运用SD细化工具进行高效工作流(一)_卡昂卡昂-站酷ZCOOL

大家好,我是卡昂卡昂,很高兴为大家分享我自己个人的一些AIGC工作流经验,以下的内容源于我近几个月来跑通的一些实验结果,本篇教程主要在于从思维讲解/功能介绍/案例解析三个方面系统的整合了AI在我们工作中的应用流程。或许会为想了解AIGC,但面对碎片化知识无从下手的朋友有所帮助。
前言:一位3D设计师,从0-1做一张类似封面图中符合IP设定和质感的3D形象(3D设定源于我为哔哩哔哩电竞创作的IP插画)需要多少时间呢,也许要一周左右或者更久。而我完成它只用了4-5个小时,它的制作来自于Stable diffusion。其实在十分钟左右时,就已经完成了它百分之九十的效果,剩下的所有时间都是在修正和调整那百分之十的细节。在本文章,我会以它为案例拆分讲解创作过程。
⭐注意1:本文中出现的AI项目案例,均为个人实验结果,非官方出品。
⭐注意2:这并不是是一个纯操作类教程,本文中内容术语可能会对未实操过AI软件(尤其SD)的朋友来说有些晦涩,建议不理解内容的同学可以先到B站看下秋葉aaaki,大江户战士等UP主的教程。

一.AIGC应用逻辑的思维讲解

1.**探索AIGC工作流经验**
先说观点:一个拼审美的时代即将到来,对脑洞创作者来说,AI会增加他们的实现方式与效率。

(1)我认为AIGC的未来应用会分为工作流(专业级)与壁纸流(大众级),对设计师来说,如果没有足够的审美和设计功底来驾驭AI,那它只是一个壁纸连连看生成器。
(2)AI未来应该会细分为很多方向,我个人实验和学习的为Ai可控流,以Stable Diffusion为主要深耕方向,我认为只有稳定可控,可预见效果的Ai才能真正的不再局限,加入工作流之中。
(3)对参数和数据敏感的设计师会更容易上手。也就是除了美术功底,审美,工作方法论经验等传统设计师要求外,或许未来会增加数据敏感度这一要求。也就是个人不认为Ai会降低行业门槛,反之,对于未来职业设计师的要求会更高。
(4)人工与智能的合作关系:因为SD(Stable Diffusion)的开源属性,所以我个人认为它可能会是未来设计师应用的主流。即在商业流程中会演变为:前期草图提案给甲方确认(人工)-中期Ai细化生成(智能)-后期修改和应用排版等(人工)。使Ai成为帮助设计师不受风格与技能的限制,提高工作效率的良性工具。
2.主流AIGC软件中SD与MJ的区别
我们目前设计师主流应用的AI软件为MJ(Midjourney)与SD(Stable Diffusion)我个人认为它们主要的区别在于这四点

(1)应用方向:MJ出图更概念性/SD更可控(可控也就意味着有可能没控住,造成画面崩盘,参考第三点的数据,而MJ无论怎么出图,都一定是美的,好看的,从视觉上合格的,只是因为它的不可控,这种美很多时候无法合适的应用在工作之中)
(2)经济成本:MJ收费(10-60刀每月)/SD免费
(3)出图质量:MJ60-90分/SD10-99分
(4)时间成本:MJ上手容易,操作简单/SD入门难,操作复杂
以上的区别和对比,并不是为了“踩一捧一”,探讨软件的优劣性,而是了解不同软件的 特性后,在合适的场景去选择合适的应用。软件只是工具,不要局限,结合使用不同的工具实现1+1大于2的目的。
人们的生活中需要美学,它影响着人们的方方面面,从产品,服饰,游戏,科技,电影等,一个社会的美学展现也代表了当代社会文化的映射。美不局限于一种符号,创作美的方式也将不再局限与某个软件,我相信AI会带来更多机遇和可能。
3.SD工作流方向示例
由于平台,软件,应用方向的不同,我认为AIGC会催生出很多不同的流派,在大多时候,设计师只需要深耕其中适合自己行业应用场景的某几类就能得到不错的提升。以下我举几个能实际对工作流产生意义的示例。

