JDBC(一)概述
JDBC api包含以下几个核心部分:
- JDBC Drivers
- Connections
- Statements
- Result Sets
JDBC Drivers — 驱动
jdbc driver(驱动)是一个可以让你连接数据库的一个java类,它继承了很多个jdbc接口,当你用jdbc驱动的时候,它用标准的jdbc接口,所使用的具体JDBC驱动程序隐藏在JDBC接口后面。Connections — 连接
一旦加载并初始化JDBC驱动程序,就需要连接到数据库。 您可以通过JDBC API和加载的驱动程序获取与数据库的连接。 与数据库的所有通信都通过连接进行。 应用程序可以同时向数据库打开多个连接。Statements — 报告
Statement是用来对数据库执行语句。 可以使用几种不同类型的语句。 每条语句都对应一个增删改查。ResultSets — 结果集
对数据库执行查询(statement操作)后,你会得到一个ResultSet。 然后可以遍历此ResultSet以读取查询的结果。工作原理图
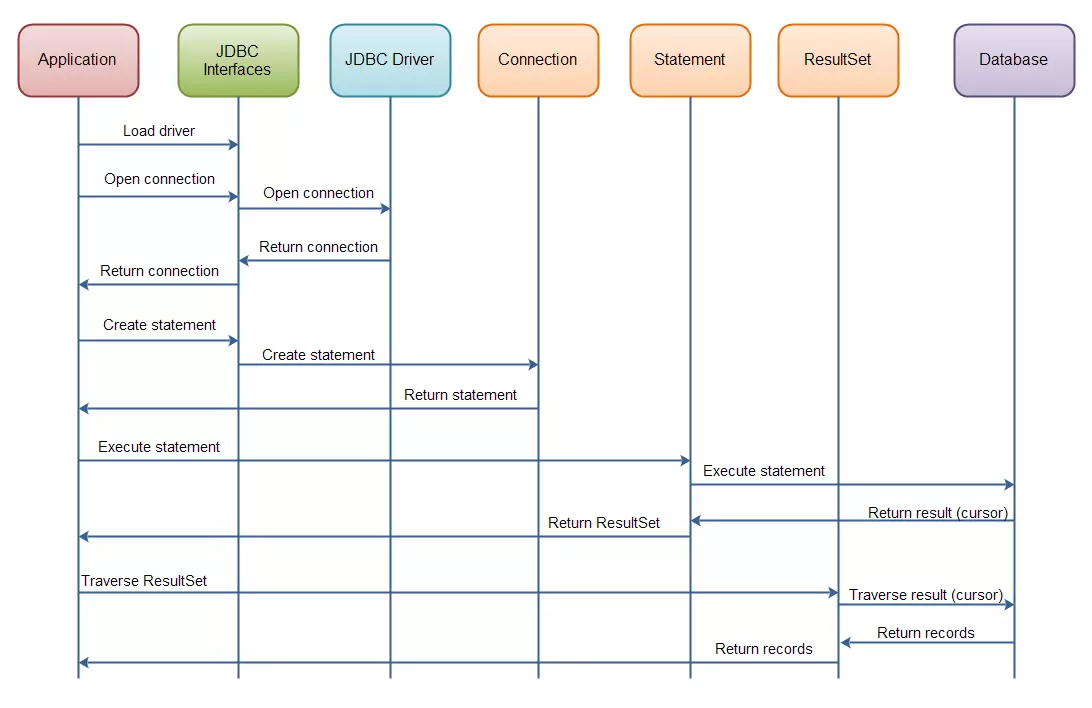
JDBC(二)驱动程序类型发展历程
有4种不同类型的JDBC驱动程序:
- 类型1:JDBC-ODBC桥驱动程序
- 类型2:Java +程序代码驱动程序
- 类型3:Java + Middleware转化驱动程序
- 类型4:Java驱动程序。
大多数类型都是4类型,Java驱动程序。JDBC-ODBC桥驱动程序
该类型的jdbc驱动运行原理是 在jdbc接口来调用odbc进行操作,这是最开始的做法。
科普:
jdbc:java database connectivity
odbc:open database connectivity 微软公司开放服务结构中有关数据库的一个组成部分
JDBC-ODBC桥驱动Java +程序代码驱动程序
该类型与odbc桥驱动很类似,就是把odbc的方式换成了程序代码。

Java + Middleware转化驱动程序
该驱动是将JDBC接口调用发送到中间服务器的全部Java驱动程序。 中间服务器然后代表JDBC驱动程序连接到数据库。

Java驱动程序。即jdbc
JDBC驱动程序是直接连接到数据库的Java驱动程序。 它针对特定的数据库产品实施。

JDBC(三)数据库连接和数据增删改查
加载JDBC驱动
只需要在第一次连接数据库时加载,java6以后我们可以直接这样加载:
- 我在本系列教程中用mysql示例。
- 需要导入jar包:mysql-connector-java-5.0.8-bin.jar(版本和下载网站自己挑)
- 如果是web程序,把jar包放到WebRoot/WEB-INF/lib/下
- 如果是普通java项目,将jar包导入到自己项目的lib库中。
- 然后加载驱动如下
Class.forName("com.mysql.jdbc.Driver");
打开连接
打开连接的话需要调用DriverManager类中的getConnection()方法,该方法有三个重载方法。如下所示 ```java public static Connection getConnection(String url,
}java.util.Properties info) throws SQLException {return (getConnection(url, info, Reflection.getCallerClass()));
public static Connection getConnection(String url, String user, String password) throws SQLException { java.util.Properties info = new java.util.Properties(); if (user != null) { info.put(“user”, user); } if (password != null) { info.put(“password”, password); } return (getConnection(url, info, Reflection.getCallerClass())); }
