1、java语言特点
java从c语言和c++语言中继承了很多成分,比如java语言的变量声明,操作符的形式,参数传递,流程控制等方面和c语言、c++语言完全相同,但同时java是一个纯粹面向对象的程序设计语言,舍弃了c语言中更容易引起错误的指针(以引用取代)、运算符重载、多重继承(以接口取代)等特性,增加了垃圾回收器功能用于回收不再被引用的对象所占据的内存空间。
1.1 面向对象
从我们开始接触Java这门语言后,就一直反复的在说java是一种面向对象的程序设计语言。很早以前的编程都是面向过程的,那么面向过程和面向对象有什么区别,举个简单的例子:<br />有一天你想吃鱼香肉丝了,你现在有两个选择:(1)自己买材料,肉,鱼香肉丝调料,蒜苔,胡萝卜等等然后切菜切肉,开炒,盛到盘子里。(2)去饭店,张开嘴:老板!来一份鱼香肉丝!<br />(1)是面向过程,(2)是面向对象。区别很明显,面向对象的优势就是你不需要知道鱼香肉丝是怎么做的,降低了耦合性。假如有一天你不想吃鱼香肉丝了,想吃别的,对于(1)来说太麻烦了,你还要重新买菜、调料什么的,对于(2)来说太容易了,你只需要和老板说一声,将鱼香肉丝替换成别的就可以了,提高了可维护性。<br />面向过程是具体化的,流程化的,解决一个问题,你需要一步一步的分析,一步一步的实现。面向对象是模型化的,你只需抽象出一个类,这是一个封闭的盒子,在这里你拥有数据也拥有解决问题的方法。需要什么功能直接使用就可以了,不必去一步一步的实现,至于这个功能是如何实现的,管我们什么事?我们会用就可以了。
1.1.1 两个基本概念:类、对象
随着时代的进步,现在人们面对的问题越来越复杂,比如对一个班级学生的数据进行分析,这样出现了对象的概念,一切事物皆对象。将现实事物抽象出来,把现实生活的事物以及关系,抽象成类,通过继承,实现,组合的方式把万事万物都给容纳了,实现了对现实世界的抽象和数学建模。
再通俗带点讲,对象是类的一个实例,有状态和行为;类是一个模板,它描述一类对象的行为和状态。比如下图中男孩(boy)、女孩(girl)为类(class),而具体的每个人为该类的对象(object):

1.1.2 面向对象三大特性:继承、封装和多态
继承:
如同生活中的子女继承父母拥有的所有财产,程序中的继承性是指子类拥有父类的全部特征和行为,这是类之间的一种关系。Java 只支持单继承。
例如定义一个语文老师类和数学老师类,如果不采用继承方式,那么两个类中需要定义的属性和方法如下图:
语文老师类和数学老师类中的许多属性和方法相同,这些相同的属性和方法可以提取出来放在一个父类中,这个父类用于被语文老师类和数学老师类继承。当然父类还可以继承别的类,如下图: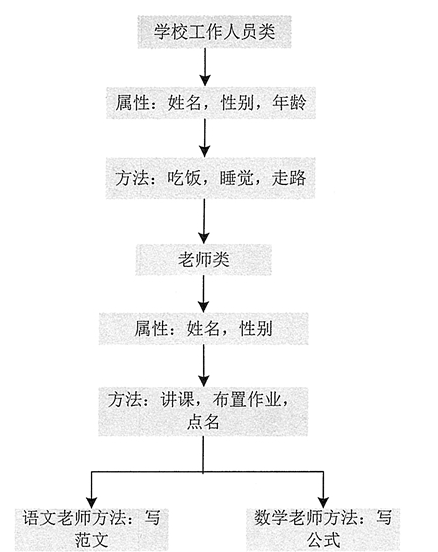
使用这种层次形的分类方式,是为了将多个类的通用属性和方法提取出来,放在它们的父类中,然后只需要在子类中各自定义自己独有的属性和方法,并以继承的形式在父类中获取它们的通用属性和方法即可。
封装:
封装是将代码及其处理的数据绑定在一起的一种编程机制,该机制保证了程序和数据都不受外部干扰且不被误用。Java 语言的基本封装单位是类。由于类的用途是封装复杂性,所以类的内部有隐藏实现复杂性的机制。Java 提供了私有和公有的访问模式,类的公有接口代表外部的用户应该知道或可以知道的每件东西,私有的方法数据只能通过该类的成员代码来访问,这就可以确保不会发生不希望的事情。
多态:
面向对象的多态性,即“一个接口,多个方法”。多态性体现在父类中定义的属性和方法被子类继承后,可以具有不同的属性或表现方式。多态性允许一个接口被多个同类使用,弥补了单继承的不足。多态可以用一个简单的图来解释,如下图: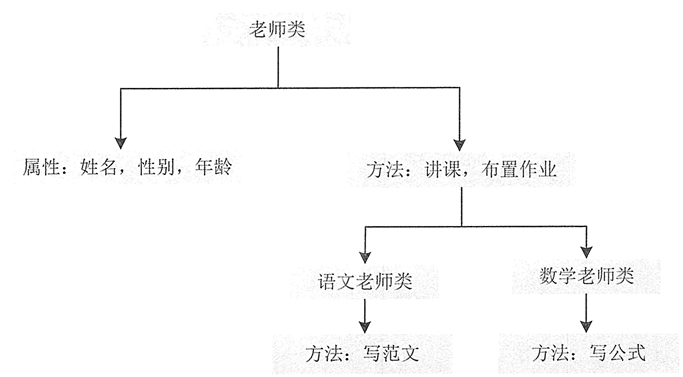
从上图可以看出,老师类中的许多属性和方法可以被语文老师类和数学老师类同时使用,这样也不易出错。
