


一.写实人物面部和衣服类Lora
1.素材选取
1.不同面部表情
2.构图
3.人物特征
4.灯光
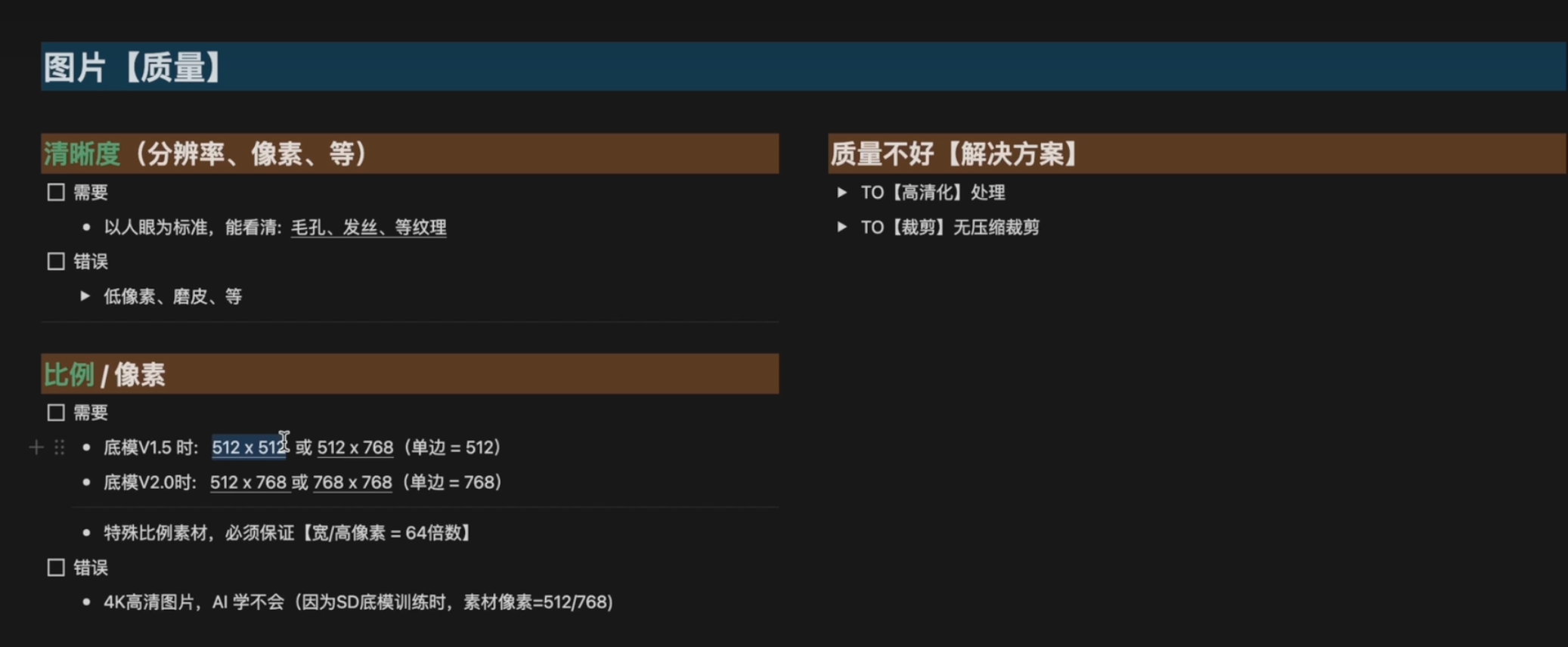
5.图片质量
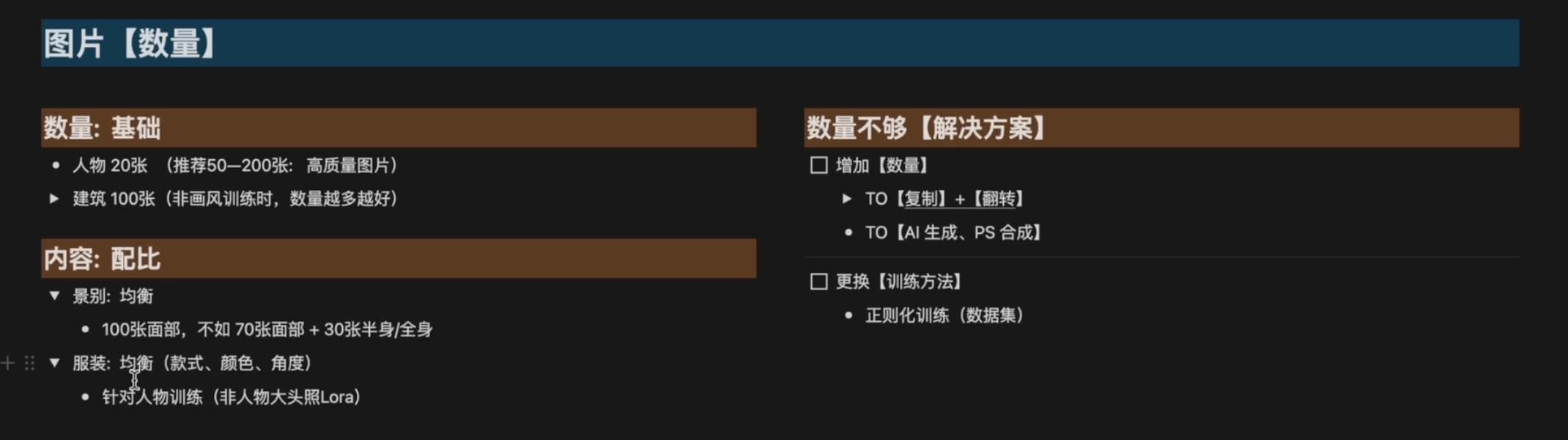
满足越多越好2.图片数量
简单主体(人物、动漫、面部等):至少15张图片
复杂主体(场景、建筑物等):至少100+张图片
3.训练步数
每张步数:Ai在训练时每张训练多少次,次数越多,细节越明显
最少10步(也不宜过高)以下仅供参考:
二次元:10-16步
写实人物:17-35步
场景:50步起
Lora训练总步数:1500-6000步
Checkpoint训练总步数:30000步起
4.显卡要求
N卡,显存8G或以上
512x512建议显存8G以下用户使用
768x768建议显存8G以上用户使用
5.部署
1.Kohya_ss(训练页面)