public static Connection getConnection(String url)throws SQLException {java.util.Properties info = new java.util.Properties();return (getConnection(url, info, Reflection.getCallerClass()));}
大概看下它的参数名字应该知道它需要什么吧。在这里我只解释第一个方法。Properties info 这个参数其实也是user和password的打包。其实和方法二一样。<a name="NMZl1"></a>###### 实例:```javapublic class Main {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/user";String user = "root";String password = "root";Connection connection = null;Statement statement = null;ResultSet resultSet = null;try {// 1.加载驱动//com.mysql.jdbc.DriverClass.forName("com.mysql.jdbc.Driver");// 2.获取连接connection = DriverManager.getConnection(url, user, password);// 3.获取用于向数据库发送SQL的Statement对象statement = connection.createStatement();// 4.执行sql,获取数据resultSet = statement.executeQuery("SELECT * FROM user;");// 解析数据while (resultSet.next()) {int id = resultSet.getInt("id");String name = resultSet.getString("username");String psd = resultSet.getString("birthday");String email = resultSet.getString("sex");String birthday = resultSet.getString("address");System.out.println(" " + name + " " + psd + " " + email+ " " + birthday);}} catch (ClassNotFoundException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();} finally {//5.关闭连接,释放资源if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {e.printStackTrace();}resultSet = null;}if (statement != null) {try {statement.close();} catch (SQLException e) {e.printStackTrace();}statement = null;}if (connection != null) {try {connection.close();} catch (SQLException e) {e.printStackTrace();}connection = null;}}}}
数据查询
数据查询需要我们将sql发送给数据库,我们需要创建一个Statement对象。
Statement statement = connection.createStatement();
因为Statement对象可以执行sql
String sql = "select * from user";ResultSet resultSet = statement.executeQuery(sql);
当执行一个sql查询的时候,会得道一个ResultSet对象,它里面放着查询的结果。
ResultSet resultSet = statement.executeQuery("SELECT * FROM user;");
那怎样获取user表中对应列的数据呢?
