- Performance性能
- Required functions
- Using
- Building
- Cache configuration options
- Other configuration options
- Huge pages
- Quick overview快速概览
- Implementation details实现细节
- Memory mapping内存映射
- Span breaking 分割Span
- Memory fragmentation内存碎片
- First class heaps一类堆
- Producer-consumer scenario生产者-消费者场景
- Best case scenarios最优情况
- Worst case scenarios最坏情况
- Caveats注意事项
- Other languages
- License
This library provides a public domain cross platform lock free thread caching 16-byte aligned memory allocator implemented in C. The latest source code is always available at https://github.com/mjansson/rpmalloc
该库提供开源跨平台无锁线程缓存16字节对齐的内存分配器(用C实现)。最新的源代码:
https://github.com/mjansson/rpmalloc
Created by Mattias Jansson (@maniccoder) - Discord server for discussions at https://discord.gg/M8BwTQrt6c
Platforms currently supported:
- Windows
- MacOS
- iOS
- Linux
- Android
- Haiku
The code should be easily portable to any platform with atomic operations and an mmap-style virtual memory management API. The API used to map/unmap memory pages can be configured in runtime to a custom implementation and mapping granularity/size.
This library is put in the public domain; you can redistribute it and/or modify it without any restrictions. Or, if you choose, you can use it under the MIT license.
Performance性能
We believe rpmalloc is faster than most popular memory allocators like tcmalloc, hoard, ptmalloc3 and others without causing extra allocated memory overhead in the thread caches compared to these allocators. We also believe the implementation to be easier to read and modify compared to these allocators, as it is a single source file of ~3000 lines of C code. All allocations have a natural 16-byte alignment.
我们相信rpmalloc比大多数流行的内存分配器如tcmalloc、hoard、ptmalloc3等更快,与这些分配器相比,rpmalloc不会在线程缓存中造成额外的分配内存的开销。我们还认为,与这些分配器相比,该实现更容易阅读和修改,因为它是一个由~3000行C代码组成的单一源文件。所有的分配都有一个自然的16字节对齐。
Contained in a parallel repository is a benchmark utility that performs interleaved unaligned allocations and deallocations (both in-thread and cross-thread) in multiple threads. It measures number of memory operations performed per CPU second, as well as memory overhead by comparing the virtual memory mapped with the number of bytes requested in allocation calls. The setup of number of thread, cross-thread deallocation rate and allocation size limits is configured by command line arguments.
包含在并行资源库中的是一个基准工具,它在多个线程中执行交错的无对齐分配和释放(包括线程内和跨线程)。它通过比较虚拟内存映射和分配调用中请求的字节数来测量每CPU秒执行的内存操作数,以及内存开销。线程数、跨线程去分配率和分配大小限制的设置是通过命令行参数配置的。
https://github.com/mjansson/rpmalloc-benchmark
Below is an example performance comparison chart of rpmalloc and other popular allocator implementations, with default configurations used.