1.2 核心机制-垃圾回收
在c/c++语言中是要由程序员负责回收无用内存的,而java消除了程序员回收无用内存空间的责任:它提供了一种系统级线程跟踪存储空间的分配情况,并在JVM空闲时,检查并释放那些可被释放的内存空间。<br /> 垃圾回收在java程序运行过程中自动进行,程序员无法精确控制和干预。
2、java环境搭建
2.1 JDK、JRE、JVM的关系
JDK是提供给java开发人员使用的,其中包含了Java的开发工具,也包括了JRE。其中的开发工具:编译工具(javac.exe),打包工具(jar.exe)等。<br />JRE包括java虚拟机(JVM)和java程序所需要的核心类库等,如果想要运行一个开发好的java程序,计算机中只需要安装JRE即可。<br />简单来说就是,使用JDK的开发工具完成的java程序,交给JRE去运行。<br />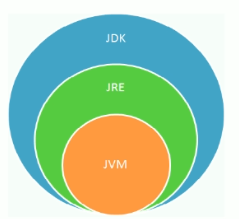
JDK=JRE+开发工具集(例如Javac编译工具等)
JRE=JVM+Java核心类库
2.2 JDK安装配置
官网下载java:
https://www.oracle.com/technetwork/java/javase/downloads/index.html
java安装可以说是傻瓜式安装,根据提示一步步的往下走就好了,接下来我们说下环境变量的配置。
第一步:右键单击“此电脑->属性->高级系统设置->环境变量”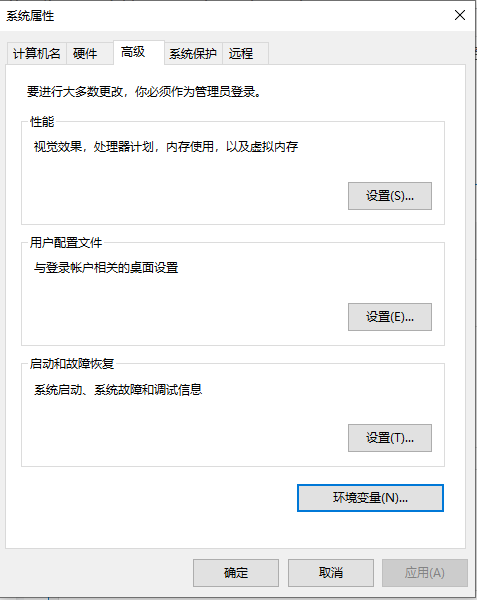
第二步:在“系统变量”栏下单击“新建”
新建->变量名:JAVA_HOME 变量值:D:\java\jdk (即JDK的安装路径)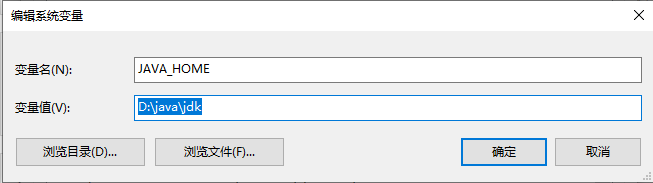
在“系统变量”栏里找到Path,选中后单击编辑,填入%JAVA_HOME%\bin,填入%JAVA_HOME%\jre\bin
第三步:新建->变量名:CLASSPATH 变量值:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;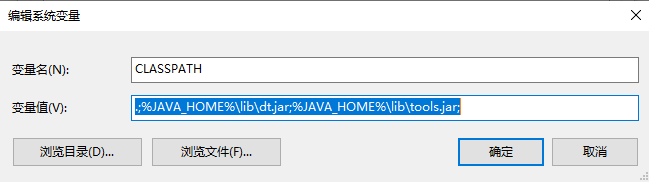
第四步:验证是否配置成功,win+R打开运行,输入cmd,打开控制台,在控制台分别输入java、javac、
java -version命令,出现如下所示即为配置成功。
3、Java基本语法
3.1 关键字与保留字
所谓关键字就是,被Java语言赋予了特殊含义,用作专门用途的字符串(均为小写)。
用于定义数据类型的关键字:class、interface、enum、byte、short、int、long、float、double、char、void、boolean。
用于定义流程控制的关键字:if、else、switch、case、default、while、do、for、break、continue、return。
用于定义访问权限修饰符的关键字:private、public、protected。
用于定义类、函数、变量修饰符的关键字:abstract、final、static、synchronized。
用于定义类与类之间关系的关键字:extends、implements。
用于定义建立实例及引用实例、判断实例的关键字:new、this、super、instanceof。
用于异常处理的关键字:try、catch、finally、throw、throws。
用于包的关键字:package、import。
其它修饰符关键字:native、strictfp、transient、volatile、assert。
用于定义数据类型值的字面值:true、false、null。
保留字在现有的Java版本中尚未使用,但也不能保证在以后的版本中不使用,自己命名标识符时要避免使用这些保留字:goto、const。
