了一套指令集,只是前者能被虚拟机执行引擎去执行,而 后者能被物理机的 CPU 去执行罢了。
知道了大概的原理,我们就思考另一个问题,java 虚拟机去执行 Class 文件,那和 java 的源文件 有什么关系呢。答案是 没关系。换句话说,java 的源文件编译的输出结果为 Class 文件,而 Class 文件能被 java 虚拟机认识,并执行,这是两个独立的过程,中间也没啥关系和必然性。
那么进而引申出另一个问题,某一种其他编程语言,如果我设计出了一种对应的编译器,将其编译输出结果为 Class 文件,那这样该语言岂不是也实现了跨平台了?
想到这一点,那么恭喜你,你发现了 java 虚拟机的另一种 重要特性。语言无关性
语言无关性
java 虚拟机在执行 Class 文件时,不知道也完全不关心这个 Class 文件是咋来的。(这个 Class 文件可以是任何一种语言的源文件编译而来,当然,就像直接编写汇编一样,你直接编写 ByteCode 也行, 只要格式正确)。
其实 CPU 在执行二进制的指令时,它不知道也完全不关心这些指令流是咋来的。这都是同一个道理。
很多程序员都还认为 Java 虚拟机执行 Java 程序是一件理所当然和天经地义的事情。这是错误的。
下面某些内容 援引 周志明的 《深入理解 java 虚拟机》:
Sun 的开发设计团队在最初设计的时候就把 Java 的规范拆分成了 Java 语言规范《The Java Language Specification》及 Java 虚拟机规范《The Java Virtual Machine Specification》。
并且在 1997 年发布的第一版 Java 虚拟机规范中就曾经承诺过:“In the future,we will consider bounded extensions to the Java virtual machine to provide better support for other languages”(在未来,我们会对 Java 虚拟机进行适当的扩展,以便更好地支持其他语言运行于 JVM 之上)。
实现语言无关性的基础仍然是虚拟机和字节码存储格式。Java 虚拟机不和包括 Java 在内的任何语言绑定,它只与 “Class 文件” 这种特定的二进制文件格式所关联,Class 文件中包含了 Java 虚拟机指令集和符号表以及若干其他辅助信息。基于安全方面的考虑,Java 虚拟机规范要求在 Class 文件中使用许多强制性的语法和结构化约束,但任何一门功能性语言都可以表示为一个能被 Java 虚拟机所接受的有效的 Class 文件。作为一个通用、机器无关的执行平台,任何其他语言的实现者都可以将 Java 虚拟机作为语言的产品交付媒介。
换句话说,java 虚拟机这个名字其实只是一个误导,java 虚拟机和 java 没啥关系,其实更应该叫做 Class 文件虚拟机。
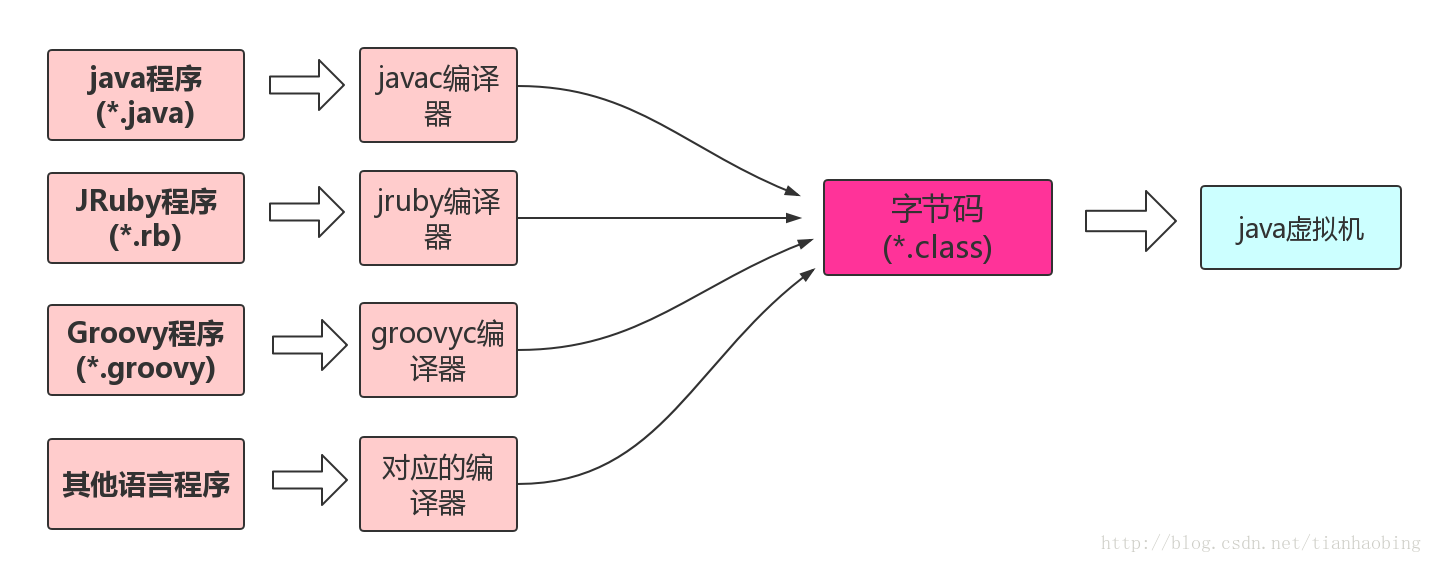
因为其他语言, 只要有对应的编译器,输出结果就可以运行在 java 虚拟机上,所以时至今日, 涌现 Clojure、Groovy、JRuby、Jython、Scala 一批运行在 java 虚拟机上的语言。
目前下图中的语言都已经可以运行在 java 虚拟机上。

所以广义上的 java 技术体系,也包括 Clojure、JRuby、Groovy,Scale 等运行于 Java 虚拟机上的语言及其相关的程序。
Java,Scale 等各种语言中的各种变量、关键字和运算符号的语义最终都是由多条字节码命令组合而成的,因此字节码命令所能提供的语义描述能力肯定会比单一语言本身更加强大。
当然,在 java 最初刚出现的时候,Write Once,Run Anywhere, 这种 平台无关性被吹嘘的比较厉害,但是现在 这种虚拟机的思想,被很多其他语言也学会了,比如 python 和 pvm。go 语言,.NET 等都是同样的思想。
为什么 C/C++ 没有被替代。
关于 java 虚拟机和 Class 文件格式, 貌似很厉害的样子,什么 个人一小步,人类一大步都扯上了,那肯定有人疑问,为什么 c/c++ 这些不能跨平台的语言,还现在还被很多人使用,还没被 java 取代呢。