下面是rpmalloc和其他流行的分配器实现 (使用默认配置) 的示例性能比较图。
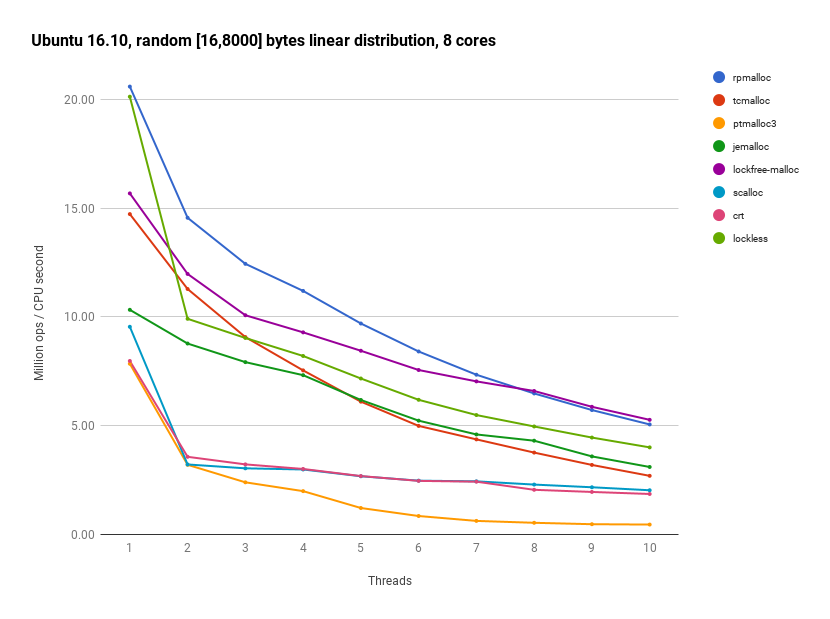
The benchmark producing these numbers were run on an Ubuntu 16.10 machine with 8 logical cores (4 physical, HT). The actual numbers are not to be interpreted as absolute performance figures, but rather as relative comparisons between the different allocators. For additional benchmark results, see the BENCHMARKS file.
产生这些数字的基准在具有8个逻辑核 (4个物理核,HT) 的Ubuntu 16.10计算机上运行。实际数字不应解释为绝对性能数字,而应解释为不同分配器之间的相对比较。有关其他基准测试结果,请参阅基准文件 BENCHMARKS 。
Configuration of the thread and global caches can be important depending on your use pattern. See CACHE for a case study and some comments/guidelines.
线程和全局缓存的配置可能很重要,这取决于你的使用模式。在文件 CACHE 中可以查看案例研究和一些评论/指南。
Required functions
Before calling any other function in the API, you MUST call the initialization function, either rpmalloc_initialize or pmalloc_initialize_config, or you will get undefined behaviour when calling other rpmalloc entry point.
Before terminating your use of the allocator, you SHOULD call rpmalloc_finalize in order to release caches and unmap virtual memory, as well as prepare the allocator for global scope cleanup at process exit or dynamic library unload depending on your use case.
Using
The easiest way to use the library is simply adding rpmalloc.[h|c] to your project and compile them along with your sources. This contains only the rpmalloc specific entry points and does not provide internal hooks to process and/or thread creation at the moment. You are required to call these functions from your own code in order to initialize and finalize the allocator in your process and threads:
rpmalloc_initialize : Call at process start to initialize the allocator
rpmalloc_initialize_config : Optional entry point to call at process start to initialize the allocator with a custom memory mapping backend, memory page size and mapping granularity.
rpmalloc_finalize: Call at process exit to finalize the allocator
rpmalloc_thread_initialize: Call at each thread start to initialize the thread local data for the allocator
rpmalloc_thread_finalize: Call at each thread exit to finalize and release thread cache back to global cache
rpmalloc_config: Get the current runtime configuration of the allocator
Then simply use the rpmalloc/rpfree and the other malloc style replacement functions. Remember all allocations are 16-byte aligned, so no need to call the explicit rpmemalign/rpaligned_alloc/rpposix_memalign functions unless you need greater alignment, they are simply wrappers to make it easier to replace in existing code.
If you wish to override the standard library malloc family of functions and have automatic initialization/finalization of process and threads, define ENABLE_OVERRIDE to non-zero which will include the malloc.c file in compilation of rpmalloc.c. The list of libc entry points replaced may not be complete, use libc replacement only as a convenience for testing the library on an existing code base, not a final solution.
For explicit first class heaps, see the rpmallocheap* API under first class heaps section, requiring RPMALLOC_FIRST_CLASS_HEAPS tp be defined to 1.
Building
To compile as a static library run the configure python script which generates a Ninja build script, then build using ninja. The ninja build produces two static libraries, one named rpmalloc and one named rpmallocwrap, where the latter includes the libc entry point overrides.
