Stream API就是流操作api,Java中 流 都是指数据,尤其是大量数据,所以Stream API是为了方便处理大量数据的,也就是给大数据运算做基础的。
注意区别于io流,io的流操作的数据是字节码或字符,主要是处理输入输出。
Stream api的流操作的数据是数组或集合,主要是数据的计算,把一个集合转变为另一个集合的过程中,进行一系列流水线式的操作,主要是数据的查找、过滤和映射等操作。
集合是数据,流(Stream)是指计算 数据集合或数据数组的计算,称为Stream,也就是我们常说的流式计算
相通于Hadoop框架的流式计算,map-reduce思想是一致的
注意:
- stream api是基于lambda表达式的,也就是基于函数式编程的
- stream不会自己存储数据,只是处理数据
- stream不会改吧源数据对象,处理结束后会返回一个新生成的stream
- stream操作是有延时的,意味着它们会等到·需要结果的时候才执行
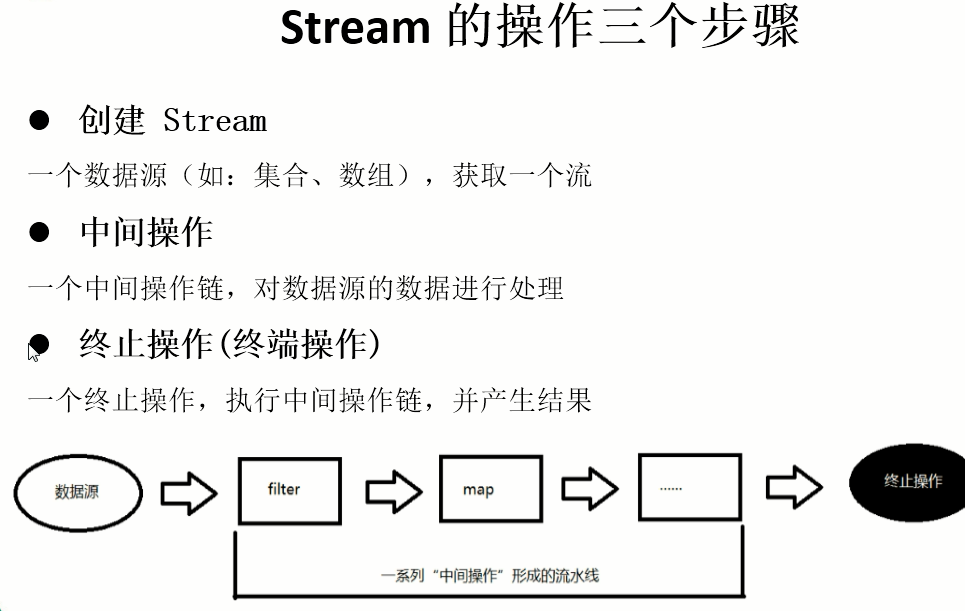
一、创建Stream
//1. 通过Collection系列集合提供的 stream()或ParallelStream() 获取及河流List<String> list = new ArrayList<>();Stream<String> stream = list.stream();//非并行的流Stream<String> parallelStream = list.parallelStream();//并行的流//2. 通过Arrays的静态方法 stream()获取数组流Stream<Integer> stream1 = Arrays.stream(new Integer[10]);//3. 通过Stream类的静态方法of()Stream<Serializable> stream2 = Stream.of(1, 2, "initit.com");//4. 创建无限流//4.1 迭代方式Stream<Integer> stream3 = Stream.iterate(1001, x -> x + 2);/*说明:方法:iterate(final T seed, final UnaryOperator<T> f)其中 UnaryOperator 接口如下:@FunctionalInterfacepublic interface UnaryOperator<T> extends Function<T, T> {static <T> UnaryOperator<T> identity() {return t -> t;}}*///终止 测试stream3.limit(5).forEach(System.out::println);// 4.2 生成方式Stream<Double> stream4 = Stream.generate(Math::random);stream4.limit(100).forEach(System.out::println);//说明: generate(Supplier<T> s)//@FunctionalInterface//public interface Supplier<T> {// T get();//}
二、中间操作
- filter 过滤数据
- limit 截断数据,不输出后边的数据
- skip 跳过数据,不输出前边的数据
- distinct 去重
- map 映射
- flatMap 平铺的映射,map和flatMap的区别等同于add和addAll的区别,flatMap是把多个流连成一个流,addAll是把多个集合连成一个集合
- sorted 排序,默认排序
- sorted(comparator)重写comparator方法,定制排序
//模拟一个User对象class User {private Integer id; //主键private String name; //姓名private Integer age;//年龄private Double salary;//薪水public User(String name, Integer age, Double salary) {this.name = name;this.age = age;this.salary = salary;}//构造函数 方便测试public User(String name, int age, double salary) {this.name = name;this.age = age;this.salary = salary;}//后边要比对对象是否相同 需要重写equals和hasCode方法@Overridepublic boolean equals(Object o) {if (this == o) return true;if (!(o instanceof User)) return false;User user = (User) o;return Objects.equals(getId(), user.getId()) &&Objects.equals(getName(), user.getName()) &&Objects.equals(getAge(), user.getAge()) &&Objects.equals(getSalary(), user.getSalary());}@Overridepublic int hashCode() {return Objects.hash(getId(), getName(), getAge(), getSalary());}//toString 方便控制台输出查看@Overridepublic String toString() {return "User{" +"id=" + id +", name='" + name + '\'' +", age=" + age +", salary=" + salary +'}';}//省略get set方法}//准备数据List<User> list = new ArrayList<User>() {{add(new User("张三", 18, 6000));add(new User("张三", 18, 6000));add(new User("张三", 18, 6000));add(new User("李四", 20, 6000));add(new User("张三", 50, 8000));add(new User("编程指南", 30, 120000));//为测试速度 添加一千万数据// for (int i = 0; i < 1000 * 