resultSet .getString ("columnName");resultSet .getLong ("columnName");resultSet .getInt ("columnName");resultSet .getDouble ("columnName");resultSet .getBigDecimal("columnName");
或者通过第几列进行查询。
resultSet .getString (1);resultSet .getLong (2);resultSet .getInt (3);resultSet .getDouble (4);resultSet .getBigDecimal(5);
如果你想知道对应列名的index值(位于第几列),可以这样
int columnIndex = resultSet .findColumn("columnName");
数据修改/删除
为什么要把修改和删除放一块说呢,因为他们和查询调用不一样的方法。
查询我们调用executeQuery()方法,修改和删除我们需要用executeUpdate()方法。
举个简单的例子:
//更新数据(也叫修改数据)String sql = "update user set name='fantj' where id=1";int rowsAffected = statement.executeUpdate(sql); //rowsAffected是影响行数的意思//删除数据String sql = "delete from user where id=123";int rowsAffected = statement.executeUpdate(sql);
关闭连接
为了安全性和项目性能,我们尽量在执行完操作之后关闭连接(虽然高版本jvm会自动关闭它,但是这也需要检测浪费cpu资源)。
关闭连接分为三个部分。
结果集类型,并发性和可持续性
当创建一个ResultSet时,你可以设置三个属性:
- 类型
- 并发
- 可保存性
在创建Statement或PreparedStatement时已经设置了这些值,如下所示: ```java
Statement statement = connection.createStatement( ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY, ResultSet.CLOSE_CURSORS_OVER_COMMIT );
PreparedStatement statement = connection.prepareStatement(sql, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY, ResultSet.CLOSE_CURSORS_OVER_COMMIT );
<a name="n4Vrq"></a>### 1. 最基本的ResultSet.之所以说是最基本的ResultSet是因为,这个ResultSet他起到的作用就是完成了查询结果的存储功能,而且只能读去一次,不能够来回的滚动读取.这种结果集的创建方式如下:
Statement st = conn.CreateStatement ResultSet rs = Statement.excuteQuery(sqlStr);
由于这种结果集不支持,滚动的读去功能所以,如果获得这样一个结果集,只能使用它里面的next()方法,逐个的读去数据.<a name="gSWbU"></a>### 2. 可滚动的ResultSet类型.这个类型支持前后滚动取得纪录next(),previous(),回到第一行first(),同时还支持要去的ResultSet中的第几行absolute(int n),以及移动到相对当前行的第几行relative(int n),要实现这样的ResultSet在创建Statement时用如下的方法.
Statement st = conn.createStatement(int resultSetType, int resultSetConcurrency) ResultSet rs = st.executeQuery(sqlStr)
其中两个参数的意义:- resultSetType是设置ResultSet对象的类型可滚动,或者是不可滚动.取值如下:- ResultSet.TYPE_FORWARD_ONLY只能向前滚动ResultSet.TYPE_SCROLL_INSENSITIVE和Result.TYPE_SCROLL_SENSITIVE这两个方法都能够实现任意的前后滚动,使用各种移动的ResultSet指针的方法.二者的区别在于前者对于修改不敏感,而后者对于修改敏感.<br />resultSetConcurency是设置ResultSet对象能够修改的,取值如下:<br />ResultSet.CONCUR_READ_ONLY 设置为只读类型的参数.<br />ResultSet.CONCUR_UPDATABLE 设置为可修改类型的参数.<br />所以如果只是想要可以滚动的类型的Result只要把Statement如下赋值就行了.