The configure + ninja build also produces two shared object/dynamic libraries. The rpmallocwrap shared library can be used with LD_PRELOAD/DYLD_INSERT_LIBRARIES to inject in a preexisting binary, replacing any malloc/free family of function calls. This is only implemented for Linux and macOS targets. The list of libc entry points replaced may not be complete, use preloading as a convenience for testing the library on an existing binary, not a final solution. The dynamic library also provides automatic init/fini of process and threads for all platforms.
The latest stable release is available in the master branch. For latest development code, use the develop branch.
Cache configuration options
Free memory pages are cached both per thread and in a global cache for all threads. The size of the thread caches is determined by an adaptive scheme where each cache is limited by a percentage of the maximum allocation count of the corresponding size class. The size of the global caches is determined by a multiple of the maximum of all thread caches. The factors controlling the cache sizes can be set by editing the individual defines in the rpmalloc.c source file for fine tuned control.
ENABLE_UNLIMITED_CACHE: By default defined to 0, set to 1 to make all caches infinite, i.e never release spans to global cache unless thread finishes and never unmap memory pages back to the OS. Highest performance but largest memory overhead.
ENABLE_UNLIMITED_GLOBAL_CACHE: By default defined to 0, set to 1 to make global caches infinite, i.e never unmap memory pages back to the OS.
ENABLE_UNLIMITED_THREAD_CACHE: By default defined to 0, set to 1 to make thread caches infinite, i.e never release spans to global cache unless thread finishes.
ENABLE_GLOBAL_CACHE: By default defined to 1, enables the global cache shared between all threads. Set to 0 to disable the global cache and directly unmap pages evicted from the thread cache.
ENABLE_THREAD_CACHE: By default defined to 1, enables the per-thread cache. Set to 0 to disable the thread cache and directly unmap pages no longer in use (also disables the global cache).
ENABLE_ADAPTIVE_THREAD_CACHE: Introduces a simple heuristics in the thread cache size, keeping 25% of the high water mark for each span count class.
Other configuration options
Detailed statistics are available if ENABLE_STATISTICS is defined to 1 (default is 0, or disabled), either on compile command line or by setting the value in rpmalloc.c. This will cause a slight overhead in runtime to collect statistics for each memory operation, and will also add 4 bytes overhead per allocation to track sizes.
Integer safety checks on all calls are enabled if ENABLE_VALIDATE_ARGS is defined to 1 (default is 0, or disabled), either on compile command line or by setting the value in rpmalloc.c. If enabled, size arguments to the global entry points are verified not to cause integer overflows in calculations.
Asserts are enabled if ENABLE_ASSERTS is defined to 1 (default is 0, or disabled), either on compile command line or by setting the value in rpmalloc.c.
To include malloc.c in compilation and provide overrides of standard library malloc entry points define ENABLE_OVERRIDE to 1. To enable automatic initialization of finalization of process and threads in order to preload the library into executables using standard library malloc, define ENABLE_PRELOAD to 1.
To enable the runtime configurable memory page and span sizes, define RPMALLOC_CONFIGURABLE to 1. By default, memory page size is determined by system APIs and memory span size is set to 64KiB.
To enable support for first class heaps, define RPMALLOC_FIRST_CLASS_HEAPS to 1. By default, the first class heap API is disabled.
Huge pages
The allocator has support for huge/large pages on Windows, Linux and MacOS. To enable it, pass a non-zero value in the config value enable_huge_pages when initializing the allocator with rpmalloc_initialize_config. If the system does not support huge pages it will be automatically disabled. You can query the status by looking at enable_huge_pages in the config returned from a call to rpmalloc_config after initialization is done.
该分配器在Windows、Linux和MacOS上支持巨大/大型页面。要启用它,在用rpmalloc_initialize_config初始化分配器时,在配置值中传递一个非零值 enable_huge_pages。如果系统不支持巨大页面,它将被自动禁用。你可以通过查看初始化完成后调用 rpmalloc_config返回的 config 中的 enable_huge_pages来查询状态。
Quick overview快速概览
The allocator is similar in spirit to tcmalloc from the Google Performance Toolkit. It uses separate heaps for each thread and partitions memory blocks according to a preconfigured set of size classes, up to 2MiB. Larger blocks are mapped and unmapped directly. Allocations for different size classes will be served from different set of memory pages, each “span” of pages is dedicated to one size class. Spans of pages can flow between threads when the thread cache overflows and are released to a global cache, or when the thread ends. Unlike tcmalloc, single blocks do not flow between threads, only entire spans of pages.
