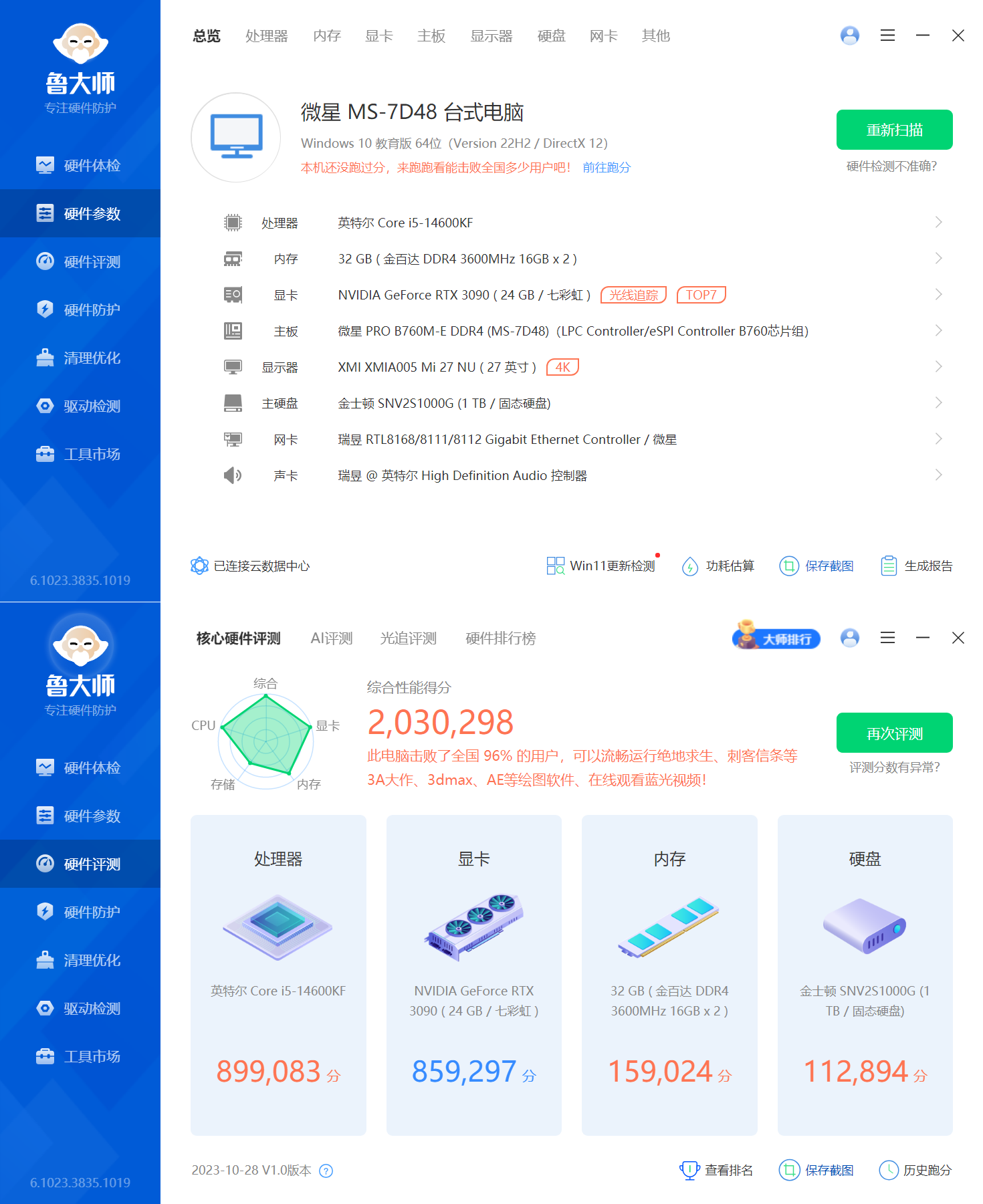

一、模型
1.大模型
作用:几乎决定整体画风、样式及内容
扩展名:ckpt或safetensors
文件大小:2GB以上
下载方式:①启动器下载,无预览,无需科学 ② https://civitai.com/,模型全,有预览,需科学
存放路径:D:\stable diffusion\models\Stable-diffusion
经典现实风模型
chilloutmix_NiPrunedFp32Fix
sd-v1-5-inpainting(SD官方)
二次元模型
Anything-V3.0
2.VAE
作用:提亮色彩
减少出黑图情况
1.使用vae-ft-mse-840000-ema-pruned
2.启动器-高级选项-取消勾选【不适用版精度 VAE(no-half-vae)】
下载方式:启动器下载 (模型管理——变分自编码器VAE模型)或C站

存放路径:D:\stable diffusion\models\VAE
3.emdding
又名:textual inversion,嵌入/文本反转
使用方法:

放在这个文件夹里面,生成图片的时候需要带上 文件名 作为 tag。
例如,上面这张图里面的 shiratama_at_2-3000.pt 这个模型,使用的时候就需要带上这个tag:shiratama_at_2-3000
作用:生成特定的动作或特定的特征,也可以用来生成某种特定的画风

存放路径:D:\stable diffusion\embeddings
4.LoRA
全称Low-Rank Adaptation of Large Language Models,大语言模型的低阶适应
存放路径:D:\stable diffusion\models\Lora作用:只要是图片特征几乎都可以,动作、画风、物品细节、人物细节…
①挂载lora可以九成九复刻指定人物的特征
③固定人物的动作特征,只要加载生成的人物都是这个动作
Lora与Emdedding区别:
Embedding文件小,保存信息量有限,对人物还原、动作指定、画风指定效果一般
大部分用来还原动漫人物 三视图、多视图人物展现
可做同一件事,优先Lora;涉及还原真人,Lora更好
注意点
1.用Lora配套的大模型效果更好
2.最好使用和Lora作者相同的参数
正面提示词、负面提示词、提示词相关性CFG、采样迭代步数Steps、随机种子seed
若生成失败,注意检查Lora中间的名字和模型名字是否一致3.正确设置Lora权重
如:
lora权重值不要设置在1以上,最好0.8、0.9提高出图质量
若想稍有影响,修饰来用,设置0.6、0.4之间
4.有触发词一定使用触发词(Trigger Words)
加入到正向提示词,每一个触发词代表一类风格,一般不混用;Tags没用不管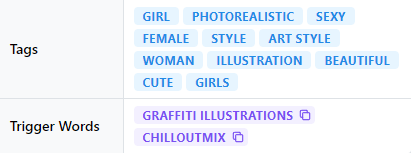 5.新手尽量不要混用lora
除非作者给了非常成熟的建议
5.新手尽量不要混用lora
除非作者给了非常成熟的建议
 ### 5.Hypernetworks
低配版lora
作用:对画面风格的转换,对生成的图片针对性调整
存放路径:D:\stable diffusion\models\hypernetworks
注意点同lora:正确设置超网络的权重,有触发词一定使用触发词、最好使用和超网络作者相同的参数、新手不混用超网络
### 6.模型解惑
不能通过扩展名确定模型类型
Stable Diffusion 模型解析>>
safetensors=ckpt,可在web ui转换格式,safetensors比较安全
### 7.Web UI 参数设置
### 5.Hypernetworks
低配版lora
作用:对画面风格的转换,对生成的图片针对性调整
存放路径:D:\stable diffusion\models\hypernetworks
注意点同lora:正确设置超网络的权重,有触发词一定使用触发词、最好使用和超网络作者相同的参数、新手不混用超网络
### 6.模型解惑
不能通过扩展名确定模型类型
Stable Diffusion 模型解析>>
safetensors=ckpt,可在web ui转换格式,safetensors比较安全
### 7.Web UI 参数设置
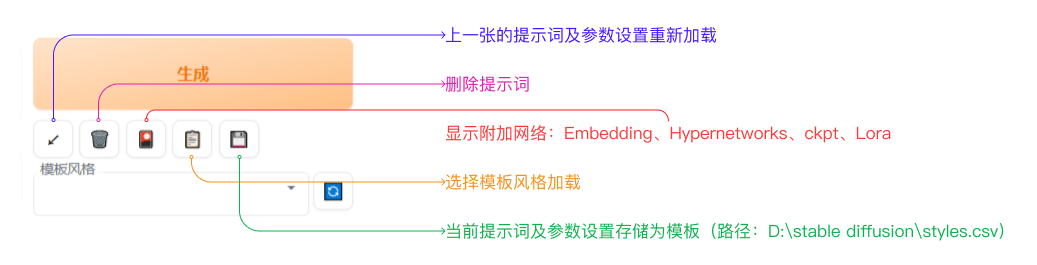 #### 1.Clip跳过层
全称:Contrative Language-Image Pre-training 语言与图像的对比预训练
画面丰富,Clip跳过层拉高,更加理解提示词,Clip跳过层拉低
#### 2.采样方法
常用推荐:Euler a | DPM++2M Karras | DDIM
#### 1.Clip跳过层
全称:Contrative Language-Image Pre-training 语言与图像的对比预训练
画面丰富,Clip跳过层拉高,更加理解提示词,Clip跳过层拉低
#### 2.采样方法
常用推荐:Euler a | DPM++2M Karras | DDIM
DPM adaptive:选用此采样,迭代步数没用(一般配合特殊插件、特殊场景使用)