1.游戏素材类:用简单的线稿来生成精致的3D游戏人物素材(效率提升,质感提升)
2.上色细化类:用controlnet工具使黑白线稿一键多方案上色细化(效率提升,方案提升)
3人物模特类:用人物模型搭配lora生成免费模特素材(效率提升,成本降低)
4.3D转化类:用平面插画生成结果可控的3D效果图(效率提升,技能提升)
5.画风转换类:用个人风格的底图生成适合不同项目风格的需求效果(效率提升,技能提升)
6.其他:还有很多可开发的工作流方向,他们的结果基本于两个方向:提高效率和实现技能。
4.个人SD 实验作品讲解
对于AI的工作流应用需要用实验来验证,靠【想象】,【以为】,很容易碰壁。但只要某项类别的流程跑通后,它的效率有望是传统工作流的10-100倍。我个人认为,AI使我可以不再局限于风格,不再局限于技能,即思维创意,美术功底,审美和工作流经验会决定产出的上线。把细化交给AI,让设计师回归“设计”。
以下是我个人跑通的一些实验作品

案例1-《电子水母》
这是一张用SD图生图进行3D转化类的工作流实验作品,左边是我之前为哔哩哔哩电竞IP形象所设计的延展海报。它的完成度是一个勾完线铺了底色的一个扁平细节状态,我称这个完成进度为【概念图】。右边是用概念图生成的3D效果图。
1.我认为SD软件与概念图是一个互相影响的关系,就像正负极磁铁一样,你调整软件操作就会影响出图效果,同样调整概念图也会在软件内收到反馈。但是大部分教程都在教授软件的知识,忽略概念图的影响。因为在软件界面里,有着繁杂的操作按钮,你点击它们就会给你反馈,这很好具象化。但对于概念图,却无从下手。其实我们可以通过几个注意点来用概念图控制出图效果。

👈概念图与SD生成的3D图👉

2.图生图概念图的注意点:SD图生图会根据图案/结构线分割来识别物体,清晰的线稿与底色会直接影响效果。概念稿底色与Ai产出颜色直接相关,因此可改变概念图颜色来控制画面颜色,要比在SD软件中调整快得多。
概念图的元素设计需要有逻辑性:我们把世界分为三个层级【我们的世界-AI的世界-模型的世界】,在设计概念图和写tag时,我们需要去理解这三个世界。
⭐(1)我们的世界:这里包括一切。我们所能看到想到的一切内容,但是AI的内容库里不一定有。举个例子:一个外形是正方形的足球。或许这是某种独特的设计,但是SD不会把一个正方形联想到足球(除非打了特定的lora)
⭐(2)AI的世界:SDAI能够识别出的tag和AI所存储的图像库。(可以在danbooru tags中对照词条)
⭐(3)模型的世界:模型作者在训练模型时所提供的素材库,当你的概念图和素材库的内容类别对应,就很容易出效果。同时,当你的概念图里的某些部分(例如耳机)在A模型里识别效果不好,就可以换B模型来重点识别此内容,如果效果提升即说明B模型中拥有大量优质的耳机类素材库(其他内容同理)
因此,概念图的设计需要摒弃“我世界”的思维。去理解AI世界并且针对我们要用的AI模型来设计画面内容,这样的效率最快,质量最好。
同时,我们也注意到模型和lora的重要性。如果拥有针对工作项目去训练特制的AI模型和lora的能力,将大大提升“应用范围”。

3.【人工】与【智能】的合作关系
因为SD的开源属性,我认为未来会有两波人与AiGC的工作流密切相关。1.训练和开发Ai的人,例如公司专有模型,lora,插件等。并且,特定工作流应用内容的模型和lora或许会被开发者售卖,但模型质量会和开发者的水平一样参差不齐,这个门槛深度足以拓展出一个职业来,如果某款模型会对某类工作内容提高百分之五十的效率和细节,那它的市场会非常大。2.实验Ai使用经验的人,例如开发控制流模式,不同风格,不同行业,都会有针对性的工作流经验。这两者就类似发明和改造钢琴的人与写乐谱的音乐家一样。他们会互相促进AIGC的迅速发展。

