https://docs.qq.com/doc/DWHl3am5Zb05QbGVs
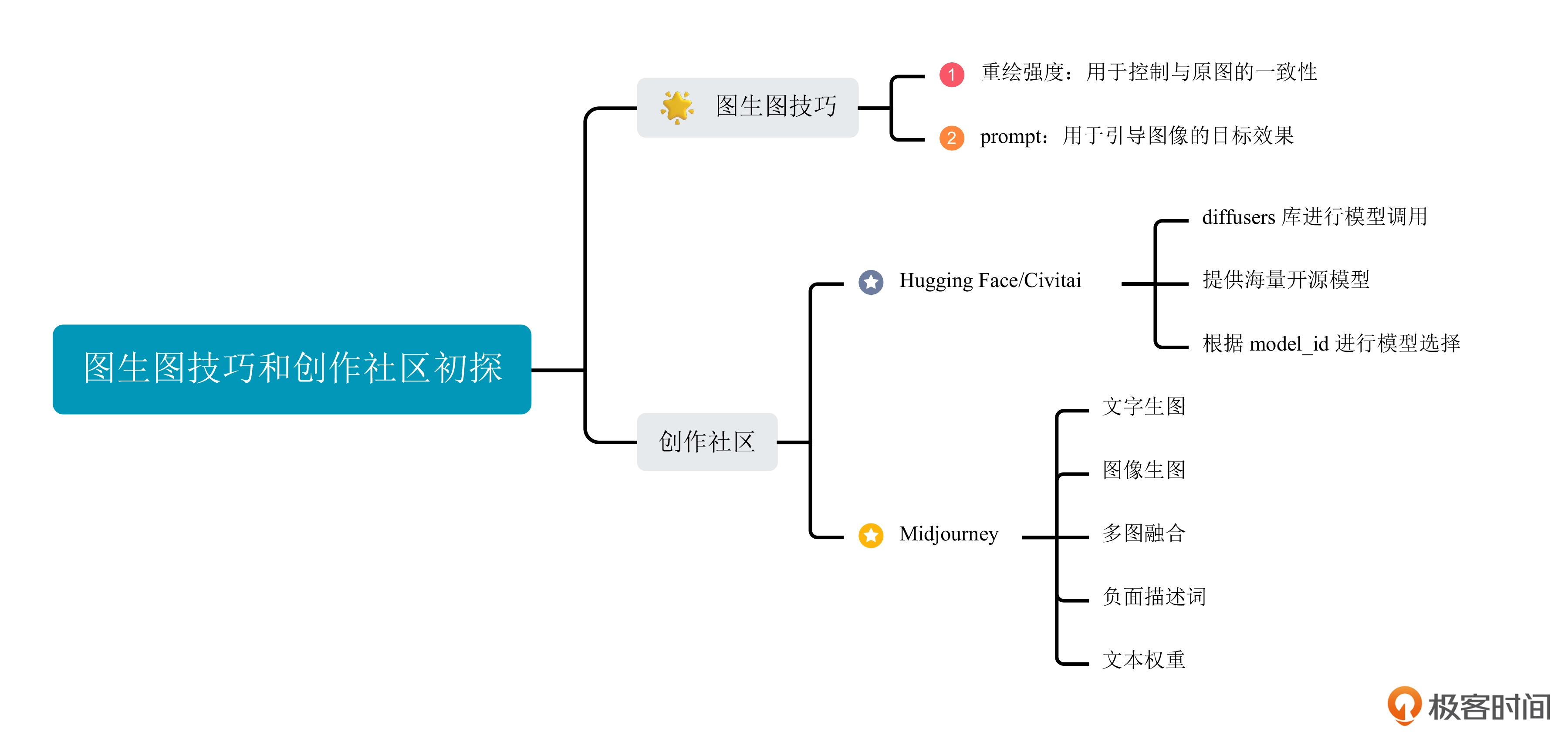
思考题: 如果你想绘制一幅精细化的人物肖像,AI 绘画生成的图像在手部和脸部细节存在瑕疵。这种情况下,有哪些方法可以改善这些问题? 我尝试了下面的提示词: a beautiful women, medium shot, studio light, Realism Portrait 当使用 “a utral detailed portrait of …” 时,效果与 “close up” 接近: a utral detailed portrait of a beautiful women, 应对手部和脸部的瑕疵,使用了下面的负面提示词: mutated hands, fused fingers, too many fingers, missing fingers, poorly drawn hands, blurry eyes, blurred iris, blurry face, poorly drawn face, mutation, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, out of frame, multiple faces, long neck, nsfw, 提示词网站https://stablediffusion.fr/prompts
本身sd就是一个预训练模型了,还需要加载其他模型和lora?
