1. OOM问题定位方法
内存溢出和内存泄露
内存溢出概念
JVM内存不够了,,目前无法存放创建的对象
原因
- JVM分配的内存太小,也可能是服务器本身内存太小,也许是JVM分配的堆内存太小
- 某段代码死循环,导致疯狂创建对象,但又不会触发GC
- 创建的对象太大,导致新生代存不下,老年代也存不下,只能OOM了。
解决
- 增加服务器内存,设置合理的-Xms和-Xmx
- 通过线程dump和堆dump,分析出现问题的代码
- 增大JVM内存,及时GC
内存泄露概念
不会被使用的对象却不能被回收,就是内存泄露
例子
public class Simple{Object o1;public void method() {o1 = new Object();//...其他代码}}在Simple实例被回收之前,o1都不会被回收,因为o1是全局变量
改进:
public class Simple{Object o1;public void method() {o1 = new Object();//...其他代码o1 = null; //帮助GC}
调优思路
确定是否有频繁Full FC现在
线上内存OOM问题是最难定位的问题,最常见的原因:
(1)本身资源不够
(2)申请的太多
(3)资源耗尽
某服务器上部署了Java服务,出现OutOfMemoryError,请问有可能是什么原因,问题应该如何定位?
解决思路:
Java服务OOM,最常见的原因为:
(1)有可能是内存分配确实过小,而正常业务需要使用更大的内存;
(2)某一个对象被频繁申请,却没有释放,内存不断泄露,导致内存耗尽;
(3)某一个资源被不断申请,系统资源耗尽,例如:不断创建线程,不断发起网络连接
排查过程
1.确认是不是内存本身就分配过小
jmap -heap pid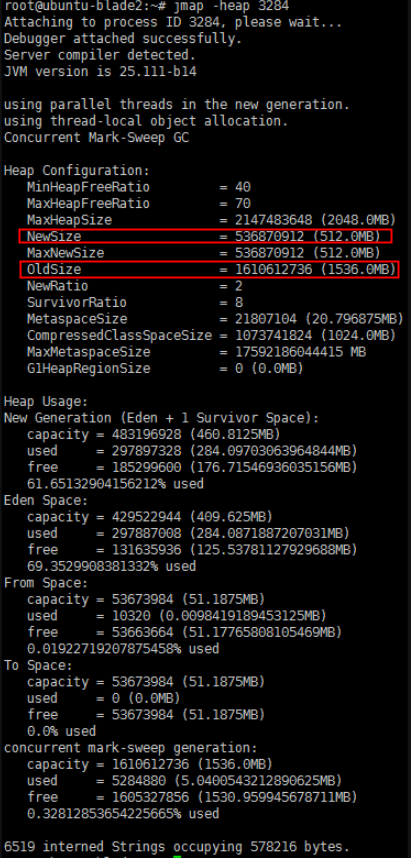