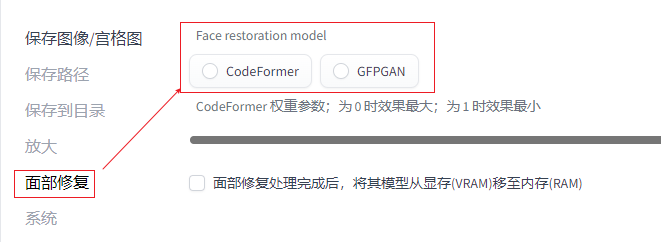
3.面部修复
1.现实风开启面部修复,二次元不建议开启
2.不建议开高清修复的同时开面部修复,或者这两个同时开的同时再加Lora
3.注:如果脸部在画面中占比很小,则不能很好地还原面部特征4.可平铺(生成花纹)
5.放大算法
三次元3D R-ESRGAN 4x+ 二次元2D R-ESRGAN 4x+Anime6B6.重绘幅度
值越小与原图越相近,推荐 0.4-0.7
7.图片宽高
注意:1.5版本官方模型训练的分辨率512-768之间,
宽高可以设置在512-768之间,生成正确构图的小图通过高清修复实现大图

8.提示词相关性 (CFG Scale)
图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示 (根据模型)在一定程度上降低了图像质量。可以用更多的采样步骤来抵消
提高图片的对比度,可以把CFG适度拉高

9.随机种子
点筛子图标重置随机种子
原理:不同种子产生不同的噪声图,通过对不同噪声图去噪,得到不同的图片
其他参数一致,随机种子一样,生成的图有99%的像

差异随机种子是固定一个种子,然后调整差异强度来生成图片,因为是固定的seed值,所以生成的图风格都是类似的。

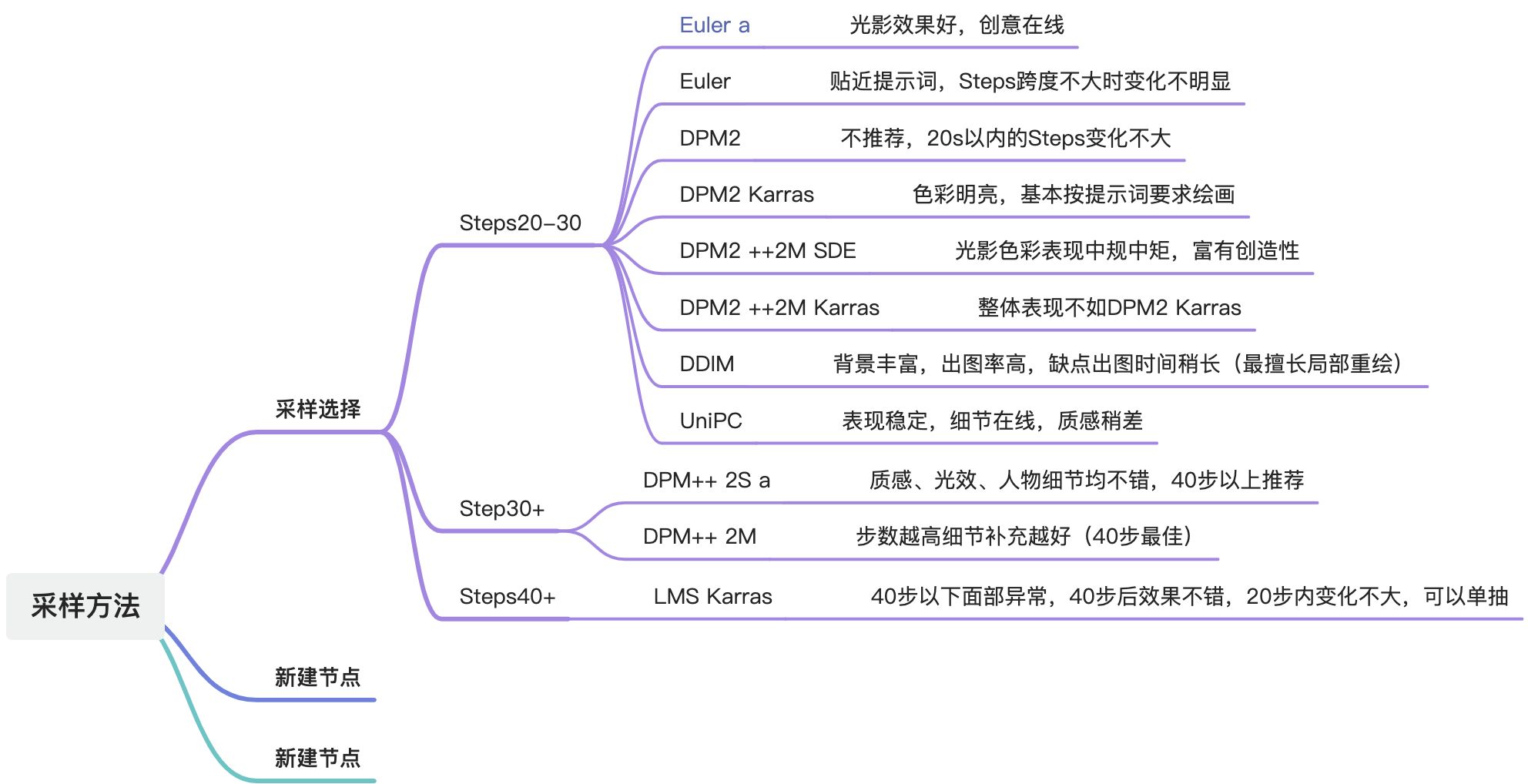
10.脚本
注:脚本不用时选无关闭
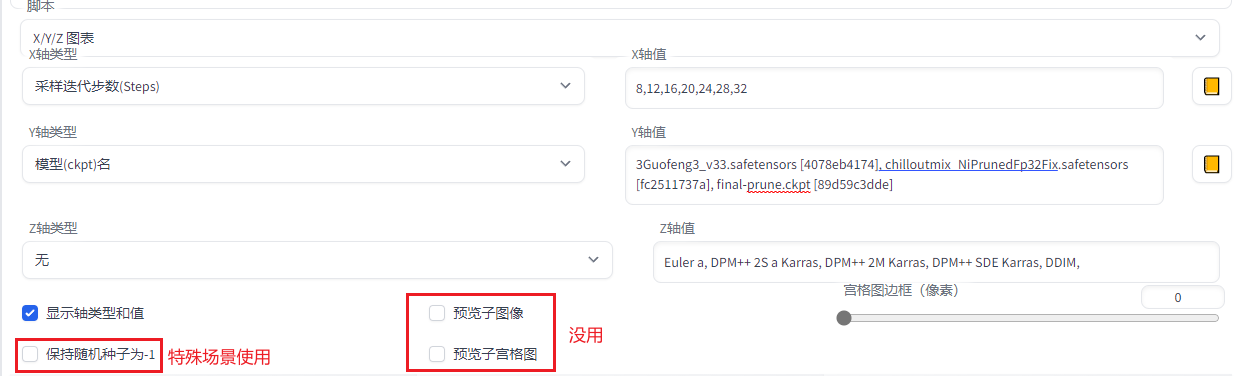