案例2-《三国题材人物实验》
下图我用SD图生图模式做的国风类生成实验,用P2的扁平线稿生成P1的细化效果。解决了两个问题:效率和技能。效率提升或许是百分之九十,同时,因为我对写实类人物插画并不擅长,这对我来说也是一次“技能提升”。
1.我认为这次实验 不止验证效率和技能的提升,还有一个或许被大多数人忽略,但是对工作流来说至关重要的点:【人设还原】,我们可以看到P1与P2右边的人设图还原度是比较高的,这验证了sd图生图的结果是可预估,可控的。
我个人的实验最大目的是追求AI的可控性,也就是:画面中所有的细节都可调整-可控制-可预估。


2.概念稿来源为我之前为《三国杀》項目创作KV时,用游戏角色人设来延伸的前期铺色图,分别为【曹操和赵云】。目前主要两个问题:1.部分的细节还不够完善2.人物脸部不符合游戏里人设的脸,这个问题是因为大多数模型是以外国人来融图的。解决问题办法有两个:1.人工后期修图(单次使用)2.提供赵云,曹操的清晰面部三视图来训练LORA,即可永久解决此问题。


案例3-《小电视宇航员》
看到这里或许有的同学会说上面用概念图控制Stable diffusion图生图的实验里“概念图太复杂”,门槛太高,那就来点“简单”的。
1.关于版权:因左边概念图设定为我之前为哔哩哔哩电竞所设计的企业IP形象的延展图,所以此IP的AI图生图生成图版权归属与哔哩哔哩。
2.在这个过程中,SD和c4d,blender一样,起到的是“技能和软件”的作用,而结果是取决于使用它的人。设计师的审美,脑洞,产品理解,品牌思维等等。这些靠项目经验积累来的知识,依然是稀缺品。无论你用AI还是用别的,最终的产出都是为了符合这些定位。这也是我认为AI不能取代设计师的原因,如果你有这个顾虑,或许在目前的工作定位上,过于“工具化”了。这是一个值得思考的问题。
3.AI会降低大众级,壁纸流的创作门槛,但综上所述,我个人不认为Ai会降低行业门槛,而是对未来“职业设计师”的要求会更高。就像《人人都是产品经理》这句话是绝对正确的,但是产品经理却是很高门槛的一个职业。

4.简单讲解下过程:我把决定结果的要素分为【稳定】和【细节】两个数值。这个数值并不存在于软件界面中,而是你对生成图片的逻辑判断,把每一次图生图根据画面在大脑中数值化。其中,在概念稿时,稳定值为1,细节值为0。AI生成所产生的效果对稳定值产生负【-】影响,对细节值产生正【+】影响。例如,在AI生成之前,我的概念稿数值为【稳定1,细节0】。我希望的最终结果是【稳定1,细节1】。那么在一次AI【改变0.2】批量生成后,产生的图为【稳定0.8,细节0.2】,然后我选用其中满意的一张图对它进行修改,使这张图变为【稳定1,细节0.2】,然后用修改后的图再用AI【改变0.3】批量生成,产生的图为【稳定0.7,细节0.5】,再重复上述的过程,直到最后的图为【稳定1,细节1】,最后在后期调色,修饰,排版等成为完整的工作流。

 ### 案例4-《孝康的IP对照组实验》
是否我只能控制自己画风和内容的生成效果?这个案例为验证SdAI图生图转换结果不受概念图画风限制的对照组实验。
在取得了geigei:孝康的授权后,我用他的插画为概念图进行了一次3D效果转换
本案例IP版权归@PS孝康所有
1.如前所说,因插画与AI/3d在“世界逻辑”上有区别,因此需要「在画概念稿时就设计好逻辑的合理性」,举例:p2的原稿中,左边的翅膀与右边的飞行器颜色和质感一致,所以会被识别成一个物体,所以后面我把左翅膀去掉了,诸如此类会产生一部分修改时间。
### 案例4-《孝康的IP对照组实验》
是否我只能控制自己画风和内容的生成效果?这个案例为验证SdAI图生图转换结果不受概念图画风限制的对照组实验。
在取得了geigei:孝康的授权后,我用他的插画为概念图进行了一次3D效果转换
本案例IP版权归@PS孝康所有
1.如前所说,因插画与AI/3d在“世界逻辑”上有区别,因此需要「在画概念稿时就设计好逻辑的合理性」,举例:p2的原稿中,左边的翅膀与右边的飞行器颜色和质感一致,所以会被识别成一个物体,所以后面我把左翅膀去掉了,诸如此类会产生一部分修改时间。



