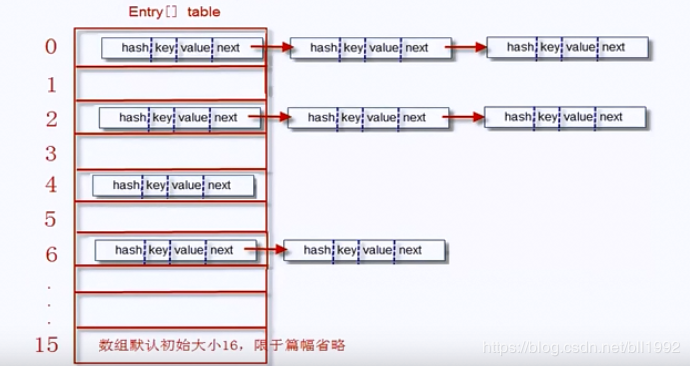
hashmap底层实现采用的是哈希表(基本结构就是“数组+链表”)。
一个Entry[]对象存储了:
1、key:键对象value:值对象
2:next:下一个节点
3、hash值对象的hash值。
显然每一个Entry对象就是一个单向链表结构,我们使用图形表示一个Entry对象的典型示意:

然后,我们画出Entry[]数组的结构(这也是HashMap的结构):在这里我们把单向链表存储在一个数组里面。
一、存储数据的过程put(key,value)
明白了HashMap的基本结构后,我们继续深入学习HashMap如何存储数据的。此处的核心是如何产生hash值,该值用来对应数组的存储位置。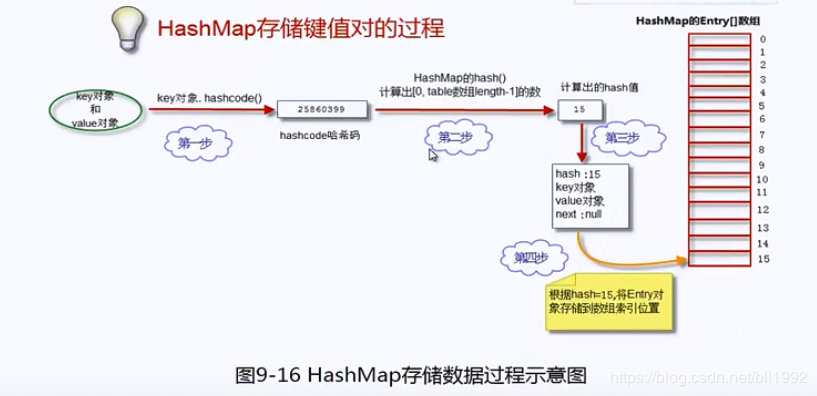
我们的目的是将“key-value两个对象” 成对的存放到HashMap扥Entry[]数组中,参见以下步骤:
1、获得key对象的hashcode
首先调用key对象的hashcode()方法,获得hashcode。
2、根据hashcode计算出hash值(要求在[0,数组长度-1]区间)
hashcode是一个整数,我们需要将它转化成[0,数组长度-1]区间)的范围。我们要求转化后的hash值尽量均匀地分布在[0,数组长度-1]区间),减少“hash冲突”。
- 一个简单和常用的计算hash值的算法(相除取余算法)
- hash值=hashcode%数组的长度
- 这种算法可以让hash值均匀的分布在[0,数组长度-1]的区间。早期HashTable就是采用这种算法。但是,这种算法由于使用了“除法”,效率低下。JDK后来改进了算法。首先约定数组长度必须为2的整数幂,这样采用位运算即可实现取余的效果:hash值=hashcode&(数组长度-1)。
测试Hash算法
public class test {
//测试hash算法
public static void main(String[] args) {
int h=25860399;
int length=16;//length为2的整数次幂,则h&(length-1)相当于length取模
myHash(h,length);
}
public static int myHash(int h,int length){
System.out.println("通过位运算实现取余操作:"+(h&(length-1)));
System.out.println("直接取余操作:"+(h%length));
return h&(length-1);
}
}
运行上面的程序,我们发现直接取余h%length和位运算+(h&(length-1))结果是一致的。事实是为了获得更好的散列效果。
3、生成Entry对象
如上所述,一个Entry对象包含4部分:key对象、value对象、hash值、指向下一个Entry对象的引用。我们现在算出了hash值。下一个Entry对象的引用为null。
4、将Entry对象放到table数组中
如果本Entry对象对应的数组索引位置还没有放Entry对象,则直接将Entry对象存储进数组;如果对应索引位置已经有Entry对象,则将已有Entry对象的next指向本Entry对象,形成链表。
总结上述过程:
当添加一个元素(key-value)时,首先计算key的hash值,以此确定插入数组中的位置,但是可能存在同一个hash值的元素已经放在同一位置了,这是就添加到同一hash值元素的后面,他们在数组同一个位置,就形成了链表,同一个链表上的hash值是相同的,所以说数组存放的是链表。
二、取数据过程get(key)
我们需要通过key对象获得“键值对”对象,进而返回value对象,明白了存储数据过程,去数据过程就比较简单了,参见以下步骤:
扩容问题
HashMap的位桶数组,初始大小为16.实际使用时,显然大小是可变的。如果位桶数组中的元素达到(0.75*数组length),就重新调整数组大小变为原来2倍大小。
扩容很耗时的,扩容的额本质是定义新的更大的数组,并将旧的数组内容挨个拷贝到新的数组中。
- 获得key的hashcode,通过hash()散列算法得到hash值,进而定位到数组的位置。
- 在链表上挨个比较key对象。调用equel()方法,将key对象和链表上所有节点的key对象进行比较,直到碰到返回 true的节点对象为止。
- 返回equel()为true的节点对象的value对象。
简单手动实现
package com.autotest.openapi.define.util;
public class MyHashMap<K, V> {
private class Node<T> {
int hasCode;
T key ;
T value;
Node next;
}
//位桶数组
Node[] table;
//存放的键值对的个数
int size;
public MyHashMap() {
table = new Node[16];
}
public void put(K key, V value) {
//定义了新的节点对象
Node newNode = new Node();
newNode.hasCode = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
newNode.next = null;
Node temp = table[newNode.hasCode];
Node iterLast = null;
boolean isRepeat = false;
if (temp == null) {
//如果当前table哈希是空,直接存入
table[newNode.hasCode] = newNode;
size++;
} else {
//如不为空,则需要遍历对应的链表
while (temp != null) {
//如果key相同了,替换原来的值
if (temp.key.equals(key)) {
isRepeat = true;
temp.value = value;
break;
} else {
//key不重复,则遍历下一个
iterLast = temp;
temp = temp.next;
}
}
if (!isRepeat) {
iterLast.next = newNode;
size++;
return;
}
}
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
//遍历数组
for (int i = 0; i < table.length; i++) {
Node temp = table[i];
//遍历链表
while (temp != null) {
sb.append(temp.key + ":" + temp.value + ",");
temp = temp.next;
}
}
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
private int myHash(int v, int length) {
//System.out.println("hash in myHash:" + (v&(length-1))); //直接位运算,效率高
//System.out.println("hash in myHash:" + (v%(length-1))); //取模运算,效率低
return v & (length - 1);
}
public static void main(String[] args) {
MyHashMap<Integer, String> mhm = new MyHashMap<Integer,String>();
mhm.put(10, "a");
mhm.put(20, "b");
mhm.put(30, "c");
mhm.put(30, "ddd");
mhm.put(30, "ddd");
System.out.println("字典长度:" + mhm.size);
System.out.println(mhm);
}
}

若有收获,就点个赞吧
0 人点赞