1.提示词矩阵
测试某个或多个提示词有没有效果 ( AI | cloud | cube | … )

2.x/y/z图表-提示词搜索/替换

11.图生图
(1)缩放模式
常用填充:填充风景效果好,人物效果一般
进阶案例:不改变整体线条和色彩,逐步变为二次元
重绘幅度每次设置0.2-图生图-重绘0.2-图生图…循环往复

(2)局部重绘
蒙版模糊:相当于PS的羽化
蒙版蒙住内容:推荐原图,还原效果较好
重绘区域:全图(更好地融合本体与画上的衣服),仅蒙版(只重绘蒙版区域内容)
仅蒙版模式的边缘预留像素:值越高,像素越来越稀疏;值越小,像素密度越大,单位区域里修复效果越好,如果太低,很容易出现在很小的区域出现一张图(房间,人)的场景

(3)局部重绘(上传蒙版)
ps里精准抠出蒙版黑白图层,贴合边缘
黑色代表不涂蒙版(不修改)、白色代表涂蒙版
12.附加功能
作用:缩放修复,放大的同时变清晰
upscaler1(放大算法)三次元3D R-ESRGAN 4x+ ;二次元2D R-ESRGAN 4x+Anime6B

13.图片信息
不是sd生成的,用Tag反推插件,相当于MJ的描述功能
阈值一般0.35-0.4,仅参考
14.高分辨率修复更新(v1.6版本)
设置-用户界面-勾选