3.2 标识符
所谓标识符就是,Java对各种变量、方法和类等要素命名时使用的字符序列。
定义规则:
(1)由26个英文字母大小写,0-9,下划线(_)和美元符号($)组成。
(2)数字不能开头。
(3)不能使用关键字和保留字,但能包含关键字和保留字。
(4)Java严格区分大小写,长度无限制。
(5)标识符不能有空格、@、#、+、-、/ 等符号。
命名规范:
(1)包名:多单词组成时所有字母都小写;
(2)类名、接口名:多单词组成时,所有单词的首字母大写;
(3)变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写;
(4)常量名:所有字母都大写,多单词时每个单词用下划线连接。
3.3 变量
概念:
变量是内存中的一个存储区域,该区域的数据可以在同一类型范围内不断变化;变量是程序中最基本的存储单元,包含变量类型、变量名和存储的值。
注意事项:
(1)Java中每个变量必须先声明后使用;
(2)使用变量名来访问这块区域的数据;
(3)变量的作用域:其定义所在的一对{}内;
(4)变量只有在其作用域内才有效;
(5)同一作用域内不能定义重名变量。
定义格式:
数据类型 变量名 = 变量值;
数据类型:
八大基本数据类型:byte、boolean、short、cahr、float、int、long、double
对应引用类型:Byte、Boolean、Short、Character、Float、Integer、Long、Double
引用数据类型:数组、字符串、JDK提供的类、自定义的类。
**
3.3.1 整型变量的使用
Java的整型常量默认为int型,声明为long型常量须后加”l”或”L”。
Java程序中变量通常声明为int型,除非不足以表示较大的数,才使用long。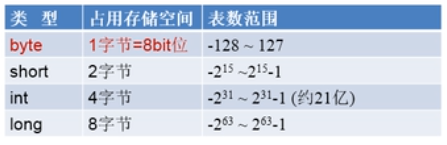
3.3.2 浮点型变量的使用
与整数类型相似,Java浮点类型也有固定的范围和字段长度,不受具体操作系统的影响。
浮点型常量通常有两种表示形式:(1)十进制形式,如5.12 512.0f .512(必须有小数点)(2)科学计数法形式,如:5.12e2 512E2 100E-2
float:单精度,尾数可以精确到7位有效数字,很多情况下,精度很难满足需求。
double:双精度,精度是float的两倍,通常采用此类型。
Java的浮点型常量默认为double型,声明为float型常量,须后加”f”或”F”。 
3.2.3 char型变量的使用
char型数据用来表示通常意义上的“字符”(2字节)。
Java中的所有字符都使用Unicode编码,故一个字符可以存储一个字母,一个汉字,或其它书面语的一个字符。
字符变量有三种表现形式:
(1)字符常量都是用单引号括起来的单个字符,例如:char c1 = ‘a’
(2)Java中允许使用转义字符‘\’来将其后的字符转变为特殊字符常量,例如:char c3 = ‘\n’
(3)直接使用Unicode值来表示字符常量:‘\uXXXX’,其中XXXX代表一个十六进制整数。
char类型是可以进行运算的,因为它都对应有Unicode码。
3.2.4 boolean型变量的使用
boolean只有两个值:true、false。
常常在条件判断、循环结构中使用。
3.2.5 基本数据类型之间的运算规则
自动类型提升:
当容量小的数据类型的变量与容量大的数据类型变量间的做运算时,结果自动提升为容量大的数据类型。
byte、short、char—>int—>long—>float—>double
特别的,当byte、short、char三种类型的变量做运算时,结果为int类型。
byte b = 2;int i = 12;byte = b + i; // 编译不通过int i1 = b + i; // 编译通过long l1 = b + i; // 编译通过float f1 = b + i; // 编译通过double d1 = b + i; // 编译通过