2.Additional Networks插件(秋叶启动器自带)
3.CUDNN训练加速器(30系以下请忽略)
4.参数预设(可不下载)

二、Lora人像训练-朱尼酱
工作流
素材准备-设参训练-XYZ测试-参数调优-再次训练
成熟Lora参考:小人书.连环画
可选附加网络(Lora插件),看训练的相关信息| 参数 | 数值 |
|---|---|
| Image | 121 |
| Repeat | 8 |
| Epoch | 20 |
| Unet Lr | 6e-5 |
| Text Lr | 7e-6 |
| DIM | 128 |
| Alpha | 64 |
| Lr_scheduler | Consine_with_reatart |
| Optimizer | Lion |
赛博丹炉建议放在D盘,一定不要放C盘,路径不能有中文
自己预先处理的数据集,手动存放目录:train/image/30_miren
1.Lora训练核心参数
| 通俗理解 | 参数影响 | 新手参数建议(人物) | |
|---|---|---|---|
| Image | 原素材、训练集 | 原图质量越高,模型质量越好 | 30张 |
| Repeat | 重复次数 | 次数多,学习效果好 | 清晰度低10,高20-30 |
| Epoch | 循环 | 循环多,学习效果好 | 10(根据loss可适当增加) |
| Learning rate | 学习率 | 学习率高,学习速度快 | 1e-4(初始loss下不去,提高学习率,loss过低,降低学习率) |
| Network rank Dimension | 学习精细度 | 精细度高,模型细节好 | 128/64(128细节更好) |
| Loss | 深度学习效果 | 值低,学习效果好 | 一般0.08左右Loss最优 |
2.Image(训练集)
1.原图分辨率越高越好(但更好的原图,对学习的参数设置越高,且不是越多越好)