Statement st = conn.createStatement(Result.TYPE_SCROLL_INSENITIVE,ResultSet.CONCUR_READ_ONLY); ResultSet rs = st.excuteQuery(sqlStr);
用这个Statement执行的查询语句得到的就是可滚动的ResultSet.<a name="O5Agk"></a>### 3. 可更新的ResultSet这样的ResultSet对象可以完成对数据库中表的修改,但是我知道ResultSet只是相当于数据库中表的视图,所以并不时所有的ResultSet只要设置了可更新就能够完成更新的,能够完成更新的ResultSet的SQL语句必须要具备如下的属性:- a,只引用了单个表.- b,不含有join或者group by子句.- c,那些列中要包含主关键字.具有上述条件的,可更新的ResultSet可以完成对数据的修改,可更新的结果集的创建方法是:
Statement st = createstatement(Result.TYPE_SCROLL_INSENSITIVE,Result.CONCUR_UPDATABLE)
这样的Statement的执行结果得到的就是可更新的结果集.更新的方法是,把ResultSet的游标移动到你要更新的行,然后调用updateXXX(),这个方法XXX的含义和getXXX()是相同的.updateXXX()方法,有两个参数,第一个是要更新的列,可以是列名或者序号.第二个是要更新的数据,这个数据类型要和XXX相同.每完成对一行的update要调用updateRow()完成对数据库的写入,而且是在ResultSet的游标没有离开该修改行之前,否则修改将不会被提交.使用updateXXX方法还可以完成插入操作.但是首先要介绍两个方法:- moveToInsertRow()是把ResultSet移动到插入行,这个插入行是表中特殊的一行,不需要指定具体那一行,只要调用这个方法系统会自动移动到那一行的.- moveToCurrentRow()这是把ResultSet移动到记忆中的某个行,通常当前行.如果没有使用insert操作,这个方法没有什么效果,如果使用了insert操作,这个方法用于返回到insert操作之前的那一行,离开插入行,当然也可以通过next(),previous()等方法离开插入行.要完成对数据库的插入,首先调用moveToInsertRow()移动到插入行,然后调用updateXXX的方法完成对,各列数据的更新,完成更新后和更新操作一样,要写到数据库,不过这里使用的是insertRow(),也要保证在该方法执行之前ResultSet没有离开插入列,否则插入不被执行,并且对插入行的更新将丢失.<a name="b8bTG"></a>### 4. 可保持的ResultSet正常情况下如果使用Statement执行完一个查询,又去执行另一个查询时这时候第一个查询的结果集就会被关闭,也就是说,所有的Statement的查询对应的结果集是一个,如果调用Connection的commit()方法也会关闭结果集。可保持性就是指当ResultSet的结果被提交时,是被关闭还是不被关闭。JDBC2.0和1.0提供的都是提交后ResultSet就会被关闭。不过在JDBC3.0中,我们可以设置ResultSet是否关闭。要完成这样的ResultSet的对象的创建,要使用的Statement的创建要具有三个参数,这个Statement的创建方式也就是,我所说的 Statement的第三种创建方式。<br /> 当使用ResultSet的时候,当查询出来的数据集记录很多,有一千万条的时候,那rs所指的对象是否会占用很多内存,如果记录过多,那程序会不会把系统的内存用光呢 ?<br /> 不会的,ResultSet表面看起来是一个记录集,其实这个对象中只是记录了结果集的相关信息,具体的记录并没有存放在对象中,具体的记录内容知道你通过next方法提取的时候,再通过相关的getXXXXX方法提取字段内容的时候才能从数据库中得到,这些并不会占用内存,具体消耗内存是由于你将记录集中的数据提取出来加入到你自己的集合中的时候才会发生,如果你没有使用集合记录所有的记录就不会发生消耗内存厉害的情况。<a name="LiFfv"></a>### 遍历resultSet遍历ResultSet跟打印读取流内容一样,它有一个next()方法,它会判断是否该对象里还有数据。示例:
while(result.next()) { // … get column values from this record }
<a name="rfgjs"></a>### 从ResultSet接受数据表中列数据上文有详细的讲解,这里只提一下
while(result.next()) { result.getString (“name”); result.getInt (“age”); // 等等 }
或者根据数据表中列的index值获取
while(result.next()) { result.getString (1); result.getInt (2); // 等等 }
但是请注意列中的数据类型和java数据类型要相对应,以免报错。<a name="rrz7z"></a># JDBC(五)PreparedStatement 详解PreparedStatement 是一个特殊的Statement对象,如果我们只是来查询或者更新数据的话,最好用PreparedStatement代替Statement,因为它有以下有点:- 简化Statement中的操作- 提高执行语句的性能- 可读性和可维护性更好- 安全性更好。<br />使用PreparedStatement能够预防SQL注入攻击,所谓SQL注入,指的是通过把SQL命令插入到Web表单提交或者输入域名或者页面请求的查询字符串,最终达到欺骗服务器,达到执行恶意SQL命令的目的。注入只对SQL语句的编译过程有破坏作用,而执行阶段只是把输入串作为数据处理,不再需要对SQL语句进行解析,因此也就避免了类似select * from user where name='aa' and password='bb' or 1=1的sql注入问题的发生。Statement 和 PreparedStatement之间的关系和区别.- 关系:PreparedStatement继承自Statement,都是接口- 区别:PreparedStatement可以使用占位符,是预编译的,批处理比Statement效率高<a name="Kq2WO"></a>### 创建一个PreparedStatementPreparedStatement对象的创建也同样离不开 DriverManger.getConnect()对象,因为它也是建立在连接到数据库之上的操作。
connection = DriverManager.getConnection(url,user,password); String sql = “update user set username=? where id = ?”; PreparedStatement preparedStatement = connection.prepareStatement(sql);