二、提示词
Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.
越靠前的词汇权重越高
正面 Tag(想要的内容)是这些,改善画质用的 Tag:
masterpiece, best quality,
通用反面 Tag(不想要的内容),保底不出古神用的 Tag:
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
整合包内一般都会带一个自动补全 Tag 的插件,如果你不知道那些 Tag 好,可以使用标签超市
另外,你可能会看到别人发的 Tag 里面会有一些符号?比如大小括号等等。这属于进阶用法,这里仅仅简单提及一下。以 girl 这个 Tag 作为例子。
(girl) 加权重,这里是1.1倍。括号是可以叠加的,如((girl)) 加很多权重。1.1*1.1=1.21倍
[girl] 减权重,一般用的少。减权重也一般就用下面的指定倍数。
(girl:1.5) 指定倍数,这里是1.5倍的权重。还可以 (girl:0.9) 达到减权重的效果
采样步数不需要太大,一般在50以内。通常28是一个不错的值。
采样器没有优劣之分,但是他们速度不同。全看个人喜好。推荐的是图中圈出来的几个,速度效果都不错
提示词相关性代表你输入的 Tag 对画面的引导程度有多大,可以理解为 “越小AI越自由发挥”
太大会出现锐化、线条变粗的效果。太小AI就自由发挥了,不看 Tag
随机种子是 生成过程中所有随机性的源头 每个种子都是一幅不一样的画。默认的 -1 是代表每次都换一个随机种子。由随机种子,生成了随机的噪声图,再交给AI进行画出来。
作者:秋葉aaaki https://www.bilibili.com/read/cv22661198 出处:bilibili短句优势:可以描述物品和物品之间的关系,能够更好地表现场景之间的关系
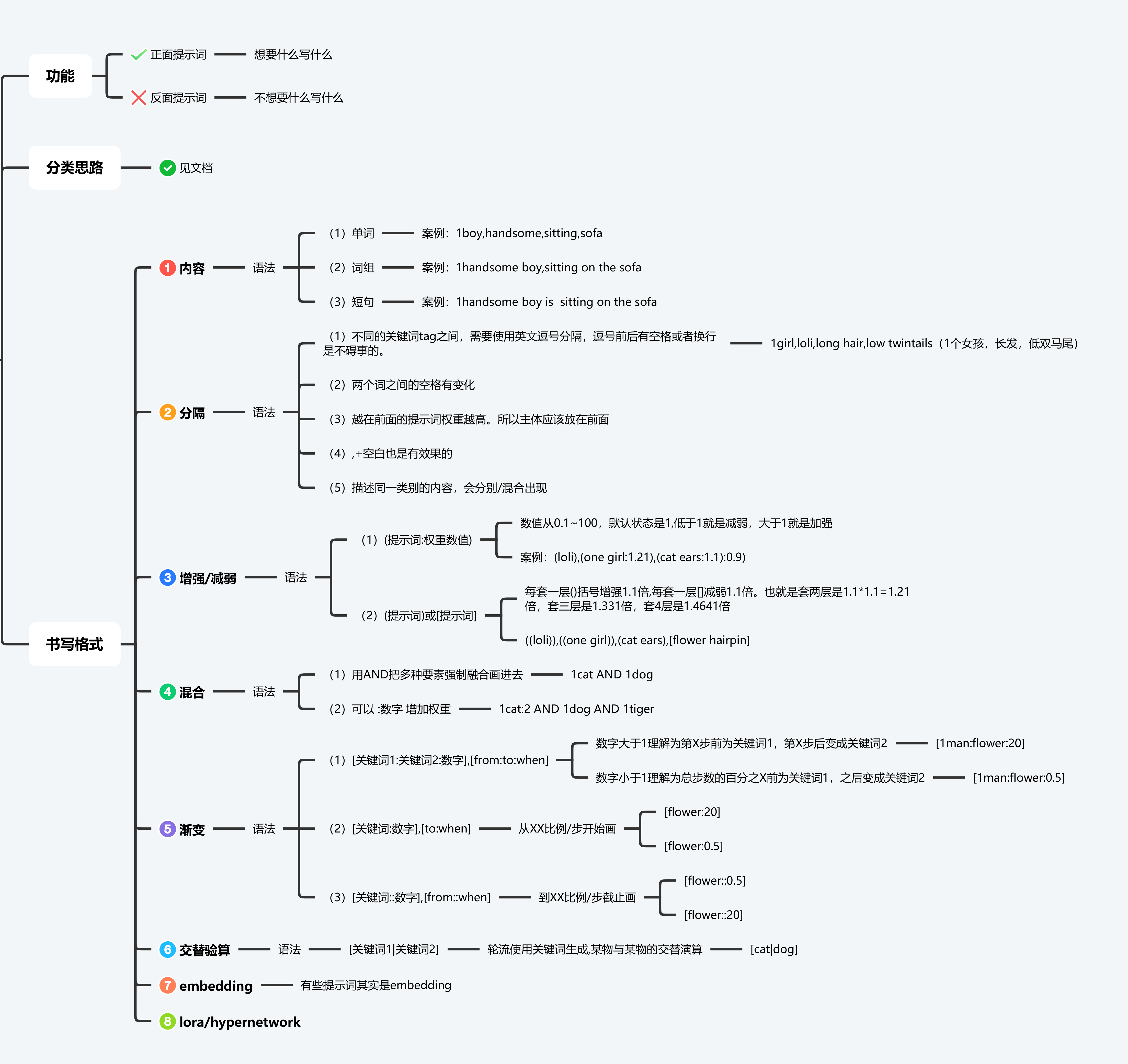
栗子:
[画质]masterpiece,high quality,8k,highres,
[主体]photo of 1girl,
[人物属性描写]thin,long hair,black hair,kind smile,cat ears,purple eyes,red lip,
[人物衣服]hoop earrings,nurse cap,capelet,sunglasses,business suit,high heels,
[背景]background is street,
[画风]realistic,
[镜头]full body,
[其他] Minter,sunlight,warm
((nsfw)),sketches, nude
(worst quality:2), (low quality:2), (normal quality:2), lowers, normal quality,
((monochrome)), ((grayscale)),
facing away, looking away,
text, error,extra digit, fewer digits, croppedjpeg artifacts,signature, watermark, username, blurry,