强制类型转换(自动类型提升的逆运算):
需要使用强制类型转换符:()
强制转换可能会导致精度损失。
double d = 12.3;int i = (int)d; // 截断操作,会损失精度
3.2.6 字符串类型String
String属于引用数据类型,不是基本数据类型。
String可以和8种基本数据类型变量做运算,且只能是连接运算,运算结果仍是String类型。
String a = ""; // 编译通过String b = "a"; // 编译通过char c = ''; // 编译不通过char d = ' '; // 编译通过
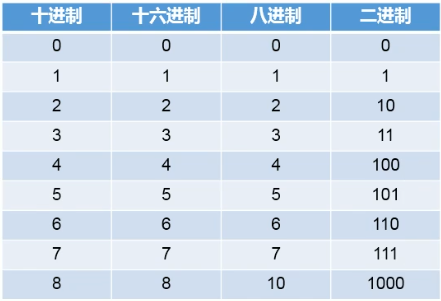
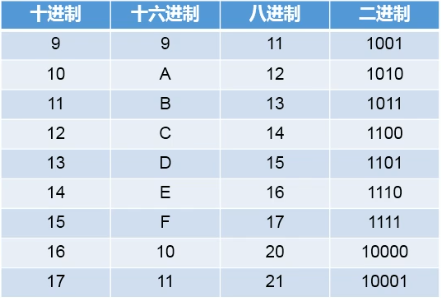
3.2.7 进制转换
- 所有数字在计算机底层都是以二进制形式存在的
- 对于整数有四种表示方式:
(1)二进制:0,1,满2进1。以
(2)十进制:0-9,满10进1。
(3)八进制:0-7,满8进1,以数字0开头表示。
(4)十六进制:0-9及A-F,满16进1,以数字0x或0X开头表示。
3.4 运算符
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等,包括算术运算符、赋值运算符、比较运算符(关系运算符)、逻辑运算符、位运算符以及三目运算符。
算术运算符: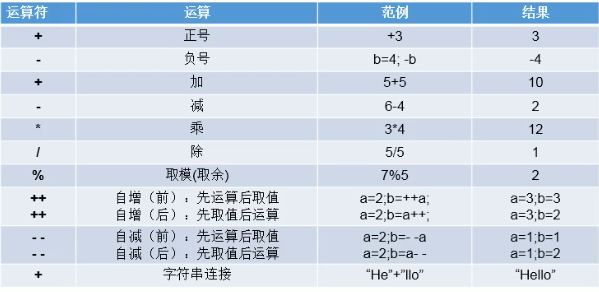
赋值运算符:=
当=号两边数据类型不一致时,可以使用自动类型抓换或使用强制类型转换原则进行处理。支持连续赋值。
扩展的赋值运算符:+=、-=、*=、/=、%=
比较运算符: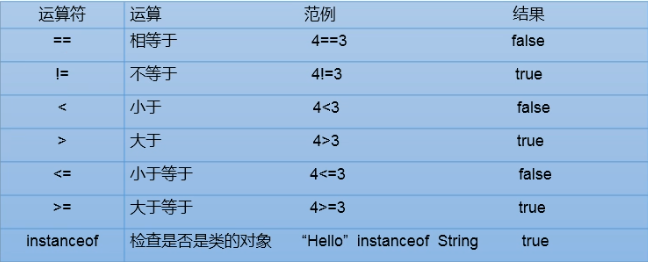
逻辑运算符: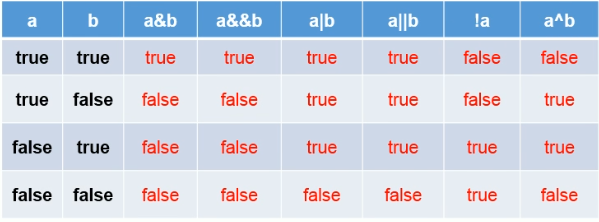
位运算符:位运算是直接对整数的二进制进行的运算。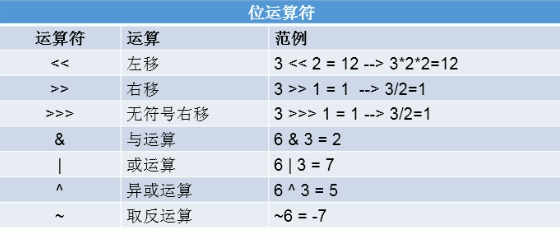
三目运算符:【条件表达式】?表达式1:表达式2;
3.5 程序流程控制
程序流程控制:顺序、分支(选择)、循环。
顺序:程序从上到下地执行,中间没有任何跳转和判断。
分支:根据条件选择性地执行某段代码,有if…else和switch-case两种分支语句。
循环:根据循环条件,重复性地执行某段代码,有for、while、do…while三种循环语句,在JDK1.5及以上版本中还提供了foreach循环,方便遍历集合、数组元素。
3.6 数组
3.6.1 概述
数组是多个相同类型数据按照一定顺序排列的集合,并使用一个名字命名,通过编号的方式对这些数据进行同一管理。
数组相关概念:数组名、元素、角标(下标、索引)、数组的长度。
数组是属于引用类型的变量。
创建数组对象会在内存中开辟一整块的连续空间,而数组名中引用的是这块连续空间的首地址。
数组的长度一旦确定就不能修改。
数组的索引是从0开始的,到数组的长度-1结束,调用时注意不要下标越界。
数组元素的默认初始化值:(1)整型数组默认0(2)浮点型数组默认0.0(3)char型默认0或’\u0000’,而非’0’
(4)boolean型默认false (5)引用数据类型数组默认为null
3.6.2 一维数组的内存解析
通俗来讲,局部变量存放在栈中,new出来的存放在堆中。
int[] arr = new int[]{1,2,3}; // 变量arr存放在栈中,new出来的那一部分存放在堆中// 将堆中那一部分的首地址赋给arr就将两者联系起来了String[] str = new String[4]; // 变量str存放在栈中,new出来的那一部分存放在堆中,初始值为nullstr[1] = "张杰";