<a name="lM4gv"></a>### 往PreparedStatement里写入参数看上面那个sql 字符串,中间有几个?,它在这里有点占位符的意思,然后我们可以通过PreparedStatement的setString(),等方法来给占位符进行赋值,使得sql语句变得灵活。```javaClass.forName("com.mysql.jdbc.Driver");connection = DriverManager.getConnection(url,user,password);String sql = "update user set username=? where id = ?";PreparedStatement preparedStatement = connection.prepareStatement(sql);preparedStatement.setString(1,"Fant.J");preparedStatement.setInt(2,27);
参数中的第一个参数分别是1和2,它代表的是第几个问号的位置。如果sql语句中只有一个问号,那就不用声明这个参数。
执行PreparedStatement
执行查询
如果是执行查询数据库的话,也像Statement对象执行excuteQuery()一样返回一个ResultSet结果集。这里就不多详述:
String sql = "select * from user";PreparedStatement preparedStatement = connection.prepareStatement(sql);ResultSet resultSet = preparedStatement.executeQuery();while (resultSet.next()) {int id = resultSet.getInt("id");String username = resultSet.getString("username");String birthday = resultSet.getString("birthday");String sex = resultSet.getString("sex");String address = resultSet.getString("address");System.out.println(" " + username + " " + birthday + " " + sex+ " " + address);}
Fant.J 2017-04-20 男 xxxx
复用PreparedStatement
什么叫复用,就是一次实例化,多次使用。
preparedStatement.setString(1,"Fant.J");preparedStatement.setInt(2,27);int result = preparedStatement.executeUpdate();preparedStatement.setString(1,"Fant.J reUseTest");preparedStatement.setInt(2,27);preparedStatement.executeUpdate();
那如何在同一个PreparedStatement对象中进行查询操作呢
String sql2 = "select * from user";ResultSet resultSet = preparedStatement.executeQuery(sql2);while (resultSet.next()) {int id = resultSet.getInt("id");String username = resultSet.getString("username");String birthday = resultSet.getString("birthday");String sex = resultSet.getString("sex");String address = resultSet.getString("address");System.out.println(" " + username + " " + birthday + " " + sex+ " " + address);}
Fant.J reUseTest 2017-04-20 男 xxxx
完整代码
package com.jdbc;import java.sql.*;/*** Created by Fant.J.* 2018/3/3 13:35*/public class PreparedStatementTest {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/user";String user = "root";String password = "root";Connection connection =null;try {Class.forName("com.mysql.jdbc.Driver");connection = DriverManager.getConnection(url,user,password);String sql = "update user set username=? where id = ?";PreparedStatement preparedStatement = connection.prepareStatement(sql);preparedStatement.setString(1,"Fant.J");preparedStatement.setInt(2,27);int result = preparedStatement.executeUpdate();preparedStatement.setString(1,"Fant.J reUseTest");preparedStatement.setInt(2,27);preparedStatement.executeUpdate();String sql2 = "select * from user";ResultSet resultSet = preparedStatement.executeQuery(sql2);while (resultSet.next()) {int id = resultSet.getInt("id");String username = resultSet.getString("username");String birthday = resultSet.getString("birthday");String sex = resultSet.getString("sex");String address = resultSet.getString("address");System.out.println(" " + username + " " + birthday + " " + sex+ " " + address);}} catch (ClassNotFoundException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();}}}
PreparedStatement性能分析