skin spots, acnes, skin blemishes, bad anatomy,fat,bad feet,cropped,poorly drawn hands, poorly drawn face,
mutation,deformed
注:权重一般在0-2之间调节,如:(red hair:2)
nsfw = not suitable for work
三、插件
安装&卸载
1.扩展-可用-加载自,搜索插件名,安装(首选)
2.扩展-从网址安装-粘贴Git地址,安装(推荐)
3.本地安装:Github下载ZIP解压,放置:D:\stable diffusion\extensions(不推荐,无法升级,切换版本)
1.启动器-版本管理-扩展-卸载
2.到D:\stable diffusion\extensions文件夹,删除不想要的插件文件夹
1.ControlNet
作用:
骨骼绑定,精准控线,依据3D视图的法线进行绘图,线稿上色,依据深度图结构透视精准重绘(可以简单理解为3渲2)等 1.Pixel Perfect完美像素(智能决定最适合预处理器以及sd的分辨率 ) 2.生成图中含有Controlnet的预览图,说明ControlNet调用成功 下载对应的模型放在模型路径(软件会自动下载预处理器) 模型路径:D:\stable diffusion\extensions\sd-webui-controlnet\models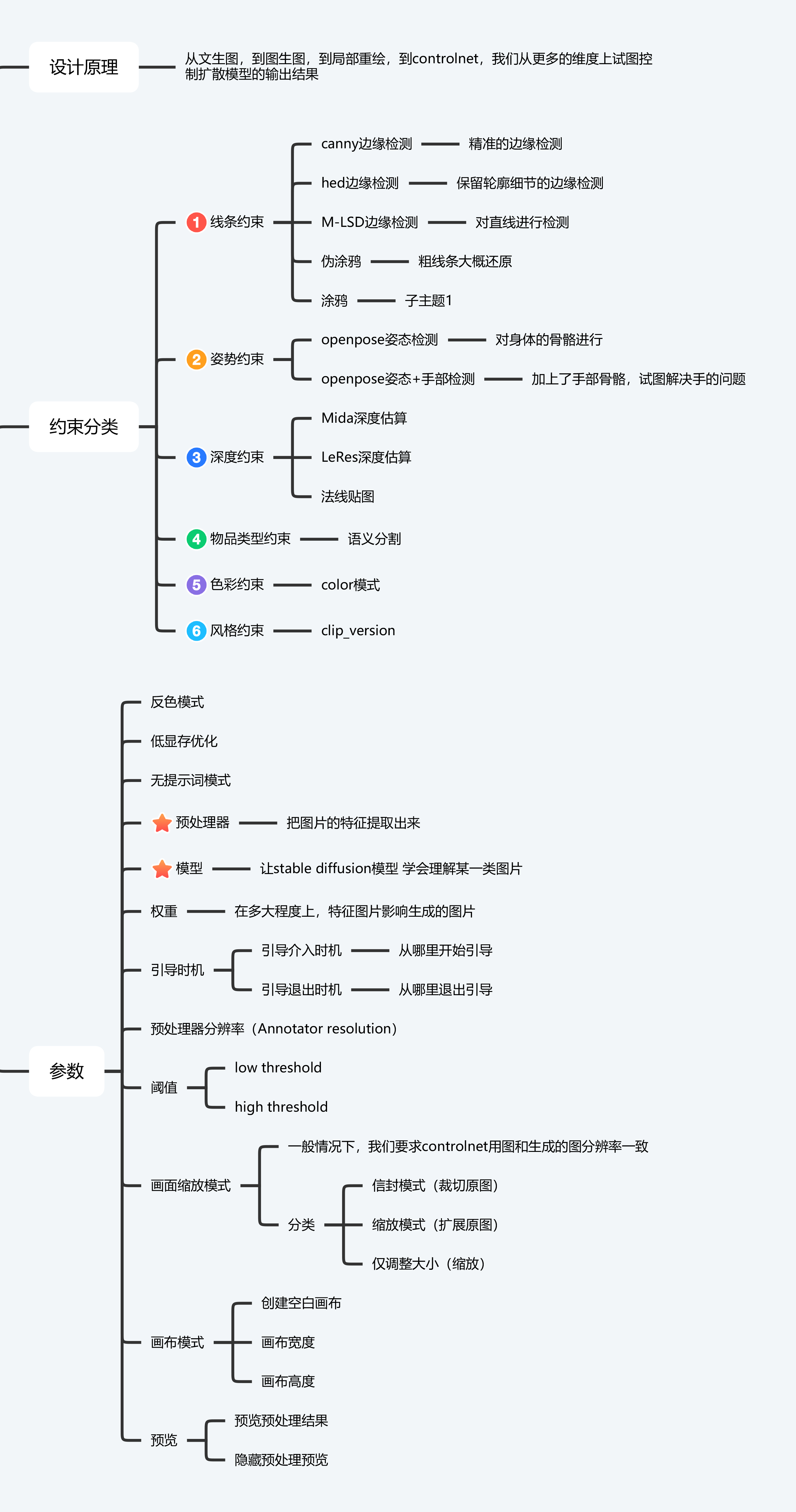
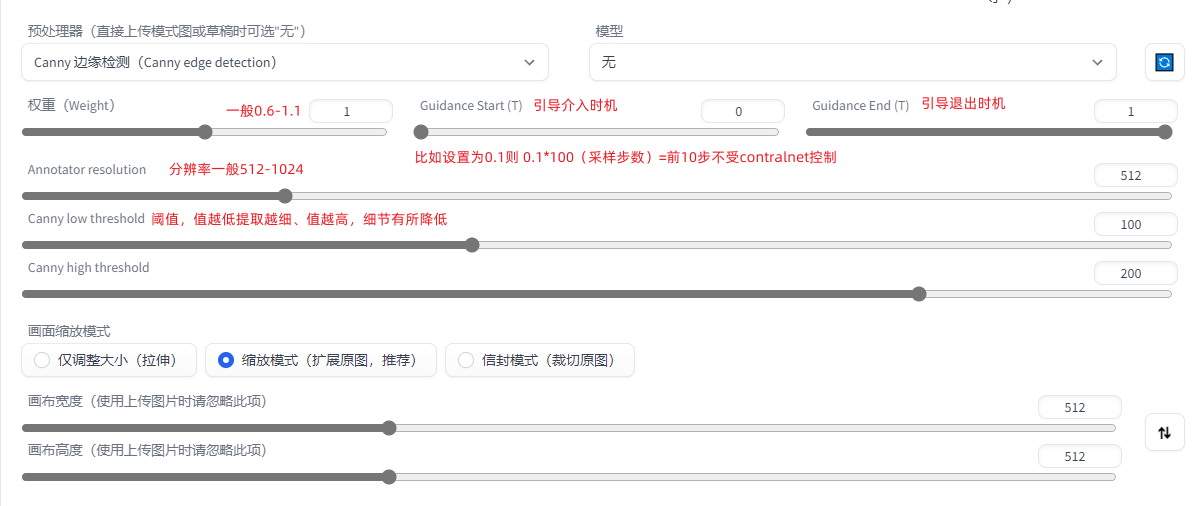 越前面的步数,对整个图片带来的效果越明显
越是后面的步数,只是在原来的基础上进行修饰,无力去改变整体的一个构图
#### ControlNetv1.1
+ canny模型作用在1.1版本后会下降,有了更好的line art模型
+ scribble模型的预处理方法改为invert,web ui取消原本的反转颜色选项,直接打开无提示词,无需额外操作
越前面的步数,对整个图片带来的效果越明显
越是后面的步数,只是在原来的基础上进行修饰,无力去改变整体的一个构图
#### ControlNetv1.1
+ canny模型作用在1.1版本后会下降,有了更好的line art模型
+ scribble模型的预处理方法改为invert,web ui取消原本的反转颜色选项,直接打开无提示词,无需额外操作
 对于所有的Ctrolnet1.1模型,如果输入黑白线图,一律使用invert预处理器
scribble理解能力提高,最好搭配无提示词使用,使用无提示词模式时,可能导致图片饱和度过高或线条过粗,可通过降低CFG数值来减轻,该方法试用所有模型
对于所有的Ctrolnet1.1模型,如果输入黑白线图,一律使用invert预处理器
scribble理解能力提高,最好搭配无提示词使用,使用无提示词模式时,可能导致图片饱和度过高或线条过粗,可通过降低CFG数值来减轻,该方法试用所有模型
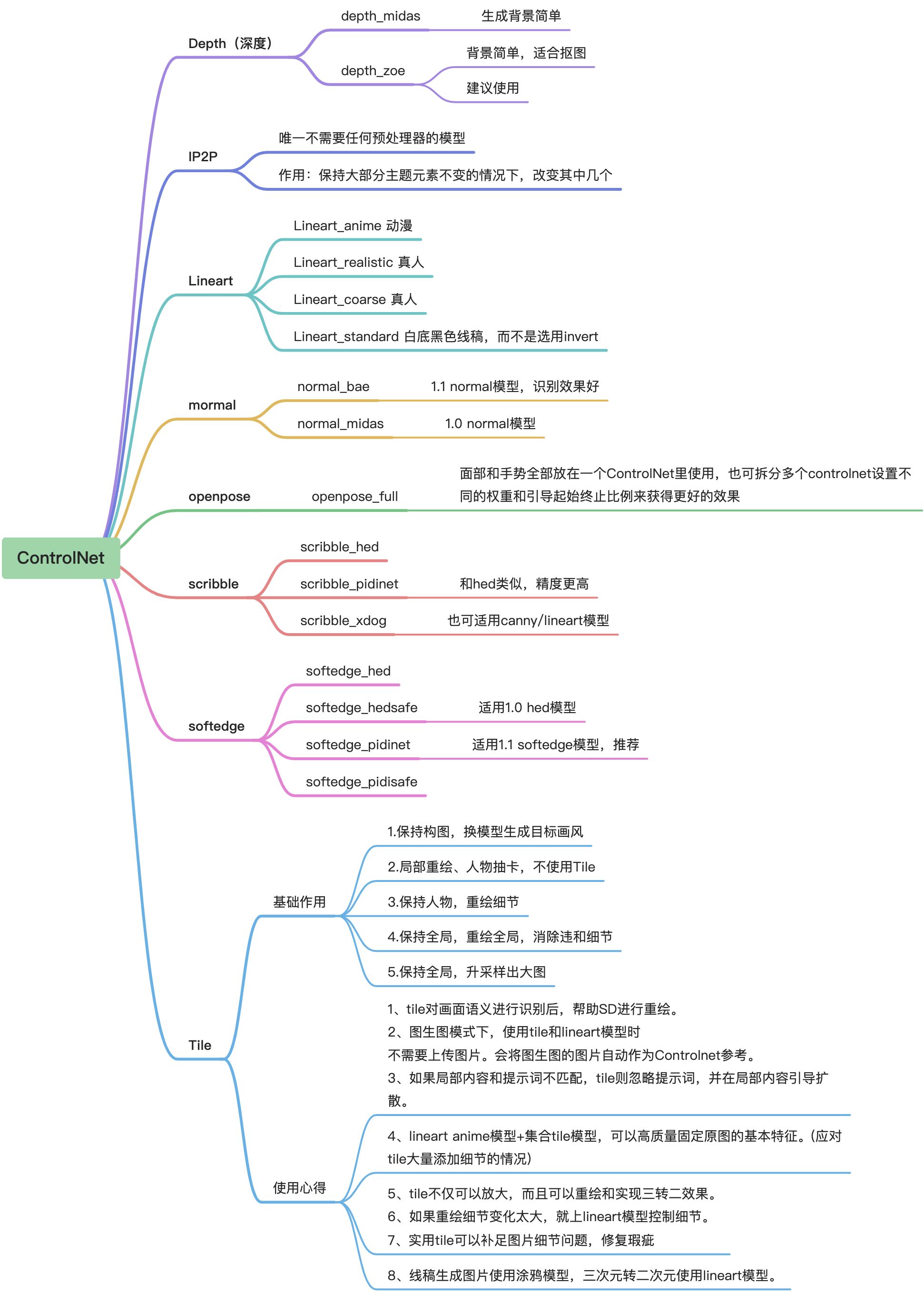