10000; i++) {// add(new User(UUID.randomUUID() + "", 30, 120000));// }}};Stream<User> stream = list.stream();@Testpublic void filter() {//过滤 filterstream.filter(user -> user.getAge() > 18).forEach(System.out::println);// Stream<T> filter(Predicate<? super T> predicate);//Predicate的方法 boolean test(T t);//输出如下://User{id=0, name='李四', age=20, salary=6000.0}//User{id=0, name='张三', age=50, salary=8000.0}//User{id=0, name='编程指南', age=30, salary=120000.0}}//迭代 forEach@Testpublic void foreach() {stream.forEach(System.out::println);//输出//User{id=0, name='张三', age=18, salary=6000.0}//User{id=0, name='张三', age=18, salary=6000.0}//User{id=0, name='张三', age=18, salary=6000.0}//User{id=0, name='李四', age=20, salary=6000.0}//User{id=0, name='张三', age=50, salary=8000.0}//User{id=0, name='编程指南', age=30, salary=120000.0}//stream 会帮我们自动实现内部迭代 forEach//区别于外部迭代list.forEach(System.out::println);//其本质就是以下代码Iterator<User> iterator = list.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}//也就是for (User user : list) {System.out.println(user);}}//过滤 filter@Testpublic void test() {Stream<User> userStream = stream.filter(user -> {System.out.println("判断年龄……");return user.getAge() > 18;});//此时运行无任何输出//调用终止操作userStream.forEach(System.out::println);//输出如下://判断年龄……//判断年龄……//判断年龄……//判断年龄……//User{id=0, name='李四', age=20, salary=6000.0}//判断年龄……//User{id=0, name='张三', age=50, salary=8000.0}//判断年龄……//User{id=0, name='编程指南', age=30, salary=120000.0}//说明: 中间操作不会自动执行,只有调用终止操作时,才会一次性执行 这个叫 惰性求值}//截断 limit@Testpublic void limit() {stream.limit(3).forEach(System.out::println);//输出如下://User{id=0, name='张三', age=18, salary=6000.0}//User{id=0, name='张三', age=18, salary=6000.0}//User{id=0, name='张三', age=18, salary=6000.0}}//跳过 skip@Testpublic void skip() {stream.skip(3).forEach(System.out::println);//输出如下://User{id=0, name='李四', age=20, salary=6000.0}//User{id=0, name='张三', age=50, salary=8000.0}//User{id=0, name='编程指南', age=30, salary=120000.0}}//去重 distinct@Testpublic void distinct() {//distinct 需要重写 equals 和 hasCode方法stream.distinct().forEach(System.out::println);//输出如下://User{id=0, name='张三', age=18, salary=6000.0}//User{id=0, name='李四', age=20, salary=6000.0}//User{id=0, name='张三', age=50, salary=8000.0}//User{id=0, name='编程指南', age=30, salary=120000.0}}//映射 map@Testpublic void map() {//假如要提取用户名stream.map(User::getName).forEach(System.out::println);//map方法接收一个Function函数:接收一个值,处理后返回一个新值//就是把每个对象映射成一个新对象// <R> Stream<R> map(Function<? super T, ? extends R> mapper);//@FunctionalInterface//public interface Function<T, R> {// R apply(T t);//}//输出如下://张三//张三//张三//李四//张三//编程指南}//再来个映射测试 问每个人的薪水是多少@Testpublic void map1() {stream.map(user -> user.getName() + "的薪水是: " + user.getSalary()).forEach(System.out::println);//map方法接收一个Function函数:接收一个值,处理后返回一个新值//就是把每个对象映射成一个新对象// <R> Stream<R> map(Function<? super T, ? extends R> mapper);//@FunctionalInterface//public interface Function<T, R> {// R