数据库解析SQL字符串需要时间,并为其创建查询计划。查询计划是分析数据库如何以最有效的方式执行查询。
如果为每个查询或数据库更新提交新的完整SQL语句,则数据库必须解析SQL,并为查询创建查询计划。通过重用现有的PreparedStatement,可以为后续查询重用SQL解析和查询计划。这通过减少每个执行的解析和查询计划开销来加速查询执行。
PreparedStatement有两个潜在的重用(复用)级别。
- JDBC驱动程序重新使用PreparedStatement。
- 数据库重用PreparedStatement。
首先,JDBC驱动程序可以在内部缓存PreparedStatement对象,从而重用PreparedStatement对象。这可能会节省一小部分PreparedStatement创建时间。
其次,高速缓存的解析和查询计划可能会跨Java应用程序(例如群集中的应用程序服务器)重复使用,并使用相同的数据库。
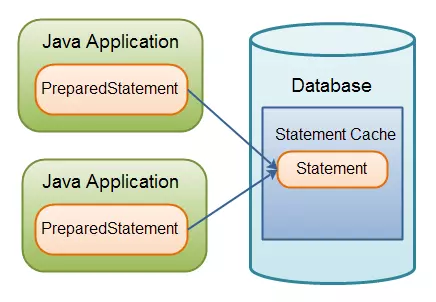
JDBC(六)批量处理sql
批量更新是分组在一起的一批更新,并以“批量”方式发送到数据库,而不是逐个发送更新。节省网络传输时间(多次传输肯定要比一次传输浪费时间)
一次发送一批更新到数据库,比一个一个发送更快,等待每个更新完成。 发送一批更新(仅一次往返)涉及的网络流量较少,数据库可能能够并行执行一些更新。 与逐个执行更新相比,加速可能相当大。
有两种方法可以执行批量更新:
- 使用Statement
- 使用PreparedStatement
Statement 批量更新
用Statement对象执行批量更新时,用到addBatch()和executeBatch()方法。例子:
使用addBatch()方法添加要在批处理中执行的SQL语句。然后使用executeBatch()执行SQL语句。Statement statement = null;try{statement = connection.createStatement();statement.addBatch("update people set firstname='aaa' where id=123");statement.addBatch("update people set firstname='bbb' where id=456");statement.addBatch("update people set firstname='ccc' where id=789");int[] recordsAffected = statement.executeBatch();} finally {if(statement != null) statement.close();}
PreparedStatement 批量更新
还可以使用PreparedStatement对象执行批量更新。 PreparedStatement可以重用相同的SQL语句,并只需插入新参数即可执行每个更新:
将每组参数值插入到preparedStatement中,并调用addBatch()方法。 这会将参数值添加到批处理内部。 现在可以添加另一组值,以便插入到SQL语句中。 将全部批次发送到数据库后,将每组参数插入到SQL中并分别执行。然后执行executeBatch()方法,它执行所有的批量更新。 SQL语句和参数集一起发送到数据库。String sql = "update user set username=? where id=?";PreparedStatement preparedStatement = null;try{preparedStatement =connection.prepareStatement(sql);preparedStatement.setString(1, "aaa");preparedStatement.setLong (2, 123);preparedStatement.addBatch();preparedStatement.setString(1, "bbb");preparedStatement.setLong (2, 456);preparedStatement.addBatch();int[] affectedRecords = preparedStatement.executeBatch();}finally {if(preparedStatement != null) {preparedStatement.close();}}
注意
批量操作应该放到事务里进行,因为它会存在某条语句执行失败的情况。JDBC(七)事务Transaction
事务Transaction是一组要作为单一的原子动作进行的行为。 要么执行所有的操作,要么都不执行。
我们可以通过它来调用事务
connection.setAutoCommit(false);
如果在事务中间出现失败,就需要对事务进行回滚
connection.rollback();
如果所有操作都没有失败,那最终需要提交。
connection.commit();
当然,我们需要借助try-catch 来帮我们捕获异常:
Connection connection = ...try{connection.setAutoCommit(false);// create and execute statements etc.connection.commit();} catch(Exception e) {connection.rollback();} finally {if(connection != null) {connection.close();}}
完整示例
Connection connection = ...try{connection.setAutoCommit(false);Statement statement1 = null;try{statement1 = connection.createStatement();statement1.executeUpdate("update user set username='aaa' where id=123");} finally {if(statement1 != null) {statement1.close();}}Statement statement2 = null;try{statement2 = connection.createStatement();statement2.executeUpdate("update user set username='bbb' where id=456");} finally {if(statement2 != null) {statement2.close();}}connection.commit();} catch(Exception e) {connection.rollback();} finally {if(connection != null) {connection.close();}}
JDBC(八)CallableStatement 存储过程调用
CallableStatement 和 PreparedStatement用法特别相似,只是CallableStatement 可以用来调用存储过程。
