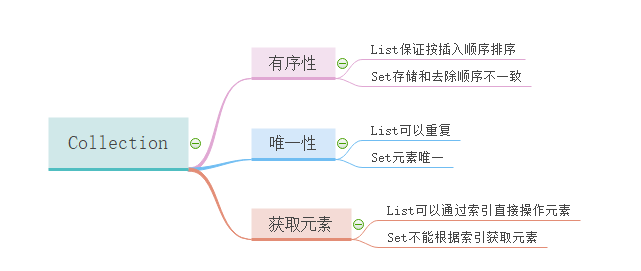
1.List和Set的区别:
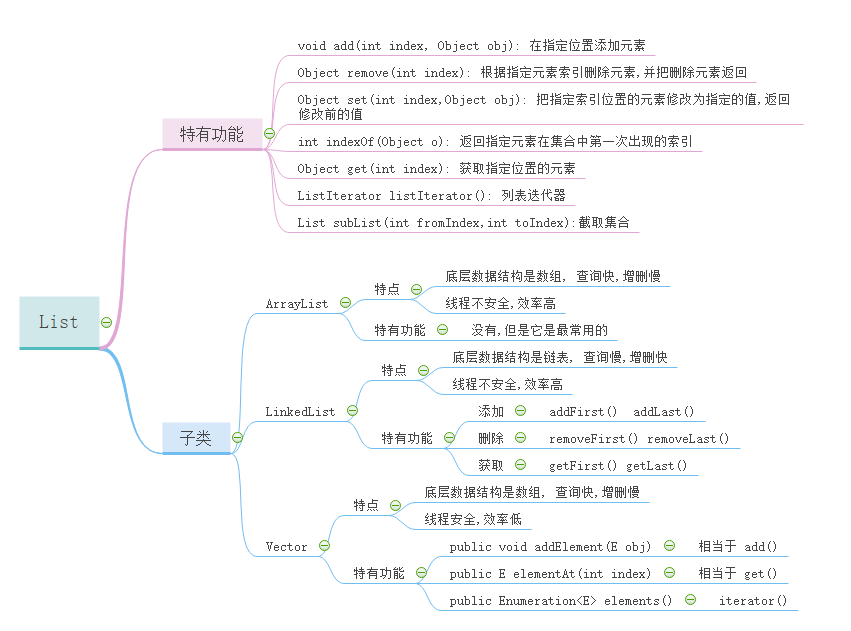
2.List
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
(3)Vector**:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
3.Set
3.1 HashSet : 为快速查找设计的Set。
存入HashSet的对象必须定义hashCode()。
Hashset实现set接口,由哈希表(实际上是一个HashMap实例)支持。它不保证set的迭代顺序,别是它不保证该顺序恒久不变。此类允许使用Null元素 对于HashSet而言,它是基于HashMap实现的,HashSet底层使用HashMap来保存所有元素,因此HashSet的实现比较简单,相关HashSet的操作,基本上都说调用HashMap的相关方法来实现的 对于HashSet中保存的对象,请注意正确重写其equals和hashCode方法,以保证放入的对象的唯一性。
HashSet: 哈希表结构的集合 利用哈希表结果构成的集合查找速度会很快。
HashSet : 底层数据结构是哈希表,线程 是不同步的 。 无序,高效;
HashSet 集合保证元素唯一性 :通过元素的 hashCode 方法,和 equals 方法完成的。
当元素的 hashCode 值相同时,才继续判断元素的 equals 是否为 true。如果为 true,那么视为相同元素,不存。如果为 false,那么存储。如果 hashCode 值不同,那么不判断 equals,从而提高对象比较的速度。
特点:存储取出都比较快
1、不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
2、HashSet不是同步的,必须通过代码来保证其同步。
3、集合元素可以是null.
原理:简单说就是链表数组结合体
3.2 Linkedhashset
LinkedHashSet : 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序
LinkedHashSet 综合了链表+哈希表,根据元素的hashCode值来决定元素的存储位置,它同时使用链表维护元素的次序。
当遍历该集合时候,LinkedHashSet 将会以元素的添加顺序访问集合的元素。
对于 LinkedHashSet 而言,它继承与 HashSet、又基于 LinkedHashMap 来实现的。
这个相对于HashSet来说有一个很大的不一样是LinkedHashSet是有序的。LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
与HashSet相比,特点:
对集合迭代时,按增加顺序返回元素。
性能略低于HashSet,因为需要维护元素的插入顺序。
但迭代访问元素时会有好性能,因为它采用链表维护内部顺序。
LinkedHashSet不允许元素的重复,存储的顺序是元素插入的顺序。
Linkedhashset实现原理 https://wiki.jikexueyuan.com/project/java-collection/linkedhashset.html
3.3 TreeSet
TreeSet : 保存次序的Set, 底层为树结构。使用它可以从Set中提取有序的序列。
TreeSet 继承AbstractSet类,实现NavigableSet、Cloneable、Serializable接口。与HashSet是基于HashMap实现一样,TreeSet 同样是基于TreeMap 实现的。由于得到Tree 的支持,TreeSet 最大特点在于排序,它的作用是提供有序的Set集合。
用于对 Set 集合进行元素的指定顺序排序,排序需要依据元素自身具备的比较性。
如果元素不具备比较性,在运行时会抛出ClassCastException 异常。 所以元素需要实现Comparable 接口 ,让元素具备可比较性, 重写 compareTo 方法 。依据 compareTo 方法的返回值,确定元素在 TreeSet 数据结构中的位置。 或者用比较器方式,将Comparator对象传递给TreeSet构造器来告诉树集使用不同的比较方法