如图,可以查看新生代,老年代堆内存的分配大小以及使用情况,看是否本身分配过小。
2.找到最耗内存的对象
jmap -histo:live pid | more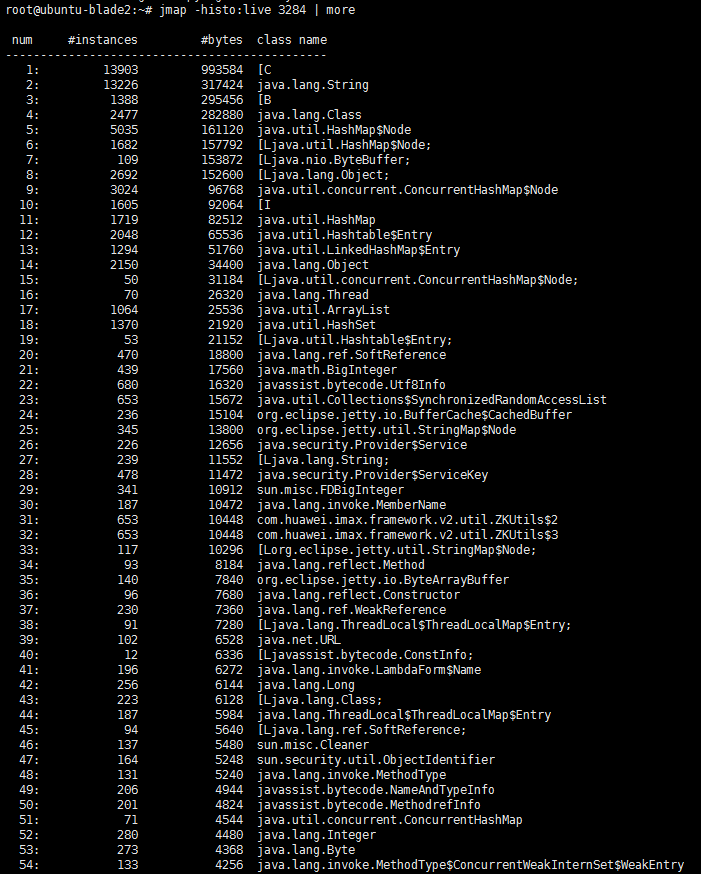
如图,结果以表格的形式显示存活对象的信息,并按照所占内存大小排序:
实例数,所占内存大小,类名
如果发现某类对象占用内存很大,很可能是类对象创建太多,且一直未释放。例如:
(1)申请完资源后,未调用close释放资源
(2)消费者消费速度慢,生产者不断往队列中投递任务,导致队列中任务累积过多
3.确认释放是资源耗尽
pstree:查看进程创建的线程数
netstat:网络连接数
还有另一种方法,通过
ll /proc/pid/fd 查看占用句柄
ll /proc/pid/task 查看线程数
例如,某一台显示服务器的sshd进程是1041,查看: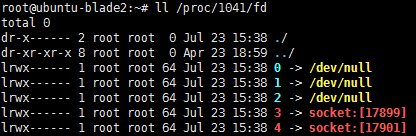
sshd共占用了5个句柄。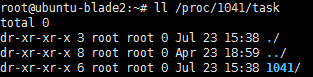
sshd只有一个主线程为1041,并没有多线程。
2. 100%CPU问题排查(或CPU突然飙升)
下面给出两种系统环节下的排查步骤,都是一模一样的,只是命令稍有区别!
- 查消耗cpu最高的进程Pid
- 根据Pid查出消耗cpu最高的线程号
- 根据线程号查出对应的java线程,进行处理。
准备一行死循环代码
public class TestFor {public static void main(String[] args) {int random = 0;while (random < 100) {random = random * 10;}}}
1.查消耗Cpu最高的进程PID
执行命令
- 执行top -c,显示进程运行信息列表。按下P,进程按照Cpu使用率排序