当然,这个原因有很多,比如 java 的 gc 过程所无法避免的stop the world过程,这在 某些实时性要求比较高的 系统中,比如 股票交易系统,军事系统,是不可接受的。(关于垃圾回收这是另一个话题,不在本文范围内,未来有时间可以花时间另写博客讨论这个问题)。
不过有句话说的很好
java 和 c++ 之间有一堵由动态内存分配和垃圾收集技术所围成的’高墙’,墙外的人想进去,墙内的人想出来
另外,对于直接与硬件交互的事情,也只能靠 C 语言了。毕竟上层再怎么发展,硬件与系统之间永远要存在一个驱动层啊。
但是除了以上这些,还有一个原因。给大家讲讲软件历史上的一个重大教训,大家也许就明白了。
当年为了对抗 sun 的 java 平台,微软 2002 年推出了类似中间件思想的. NET 平台 (C#)。当时 window xp 一统江湖,让微软如日中天,不可一世,微软在下一代操作系统(就是 window visa) 的开发中,决定使用 C#, 虽然微软牛逼哄哄,拥有最牛逼的程序员,最顶尖的科学家,但是开发到最后他们发现,使用 C# 这种运行在虚拟机上的中间件语言,无论如何也达不到 C/C++ 语言的速度。所以最后悲剧的 window visa,全部推倒重来,重新开发。当时李开复在微软,他的一本书中对此有详细介绍。
当然,当年 window visa 项目的失败,还有其他一些原因,比如 使用数据库系统代替文件系统,驱动不兼容等, 但是 使用. NET 来进行开发,起码也是失败的主要原因之一。
所以现在大家明白了,ByteCode 运行在虚拟机上,相比于直接编译成 NativeCode 运行在物理机上,速度较慢。
现在随着虚拟机运行时优化技术的发展,以及硬件的速度越来越快,所以它们速度之间的差异,也没之前差距那么大了。
实质上,Class 文件在虚拟机上运行的时候,还会有很多的优化措施。
在部分的商用虚拟机中,Java 程序最初是通过解释器(Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为 “热点代码”(Hot Spot Code)。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(Just In Time Compiler,简称 JIT 编译器)。
许多主流的商用虚拟机都同时包含解释器与编译器。解释器与编译器两者各有优势:当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。当程序运行环境中内存资源限制较大(如部分嵌入式系统中),可以使用解释执行节约内存,反之可以使用编译执行来提升效率。
但是实际上,编译器可以把 java 源文件的输出结果编译成 Class 格式 (也就是 ByteCode),那自然也可以有其他类型的编译器 可以直接将 java 源文件编译为 NativeCode 啊。所以对于编程语言来说,我们可以有各种方式来编译它,Java 语言的“编译期” 其实是一段 “不确定” 的操作过程。因为我们可以使用不同类型的编译器编译出不同的输出结果。
java 常见的编译器有以下类型。
- 前端编译器:把.java 文件转变成.class 文件。比如 Sun 的 Javac、Eclipse JDT 中的增量式编译器(ECJ)。
- JIT 编译器:字节码 (ByteCode) 转变成机器码(NaticeCode)。比如 HotSpot VM 的 C1、C2 编译器。
- AOT 编译器:直接把*.java 文件编译成本地机器代码。 比如 GNU Compiler for the Java(GCJ)、Excelsior JET。
结束
所以讨论到最后,大家就已经明白,所以平台无关性,与 编译器与编译输出结果格式 的关系。花了一天时间写了这么多内容,也希望给大家带来一些启发。
在本篇博客当中,很多内容也并不是精确的分析,比如某些概念,都说的比较模糊,因为我们这片博客只是讨论思想。很多概念和过程也都没有去深究, 如有错误不准确的地方,欢迎指正。
补充内容(20170905)