apply(T t);//}//输出如下://张三的薪水是: 6000.0//张三的薪水是: 6000.0//张三的薪水是: 6000.0//李四的薪水是: 6000.0//张三的薪水是: 8000.0//编程指南的薪水是: 120000.0}//扁平化的映射 flatMap//就是把每一个值映射成一个流,然后把所有的流连在一起变成一个流@Testpublic void flatMap() {stream.flatMap(user -> getStream(user.getName())).forEach(System.out::println);//<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);//输出://张//三//张//三//张//三//李//四//张//三//编//程//指//南// map 和flatMap 的区别// 等同于 add和addAll的区别// 例如 map ={aaaa,bbbb,cccc}// 那么flatMap = {a,a,a,a,b,b,b,b,c,c,c,c}//就是把多个流合并为一个流了, 联想list.addAll() 把多个list合并成一个list}private Stream<String> getStream(String str) {return Arrays.stream(str.split(""));}//排序:自然排序 sorted() 就是按照字典排序@Testpublic void sorted() {Stream.of(1, 4, 5, 5, 6, 2, 3).sorted().forEach(System.out::print);//输出: 1234556}//排序:定制排序 sorted(Comparator<? super T> comparator) 就是定制 Comparator接口@Testpublic void sorted1() {Stream.of(1, 4, 5, 5, 6, 2, 3)//倒序排列.sorted((x, y) -> y > x ? 1 : -1).forEach(System.out::print);//输出: 1234556}//排序例子: 先按薪资排,然后按年龄排@Testpublic void sorted2() {long now = System.currentTimeMillis();list.stream().sorted((o1, o2) -> {if (o1.getAge().equals(o2.getAge())) {return o1.getSalary().compareTo(o2.getSalary());} else {return o1.getAge().compareTo(o2.getAge());}}).close();System.out.println(System.currentTimeMillis() - now);//速度测试: 百万数据// parallelStream()是 37毫秒 51 36//stream() 是31毫秒 41 35//速度测试: 千万数据// parallelStream()是 32毫秒//stream() 是33毫秒}//对比一下速度@Testpublic void sorted3() {long now2 = System.currentTimeMillis();list.sort((o1, o2) -> {if (o1.getAge().equals(o2.getAge())) {return o1.getSalary().compareTo(o2.getSalary());} else {return o1.getAge().compareTo(o2.getAge());}});// for (User user : list) {// System.out.println(user);// }System.out.println(System.currentTimeMillis() - now2);//速度测试: 百万数据 67毫秒 73 61//千万数据: 192毫秒}
三、结束操作
//是否都匹配 allMatchboolean allMatch = list.stream().allMatch(user -> user.getAge().equals(18));System.out.println(allMatch);//输出false 不是所有用户都18岁//至少有一个匹配 anyMatchboolean anyMatch = list.stream().anyMatch(user -> user.getAge() == 18);System.out.println(anyMatch);//输出true 有18岁的用户//都不匹配 noneMatchboolean noneMatch = list.stream().noneMatch(user -> user.getAge() == 18);System.out.println(noneMatch);//输出false 不是所有用户都不是18岁//查找第一个 findFirstOptional<User> first = list.stream().sorted(Comparator.comparingDouble(User::getSalary)).findFirst();System.out.println(first);//Optional 可选的,用来封装对象的容器 目的是减少空指针 我们后边会细说//查找任意一个Optional<User> any = list.parallelStream().filter(user -> user.getAge() > 18).findAny();System.out.println(any.get());//查找最大值Optional<User> max = list.stream().max(Comparator.comparingDouble(User::getAge));System.out.println(max);// 查年龄最大的用户 Optional[User{id=null, name='张三', age=50, salary=8000.0}]//查最小的//查最少的工资是多少Optional<Double> min = list.stream().map(User::getSalary).min(Double::compareTo);System.out.println(min);//输出6000//归约Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6,7,8,9,10);Integer