该分配器在原理上类似于 Google Performance Toolkit 中的tcmalloc。它为每个线程使用单独的堆,并根据预先配置的大小类别划分内存块,最大可达2MB。更大的块会直接被映射和取消映射。不同大小类别的分配将由不同的内存页集来实现,每个 “跨度 “页专门用于一个大小类别。当线程缓存溢出并释放到全局缓存中时,或当线程结束时,由多个内存页构成的Span可以在线程之间流动(即多个线程可用)。与tcmalloc不同的是,单个内存块不能在线程之间流动(即只属于某个线程),只在整个Span中可用。
Implementation details实现细节
The allocator is based on a fixed but configurable page alignment (defaults to 64KiB) and 16 byte block alignment, where all runs of memory pages (spans) are mapped to this alignment boundary. On Windows this is automatically guaranteed up to 64KiB by the VirtualAlloc granularity, and on mmap systems it is achieved by oversizing the mapping and aligning the returned virtual memory address to the required boundaries. By aligning to a fixed size the free operation can locate the header of the memory span without having to do a table lookup (as tcmalloc does) by simply masking out the low bits of the address (for 64KiB this would be the low 16 bits).
分配器基于固定但可配置的页面对齐方式 (默认为64KiB) 和16字节块对齐方式,其中所有内存页 (span:这里指一组连续的内存页) 的运行都映射到该对齐边界。在Windows上,自动保证虚拟分配粒度最大达64KiB,在mmap系统上,可以通过扩展映射大小并将返回的虚拟内存地址与所需的边界对齐来实现。通过与固定大小对齐,free操作可以找到内存span的头部,而不必进行表查找 (就像tcmalloc所做的那样) ,该方法是通过简单地屏蔽掉地址的低位 (对于64KiB,是低16位)。
Memory blocks are divided into three categories. For 64KiB span size/alignment the small blocks are [16, 1024] bytes, medium blocks (1024, 32256] bytes, and large blocks (32256, 2097120] bytes. The three categories are further divided in size classes. If the span size is changed, the small block classes remain but medium blocks go from (1024, span size] bytes.
内存块分为三类。对于64KiBspan/对齐,小块是 [16, 1024]字节,中等块 (1024,32256] 字节,大块 (32256,2097120] 字节。这三个类别进一步分为不同的大小类别。如果更改了span大小,则小块类保持不变,但中等块就是 (1024,span大小] 。
Small blocks have a size class granularity of 16 bytes each in 64 buckets. Medium blocks have a granularity of 512 bytes, 61 buckets (default). Large blocks have the same granularity as the configured span size (default 64KiB). All allocations are fitted to these size class boundaries (an allocation of 36 bytes will allocate a block of 48 bytes). Each small and medium size class has an associated span (meaning a contiguous set of memory pages) configuration describing how many pages the size class will allocate each time the cache is empty and a new allocation is requested.
小块粒度为16字节,总共有64个桶,每个桶的粒度为16字节(【熊选文补充】64个桶里的小块的大小分别是:16,32,48,…,1024,后一个桶比前一个桶大16字节)。中等块的粒度为512字节,总共有61个桶 (默认)(【熊选文补充】61个桶里的小块的大小分别是:1024+512,1024+1024,…,32256,后一个桶比前一个桶大512字节)。大块与配置的span大小具有相同的粒度 (默认为64KiB)。所有分配都匹配到这些大小边界 (一般都是向上匹配,如,36字节的分配将分配48字节的块)。每个中小型类都有一个关联的span (意味着一组连续的内存页)配置,它描述每次缓存为空并请求新分配时该size类将分配多少页。
Spans for small and medium blocks are cached in four levels to avoid calls to map/unmap memory pages. The first level is a per thread single active span for each size class. The second level is a per thread list of partially free spans for each size class. The third level is a per thread list of free spans. The fourth level is a global list of free spans.
