安装方式参考IK分词器
测试:
POST /_analyze{"text": "如家酒店还不错","analyzer": "pinyin"}
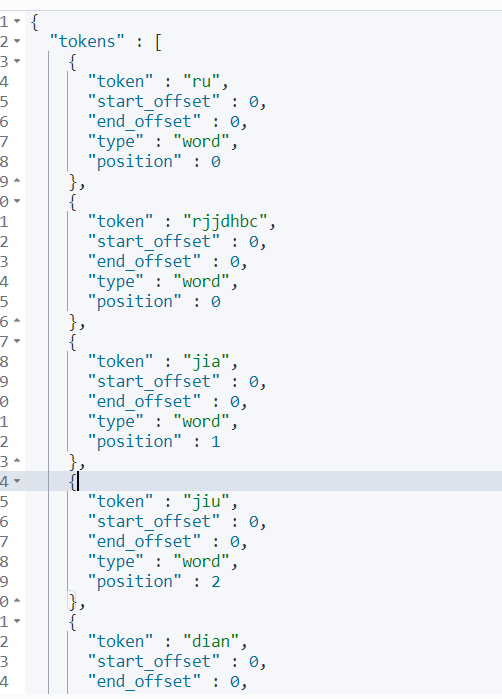
自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch中分词器(analyzer)的组成包含三部分:
声明自定义分词器如下:
PUT /test{"settings": {"analysis": {"analyzer": { // 自定义分词器"my_analyzer": { // 分词器名称"tokenizer": "ik_max_word","filter": "py"}},"filter": { // 自定义tokenizer filter"py": { // 过滤器名称"type": "pinyin", // 过滤器类型,这里是pinyin"keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart" //可以解决同音字问题}}}}
测试: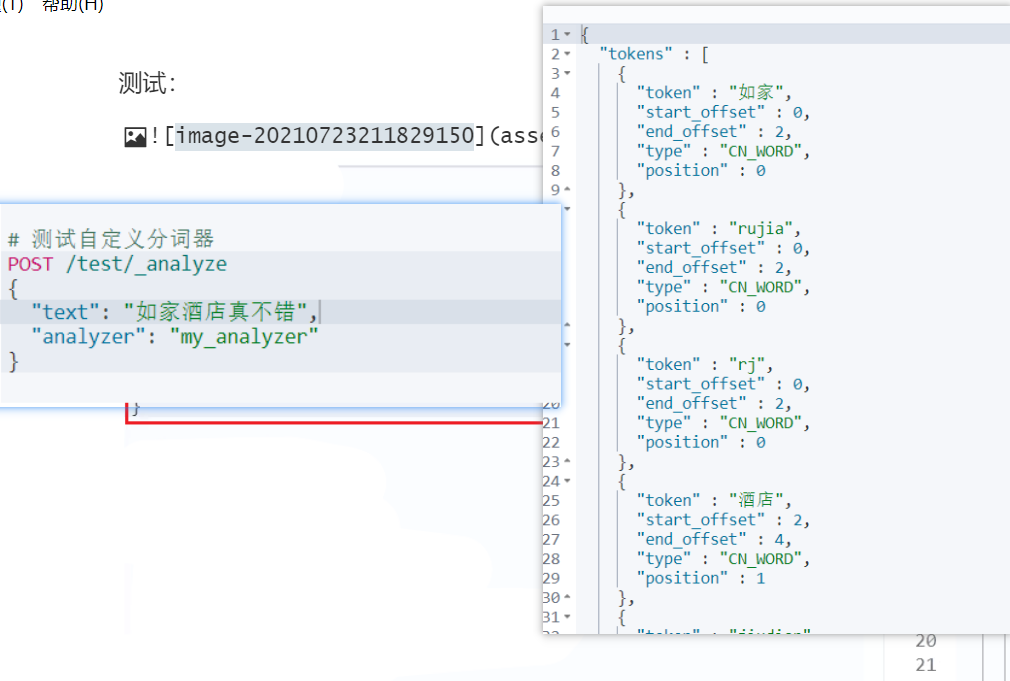

自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是completion类型。
- 字段的内容一般是用来补全的多个词条形成的数组。
创建索引库:
// 创建索引库PUT test{"mappings": {"properties": {"title":{"type": "completion"}}}}
然后插入下面的数据:
// 示例数据POST test/_doc{"title": ["Sony", "WH-1000XM3"]}POST test/_doc{"title": ["SK-II", "PITERA"]}POST test/_doc{"title": ["Nintendo", "switch"]}
查询的DSL语句如下:
// 自动补全查询GET /test/_search{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}}
数据同步
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步
思路分析
常见的数据同步方案有三种
- 同步调用
- 异步通知
- 监听binlog
方式一同步调用