非常感谢大家对这篇文章的支持,能够对其他人有所帮助,获得大家的认可。更加提升了我坚持写博客的动力。
针对评论中的问题,也进行一些解答。
一
如文章末尾所说,我本来就是写大概思想,所以很多细节没有深入去追究,其实比如像汇编的格式,指令集的执行等,其实这些讨论起来真心复杂,牵扯到 cpu 的结构设计等。今后也计划写文章和大家讨论这些问题。
评论中倒没有人指出这方面的问题,不过我大学时本来就是做 C 语言和单片机的,明白这方面介绍的依旧不够准确和详细。(当然,很多细节我也忘记了)
二
评论当中有人提到. NET 的虚拟机的问题,首先因为我本身是 Android 程序员,大学时期也做过 C 语言,单片机等,所以对 java,C 等算是了解一些,但是对. NET 的确不了解。对. NET 有限的知识,也来源于和做. NET 的朋友的讨论交流。因此关于. NET 思想的评价可能不够准确。
评论中有人提出了以下问题:
wdwwtzy 评论: 那我想问问,.net 也是 java 一样的虚拟机技术,为什么早期. net 无法跨平台?
隆德尔评论:楼主,据我所知,java 与. net,此虚拟机非彼虚拟机。而且这个问题一直被很多 javaer 所混淆。
wdwwtzy评论:啥意思,看文章的意思,java 一出生不就是真正的跨平台了吗?
有些同学直接评论做了相关解答,对此深表感谢。写博客本来就是一个相互讨论相互促进的过程,所以感谢各位的解答。
WindyAmy评论:.net CLR/.net framework 和 window 系统结合的太紧密导致。现在微软重写了部分 framework 库(.net core),已经可以实现夸平台了。
Blackheart评论:因为没有人在其他平台实现. net 的 clr 啊,后来有了 mono,可以跨平台了。没有真正意义上的跨平台,对于开发者而已,可能你不需要关心操作系统是 windows 还是 linux 了,你感觉是跨平台了。但是底层总有这么一帮人在帮你搭建支撑 “跨平台” 的基础设施的,对于他们来说,一个个的平台都需要单独去实现的。**
几位解答的同学说的都已经非常好了,本人结合评论,也 google 了一些相关知识。再对. NET 的相关问题写出我的理解。以期抛砖引玉。
- 可以确定是,.NET 和 java 虚拟机也是一样的思想,都是引入中间层 / 虚拟机的思想。做 java 的同学说 java 虚拟机(JVM),而微软的. NET 的虚拟机的名称叫做通用语言运行平台(Common Language Runtime,简称 CLR)。虽然有些同学可能认为 CLR 不叫虚拟机,但是归根到底,它还是广义的虚拟机的概念和思想。
- Clojure、Groovy、JRuby、Jython、Scala 等很多语言都可以运行在 JVM 上。而 CLR 也是一样的,C#、F#、VB.NET、C++、Python 等几十种语言也可以运行在 CLR 上。
- java,Scala 等编译结果为 ByteCode(字节码), 被称之为 Class 文件格式运行在 jvm 上,而 jvm 在运行 Class 格式文件时,可以解释运行,也可以通过 JIT 编译器编译成 NativeCode 加快运行。而 C#,C++ 等编译成 通用中间语言(Common Intermediate Language,简称 CIL), 然后再汇编成字节码,(当然这个字节码肯定不会是 Class 文件格式,但是概念相同),而在运行时,也是翻译成本地机器码运行(但是 CLR 貌似没有解释运行,这点求相关同学解答,我估计应该也有类似 javascript 的解释运行方式,不过没查到相关资料)。
以上是技术层面,下面我们再来讨论 一些非技术层面。
大家知道,我们要想在某个平台上运行 java 开发的项目,必须要安装 jdk,这个过程还是很麻烦的,要设置环境变量之类的。这对于普通用户来讲是不可能完成的操作。而. NET 其实也是需要安装环境的(叫做 .NET framework),但是 window 就是微软自家的,所以 window 系统内置了. NET framewok。(win7 自带. net3.5 版本, win10 自带 4.0 版本),所以 window 上本来就可以运行. NET 的程序。省去了普通用户安装. NET framework 的麻烦。