中小型块的Span缓存分为四个级别,以避免调用map/unmap内存页面。第一级是每个线程对每个大小类的单一活动Span。第二级是每个线程对每个大小类的部分空闲Span的列表。第三级是每个线程的自由Span列表。第四级是一个全局的空闲Span列表。
Each span for a small and medium size class keeps track of how many blocks are allocated/free, as well as a list of which blocks that are free for allocation. To avoid locks, each span is completely owned by the allocating thread, and all cross-thread deallocations will be deferred to the owner thread through a separate free list per span.
中小型类的每个Span都跟踪分配/释放了多少块,以及哪些块可以自由分配。为了避免锁定,每个span完全归分配线程所有,所有跨线程解除分配将通过每个span的单独空闲列表延迟给所有者线程去处理。
Large blocks, or super spans, are cached in two levels. The first level is a per thread list of free super spans. The second level is a global list of free super spans.
大块或超级Span的缓存分两级。第一级是每个线程的免费超级Span列表。第二级是一个全局的自由超级Span列表。
Memory mapping内存映射
By default the allocator uses OS APIs to map virtual memory pages as needed, either VirtualAlloc on Windows or mmap on POSIX systems. If you want to use your own custom memory mapping provider you can use rpmalloc_initialize_config and pass function pointers to map and unmap virtual memory. These function should reserve and free the requested number of bytes.
默认情况下,分配器使用操作系统的api映射虚拟内存页面(在Windows上是VirtualAlloc,在POSIX系统上是mmap)。如果要使用自己的自定义内存映射提供程序,可以使用rpmalloc_initialize_config并传递函数指针来映射和取消映射虚拟内存。这些函数应保留并释放请求的字节数。
The returned memory address from the memory map function MUST be aligned to the memory page size and the memory span size (which ever is larger), both of which is configurable. Either provide the page and span sizes during initialization using rpmalloc_initialize_config, or use rpmalloc_config to find the required alignment which is equal to the maximum of page and span size. The span size MUST be a power of two in [4096, 262144] range, and be a multiple or divisor of the memory page size.
从内存映射函数返回的内存地址必须与内存页面大小和内存Span大小 (更大) 对齐,这两者都是可配置的。在初始化期间提供页面和Span大小,使用rpmalloc_initialize_config,或使用rpmalloc_config找到所需的对齐方式,该对齐方式等于页面和Span大小的最大值。Span大小必须是2的幂,大小范围是 [4096,262144] ,是内存页大小的倍数或因子。
Memory mapping requests are always done in multiples of the memory page size. You can specify a custom page size when initializing rpmalloc with rpmalloc_initialize_config, or pass 0 to let rpmalloc determine the system memory page size using OS APIs. The page size MUST be a power of two.
内存映射的大小始终是内存页面大小的倍数。您可以在使用rpmalloc_initialize_config初始化rpmalloc时指定自定义页面大小,或传递0以让rpmalloc使用操作系统api来确定系统内存页面大小。页面大小必须为2的幂。
To reduce system call overhead, memory spans are mapped in batches controlled by the span_map_count configuration variable (which defaults to the DEFAULT_SPAN_MAP_COUNT value if 0, which in turn is sized according to the cache configuration define, defaulting to 64). If the memory page size is larger than the span size, the number of spans to map in a single call will be adjusted to guarantee a multiple of the page size, and the spans will be kept mapped until the entire span range can be unmapped in one call (to avoid trying to unmap partial pages).