3.6.3 二维数组的内存解析
int[][] arr = new int[4][]; // 变量arr存放在栈中 new出来的那一部分存放在堆中,首地址赋给arrarr[1] = new int[]{1,2,3}; // new出来的一部分存放在堆中arr[2] = new int[4]; // new出来的一部分存放在堆中arr[2][1] = 20;
3.6.4 数组中常见的算法
(1)数组元素赋值(杨辉三角、回形数等)
(2)求数值型数组中的元素的最大值、最小值、平均数、总和等
(3)数组的复制、反转、查找(线性查找、二分法查找)
// 二分查找(有序)int[] arr = new int[]{1,2,3,4,6,9,12,16,18,21};int dest = 18;int head = 0; // 初始索引int end = arr.length - 1;while(head <= end) {int middle = (head + end) / 2;if(dest == arr[middle]) {System.out.println("找到元素,位置为:" + middle);break;} else if(dest < arr[middle]) {end = arr[middle];} else {head = middle + 1;}}
(4)数组元素的排序算法(八大排序,这里只对冒泡排序、快速排序进行介绍)
衡量排序算法的优劣:
时间复杂度:分析关键字的比较次数和记录的移动次数。
空间复杂度:分析排序算法中需要多少辅助内存。
稳定性:若两个记录A和B的关键字值相等,但排序后A、B的先后次序保持不变,则称这种排序算法是稳定的。
冒泡排序:
基本思想:冒泡排序(Bubble
Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
/*** 冒泡排序** ①. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。* ②. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。* ③. 针对所有的元素重复以上的步骤,除了最后一个。* ④. 持续每次对越来越少的元素重复上面的步骤①~③,直到没有任何一对数字需要比较。* @param arr 待排序数组*/public static void bubbleSort(int[] arr){for (int i = arr.length - 1; i > 0; i--) { //外层循环移动游标for(int j = 0; j < i; j++){ //内层循环遍历游标及之后(或之前)的元素if(arr[j] > arr[j+1]){int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;System.out.println("Sorting: " + Arrays.toString(arr));}}}}

快速排序:
基本思想:挖坑填数+分治法
首先选一个轴值(pivot,也有叫基准的),通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
/*** 快速排序(递归)** ①. 从数列中挑出一个元素,称为"基准"(pivot)。* ②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。* ③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。