TreeSet底层的数据结构就是二叉树。
- 不能写入空数据
- 写入的数据是有序的
- 不写入重复数据
TreeSet方法保证元素唯一性的方式:就是参考比较方法的结果是否为0,如果return 0,视为两个对象重复,不存。
TreeSet集合排序有两种方式,Comparable和Comparator区别:
- 让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。
- 让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造函数。
TreeSet类是SortedSet接口的实现类。因为需要排序,所以性能肯定差于HashSet。与HashSet相比,
额外增加的方法有:
- first():返回第一个元素
- last():返回最后一个元素
- lower(Object o):返回指定元素之前的元素
- higher(Obect o):返回指定元素之后的元素
- subSet(fromElement, toElement):返回子集合
- 可以定义比较器(Comparator)来实现自定义的排序。默认自然升序排序。
TreeSet两种排序方式:自然排序和定制排序,默认情况下,TreeSet采用自然排序
TreeSet会调用集合元素的compareTo(Object object)方法来比较元素之间的大小关系,然后将元素按升序排列
如果试图把一个元素添加到TreeSet中,则该对象必须实现Comparable接口实现Comparable接口必须实现compareTo(Object object),两个对象即通过这个方法进行比较Comparable的典型实现
BigDecimal、BigInteger以及所有的数值类型对应的包装类型,按对应的数值大小进行比较
Character:按字符的Unicode值进行比较
Boolean:true对应的包装类实例大于false包装类对应的实例
String:按字符对应的Unicode值进行比较
Date、Time:后面的时间、日期比前面的时间、日期大
TreeSet采用红黑树的数据结构来存储集合元素
对于TreeSet集合而言,它判断两个对象的是否相等的唯一标准是:
两个对象的通过compareTo(Object obj)方法比较是否返回0—如果通过compareTo(Object obj)方法比较返回0,TreeSet则会认为它们相等,否则认为它们不相等。对于语句,obj1.compareTo(obj2),如果该方法返回一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2.
在默认的compareTo方法中,需要将的两个的类型的对象的转换同一个类型,因此需要将的保证的加入到TreeSet中的数据类型是同一个类型,但是如果自己覆盖compareTo方法时,没有要求两个对象强制转换成同一个对象,是可以成功的添加treeSet中
如果两个对象通过CompareTo(Object obj)方法比较返回0时,但它们通过equals()方法比较返回false时,TreeSet不会让第二个元素添加进去
4.List和Set总结
- List,Set都是继承自Collection接口,Map则不是
- List特点:元素有放入顺序,元素可重复 ,Set特点:元素无放入顺序,元素不可重复,重复元素会覆盖掉,(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的,加入Set 的Object必须定义equals()方法 ,另外list支持for循环,也就是通过下标来遍历,也可以用迭代器,但是set只能用迭代,因为他无序,无法用下标来取得想要的值。)
- Set和List对比:
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
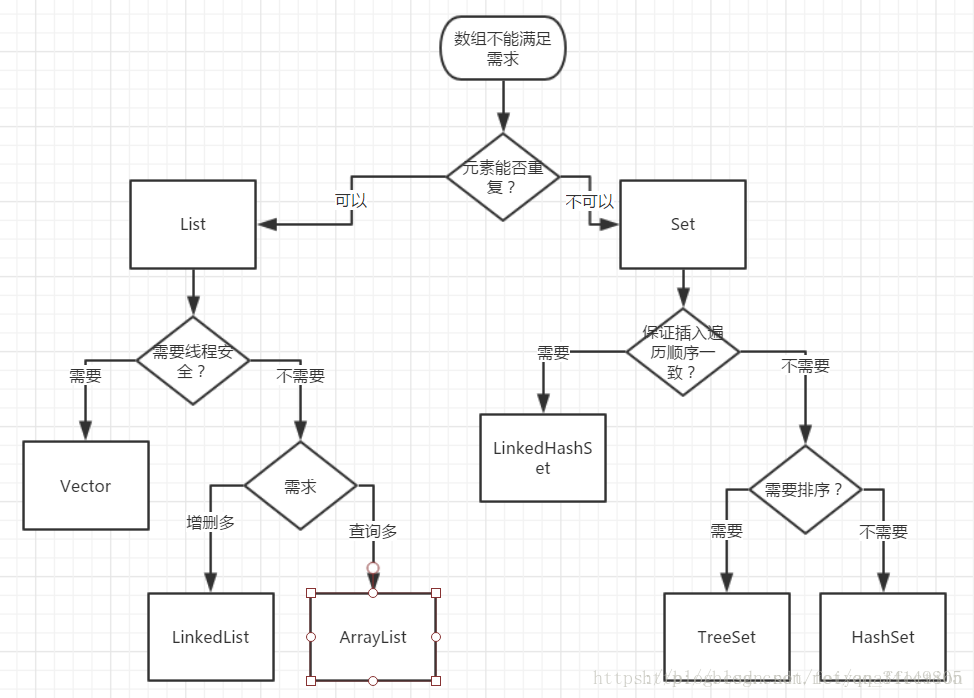
- 适用场景

若有收获,就点个赞吧
0 人点赞