reduce = stream.reduce(0, Integer::sum);System.out.println(reduce); //55// Optional<T> reduce(BinaryOperator<T> accumulator);//归约 计算工资的总和Optional<Double> reduce1 = list.stream().map(User::getSalary).reduce(Double::sum);System.out.println(reduce1.get());//152000.0//收集list.stream().map(User::getName).collect(Collectors.toList()).forEach(System.out::println);// <R> R collect(Supplier<R> supplier,// BiConsumer<R, ? super T> accumulator,// BiConsumer<R, R> combiner);//输出://张三//张三//张三//李四//张三//编程指南System.out.println("----------------");list.stream().map(User::getName).collect(Collectors.toSet()).forEach(System.out::println);//输出://李四//张三//编程指南System.out.println("==============");LinkedHashSet<String> linkedHashSet = list.stream().map(User::getName).collect(Collectors.toCollection(LinkedHashSet::new));System.out.println(linkedHashSet);//输出: [张三, 李四, 编程指南]//计算平均值Long count = list.stream().collect(Collectors.counting());//等同于// Long collect = list.stream().count();System.out.println(count);//计算工资的平均值Double avg = list.stream().collect(Collectors.averagingDouble(User::getSalary));System.out.println(avg);//激素那年龄总和Double sum = list.stream().collect(Collectors.summingDouble(User::getAge));//等同于// Double sum = list.stream().mapToDouble(User::getAge).sum();System.out.println(sum);//以上输出://6//25333.333333333332//154.0System.out.println("-------分组----------");//分组//安年龄分组Map<Integer, List<User>> map = list.stream().collect(Collectors.groupingBy(User::getAge));System.out.println(map);//{50=[User{id=null, name='张三', age=50, salary=8000.0}],// 18=[User{id=null, name='张三', age=18, salary=6000.0},// User{id=null, name='张三', age=18, salary=6000.0},// User{id=null, name='张三', age=18, salary=6000.0}],// 20=[User{id=null, name='李四', age=20, salary=6000.0}],// 30=[User{id=null, name='编程指南', age=30, salary=120000.0}]}//多级分组System.out.println("-------------多级分组-----------");Map<String, Map<String, List<User>>> map2 = list.stream().collect(Collectors.groupingBy(User::getName,Collectors.groupingBy(user -> {if (user.getAge() <= 18) {return "青少年";} else if (user.getAge() <= 60) {return "中年";} else {return "老年";}})));System.out.println(map2);//输出:{李四={中年=[User{id=null, name='李四', age=20, salary=6000.0}]},// 张三={青少年=[User{id=null, name='张三', age=18, salary=6000.0},// User{id=null, name='张三', age=18, salary=6000.0},// User{id=null, name='张三', age=18, salary=6000.0}],// 中年=[User{id=null, name='张三', age=50, salary=8000.0}]},// 编程指南={中年=[User{id=null, name='编程指南', age=30, salary=120000.0}]}}//收集统计System.out.println("-----收集统计-----");LongSummaryStatistics statistics = list.stream().collect(Collectors.summarizingLong(User::getAge));double average = statistics.getAverage();long count1 = statistics.getCount();long max1 = statistics.getMax();long min1 = statistics.getMin();long sum1 = statistics.getSum();//收集 连接String join = list.stream().map(User::getName).collect(Collectors.joining());System.out.println(join);//张三张三张三李四张三编程指南String join1 = list.stream().map(User::getName).collect(Collectors.joining(" , "));System.out.println(join1);//张三 , 张三 , 张三 , 李四 , 张三 , 编程指南