* @param arr 待排序数组* @param low 左边界* @param high 右边界*/public static void quickSort(int[] arr, int low, int high){if(arr.length <= 0) return;if(low >= high) return;int left = low;int right = high;int temp = arr[left]; //挖坑1:保存基准的值while (left < right){while(left < right && arr[right] >= temp){ //坑2:从后向前找到比基准小的元素,插入到基准位置坑1中right--;}arr[left] = arr[right];while(left < right && arr[left] <= temp){ //坑3:从前往后找到比基准大的元素,放到刚才挖的坑2中left++;}arr[right] = arr[left];}arr[left] = temp; //基准值填补到坑3中,准备分治递归快排System.out.println("Sorting: " + Arrays.toString(arr));quickSort(arr, low, left-1);quickSort(arr, left+1, high);}
/*** 快速排序(非递归)** ①. 从数列中挑出一个元素,称为"基准"(pivot)。* ②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。* ③. 把分区之后两个区间的边界(low和high)压入栈保存,并循环①、②步骤* @param arr 待排序数组*/public static void quickSortByStack(int[] arr){if(arr.length <= 0) return;Stack<Integer> stack = new Stack<Integer>();//初始状态的左右指针入栈stack.push(0);stack.push(arr.length - 1);while(!stack.isEmpty()){int high = stack.pop(); //出栈进行划分int low = stack.pop();int pivotIdx = partition(arr, low, high);//保存中间变量if(pivotIdx > low) {stack.push(low);stack.push(pivotIdx - 1);}if(pivotIdx < high && pivotIdx >= 0){stack.push(pivotIdx + 1);stack.push(high);}}}private static int partition(int[] arr, int low, int high){if(arr.length <= 0) return -1;if(low >= high) return -1;int l = low;int r = high;int pivot = arr[l]; //挖坑1:保存基准的值while(l < r){while(l < r && arr[r] >= pivot){ //坑2:从后向前找到比基准小的元素,插入到基准位置坑1中r--;}arr[l] = arr[r];while(l < r && arr[l] <= pivot){ //坑3:从前往后找到比基准大的元素,放到刚才挖的坑2中l++;}arr[r] = arr[l];}arr[l] = pivot; //基准值填补到坑3中,准备分治递归快排return l;}

快速排序排序效率非常高。 虽然它运行最糟糕时将达到O(n²)的时间复杂度, 但通常平均来看, 它的时间复杂为O(nlogn),
比同样为O(nlogn)时间复杂度的归并排序还要快. 快速排序似乎更偏爱乱序的数列, 越是乱序的数列, 它相比其他排序而言, 相对效率更高。
3.6.5 Arrays工具类的使用