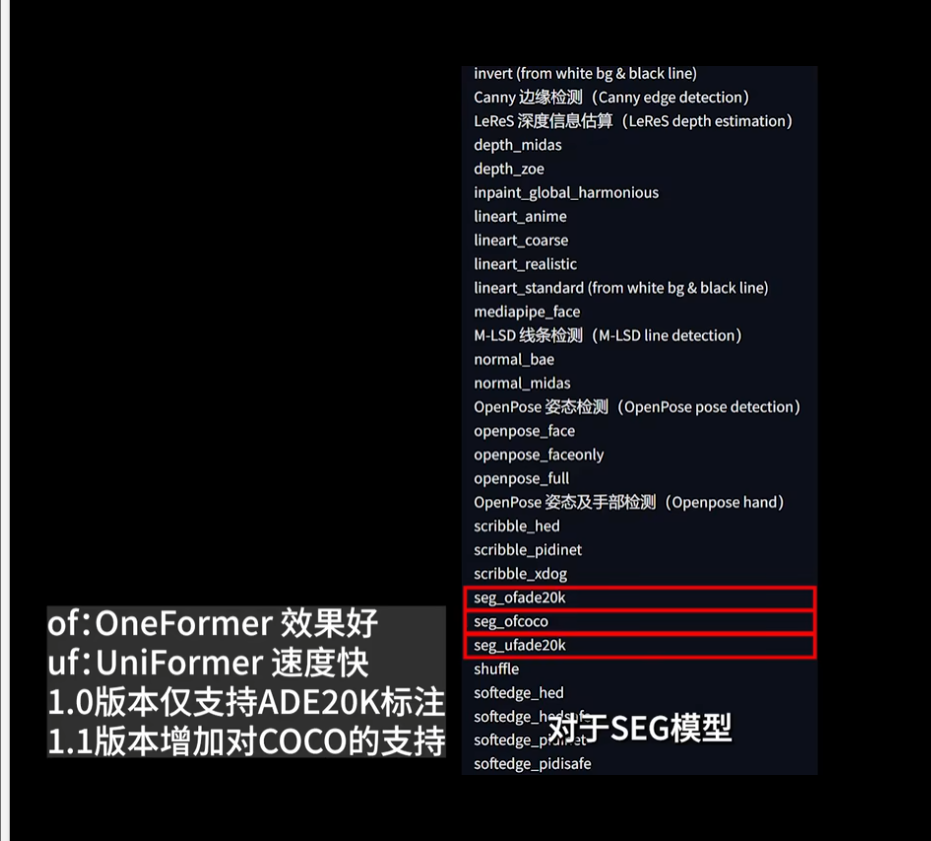

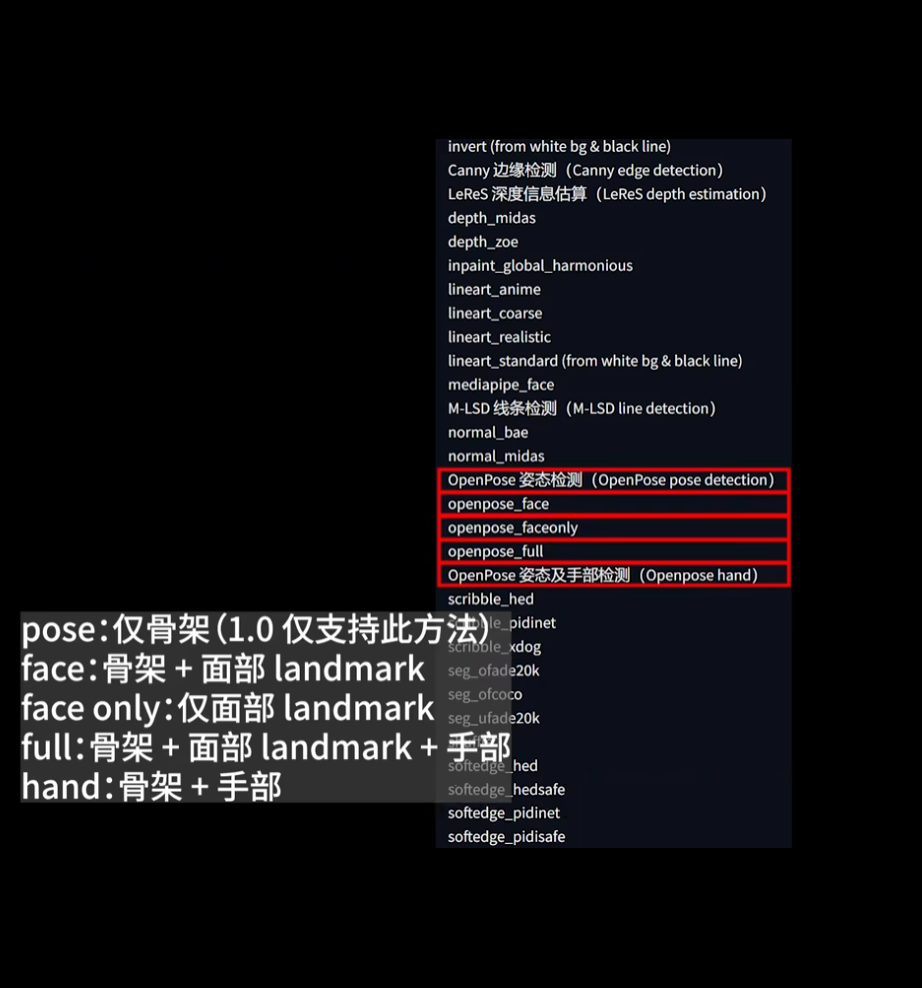 Shuffle
Inpaint
### 2.OpenPose编辑器
编辑人体姿态发生到文生图、图生图
### 3.Enhanced img2img
做序列帧动画
Shuffle
Inpaint
### 2.OpenPose编辑器
编辑人体姿态发生到文生图、图生图
### 3.Enhanced img2img
做序列帧动画