存储过程简介调用简介
SQL语句需要先编译然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。 存储过程是可编程的函数,在数据库中创建并保存,可以由SQL语句和控制结构组成。当想要在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟,它允许控制数据的访问方式。
存储过程的优点:
- (1). 增强SQL语言的功能和灵活性:存储过程可以用控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
- (2). 标准组件式编程:存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
- (3). 较快的执行速度:如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
- (4). 减少网络流量:针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织进存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大减少网络流量并降低了网络负载。
- (5). 作为一种安全机制来充分利用:通过对执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
存储过程的缺点:
- 可移植性极差,甚至同一种数据库的不同版本都不可移植,故不建议使用
- 调试费劲,开发费劲,排错费劲
- 目前来看,Web开发中,存储过程都是被禁止使用或者尽量减少使用的。
MySQL的存储过程
存储过程是数据库的一个重要的功能,MySQL 5.0以前并不支持存储过程,这使得MySQL在应用上大打折扣。好在MySQL 5.0开始支持存储过程,这样即可以大大提高数据库的处理速度,同时也可以提高数据库编程的灵活性。
1. 创建MySQL存储过程
DELIMITER //create procedure findById(IN pid INTEGER)BEGINSELECT * FROM `user` WHERE id= pid;END //DELIMITER;
2. 调用存储过程
package com.jdbc;import java.sql.*;/*** Created by Fant.J.* 2018/3/5 20:14*/public class CallableStatementTest {static String url = "jdbc:mysql://localhost:3306/user";static String user = "root";static String password = "root";public static void main(String[] args) {Connection connection = null;try {Class.forName("com.mysql.jdbc.Driver");connection = DriverManager.getConnection(url, user, password);String sql = "CALL findById(?)";CallableStatement stmt = connection.prepareCall(sql);stmt.setInt(1,27);ResultSet resultSet = stmt.executeQuery();while (resultSet.next()){int id = resultSet.getInt("id");String username = resultSet.getString("username");String birthday = resultSet.getString("birthday");String sex = resultSet.getString("sex");String address = resultSet.getString("address");System.out.println(" " + username + " " + birthday + " " + sex+ " " + address);}} catch (ClassNotFoundException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();}}}
Fant.J reUseTest 2017-04-20 男 xxxx
3. 全面科普
通过前面的讲解和例子,我想你肯定已经了解调用存储过程到底是个什么东西,但是你肯定也能看到,这例子只是一个特例,所以我在这里把 调用存储代码中的sql做个详解。
存储过程参数详解
- in:往过程里传参。 (参考我创建存储过程中的代码(IN pid INTEGER))
- out:往过程外传参。
- inout:in and out
相对于oracle数据库来说,MySQL的存储过程相对功能较弱,使用较少。
创建的存储过程保存在数据库的数据字典中。
JDBC(九)DatabaseMetaData 数据库元数据
通过java.sql.DatabaseMetaData 接口,我们能获取到数据库的列表、列等信息。
DatabaseMetaData 接口包含了许多方法,这里值介绍常用的。
获取 DatabaseMetaData 实例对象
DatabaseMetaData databaseMetaData = connection.getMetaData();
获取数据库名和版本
int majorVersion = databaseMetaData.getDatabaseMajorVersion();int minorVersion = databaseMetaData.getDatabaseMinorVersion();String productName = databaseMetaData.getDatabaseProductName();String productVersion = databaseMetaData.getDatabaseProductVersion();
数据库属性信息:5 6 MySQL 5.6.24
获取数据库驱动版本
int driverMajorVersion = databaseMetaData.getDriverMajorVersion();int driverMinorVersion = databaseMetaData.getDriverMinorVersion();
获取数据库列表
String catalog = null;String schemaPattern = null;String tableNamePattern = null;String[] types = null;ResultSet result = databaseMetaData.getTables(catalog, schemaPattern, tableNamePattern, types );while(result.next()) {String tableName = result.getString(3);}