但是微软肯定不会为 window 内置 jdk 的,原因太简单了,如果 window 也都内置了 jdk,而其他的 linux,mac 等操作系统也都进行内置,那么各个开发应用 / 游戏的厂商们,直接使用 java 开发就好了,然后开发出来的产品直接 window/linux/mac 所有系统平台上都通用,厂商们开心了,消费者也开心了,那这个时候,我们为什么还要使用 window 操作系统呢?反正对于普通消费者而言,使用应用或玩游戏都是没啥区别的。
(所以这也是为什么 java 在 pc 端应用 / 游戏领域没人使用,而服务器端使用 java 的多,因为开发服务器的码农们搭配 java 环境很 easy 啊)
回想一下 window 与 Netscape 的浏览器大战,如果使用浏览器就能干大部分事情,那么大家根本就不关心运行浏览器的操作系统是 window 还是 linux 了。当然,现在互联网的流量 / 入口之争其实都是同一个道理。普通消费者哪里关心那么多,哪个好用,哪个便宜就用那个。
2014 年 11 月 12 日,微软宣布将完全开放. NET 框架的源代码,并提供给 Linux 和 OS X 使用。
首先本博客当中非常清晰的表达了这个观点,什么跨平台不跨平台,适应各个平台 / CPU 的差异,这种脏活累活永远也得有人干,只是那些 去做虚拟机的人干了这种活,我们这种纯粹写上层的人轻松了而已。
所以我觉的很多时候,能不能跨平台,除了技术问题,还要有商业原因,甚至也有 money 的问题(毕竟开发各个平台的虚拟机也是不易)。就像 .NET 理论上跨平台,但是不开源,几年前微软又不肯为. NET 提供 linux 环境下的实现。那么自然没办法跨平台,但是这和技术无关。
java 最初设计时,理论上就可以跨平台,但是那些苦逼的虚拟机开发者们还要去开发各个平台 / cpu 的虚拟机,这也不是一朝一夕之功。
微软现在可以让. NET 跨平台,一来大的形势变了(之前的操作系统卖的那么贵,现在 win10 都可以免费了), 二来微软对. NET 有控制权。而在 java 刚出来的时候,微软也支持 java,也设计过微软版本的 jvm。但是微软是想拥有对 java 技术体系的控制权,但是发现搞不过 sun 之类的,java 不在它的控制之下,所以微软就开始搞自己的. NET 平台了。
也许 Java 程序员听起来可能会觉得惊讶,微软公司曾经是 Java 技术的铁杆支持者(也必须承认,与 Sun 公司争夺 Java 的控制权,令 Java 从跨平台技术变为绑定在 Windows 上的技术是微软公司的主要目的)。在 Java 语言诞生的初期,微软公司为了在 IE3 中支持 Java Applets 应用而开发了自己的 Java 虚拟机,虽然这款虚拟机只有 Windows 平台的版本,却是当时 Windows 下性能最好的 Java 虚拟机。但好景不长,在 1997 年 10 月,Sun 公司正式以侵犯商标、不正当竞争等罪名控告微软公司,在随后对微软公司的垄断调查之中,这款虚拟机也曾作为证据之一被呈送法庭。这场官司的结果是微软公司赔偿 2000 万美金给 Sun 公司(最终微软公司因垄断赔偿给 Sun 公司的总金额高达 10 亿美元),承诺终止其 Java 虚拟机的发展,并逐步在产品中移除 Java 虚拟机相关功能。具有讽刺意味的是,到最后在 Windows XP SP3 中 Java 虚拟机被完全抹去的时候,Sun 公司却又到处登报希望微软公司不要这样做。Windows XP 高级产品经理 Jim Cullinan 称:“我们花费了 3 年的时间和 Sun 打官司,当时他们试图阻止我们在 Windows 中支持 Java,现在我们这样做了,可他们又在抱怨,这太具有讽刺意味了。”
这个故事告诉我们一个道理:早知今日,何必当初呢。
本篇博客补充了以上内容,谢谢大家,欢迎指点批评。
https://www.cnblogs.com/jmsjh/p/7808764.html

若有收获,就点个赞吧
0 人点赞