基本步骤如下:
- hotel-demo对外提供接口,用来修改elasticsearch中的数据
酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口,
方式二异步通知
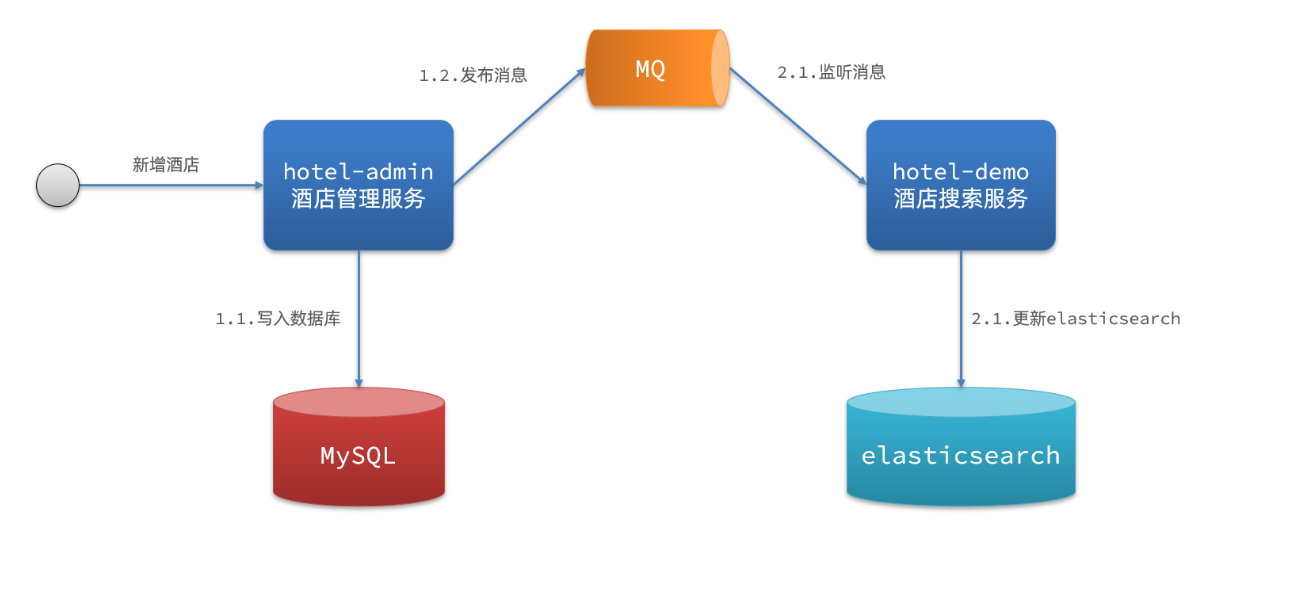
流程如下:hotel-admin对mysql数据库数据完成增、删、改后,发送MQ消息
hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改
方式三 监听binlog
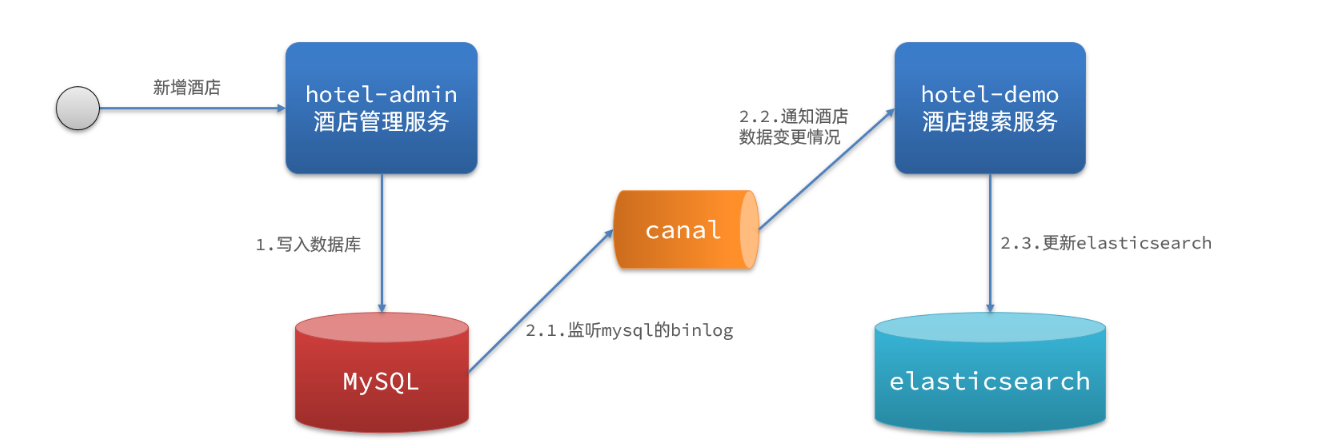
流程如下:给mysql开启binlog功能
- mysql完成增、删、改操作都会记录在binlog中
- hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
三种特点:
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高

若有收获,就点个赞吧
0 人点赞