java.util.Arrays类即为操作数组的工具类,包含了用来操作数组(比如排序和搜索)的各种方法。
下面是常用的几个方法
3.6.6 数组中的常见异常
(1)数组下标越界ArrayIndexOutOfBoundsException
(2)空指针异常NullPointerException
4、面向对象(上)
开篇时已经对面向对象做了一个简单的了解,现在我们开始对面向对象进行详细的学习。学习面向对象内容的三条主线:(1)Java类及类的成员(属性、方法、构造器;代码块、内部类) (2)面向对象三大特征(封装、继承、多态) (3)其它关键字(this、super、static、final、abstract、interface、package、import等)
4.1 面向过程(POP)与面向对象(OOP)
二者都是一种思想,面向对象是相对于面向过程而言的。面向过程强调的是功能行为,以函数为最小单位,考虑怎么做。面向对象将功能封装进对象,强调具备了功能的对象,以类/对象为最小单位,考虑谁来做。
面向对象更加强调运用人类在日常的思维逻辑中采用的思想方法与原则,如抽象、分类、继承、聚合、多态等。程序员从面向过程的执行者转化成了面向对象的指挥者。
面向对象分析方法分析问题的思路和步骤:
- 根据问题需要,选择问题所针对的现实世界中的实体。
- 从实体中寻找解决问题相关的属性和功能,这些属性和功能就形成了概念世界中的类。
- 把抽象的实体用计算机语言进行描述,形成计算机世界中类的定义,即借助某种程序语言,把类构造成计算机能够识别处理的数据结构。
- 将类实例化成计算机世界中的对象,对象是计算机世界中解决问题的最终工具。
4.2 面向对象
4.2.1 类和对象
类和对象是面向对象的核心概念。
类是对一类事物的描述,是抽象的、概念上的定义。
对象是实际存在的该类事物的每个个体,因而也被称为实例。”万事万物皆为对象”。现实世界中的生物体,都是由最基本的细胞组成的,同理,Java代码世界是由多个不同功能的类构成的。
属性:对应类中的成员变量。
行为:对应类中的成员方法。
类和对象的创建(实例化):关键字new,通过实例化出来的对象调用类的属性和方法。
4.2.2 对象的内存解析
堆(Heap):此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。这一点在Java虚拟机规范中的描述是:所有对象实例以及数组都要在堆上分配。
栈(stack):通常所说的栈,是指虚拟机的栈。虚拟机栈用于存储局部变量等。局部变量存储了编译期可知长度的 各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不等同于对象本身,是对象在堆内存的首地址)。方法执行完自动释放。
方法区(Method Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
User user = new User(); // user存储在栈区,实例化出来的对象属性存储在堆区,// 栈区值相堆区首地址将两者联系起来user.name = "Tom";
4.2.3 方法
声明:权限修饰符 返回值类型 方法名(形参列表){ 方法体 }
权限修饰符:public、private、缺省、protected(public > protected > 缺省 > private)
return关键字:在方法体中使用,作用结束方法,对有返回值类型的方法,返回指定类型返回值。该关键字后面语句不执行。
方法的使用中,可以使用当前类的属性或方法;特殊的,一个方法调用自己本身,这种叫递归调用;方法中不可以定义方法。
(1)方法的重载与重写
概念:
重载就是在同一个类中允许存在一个以上的同名方法,只要他们的参数个数或参数类型不同即可。
重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写!