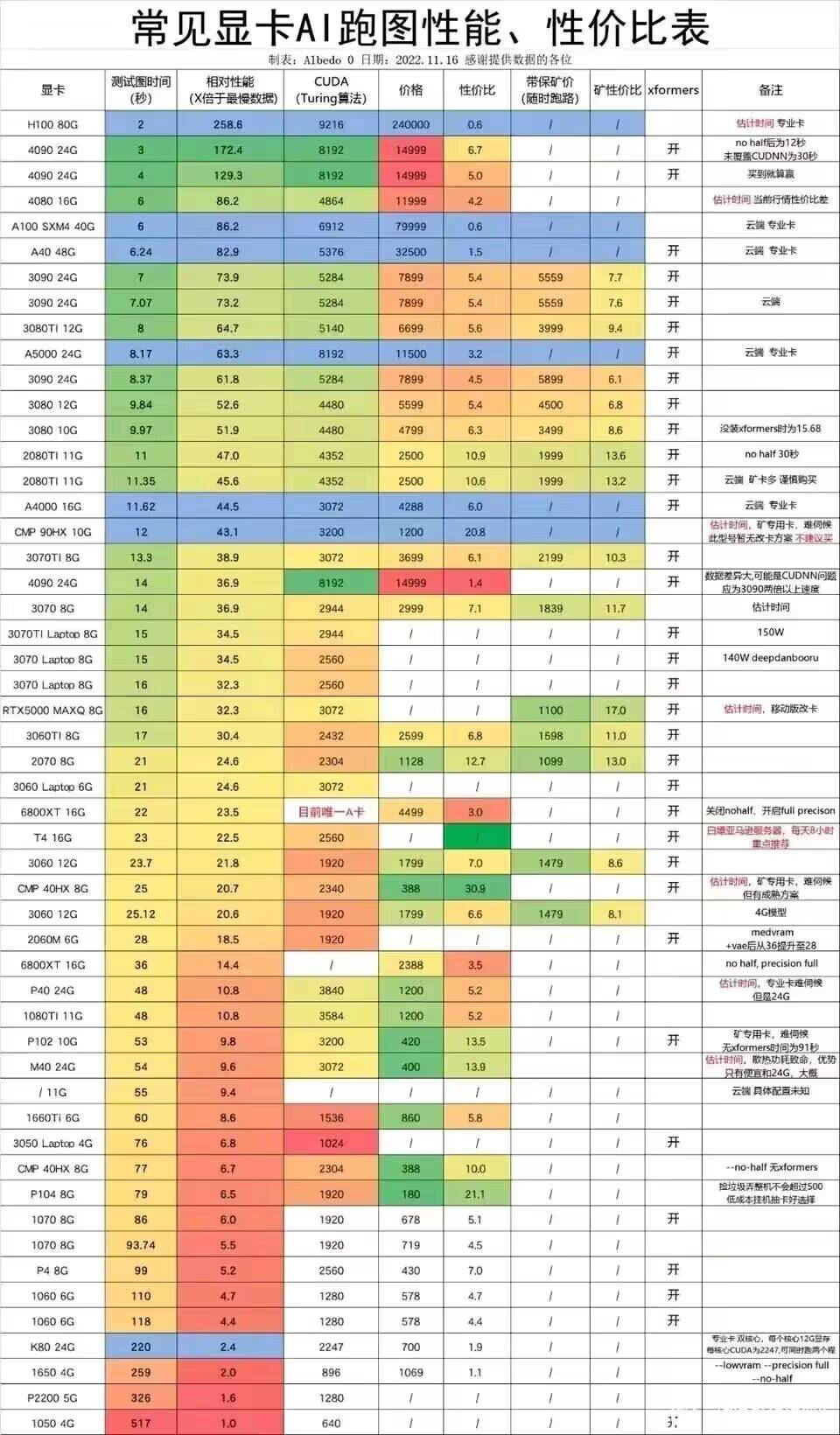
 2.拥有一台配置高的电脑:很多人有个误解,就是Ai对电脑配置要求不高,这是错误的。配置主要体现在两个方面:
显存:显存决定了你出图的精度「分辨率上限」
显卡性能:性能决定你出图的速度「好性能两三小时的产出差性能可能要两三天」
👇以下是显卡AI跑图性能性价比表 / 提供制表人:albedo
2.拥有一台配置高的电脑:很多人有个误解,就是Ai对电脑配置要求不高,这是错误的。配置主要体现在两个方面:
显存:显存决定了你出图的精度「分辨率上限」
显卡性能:性能决定你出图的速度「好性能两三小时的产出差性能可能要两三天」
👇以下是显卡AI跑图性能性价比表 / 提供制表人:albedo
案例5-《Q版形象3D转化实验》
⭐注意:因概念稿原图是我21年时为blg设计的队员形象,目前队员已离队。本次Ai转换为个人作品实验,非官方版本。
本次实验解决了一些问题
1-还原人物设定中预想的布料与塑胶质感
●p1:针织毛衣,皮裤,皮带,玩具狗
●p3:光泽卫衣(皮质),卫裤(棉质),背包(皮质),眼镜(塑料)
经验:AI出图有高随机性,要使sd做出指定质感的内容,需要从四个方向来把控, 「多模型转换-精准识别TAg-参数调控-贴图指向辅助」