为了减少系统调用开销,内存Span是批量映射的,由配置变量span_map_count来控制(如果是0则默认为DEFAULT_SPAN_MAP_COUNT,该值又根据缓存配置定义进行大小调整,默认为64)。如果内存页面大小大于Span大小,则将调整单个调用中要映射的Span数,以确保页面大小的倍数,并且Span将保持映射,直到可以在一次调用中取消映射整个Span范围 (以避免尝试取消映射部分页面)。
On macOS and iOS mmap requests are tagged with tag 240 for easy identification with the vmmap tool.
在macOS和iOS上,mmap请求用标签240标记,以便使用vmmap工具轻松识别。
Span breaking 分割Span
Super spans (spans a multiple > 1 of the span size) can be subdivided into smaller spans to fulfull a need to map a new span of memory. By default the allocator will greedily grab and break any larger span from the available caches before mapping new virtual memory. However, spans can currently not be glued together to form larger super spans again. Subspans can traverse the cache and be used by different threads individually.
超级Span (Span大于Span大小1的倍数) 可以细分为较小的Span,以满足映射新内存Span的需要。默认情况下,在映射新的虚拟内存之前,分配器将贪婪地从可用缓存中抓取并分割任何较大的Span。然而,Span目前不能粘在一起再次形成更大的超级Span。Subspan可以遍历缓存,并由不同的线程独立使用。
A span that is a subspan of a larger super span can be individually decommitted to reduce physical memory pressure when the span is evicted from caches and scheduled to be unmapped. The entire original super span will keep track of the subspans it is broken up into, and when the entire range is decommitted tha super span will be unmapped. This allows platforms like Windows that require the entire virtual memory range that was mapped in a call to VirtualAlloc to be unmapped in one call to VirtualFree, while still decommitting individual pages in subspans (if the page size is smaller than the span size).
当从缓存中取出Span并计划取消映射时,作为较大超级Span的子Span的Span可以单独解除缩以减少物理内存压力。整个原始超级Span将跟踪它被分解成的子Span,当整个范围被解除时,超级Span将被取消映射。这允许像Windows这样的平台在一次调用VirtualFree中取消映射在调用VirtualAlloc 中映射的整个虚拟内存范围,同时仍解除子Span中的单个页面 (如果页面大小小于Span大小)。
If you use a custom memory map/unmap function you need to take this into account by looking at the release parameter given to the memory_unmap function. It is set to 0 for decommitting individual pages and the total super span byte size for finally releasing the entire super span memory range.
如果您使用自定义内存映射/取消映射函数,您需要考虑查看给memory_unmap函数的release参数。它设置为0,用于解除单个页面,总超跨字节大小用于最终释放整个超跨内存范围。
Memory fragmentation内存碎片
There is no memory fragmentation by the allocator in the sense that it will not leave unallocated and unusable “holes” in the memory pages by calls to allocate and free blocks of different sizes. This is due to the fact that the memory pages allocated for each size class is split up in perfectly aligned blocks which are not reused for a request of a different size. The block freed by a call to rpfree will always be immediately available for an allocation request within the same size class.
分配器没有内存碎片,因为它不会通过调用分配和释放不同大小的块在内存页面中留下未分配和不可用的 “孔”。这是因为为每个大小类分配的内存页面被拆分成完全对齐的块,这些块不会为不同大小的请求重复使用。通过调用rpfree 释放的块将始终可立即用于相同大小类别中的分配请求。
However, there is memory fragmentation in the meaning that a request for x bytes followed by a request of y bytes where x and y are at least one size class different in size will return blocks that are at least one memory page apart in virtual address space. Only blocks of the same size will potentially be within the same memory page span.