如下图所示,PID为3033的进程耗费Cpu最高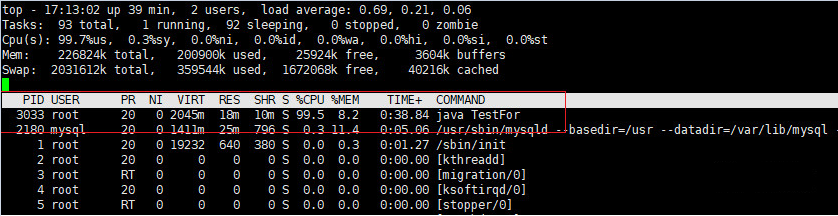
2.根据Pid查出消耗Cpu最高的线程号
执行命令
- top -Hp 3033,显示一个进程的线程运行信息列表。按下P,进程按照Cpu使用率排序
如下图所示,PID为3034的线程耗费Cpu最高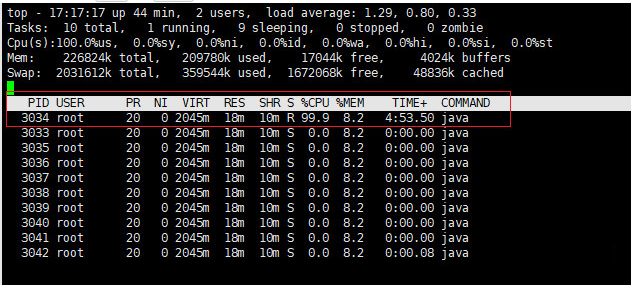
这是十进制的数据,将3034转成十六进制为0Xbda
3.根据线程号查出对应的java线程,进行处理
jstack -l 3033 > ./3033.stack
然后执行,grep命令,看线程0xbda做了什么cat 3033.stack |grep 'bda' -C 8
输出如下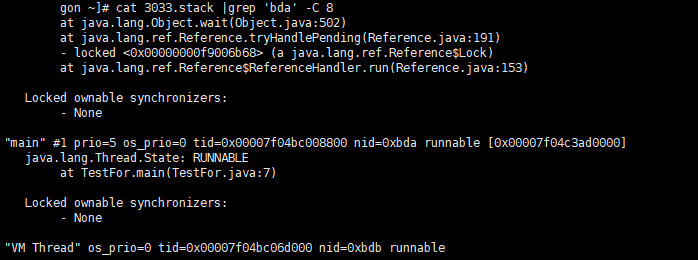
3. GC疑难情况问题分析
1、查询业务日志,可以发现这类问题:请求压力大,波峰,遭遇降级,熔断等等,基础服务、外部AP依赖。
2、查看系统资源和监控信息
硬件信息、操作系统平台、系统架构;
排査CPU负载、内存不足,磁盘使用量、硬件故障、磁盘分区用满、IO等待、IO密集、丟数据、并发竞
争等情况
排査网绉流量打满,响应超时,无响应,DNS问题,网络抖动,防火墙问题,物理故障,网络参数调整
超时、莲接
3、查看性能指标,包括实时监控、历史数据。可以发现假死,卡顿、响应变慢等现象;
排查数据库,并发连接数、慢查询、索引、磁盘空间使用量、内存使用量、网络带宽、死锁、TPS、查询
数据量、redo日志、undo、 binlog日志、代理、工具BUG。
可以考虑的优化包括:集群、主备、只读 、分片、分区
大数据,中间件, JVM参数。
4、排查系统日志,比如重启、崩溃、Kill。
APM,比如发现有些链路请求变慢等等
6、排查应用系统