你好。其他模型,比如Textual Inversion和LoRA,都是在原有SD模型基础上,新衍生的绘画能力。比如我们基于SD1.5,希望能够进行微调得到善于生成“漩涡鸣人”的模型,又不希望调整SD1.5的原有参数影响其本身的生成能力,便会引入Textual Inversion或者LoRA。我们只需要几张到几十张“漩涡鸣人”的图片就能优化我们自己的模型,使用的时候加载新增的参数即可。有两个好处:一是参数少、数据少,普通人手中的资源也能训练的动;二是使用的时候即插即用,即得到了想要的新功能、又不影响模型的原有能力。 模型的训练时间长,但训练完成后,模型确定了,类似于有了一个确定的函数,所以运算就很快,是这样吗? 你的理解基本是正确的。模型训练的过程是在训练UNet去噪结构(我们第6-8讲会详细讲),这个学习的过程需要海量的数据来驱动,需要很多GPU、很长时间;训练完成后,我们只需要使用训练好的UNet模型来帮忙计算,经过20~30 step便可以出图,因此速度就会快一些。 在实际操作中,我们可以引入多个不同的 LoRA 模型同时使用。通过结合不同的 LoRA 模型,我们可以混合并匹配不同的风格、特点和创作元素,创造出独特而个性化的作品。这种创作方法不仅丰富了图像的表现力,还让我们能够更好地实现自己的创意和想象。请根据*故事,写出对应的漫画分镜头脚本。格式是一个镜头画面,一句对应的画面文本描述。

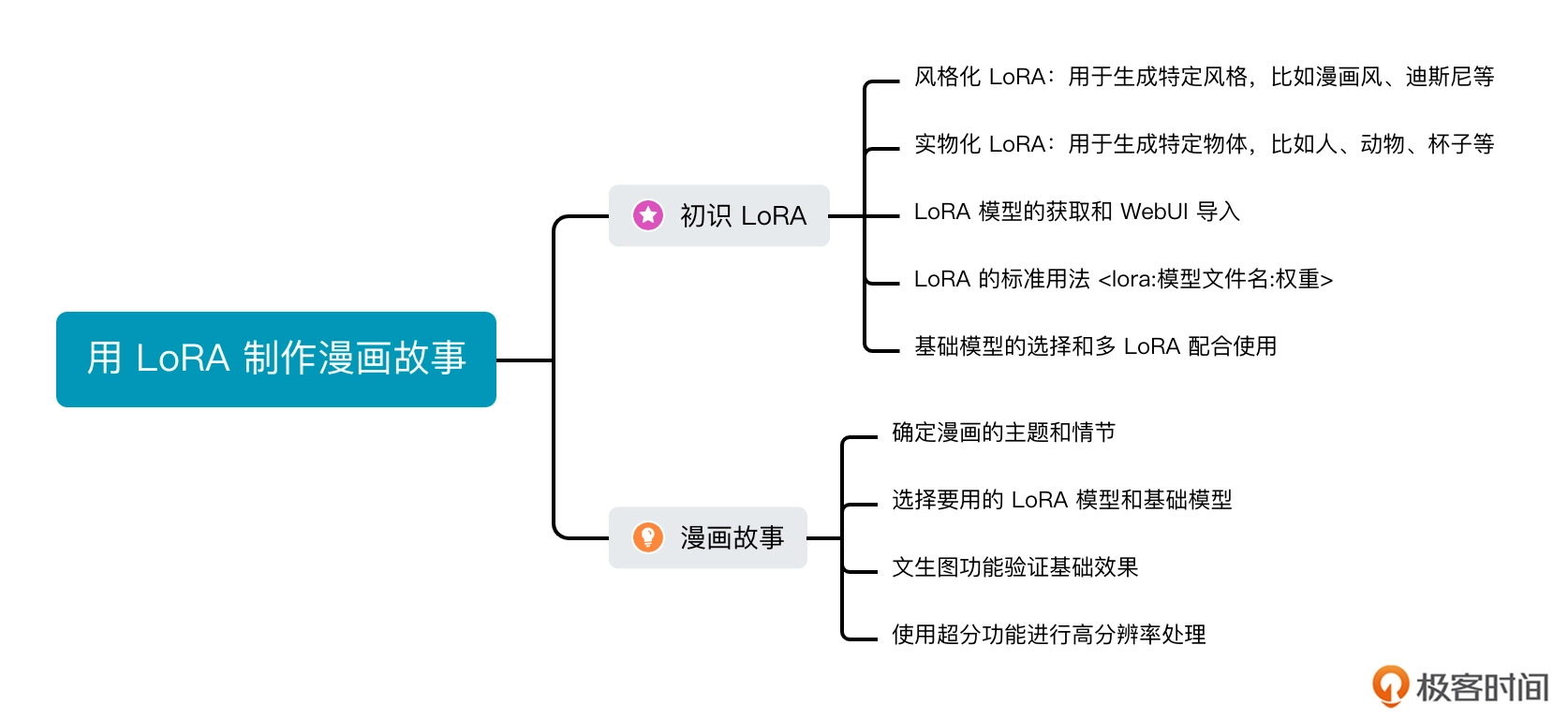
在使用 LoRA 模型生成图像时,如何既保持特定 ID 的角色,同时引入多样化的风格? ———— 可以通过多个 lora 分别控制 ID 和风格。不过多个 lora 相互融合会有冲突,有什么好的解决方法吗?
作者回复: 你好。多个LoRA互相作用确实会互相影响,有一些建议可以缓解这个问题但不能根治:第一,多个LoRA训练的时候使用相同的基础模型;第二,使用LoRA的时候,在保证效果的情况下,权重尽可能小(减小影响其他LoRA);第三,找到一张较好的构图后,反复微调各个Lora的权重组合,找到比较合理的平衡。希望这些建议能帮助到你。 A main road is divided into two small roads, and the scenery of the two roads is different —no broken road —ar 16:9
若有收获,就点个赞吧
0 人点赞