2.素材尽可能丰富,覆盖不同光影、不同角度
3.Tag除了AI自动达标外,还需要手工调整、补充
3.Repeat(重复学习次数)
理论Repeat越高,AI更好读懂图片
但过高Repeat导致过拟合,对图片认知固化,过高Repeat需要更高算力,通常需要更多时间,训练效率低
4.Epoch (循环轮次)
Epoch=图片数量*Repeat
过多同样导致过拟合,对图片认知固化,过高Repeat需要更高算力,通常需要更多时间,训练效率低
5.人物训练参数
训练集数量20-30张(包含人物多角度)
Repeat 10-15(低精度)15-30(高精度素材)
Epoch 10-15(根据loss值)
6.Learning rate(学习率)
学习率高,更快得到好的Loss,但过高会导致过拟合
学习率低,学的更细,但过低的学习率导致不拟合(出图不像)花费时间更多
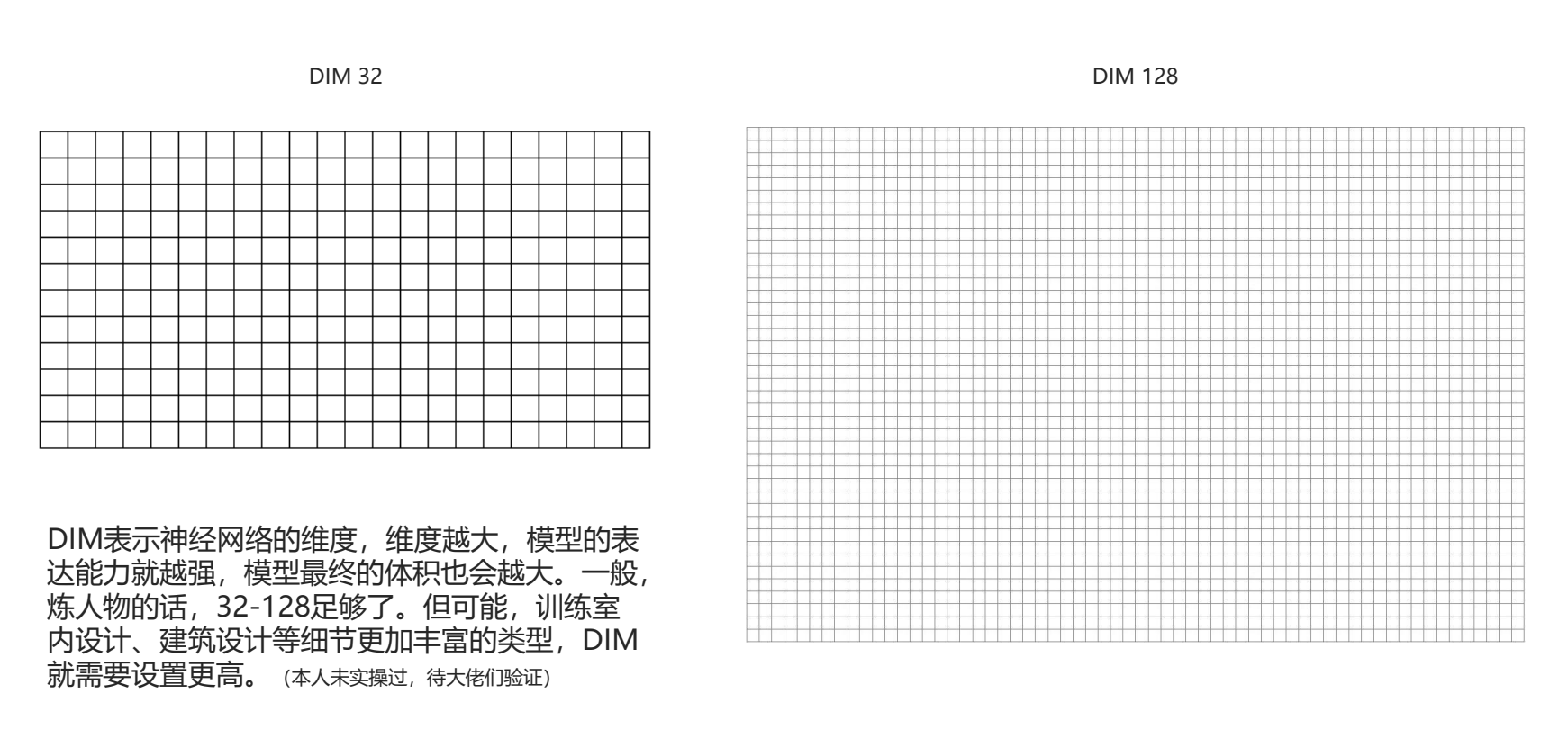
7.DIM(神经网络维度)
维度越大,模型表达能力越强,最终体积越大
人物一般30-128足够
8.实证数据
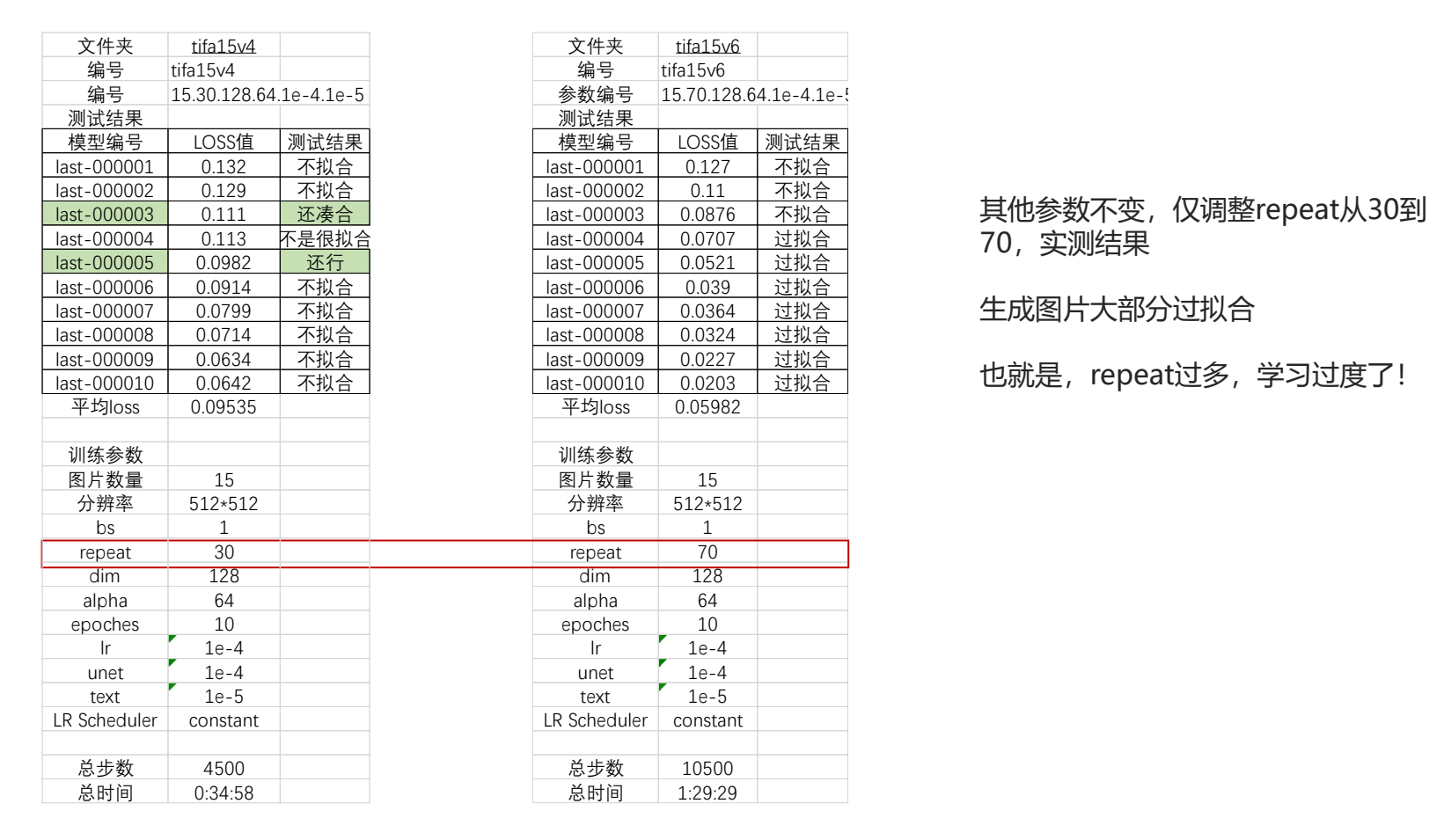
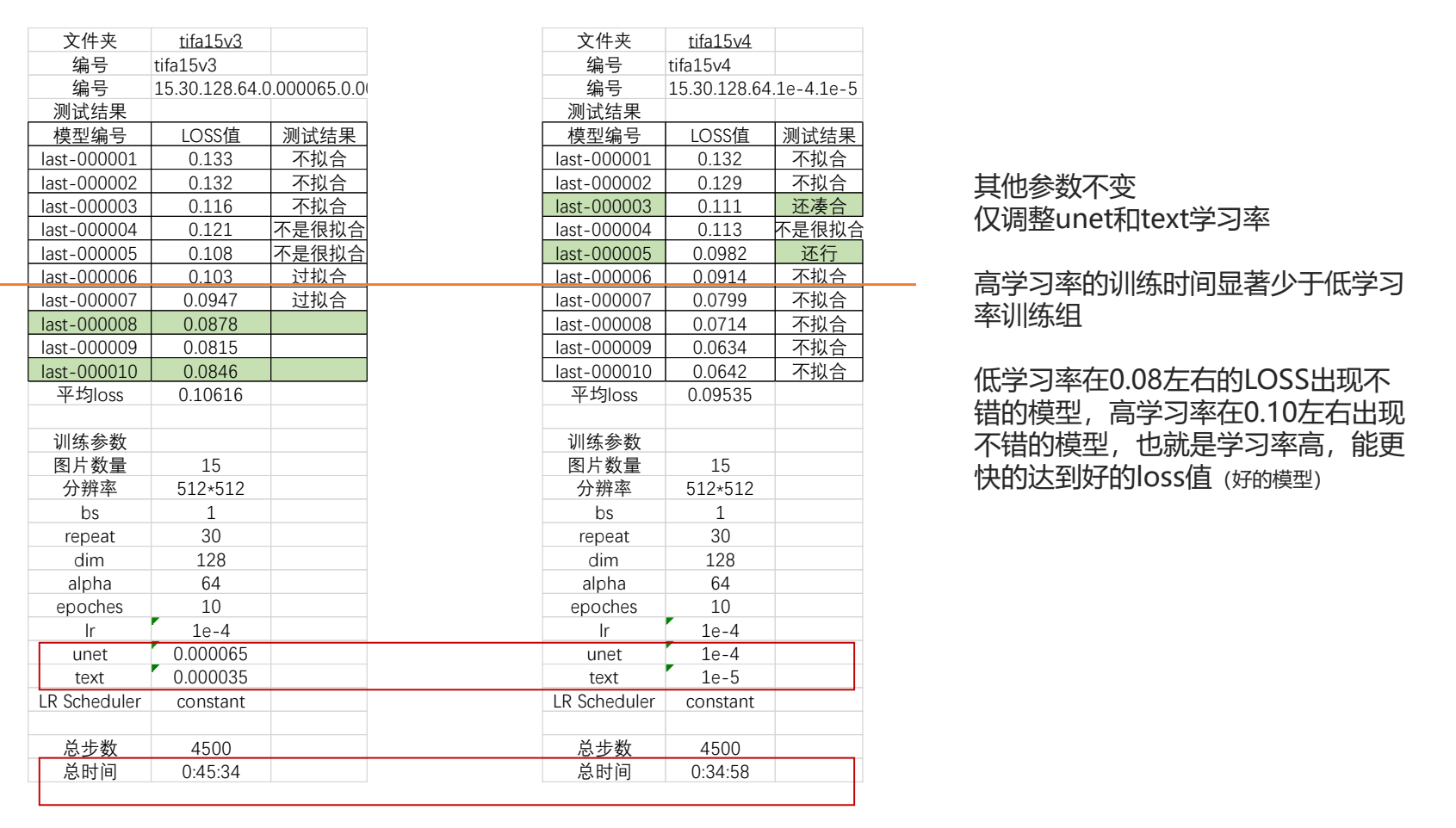

9.训练不像解决建议
1.调节repeat,让repeat的数量更高,学习更充分
2.或者适当降低一点学习率,把整个epoch的轮次放的更长,更加充分地学习
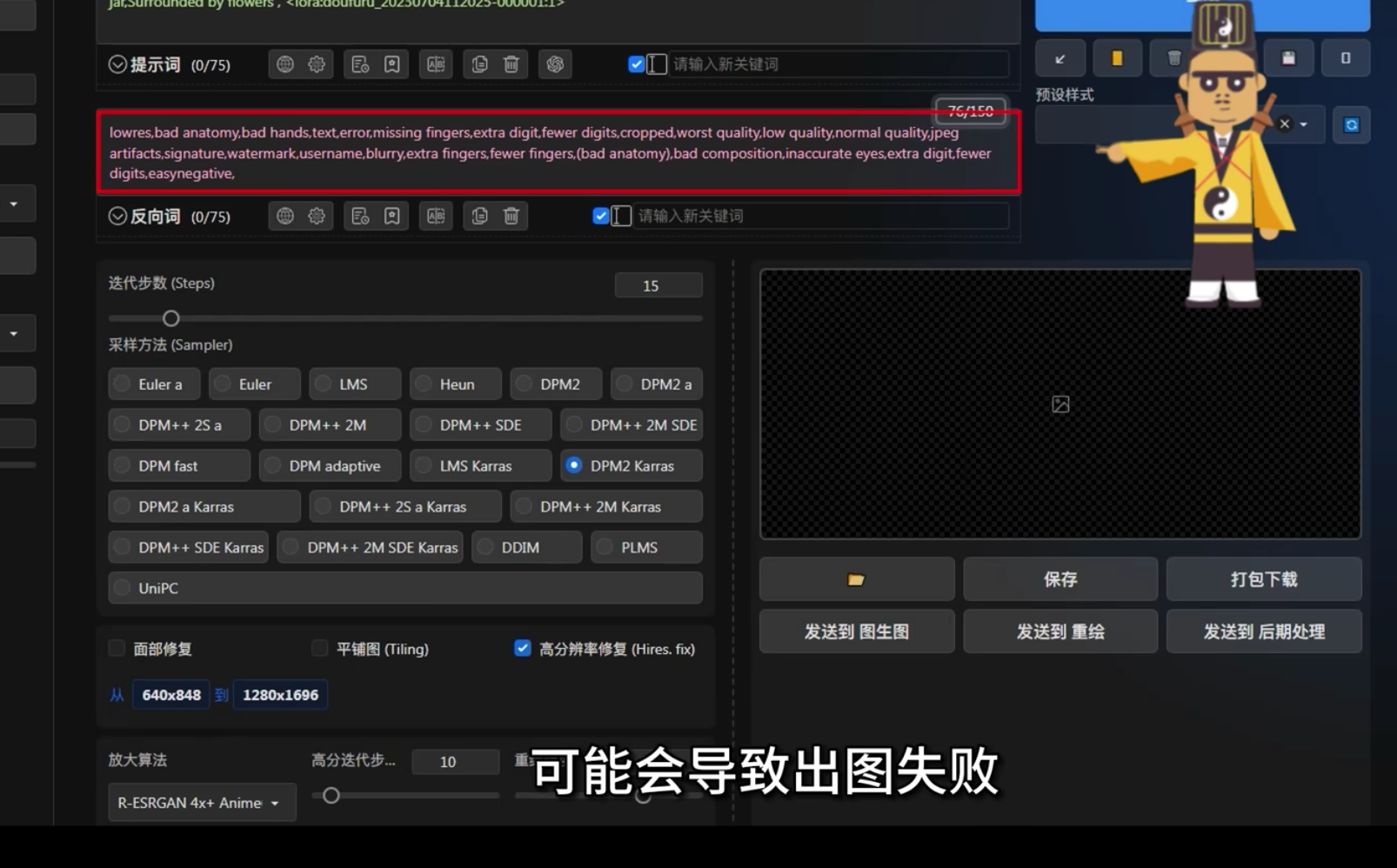
Offset Noise(偏置噪声)
使用场景
在训练风格、画风时使用
一般设0.1,不宜过大
不建议使用8bit Adam意以外的优化器,极难调参
在训练人物、物体或概念时无需使用,作用不大
kohya_ss位置