排查配置文件:启动参数配置、 Spring配置、JVM监控参数、数据库参数、Loq参数、APM配置
内存问题,比如是否存在内存泄漏,内存溢出、批处理导致的内存放大、GC问题等等
GC问题,确定GC算法、确定GC的κpl,GC总耗时、GC最大暂停时间、分析GC日志和监控指标:内存
分配速度,分代提升速度,内存使用率等数据。适当时修改内存配置
排查线程,理解线程状态、并发线程数,线程Dump,锁资源、锁等待,死锁
排查代码,比如安全漏洞、低效代码、算法优化、存储优化、架构调整、重构、解决业务代码B∪G、第三方
库、ⅩS5、CORS、正则
单元测试:覆盖率、边界值、Mock测试、集成测试
7、排除资源竞争、坏邻居效应
8、疑难问题排查分析手段
DUMP线程\内存
抽样分析\调整代码、异步化、削峰填谷。
4. 系统频繁Full GC导致系统卡顿是怎么回事
- 机器配置:2核4G
- JVM内存大小:2G
- 系统运行时间:7天
- 期间发生的Full GC次数和耗时:500多次,200多秒
- 期间发生的Young GC次数和耗时:1万多次,500多秒
大致算下来每天会发生70多次Full GC,平均每小时3次,每次Full GC在400毫秒左右;
每天会发生1000多次Young GC,每分钟会发生1次,每次Young GC在50毫秒左右。
JVM参数设置如下:
-Xms1536M -Xmx1536M //初始堆1536M, 最大堆1536G-Xmn512M -Xss256K //年轻代 512M, 每个线程大小256k, 那么老年代即 1024M-XX:SurvivorRatio=6 //eden和S0 S1的比值-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M //元空间大小 256M-XX:+UseParNewGC -XX:+UseConcMarkSweepGC //使用CMS和ParNewGC作为GC收集器-XX:CMSInitiatingOccupancyFraction=75-XX:+UseCMSInitiatingOccupancyOnly