特点:
重载规则:
- 方法名一致,参数列表中参数的顺序、类型、个数不同;
- 重载与方法的返回值无关,存在与父类、字类以及同类中;
- 可以抛出不同异常,可以有不同的修饰符。
重写规则:
- 参数列表必须完全与被重写的方法一致,返回类型必须完全与被重写方法的返回类型一致;
- 构造方法不能被重写,声明为final的方法不能被重写,声明为static的方法不能被重写,但是能够被再声明;
- 访问权限不能比父类中被重写的方法的访问权限更低;
- 重写的方法能够抛出任何非强制异常(也叫非运行时异常),无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写的方法声明的更广泛的强制性异常,反之则可以。
(2)可变形参的方法
JDK5.0以前,采用数组形参来定义方法,传入多个同一类型的变量
public void test(int a, String[] books);
JDK5.0及以后,采用可变个数形参来定义方法,传入多个同一类型的变量
public void test(String ...books);
(3)方法参数的值传递机制
- 如果参数是基本数据类型,此时实参赋给形参的是实参真实存储的数据值;
- 如果参数是引用数据类型,此时实参赋给形参的是实参存储数据的地址值。
4.2.4 理解 “万事万物皆对象”
- 在Java语言范畴中,我们都将功能、结构等封装到类中,通过类的实例化来调用具体的功能结构;
- 涉及到Java语言与前端html、后端的数据库交互时,前后端的结构在Java层面交互时,都体现为类、对象。
4.2.5 匿名对象的使用
- 匿名即为没有名字,那么匿名对象即为没有名字的对象,也即我们创建的对象没有显式的赋给一个变量;
- 简单来说就是直接new一个对象去调用该对象里面的方法;
- 匿名对象只能调用一次。
4.3 封装
首先,我们要理解为什么要进行封装,比如我们要用洗衣机洗衣服,只需要按下开关就好了,有必要去了解洗衣机的内部结构吗?
我们程序的设计追求的是“高内聚,低耦合”:
- 高内聚:类的内部数据操作细节自己完成,不允许外部干涉;
- 低耦合:仅对外暴露少量的方法用于使用。
隐藏对象内部的复杂性,只对外公开简单的接口,便于外界调用,从而提供系统的可扩展性、可维护性。通俗的说,把该隐藏的隐藏起来,该暴露的暴露出来,这就是封装的设计思想。
4.3.1 封装性的体现
将类的属性私有化,同时提供公共的方法来获取(getter、setter方法)。
还可根据需求声明不对外暴露的私有方法,单例模式的运用等等。
封装性的体现需要权限修饰符来配合:
- Java规定四种权限修饰符(从小到大):private、default、protected、public
- 四种权限修饰符可以修饰类及类的内部结构,属性、方法、构造器、内部类
- 类的修饰只能是default或public

若有收获,就点个赞吧
0 人点赞