Dreambooth LoRA——Training parameters——Advanced Configuration(下拉至底部展开此项)-Noise offset(0-1)
作用:
提高画面饱和度,能够画出更明亮、更暗的场景,效果类似Midjourney
Lora选底膜
一个好的Lora,Loss值大概率在0.1以下,大概90%的相似度
https://huggingface.co/alea31415/LyCORIS-experiments
1、底模选择要和训练集风格接近(真人找真人模型,二次元找二次元模型)。2、训练模型比合成模型泛用性更好,合成模型在细节相似度上可能表现更好。
3、二次元用NAI、AC、BP、NFMSAN这4个泛用性比较高,三次元没有更多测试,但是类似的上游元祖模型比较好。比如chillmixout的上游模型是basil以及chillgenV2
4、同类型的模型训练出来互换效果更好,比如水彩换水彩、2.5D换2.5D、3D换3D,2D换2D
素材集选择
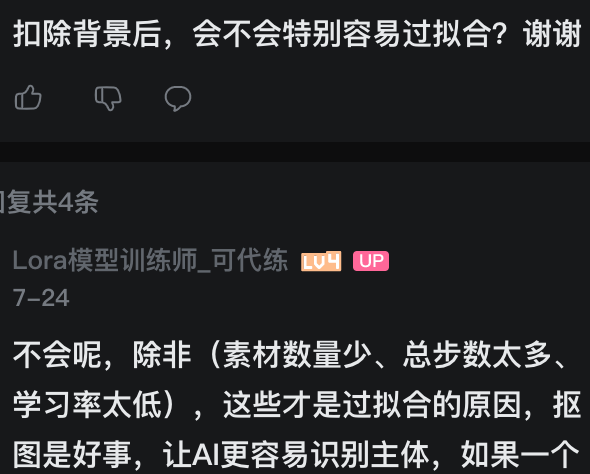
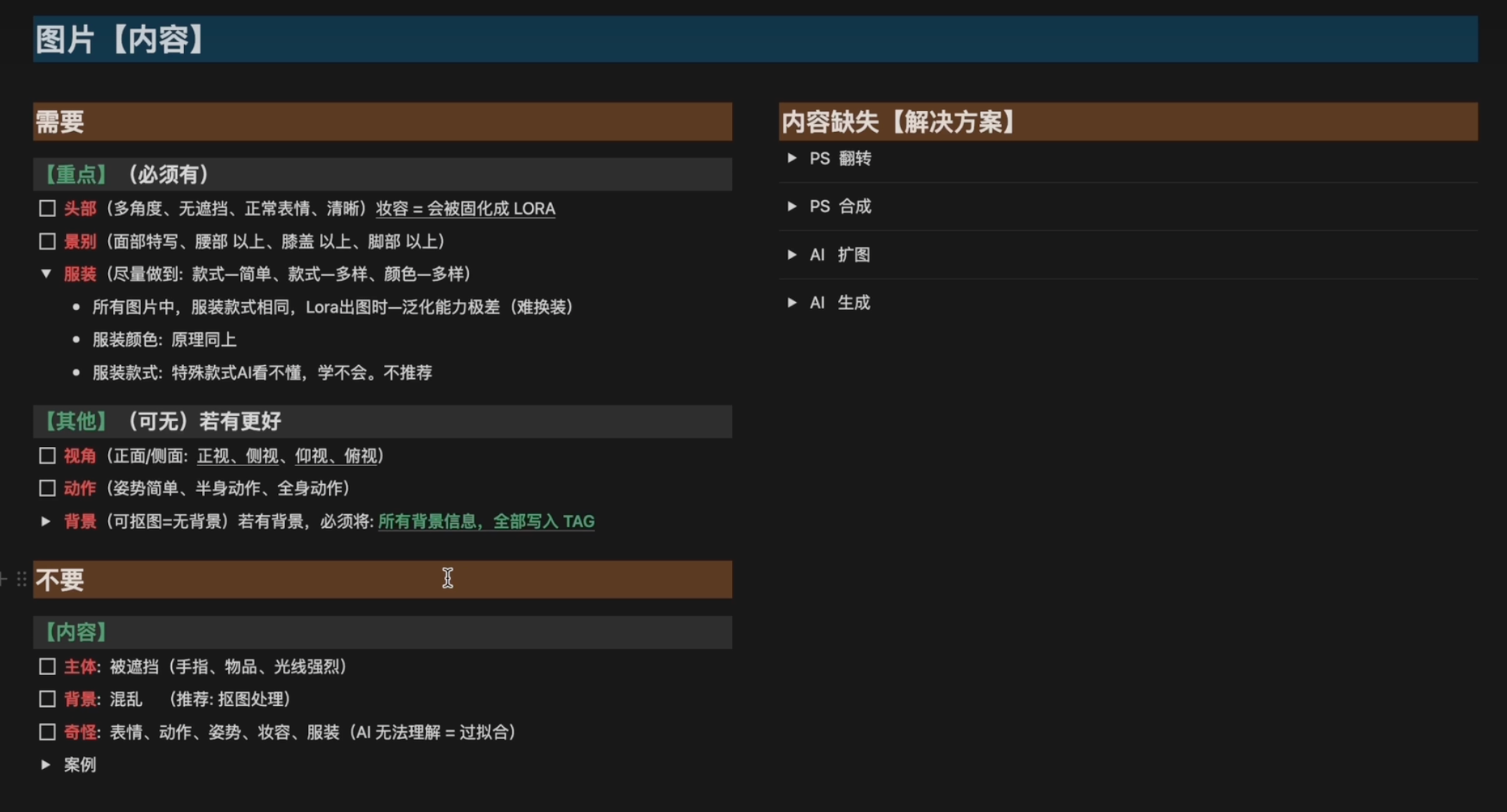
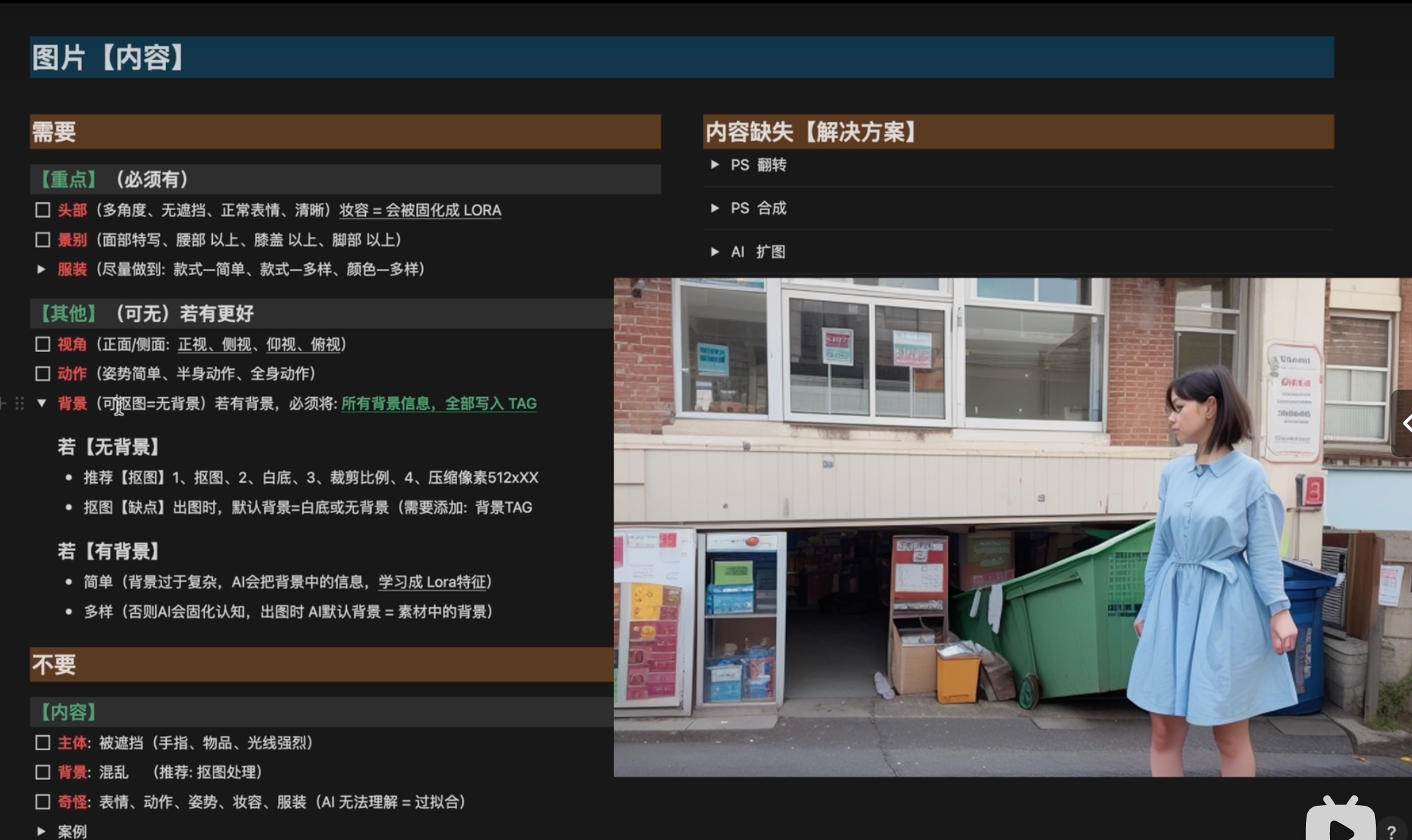

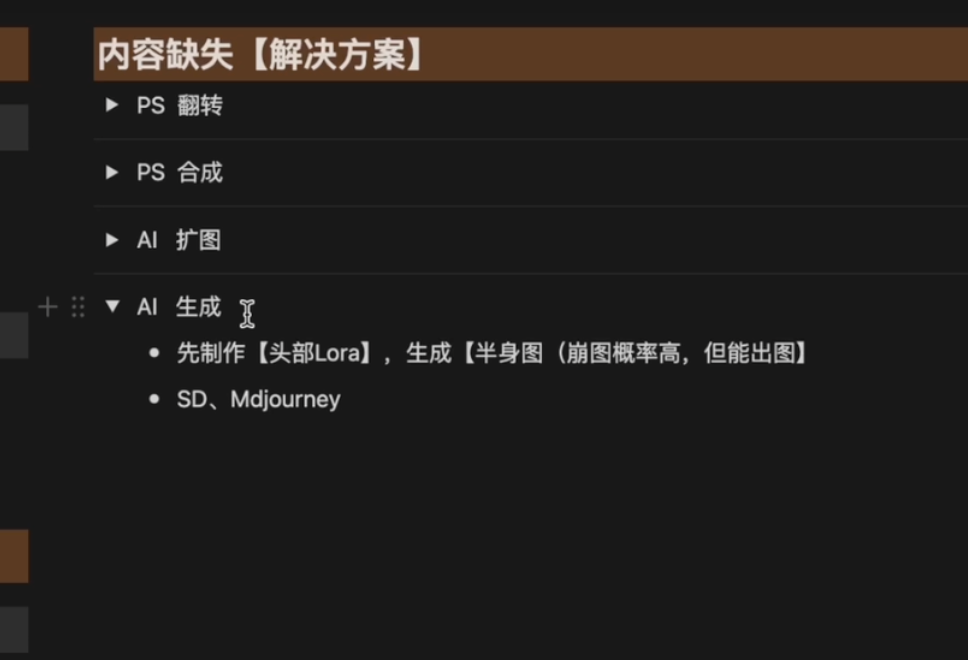
内容缺失解决方案
1.PS翻转or美图秀秀
2.PS合成(别人的不同景别不同服装,拼接人脸即可)
3.AI扩图
4.AI生成
打标Tag
想要固定某些特征,打标的时候删除,想要某些特征,在打标的时候添加它
需要控制的特征tag必须打清楚,比如衣服颜色,要把衣服的每个部分分别描述清楚,袖子、衣襟、领口,诸如此类。
元素乱飞,说明语义和图像的匹配不好,特征不可控。主要是tag没打好导致的,你好好精修下tag,尽量打完整。
如何训练底膜

3.角色模型Lora
心态:七分训练集、两分调参数、剩下看天意