根据上面的数据, 能得出一下的大概模型
一分钟发生一次Young GC(把eden区填满了), 即 eden区大小/60秒, 得每秒大概产生6M对象左右 20分钟发生一次Full GC, 发生Full GC时old大小为75%, 即得出 20分钟有700M对象挪移到老年代
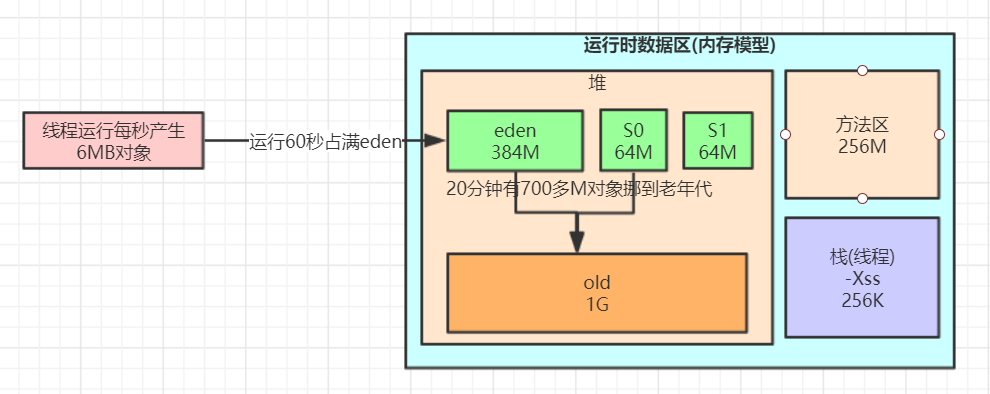
结合对象挪动到老年代那些规则推理下我们这个程序可能存在的一些问题
经过分析感觉可能会由于对象动态年龄判断机制导致full gc较为频繁
为了看效果,我模拟了一个示例程序,打印了jstat的结果如下:
jstat -gc 13456 2000 10000
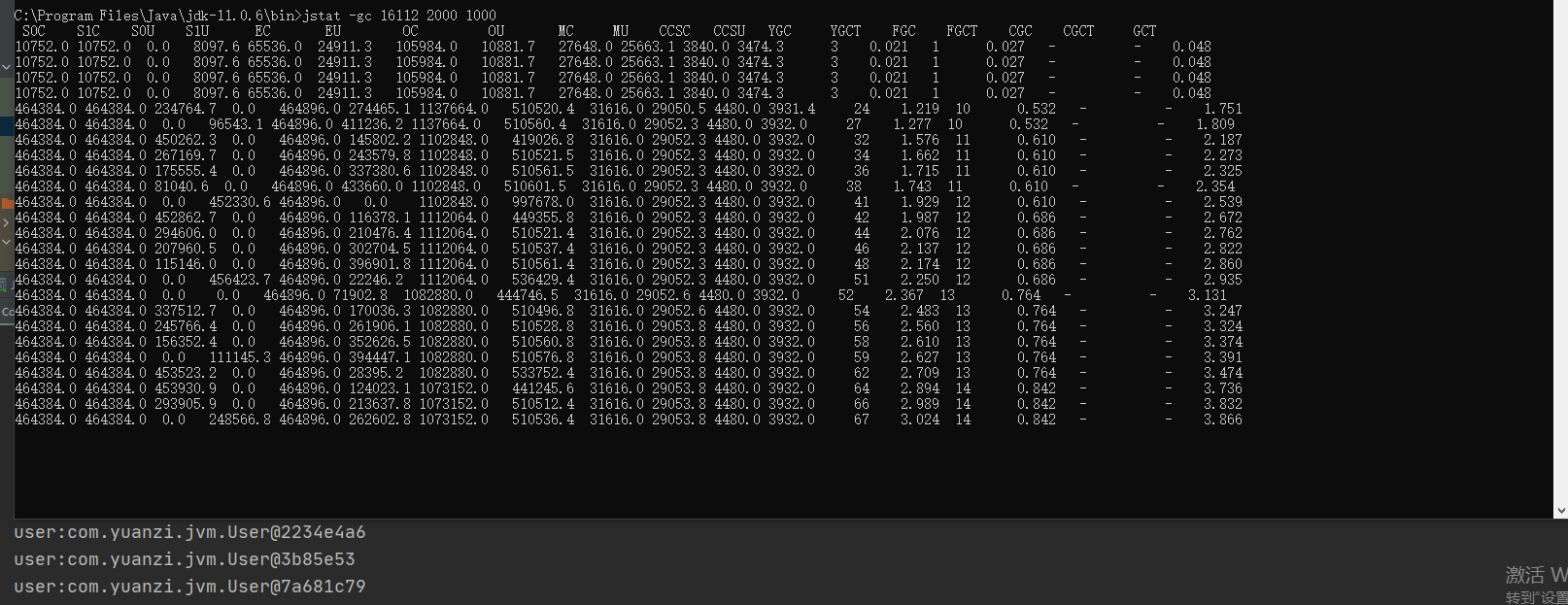
对于对象动态年龄判断机制导致的full gc较为频繁可以先试着优化下JVM参数,把年轻代适当调大点, 老年代触发Full gc的比率调到92
-Xms1536M -Xmx1536M -Xmn1024M -Xss256K -XX:SurvivorRatio=6-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+UseParNewGC-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=92-XX:+UseCMSInitiatingOccupancyOnly
优化完发现没什么变化,full gc的次数比minor gc的次数还多了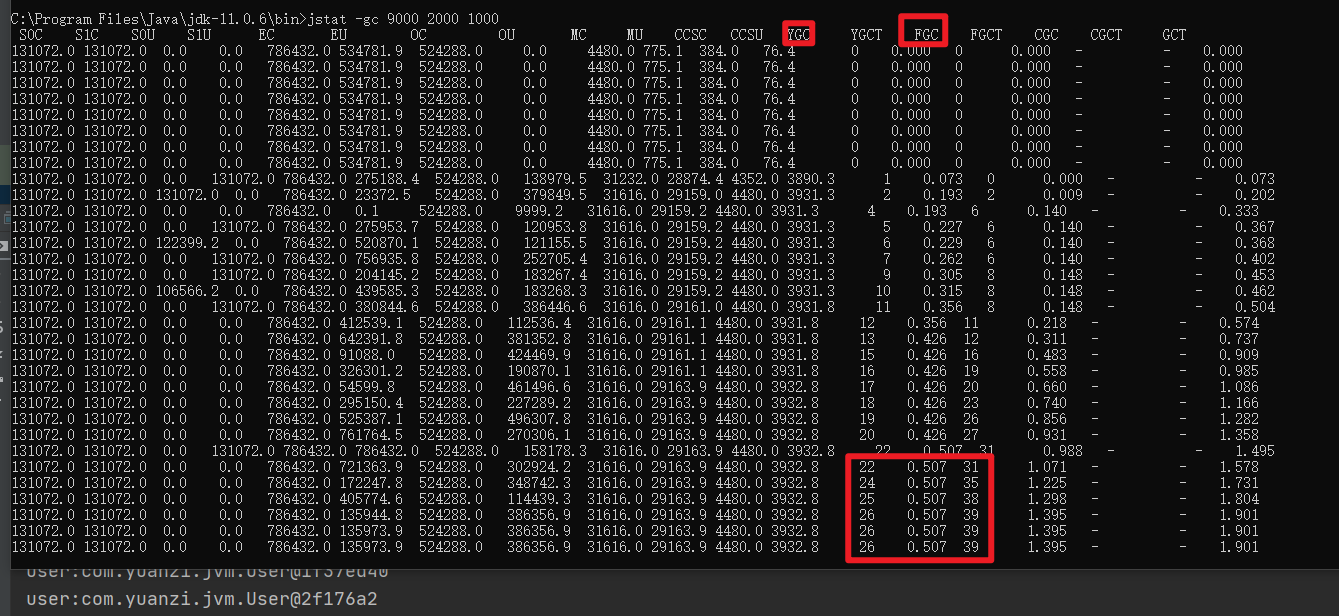
我们可以推测下full gc比minor gc还多的原因有哪些?