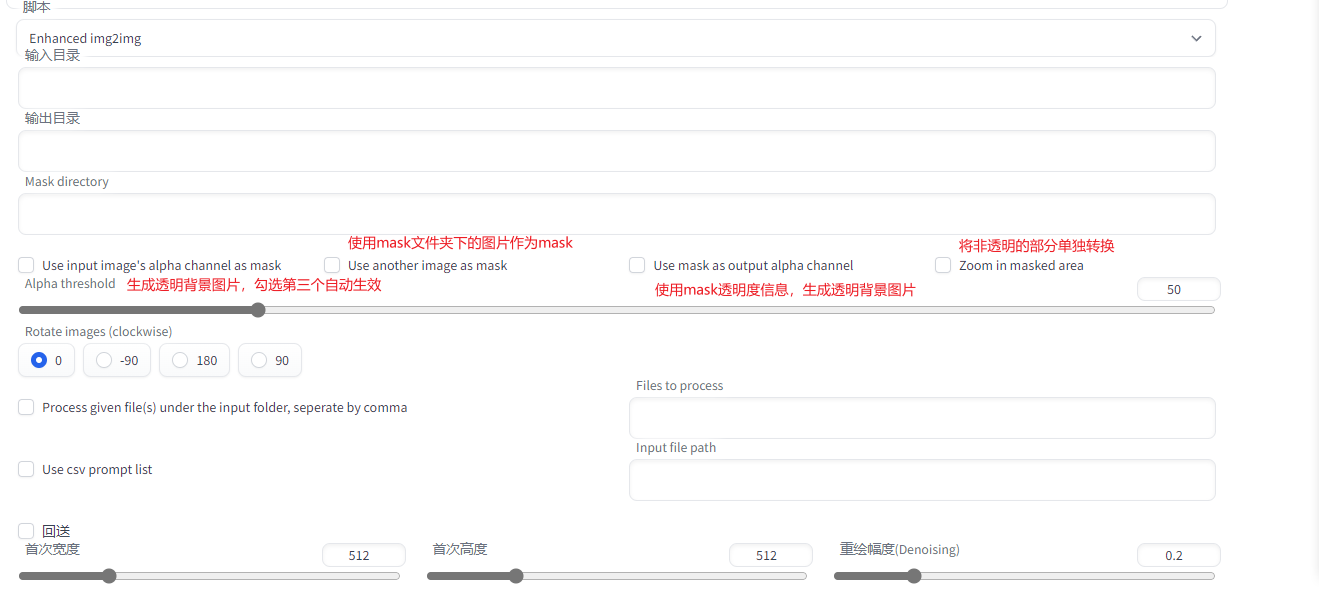


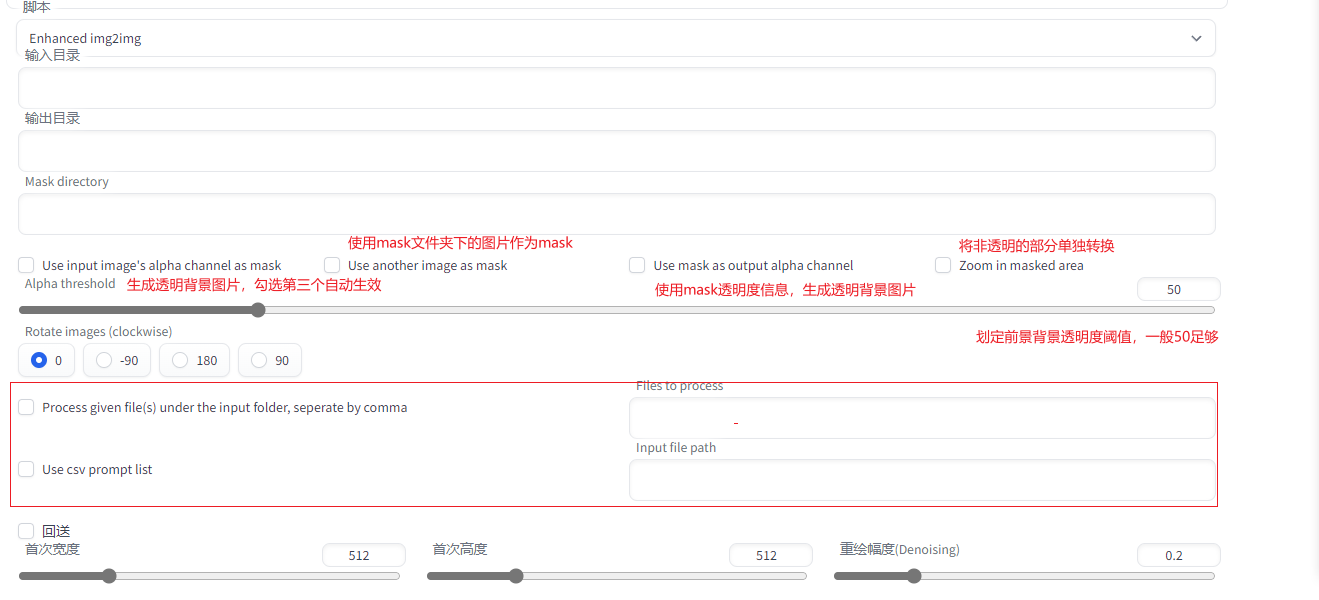
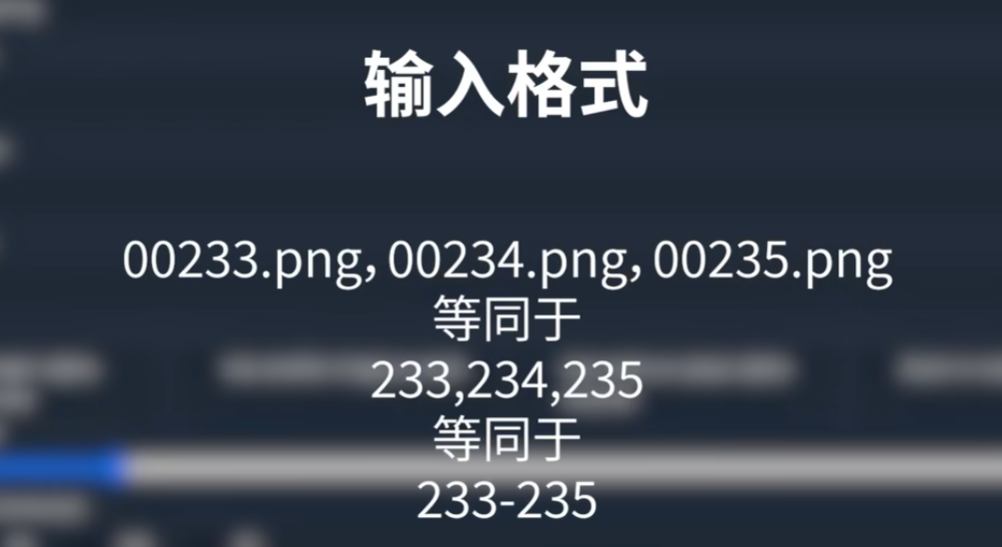
 ### 4.segment anything
注:上传蒙版与Controlnet序号对应
模型下载地址:https:github.com/continue-revolution/sd-webui-segment-anythin
模型存放地址:D:\stable diffusion\extensions\sd-webui-segment-anything\models\sam
### 5.Ultimate SD upscale
注:该插件在图生图里的脚本面板调用
1.不要开面部修复,会干扰SD的区块生成
2.重绘幅度不要太高,避免区块当中出现个体
放大算法
4x-UltraSharp 偏写实
R-ESRGAN 4x 适合平面
R-ESRGAN 4x Anime6B 适合动漫
放大模型下载地址: https://upscale.wiki/wiki/Model_Database
4x-UltraSharp放大模型(该模型适合写实)下载地址:https://mega.nz/folder/qZRBmaIY#nIG8KyWFcGNTuMX_XNbJ_g
模型存放地址:D:\stable diffusion\models\ESRGAN
图像三重放大
1.开高清修复高分重绘
原参数设置下导入重绘,重绘幅度不要过高,让分辨率在显卡承受的范围内尽可能地大
2.Ultimate SD upscale插件放大
放大后可根据需要不断局部重绘,同时根据需要运用Tile重绘添加细节
3.图片附加功能(后期处理)再次放大2倍
### 6.sd-webui-prompt-all-in-one
提示词补全插件(自动翻译)插件,支持翻译,收藏提示词等功能
https://github.com/Physton/sd-webui-prompt-all-in-one
### 7.sd-webui-qrcode-toolkit
二维码生成插件
https://github.com/antfu/sd-webui-qrcode-toolkit
### 8.adetailer
修脸神器
https://github.com/Bing-su/adetailer
### 9.C站助手
https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper
C站助手出现scan错误 无法正常使用的解决方案
C站助手最下面-其他设置-在开启科学上网的状态下,打开网络和Internet-代理-手动设置代理(把IP地址及端口号填入到C站助手的其他设置)
CivitAI Browser Plus
### 9.lora-prompt-tool
模型&lora触发词插件,能把C站案例图片提示词参数一键加载至SD
https://github.com/a2569875/lora-prompt-tool
### 10.https://github.com/huchenlei/sd-webui-openpose-editor
对识别的OpenPose在controlnet可以直接编辑(预览图右下角编辑按钮)
手的效果依然不好(插件作者表示手部的问题编辑器解决不了,得让Lvming Zhang去重炼ControlNet的openpose模型)
https://github.com/huchenlei/sd-webui-openpose-editor
### 11.Roop(换脸)
1.推荐模型BRA-V4大模型,适合亚洲人形象还原
2.图生图导入换脸的模特
重绘区域:整张图片
采样方法DPM,迭代步数适当调大30步以上
重绘幅度调小0.1
3.Roop插件导入要换脸的照片
面部修复:GFPGAN,Restore visibility (恢复能见度:决定换脸的相似程度) 0.9
4.解决不清晰:抽一张满意的图发送到图生图,关闭Roop,启用After Detailer选择一个逼真的面部模型face_yolov8m2D,重绘幅度改大,五官锐利清晰
5.Ultimate SD upscale放大
注:该插件在图生图里的脚本面板调用
1.不要开面部修复,会干扰SD的区块生成
2.重绘幅度不要太高,避免区块当中出现个体
## 四、案例
### 1.艺术二维码
模型选择:二次元总体表现优于写实风格
迭代步数取决于采样方法
人物类型开启Aditailer
预处理器:无,模型qr-monster
权重1.3-1.7(不同模型提示词有不同的权重)
心得:二维码美化不要过大,定位点不要设置正方形也不易过小,否则难识别
### 4.segment anything
注:上传蒙版与Controlnet序号对应
模型下载地址:https:github.com/continue-revolution/sd-webui-segment-anythin
模型存放地址:D:\stable diffusion\extensions\sd-webui-segment-anything\models\sam
### 5.Ultimate SD upscale
注:该插件在图生图里的脚本面板调用
1.不要开面部修复,会干扰SD的区块生成
2.重绘幅度不要太高,避免区块当中出现个体
放大算法
4x-UltraSharp 偏写实
R-ESRGAN 4x 适合平面
R-ESRGAN 4x Anime6B 适合动漫
放大模型下载地址: https://upscale.wiki/wiki/Model_Database
4x-UltraSharp放大模型(该模型适合写实)下载地址:https://mega.nz/folder/qZRBmaIY#nIG8KyWFcGNTuMX_XNbJ_g
模型存放地址:D:\stable diffusion\models\ESRGAN
图像三重放大
1.开高清修复高分重绘
原参数设置下导入重绘,重绘幅度不要过高,让分辨率在显卡承受的范围内尽可能地大
2.Ultimate SD upscale插件放大
放大后可根据需要不断局部重绘,同时根据需要运用Tile重绘添加细节
3.图片附加功能(后期处理)再次放大2倍
### 6.sd-webui-prompt-all-in-one
提示词补全插件(自动翻译)插件,支持翻译,收藏提示词等功能
https://github.com/Physton/sd-webui-prompt-all-in-one
### 7.sd-webui-qrcode-toolkit
二维码生成插件
https://github.com/antfu/sd-webui-qrcode-toolkit
### 8.adetailer
修脸神器
https://github.com/Bing-su/adetailer
### 9.C站助手
https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper
C站助手出现scan错误 无法正常使用的解决方案
C站助手最下面-其他设置-在开启科学上网的状态下,打开网络和Internet-代理-手动设置代理(把IP地址及端口号填入到C站助手的其他设置)
CivitAI Browser Plus
### 9.lora-prompt-tool
模型&lora触发词插件,能把C站案例图片提示词参数一键加载至SD
https://github.com/a2569875/lora-prompt-tool
### 10.https://github.com/huchenlei/sd-webui-openpose-editor
对识别的OpenPose在controlnet可以直接编辑(预览图右下角编辑按钮)
手的效果依然不好(插件作者表示手部的问题编辑器解决不了,得让Lvming Zhang去重炼ControlNet的openpose模型)
https://github.com/huchenlei/sd-webui-openpose-editor
### 11.Roop(换脸)
1.推荐模型BRA-V4大模型,适合亚洲人形象还原
2.图生图导入换脸的模特
重绘区域:整张图片
采样方法DPM,迭代步数适当调大30步以上
重绘幅度调小0.1
3.Roop插件导入要换脸的照片
面部修复:GFPGAN,Restore visibility (恢复能见度:决定换脸的相似程度) 0.9
4.解决不清晰:抽一张满意的图发送到图生图,关闭Roop,启用After Detailer选择一个逼真的面部模型face_yolov8m2D,重绘幅度改大,五官锐利清晰
5.Ultimate SD upscale放大
注:该插件在图生图里的脚本面板调用
1.不要开面部修复,会干扰SD的区块生成
2.重绘幅度不要太高,避免区块当中出现个体
## 四、案例
### 1.艺术二维码
模型选择:二次元总体表现优于写实风格
迭代步数取决于采样方法
人物类型开启Aditailer
预处理器:无,模型qr-monster
权重1.3-1.7(不同模型提示词有不同的权重)
心得:二维码美化不要过大,定位点不要设置正方形也不易过小,否则难识别
 对能识别的图片进行色阶或者对比度调整,原理和brightness模型类似,但更可控
(提示词参考:抽象,奇幻的超现实主义名词)
对能识别的图片进行色阶或者对比度调整,原理和brightness模型类似,但更可控
(提示词参考:抽象,奇幻的超现实主义名词)
 ### 2.电商产品合成
midjourney输出背景图,sd融合产品,ps beta修改细节
### 3.图片扩图
每次只调整宽或高度,ControlNet导入原图,
控制类型:局部重绘
预处理器:inpaint_only+lama
控制模式:ControlNet is more important
缩放模式:resize and fill
## 五、场景落地
1.线稿上色&线稿生成
### 2.电商产品合成
midjourney输出背景图,sd融合产品,ps beta修改细节
### 3.图片扩图
每次只调整宽或高度,ControlNet导入原图,
控制类型:局部重绘
预处理器:inpaint_only+lama
控制模式:ControlNet is more important
缩放模式:resize and fill
## 五、场景落地
1.线稿上色&线稿生成
 2.画风转变
3.三视图
2.画风转变
3.三视图
 4.产品设计(鞋子、耳机…)
5.建筑设计&室内设计
4.产品设计(鞋子、耳机…)
5.建筑设计&室内设计
 6.小图无损放大
7.数字人定制
8.AI换脸
9.视频转换
10.鞋子上身,包包上身
11.产品替换
12.模特换衣
6.小图无损放大
7.数字人定制
8.AI换脸
9.视频转换
10.鞋子上身,包包上身
11.产品替换
12.模特换衣