并行流和顺序流
- 并行流 就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
- Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。
- Stream API 可以声明性地通过 parallel() 与sequential() 在并行流与顺序流之间进行切换。
- 并行流底层使用的是JDK7的Fork/Join框架实现的,相当于提供了一个种简便的使用方式。
了解 Fork/Join 框架
Fork/Join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行 join 汇总.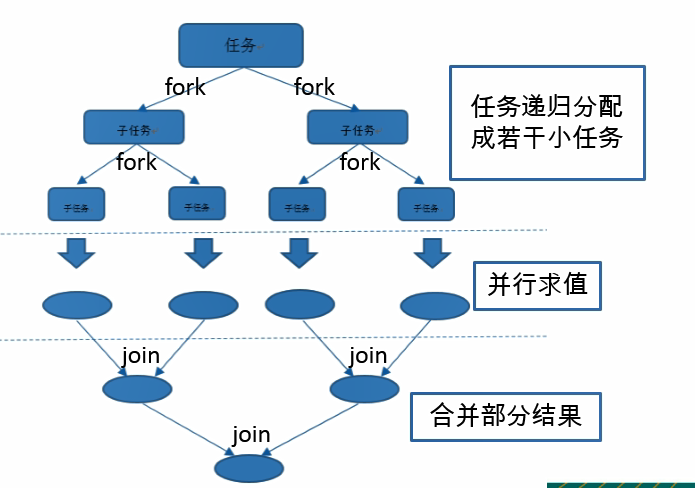
Fork/Join框架相对于多线程执行的优势是,可以更高效的利用cpu,采用 “工作窃取”模式(work-stealing):
当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能 。
举个例子: 计算0到一千亿数字求和
**
一、传统循环累积求和法
//for循环累加@Testpublic void test2() {long start = System.currentTimeMillis();long sum = 0L;for (long i = 0L; i <= 10000000000L; i++) {sum += i;}System.out.println(sum);long end = System.currentTimeMillis();System.out.println("耗费的时间为: " + (end - start));//耗费的时间为: 2660}
二、ForkJoin框架计算
package com.initit.java8.streamapi;import java.util.concurrent.RecursiveTask;/*** ForkJoin框架使用案例* 计算求和*/public class ForkJoinCalculate extends RecursiveTask<Long> {private long start;private long end;private static final long THRESHOLD = 10000L; //临界值public ForkJoinCalculate(long start, long end) {this.start = start;this.end = end;}/*** 小于临界值10000的时候,累加求和* 大于临界值10000的时候,对半拆分任务,交给多个线程执行*/@Overrideprotected Long compute() {long length = end - start;if (length <= THRESHOLD) {long sum = 0;for (long i = start; i <= end; i++) {sum += i;}return sum;} else {long middle = (start + end) / 2;ForkJoinCalculate left = new ForkJoinCalculate(start, middle);left.fork(); //拆分,并将该子任务压入线程队列ForkJoinCalculate right = new ForkJoinCalculate(middle + 1, end);right.fork();return left.join() + right.join();}}}//测试@Testpublic void test1() {long start = System.currentTimeMillis();ForkJoinPool pool = new ForkJoinPool();ForkJoinTask<Long> task = new ForkJoinCalculate(0L, 10000000000L);long sum = pool.invoke(task);System.out.println(sum);long end = System.currentTimeMillis();System.out.println("耗费的时间为: " + (end - start));//耗费的时间为: 1145}
三、使用Stream API 并行流计算求和
@Testpublic void test3() {long start = System.currentTimeMillis();Long sum = LongStream.rangeClosed(0L, 10000000000L).parallel() //切换为并行流// .sequential() //切换为顺序流 串行.sum();System.out.println(sum);long end = System.currentTimeMillis();System.out.println("耗费的时间为: " + (end - start));//耗费的时间为: 755}
- .parallel() //切换为并行流
- .sequential() //切换为顺序流 串行
map-reduce思想
最后简单提一下map-reduce思想。
- map 映射,数学概念 把A映射成B,A和B有某种对应关系
- reduce 归约,数学概念,把一系列数据按照某种关系累积
起源于google,用来处理大量的网页数据(大数据计算),后hadoop框架借鉴改思想。
map-reduce是一种并行处理数据的架构模式,就是利用大量的计算机来并行计算数据。
打个比喻:
- We want to count all the books in the library. You count up shelf #1, I count up shelf #2. That’s map. The more people we get, the faster it goes.