2.Q版人物的识别
符合工作流应用的IP形象,虽然在细节上需精致,但不能写实。我们并不想看到“大头娃娃”。这就需要结合lora模型来生成“卡通效果”这里用到了作者mr木人又制作的「blindbox」lora。

3-分辨率的影响
如果你的参数和tag等都没问题,但出图很崩,试试调节分辨率!在一些模型中,适合较小的分辨率生成。而有些模型,要很高的分辨率才能发挥其效果,这可能关乎于作者在训练模型时所用源素材的尺寸。例如在本次制作中,lora模型对1200以上的分辨率产出图影响变弱,所以第一次生成时我调低尺寸,先生成卡通效果,第二次生成时我调高尺寸,更换模型,深化卡通效果的细节。这个过程很考验对参数,数据,设计的逻辑性。


4-贴图指向辅助
如果你在SD图生图中,使用关键词描述物体质感,但生成效果不理想,或许可以试试【贴图指向辅助】的方法
这和在3D中的工作逻辑有些类似,只是用概念图操作会更直观。举例:我想要左边人物的背带是皮革质感,可以找到相应的材质贴图,填入背带选区,这等于给了AI一个更具象的tag提示词,然后再用AI下一步“融合”,它会帮你融入到整个画面中。


二.SD的功能介绍

你是否会有这样的困扰?就是打开SD后看着数不清的按钮,好像在看天书,一头乱麻,无从下手。👇
我建议先从以下几个关键词入手,根据优先级来反复跑图,试验出各参数对出图的效果权重
【-AI模型 -Tag标签以及功能性了解 -电脑配置(显卡) -分辨率设置 -采样器效果 -重绘幅度 -提示词系数 -controlnet -lora-局部重绘-seed-WD1.4标签器】

对于AI的工作流应用需要用实验来验证,靠【想象】,【以为】,很容易碰壁。大体实验流程为:概念稿-参数对照-选对模型-Ai生成-转模型互融-出图后期合成-再次AI反推-调试等。

以下是在实验中,关于SD的常用功能介绍
1.模型的作用
1.定义画面风格(画风)
2.模型会限制画面里出现的内容
3.我们可以用多个模型来推导内容(例如在模型A里生成百分之三十,模型b里生成百分之七十,最后再合成)
4.可以 使用VAE来增强模型效果(材质增强,可以理解为给游戏加光追)
5.可以使用合适的lora来补足模型的缺陷(内容增加,例如特定的脸/服饰/物品/风格等,可以理解为给游戏加mod)
5.模型的下载:civitai