 ## 六、学习路径
1.插件教学
大江户战士的个人空间-大江户战士个人主页-哔哩哔哩视频
2.资源整合
秋葉aaaki的个人空间-秋葉aaaki个人主页-哔哩哔哩视频
独立研究员-星空的个人空间-独立研究员-星空个人主页-哔哩哔哩视频
3.模型训练
青龙圣者的个人空间-青龙圣者个人主页-哔哩哔哩视频
WSH032的个人空间-WSH032个人主页-哔哩哔哩视频
4.资源
快速细化:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
## 六、学习路径
1.插件教学
大江户战士的个人空间-大江户战士个人主页-哔哩哔哩视频
2.资源整合
秋葉aaaki的个人空间-秋葉aaaki个人主页-哔哩哔哩视频
独立研究员-星空的个人空间-独立研究员-星空个人主页-哔哩哔哩视频
3.模型训练
青龙圣者的个人空间-青龙圣者个人主页-哔哩哔哩视频
WSH032的个人空间-WSH032个人主页-哔哩哔哩视频
4.资源
快速细化:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111tag补全:https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
controlnet:https://github.com/Mikubill/sd-webui-controlnet
tag反推:https://github.com/tsukimiya/stable-diffusion-webui-wd14-tagger
c站助手:https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper/
骨骼编辑:https://github.com/hnmr293/posex
深度图编辑:https://github.com/jexom/sd-webui-depth-lib
七、探索延伸

若有收获,就点个赞吧
0 人点赞