- Now we get together and add our individual counts. That’s reduce.
- 我们要数图书馆中的所有书。你数1号书架,我数2号书架。这就是“Map”。我们人越多,数书就更快。
- 现在我们到一起,把所有人的统计数加在一起。这就是“Reduce”。
知乎有位大神说:
- 举个栗子,要斗地主了,需要从10副混一起的牌里找出一幅牌,10副牌分10堆给10个人去清,每个人分别把黑红梅方放一堆,这就是map
- 然后安排4个人每人去清一种花色的牌,从中找出1到K,这就是reduce了
hadoop入门有一个统计单词出现次数的例子word count,我们简单分析一下,了解这种思想:
MapReduce大体上分为六个步骤:input, split, map, shuffle, reduce, output。细节描述如下:1. 输入(input):如给定一个文档,包含如下四行:• Hello Java• Hello C• Hello Java• Hello C++2. 拆分(split):将上述文档中每一行的内容转换为key-value对,即:• 0 - Hello Java• 1 - Hello C• 2 – Hello Java• 3 - Hello C++3. 映射(map):将拆分之后的内容转换成新的key-value对,即:• (Hello , 1)• (Java , 1)• (Hello , 1)• (C , 1)• (Hello , 1)• (Java , 1)• (Hello , 1)• (C++ , 1)4. 派发(shuffle):将key相同的扔到一起去,即:• (Hello , 1)• (Hello , 1)• (Hello , 1)• (Hello , 1)• (Java , 1)• (Java , 1)• (C , 1)• (C++ , 1)注意:这一步需要移动数据,原来的数据可能在不同的datanode上,这一步过后,相同key的数据会被移动到同一台机器上。最终,它会返回一个list包含各种k-value对,即:• { Hello: 1,1,1,1}• {Java: 1,1}• {C: 1}• {C++: 1}5. 缩减(reduce):把同一个key的结果加在一起。如:• (Hello , 4)• (Java , 2)• (C , 1)• (C++,1)6. 输出(output): 输出缩减之后的所有结果。
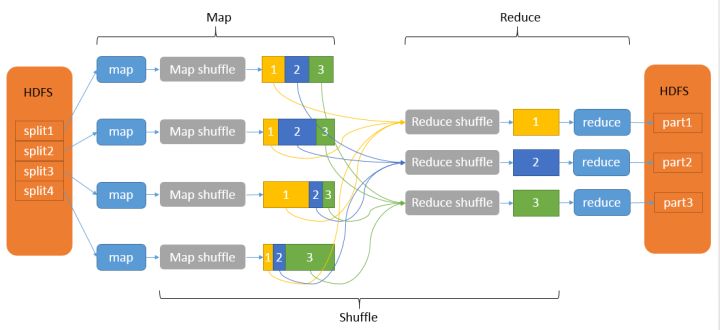
就是一种拆分和合并的思想,目的是使用多个计算资源(多台计算、多进程、多线程等等)并行计算,以提升计算效率,节省计算时间。是一种很好的架构模式,大数据计算框架Hadoop等都是采用map-reduce思想。

若有收获,就点个赞吧
0 人点赞