1、元空间不够导致的多余full gc
2、显示调用System.gc()造成多余的full gc,这种一般线上尽量通过-XX:+DisableExplicitGC参数禁用,如果加上了这个JVM启动参数,那么代码中调用System.gc()没有任何效果
3、老年代空间分配担保机制
最快速度分析完这些我们推测的原因以及优化后,我们发现young gc和full gc依然很频繁了,而且看到有大量的对象频繁的被挪动到老年代,这种情况我们可以借助[jmap](https://www.yuque.com/ltvc5b/java/guz1w5#JvJlS)命令大概看下是什么对象
jmap -histo 14532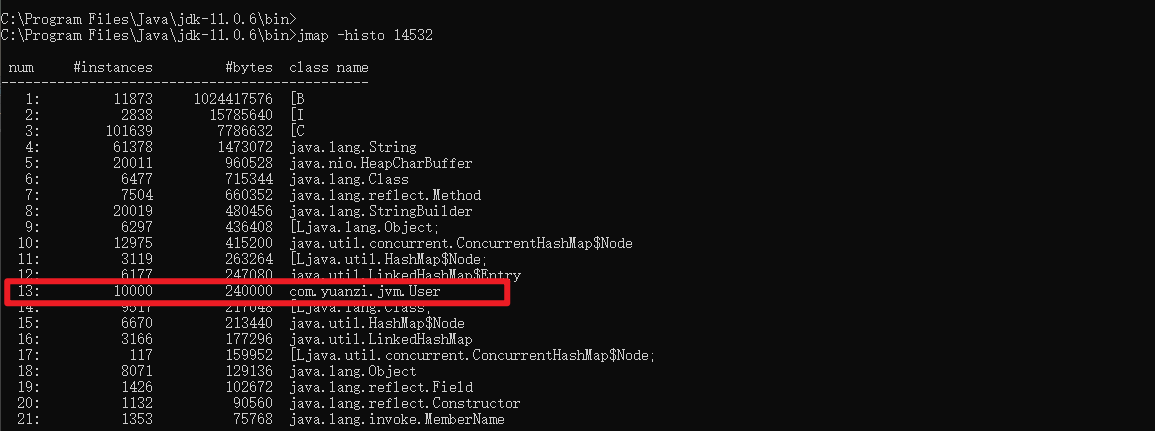
查到了有大量User对象产生,这个可能是问题所在,但不确定,还必须找到对应的代码确认,如何去找对应的代码了?