然而,存在内存碎片,这意味着:对x字节的请求后跟y字节的请求,其中x和y至少是大小不同的大小类,将返回至少为在虚拟地址空间中间隔一个内存页。只有相同大小的块可能在相同的内存页面Span内。
rpmalloc keeps an “active span” and free list for each size class. This leads to back-to-back allocations will most likely be served from within the same span of memory pages (unless the span runs out of free blocks). The rpmalloc implementation will also use any “holes” in memory pages in semi-filled spans before using a completely free span.
rpmalloc为每个大小类保留一个 “活动Span” 和空闲列表。这导致背靠背分配很可能在相同的内存页面范围内提供 (除非该Span用完了空闲块)。在使用完全空闲Span之前,rpmalloc实现还将使用半填充Span的内存页面中的任何 “孔”。
First class heaps一类堆
rpmalloc provides a first class heap type with explicit heap control API. Heaps are maintained with calls to rpmalloc_heap_acquire and rpmalloc_heap_release and allocations/frees are done with rpmalloc_heap_alloc and rpmalloc_heap_free. See the rpmalloc.h documentation for the full list of functions in the heap API. The main use case of explicit heap control is to scope allocations in a heap and release everything with a single call to rpmalloc_heap_free_all without having to maintain ownership of memory blocks. Note that the heap API is not thread-safe, the caller must make sure that each heap is only used in a single thread at any given time.
rpmalloc提供带有显式堆管理API的第一类堆类型。堆是通过调用rpmalloc_heap_acquire 和 rpmalloc_heap_release 来维护的,调用rpmalloc_heap_alloc分配, 调用rpmalloc_heap_free释放。在rpmalloc.h中可以查看堆API中的函数的完整列表。显式堆管理的主要用例是确定堆中的分配范围,通过一次调用rpmalloc_heap_free_all 来释放, 无需维护内存块的所有权。请注意,堆API不是线程安全的,调用方必须确保每个堆在任何给定时间仅在单个线程中使用。
Producer-consumer scenario生产者-消费者场景
Compared to the some other allocators, rpmalloc does not suffer as much from a producer-consumer thread scenario where one thread allocates memory blocks and another thread frees the blocks. In some allocators the free blocks need to traverse both the thread cache of the thread doing the free operations as well as the global cache before being reused in the allocating thread. In rpmalloc the freed blocks will be reused as soon as the allocating thread needs to get new spans from the thread cache. This enables faster release of completely freed memory pages as blocks in a memory page will not be aliased between different owning threads.
与其他一些分配器相比,rpmalloc不会受生产者-消费者线程场景的影响,即一个线程分配内存块,而另一个线程释放块。在某些分配器中,空闲块需要遍历线程缓存来释放,以及遍历全局缓存,然后才能在分配该内存块的线程中重用。在rpmalloc中,一旦分配线程需要从线程缓存中获取新的Span,释放的块将被重用。这可以更快地释放完全释放的内存页面,因为内存页面中的块不会在不同线程之间共用,即它是线程独占的。
Best case scenarios最优情况
Threads that keep ownership of allocated memory blocks within the thread and free the blocks from the same thread will have optimal performance.
在哪个线程中分配的内存块,就在哪个线程中释放该内存块,这样才具有最佳性能。
Threads that have allocation patterns where the difference in memory usage high and low water marks fit within the thread cache thresholds in the allocator will never touch the global cache except during thread init/fini and have optimal performance. Tweaking the cache limits can be done on a per-size-class basis.
如果线程的分配模式中,内存使用量的高低水位差符合分配器中的线程缓存阈值(即线程缓存大于或等于线程的内存使用量高水位和低水位之间的差),那么除了在线程init/fini期间,线程将永远不会触及全局缓存,并具有最佳性能。调整缓存限制可以在每个大小类的基础上进行。
Worst case scenarios最坏情况
Since each thread cache maps spans of memory pages per size class, a thread that allocates just a few blocks of each size class (16, 32, …) for many size classes will never fill each bucket, and thus map a lot of memory pages while only using a small fraction of the mapped memory. However, the wasted memory will always be less than 4KiB (or the configured memory page size) per size class as each span is initialized one memory page at a time. The cache for free spans will be reused by all size classes.