2.Tags编写知识
1.标准三段术式:前缀+主体+背景(+后缀)
前缀-(基本前缀+画风词+整体效果器)基本前缀为强调图片质量的词汇/用于凸显图片的画风/图像整体光效的词汇 。
主体-(画面中的主体部分)主体为图画想要凸显的主体,可以是人物,建筑,景物等,对于角色来说,通常包括了面部,头发,身体,衣着,姿态等描写。
背景-对周围环境的描写。后缀通常和效果器类似,用于对场景进行丰富。
2.权重控制
最基础的权重控制为控制prompt在咒语中的位置。越靠前的词汇越受到重视。权重控制可以通过对prompt加括号进行() 或 {} 为加强权重,[] 为减弱权重 ,例如(1girl:1.5)括号后对添加 “:1.5”是对词条直接赋予权重,数字即为权重大小。数字越大权重越大,默认1,通常为0-2之间。 ()为对其中内容权重乘以1.1,[]为对其中内容除以1.1
权重溢出:权重溢出现象。这一现象的表现为权重设置过大,导致原本的修饰词挣脱了词条的束缚,溢出到了其他元素中,导致画面崩坏。
3.tag词库准确性
我们之前提到过AI世界的概念,核实Tag准确性可以对照danbooru看,有时候自己通过翻译直接写的词汇可能无法被识别。
4.限制还是释放?
tag越精细,对画面的限制性越大,AI自由发挥的空间越小 ,精简tag(尤其负面)可以释放AI的想象力。
5.tag反推
CLIP 反推提示词-侧重于对图像的描述,生成句子 。
DeepBooru 反推提示词 -侧重于对图像内容的识别,生成tag。
但我个人更喜欢用第三种:wd1.4标签器,我认为它对图片Tag的识别更精准,并且可以通过阈值来控制生成Tag的长短,还可以通过更换反推模型来改变提示词的变量与优先级(因对显存占用很大,用完记得点击卸载反推模型)。

3.Lora的作用
1.类似游戏里的mod,目的是更精准的控制效果
2.注意LoRA强度对画面效果的影响(在lora里同样会有权重溢出现象,通常lora的权重不会超过1,也可以在C站去找到lora模型作者的推荐数值)

三.案例实操过程

在这次分享中,就以封面图为案例拆分讲解创作过程。

用SD把概念稿生成可控3D效果过程图👆
步骤1.概念图调整
根据我们要使用的模型风格,我们需要先在概念图上有所调整,使它符合AI和模型内容的生成逻辑
⭐提示:在本次案例中,我使用的模型为【chilloutmix和revAnimated】,VAE为【vae-ft-mse-840000-ema-pruned】

在前期图生图生成过程中,有过三次概念图调整。
1.概念图1(原图):SD图生图会根据图案/结构线分割来识别物体,清晰的线稿与底色会直接影响效果。概念图1满足【线稿清晰,结构合理】的条件,至于需不需要铺色,这个要看你使用文生图+controlnet 还是图生图模式来制作,在图生图模式,推荐铺一个底色,这也方便你控制生成图的颜色。可改变概念图颜色来控制画面颜色,要比在SD软件中通过关键词调整快得多。
2.概念图2 :在概念图1生成中,SD对小电视底部星球的识别困难,因此调整为概念图2的效果,增加服装阴影,增加蓝色背景,扩展底部星球和填色,在关键词中添加【universe,Astral】等对背景的描述引导。再次生成后,小电视立体感和空间感提升,但星球效果依旧不明显。
3.概念图3:继续对概念图2优化修改为概念图3,调整内容1.修改背景环境的深度,使主体更突出2.在花瓣中搜索“月球素材”,进行【贴图指向辅助】,在概念图星球区域内贴上月球质感材质,对AI进行更具象的引导。3.对小电视头部颜色进行调整,修改为渐变效果,这种颜色过渡会指引AI对画面的灯光效果(效果可参照完成图)。
步骤2.TAG关键词反推
把概念图放入WD1.4标签器中进行图片tag反推生成【主体关键词】
1.在WD1.4界面把图片上传后,选择反推模型wd14-convnext-v2(个人推荐),阈值调整为0.2(阈值越低生成词条越多)。