getTables()方法源码:
ResultSet getTables(String catalog, String schemaPattern,String tableNamePattern, String types[]) throws SQLException;
我在这里给四个参数都赋值null,则它会把所有数据库中的表信息 返回。
此ResultSet包含10列,每列包含有关给定表的信息。 索引3指的是表名称。
user
在表中列出列
String catalog = null;String schemaPattern = null;String tableNamePattern = "user";String columnNamePattern = null;ResultSet result = databaseMetaData.getColumns(catalog, schemaPattern, tableNamePattern, columnNamePattern);while(result.next()){String columnName = result.getString(4);int columnType = result.getInt(5);}
getColumns()方法返回的ResultSet包含给定表的列的列表。 索引为4的列包含列名称,索引为5的列包含列类型。 列类型是一个与java.sql.Types中的类型常量匹配的整数。
id 4username 12birthday 91sex 1address 12
表的主键
String catalog = null;String schema = null;String tableName = "user";ResultSet result = databaseMetaData.getPrimaryKeys(catalog, schema, tableName);while(result.next()){String columnName = result.getString(4);}
调用getPrimaryKeys()方法,向其传递3个参数。 在这个例子中,只有tableName是非空的。
getPrimaryKeys()方法返回的ResultSet包含组成给定表主键的列表。 索引4指的是的列名称。
主键可以由多个列组成。 这样的密钥被称为复合密钥。 如果表包含复合键,则ResultSet将包含多行。 复合键中的每一列都有一行。
id
全部代码
package com.jdbc;import java.sql.*;/*** Created by Fant.J.* 2018/3/5 21:38*/public class DatabaseMetaDataTest {public static void main(String[] args) {String url = "jdbc:mysql://localhost:3306/user";String user = "root";String password = "root";Connection connection =null;try {Class.forName("com.mysql.jdbc.Driver");connection = DriverManager.getConnection(url,user,password);DatabaseMetaData databaseMetaData = connection.getMetaData();int majorVersion = databaseMetaData.getDatabaseMajorVersion();int minorVersion = databaseMetaData.getDatabaseMinorVersion();String productName = databaseMetaData.getDatabaseProductName();String productVersion = databaseMetaData.getDatabaseProductVersion();System.out.println("数据库属性信息:"+majorVersion+" "+minorVersion+" "+productName+" "+productVersion);int driverMajorVersion = databaseMetaData.getDriverMajorVersion();int driverMinorVersion = databaseMetaData.getDriverMinorVersion();System.out.println("驱动信息:"+driverMajorVersion+" "+driverMinorVersion);/* String catalog = null;String schemaPattern = null;String tableNamePattern = null;String[] types = null;ResultSet result = databaseMetaData.getTables(catalog, schemaPattern, tableNamePattern, types );while(result.next()) {String tableName = result.getString(3);System.out.println(tableName);}*//* String catalog = null;String schemaPattern = null;String tableNamePattern = "user";String columnNamePattern = null;ResultSet result = databaseMetaData.getColumns(catalog, schemaPattern, tableNamePattern, columnNamePattern);while(result.next()){String columnName = result.getString(4);int columnType = result.getInt(5);System.out.println(columnName+" "+columnType+" ");}*/String catalog = null;String schema = null;String tableName = "user";ResultSet result = databaseMetaData.getPrimaryKeys(catalog, schema, tableName);while(result.next()){String columnName = result.getString(4);System.out.println(columnName);}} catch (ClassNotFoundException e) {e.printStackTrace();} catch (SQLException e) {e.printStackTrace();}}}

若有收获,就点个赞吧
0 人点赞