工具:秋叶训练器
1.图片挑选(按重要性排列 ):
1.图片要清晰
2.主体特征要明显(不要残缺或遮挡)
3.大头照/半身/全身(不同镜头距离下的还原)
4.不同角度
5.不同姿势与动作
6.丰富表情(追求还原度)
ex.少量不同画风(增加泛化性)






2.训练集的预处理:
1.统一格式:jpg或png
2.剪裁与缩放: 新手512512 或512768 或768*512
3.清理与加工:水印?logo?色彩饱和度和对比度修正
4.抠图 (部分):什么情况下要枢,什么情况下不用?
5.最终检查
3.训练集打标
自动打标: WD1.4标签器 (推荐)
聪明的AI为我们先打一轮标人工打标:BooruDatasetTagManager (别的也可)
删掉重复与错打的标,补充漏打或希望添加的标
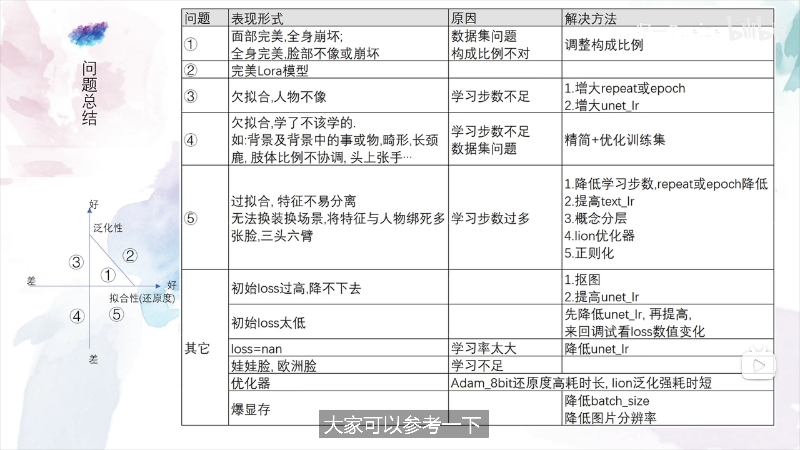
若有收获,就点个赞吧
0 人点赞