由于每个线程缓存为每个大小类映射内存页的跨度,一个为许多大小类中每个大小类(16、32……)只分配几个块的线程将永远不会填满每个桶,从而映射大量的内存页,而只使用映射内存的一小部分。然而,浪费的内存将总是小于4KiB(或配置的内存页大小),因为每个跨度是每次初始化一个内存页。空闲跨度的缓存将被所有大小类重新使用。
Threads that perform a lot of allocations and deallocations in a pattern that have a large difference in high and low water marks, and that difference is larger than the thread cache size, will put a lot of contention on the global cache. What will happen is the thread cache will overflow on each low water mark causing pages to be released to the global cache, then underflow on high water mark causing pages to be re-acquired from the global cache. This can be mitigated by changing the MAX_SPAN_CACHE_DIVISOR define in the source code (at the cost of higher average memory overhead).
如果线程的分配模式是进行大量的分配和释放,而这些分配和释放在高水位和低水位之间有很大的差异,并且这个差异大于线程缓存的大小,那么就会给全局缓存带来很大的竞争 。会发生的情况是,线程缓存会在每个低水位点上溢出,导致页面被释放到全局缓存中,然后在高水位点上溢出,导致页面被重新从全局缓存中获取。这可以通过改变源代码中的MAX_SPAN_CACHE_DIVISOR定义来缓解(代价是平均内存开销增加)。
Caveats注意事项
VirtualAlloc has an internal granularity of 64KiB. However, mmap lacks this granularity control, and the implementation instead oversizes the memory mapping with configured span size to be able to always return a memory area with the required alignment. Since the extra memory pages are never touched this will not result in extra committed physical memory pages, but rather only increase virtual memory address space.
VirtualAlloc有一个64KiB的内部颗粒度。然而,mmap缺乏这种粒度控制,而实现上却用配置的跨度大小来过度放大内存映射,以便能够总是返回一个具有所需对齐方式的内存区域。由于额外的内存页从未被触及,这不会导致额外的物理内存页,而只是增加虚拟内存地址空间。
All entry points assume the passed values are valid, for example passing an invalid pointer to free would most likely result in a segmentation fault. The library does not try to guard against errors!.
所有的入口点都假定所传递的值是有效的,例如,传递一个无效的指针给free,很可能会导致段错误。该库并不试图防范这类错误。
To support global scope data doing dynamic allocation/deallocation such as C++ objects with custom constructors and destructors, the call to rpmalloc_finalize will not completely terminate the allocator but rather empty all caches and put the allocator in finalization mode. Once this call has been made, the allocator is no longer thread safe and expects all remaining calls to originate from global data destruction on main thread. Any spans or heaps becoming free during this phase will be immediately unmapped to allow correct teardown of the process or dynamic library without any leaks.
为了支持全局范围的数据进行动态分配/释放,例如具有自定义构造函数和析构函数的C++对象,对rpmalloc_finalize的调用不会完全终止分配器,而是清空所有缓存并将分配器放入最终模式。一旦调用了这个函数,分配器就不再是线程安全的,并期望所有剩余的调用都来自主线程上的全局数据析构。在这一阶段,任何跨区或堆一旦变得空闲,将被立即取消映射,以允许正确销毁进程或动态库而不发生任何内存泄漏。
Other languages
Johan Andersson at Embark has created a Rust wrapper available at rpmalloc-rs
Stas Denisov has created a C# wrapper available at Rpmalloc-CSharp
License
This is free and unencumbered software released into the public domain.
Anyone is free to copy, modify, publish, use, compile, sell, or distribute this software, either in source code form or as a compiled binary, for any purpose, commercial or non-commercial, and by any means.
In jurisdictions that recognize copyright laws, the author or authors of this software dedicate any and all copyright interest in the software to the public domain. We make this dedication for the benefit of the public at large and to the detriment of our heirs and successors. We intend this dedication to be an overt act of relinquishment in perpetuity of all present and future rights to this software under copyright law.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
For more information, please refer to http://unlicense.org
You can also use this software under the MIT license if public domain is not recognized in your country
The MIT License (MIT)
Copyright (c) 2017 Mattias Jansson
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.

若有收获,就点个赞吧
0 人点赞