1、代码里全文搜索生成User对象的地方(适合只有少数几处地方的情况)
2、如果生成User对象的地方太多,无法定位具体代码,我们可以同时分析下占用cpu较高的线程,一般有大量对象不断产生,对应的方法代码肯定会被频繁调用,占用的cpu必然较高
可以用上面讲过的[jstack](https://www.yuque.com/ltvc5b/java/guz1w5#VveUx)或[jvisualvm](https://www.yuque.com/ltvc5b/java/guz1w5#3F85s)来定位cpu使用较高的代码,最终定位到的代码如下: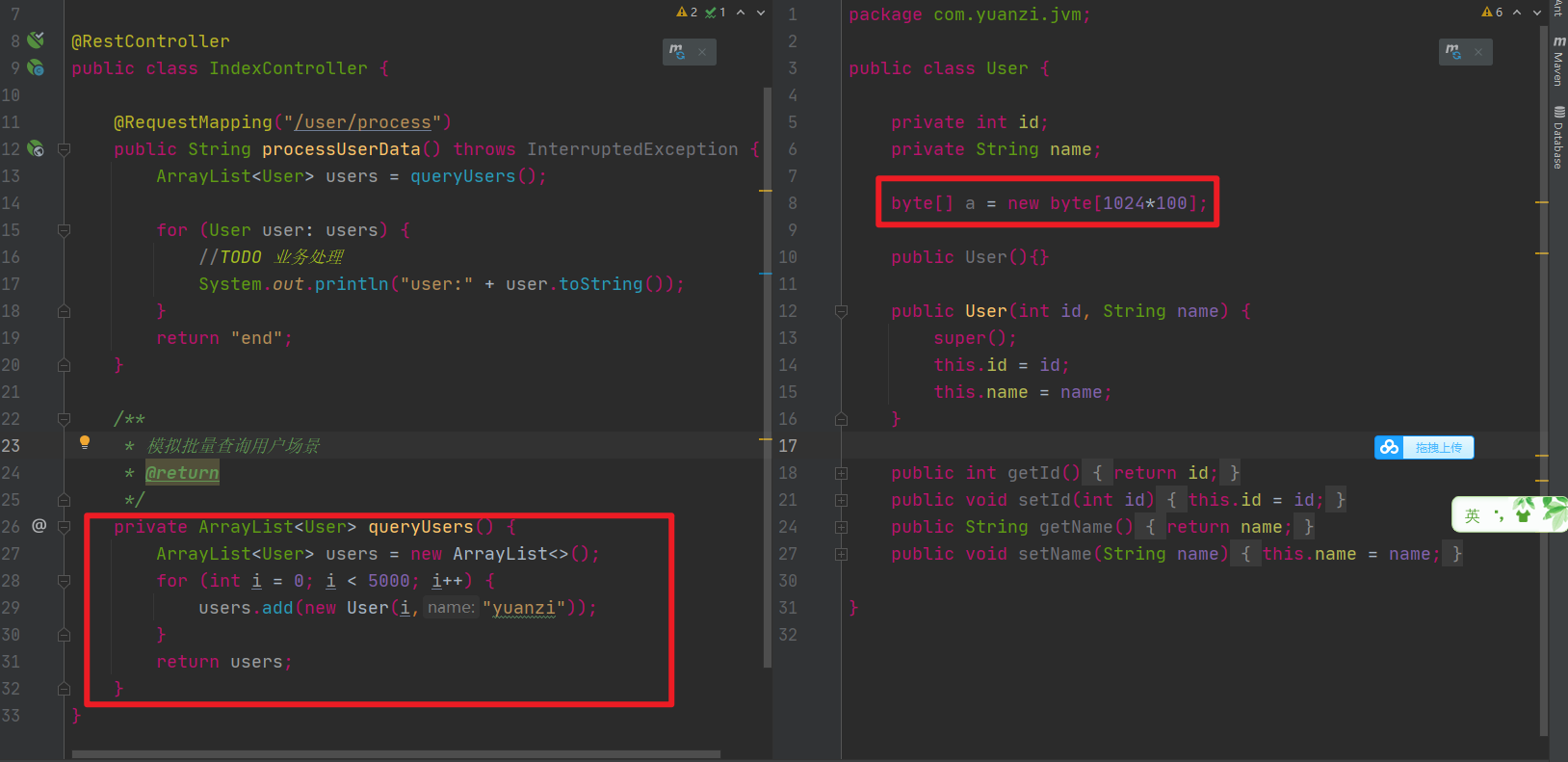 同时,java的代码也是需要优化的,一次查询出500M的对象出来,明显不合适,
同时,java的代码也是需要优化的,一次查询出500M的对象出来,明显不合适,
要根据之前说的各种原则尽量优化到合适的值,尽量消除这种朝生夕死的对象导致的full gc

若有收获,就点个赞吧
0 人点赞