2.然后我们复制tag到翻译软件中,进行核查筛选(英语很好可略过这一步),删除不符合画面需求的tag,添加补充内容的关键词。

3..按照上面所述的Tag标准三段术式:前缀+主体+背景(+后缀)来重新排列和组成完整的tag术语。
⭐这里我添加的前缀(前缀为强调图片质量的词汇/用于凸显图片的画风/图像整体光效的词汇 )是:complex 3d render ,150 mm, beautifulstudio soft light, rim light vibrant details, luxurious cyberpunkhyoerrealistic, anatomical, facial muscles, cable electric wiresmicrochip elegant, beautiful background, octane render, H. R.Giger style, 8k best quality, masterpiece, illustration, anextremelv delicate and beautiful extremely detailed CG .unitywallpaper(realistic, photo-realistic:1 37)Amazing, finelv detailmasterpiece,best quality,officlal art, extremely detailed CG unit8k wallpaper, absurdres, incredibly absurdres
这里我添加的负面提示词是(画面中不希望出现的内容):paintings, sketches, (worst quality:2), (low quality:2),(normal quality:2), lowres, normal quality, ((monochrome)). ((grayscale)), skin spots, acnes, skin blemishes, age spot, (outdoor:1.6), glans
⭐注意:关键词在图生图生成过程中,会根据画面的和控制条件改变而修改,不要习惯于把一段术语用到“通关”,多去培养对词条权重和数据敏感度的感知能力。
步骤3.参数控制
下一步我们通过调整几个图生图模式常用参数来控制画面效果。
1.缩放模式:这里推荐【比例裁剪后缩放】
2.迭代步数:可以理解为画面精细度数值,但对显存占用较大,因在30步之后的提升不明显,所以推荐数值为30
3.采样方法:推荐常用Euler a模式,它的效率更快,深入度更高。但也因此画面崩坏率更大,尤其是在重绘幅度过高的情况下。所以,还可以使用DPM系列,它在重复幅度大的情况下,对画面的稳定性控制更好,缺点是细节深入度低,所以在图生图重绘时,我可以根据我的需求选择每一步适合的采样模式。
4.重绘尺寸:如果你的参数和tag等都没问题,但出图很崩,试试调节分辨率!在一些模型中,适合较小的分辨率生成。而有些模型,要很高的分辨率才能发挥其效果,这可能关乎于作者在训练模型时所用源素材的尺寸。
5.提示词引导系数:图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示(根据模型),但它也在一定程度上降低了图像质量。可以用更多的采样步骤来抵消。
6.重绘幅度:重绘幅度就像下笔的【重量】一样。这就像在画水彩画时,一朵精致,漂亮的牡丹,从一抹淡淡的红开始。所以图生图重绘幅度要根据你每一笔的「重量」来调整。初始不建议太高。可以在0.1-0.3之间。然后多次图生图叠加,0.1+0.2+0.1….

步骤4.多模型推导
有些模型结构好些有些模型细节好,例如SD图生图中,先用模型a推百分之三十,再用模型b,不断反推,实验。同时过程图的调整也很重要

步骤5.修改与合成
不同模型生成的图,有着不同的优点,比如,在模型A中,耳机的识别效果更好,而模型B中,宇航服的效果更好,这取决于开发者在训练不同的模型时所提供的素材库类型。我们可以把他们两种模型生成的过程图,在ps中用蒙版等工具合成为一张图,保留优点,修改不足,然后再把修改好的图放到SD图生图中再跑一遍,继续生图,AI会把质感融合的更好。
在这一步,希望大家可以重读上面【稳定】和【细节】的逻辑关系,在修改过程图然后重新导入AI生成的环节里,需要把每一次图生图根据画面在大脑中数值化,并且通过修改过程图来控制数值。


步骤6.输出总结
最后,我们把最终满意的图片输出再PS里后期调色,修饰细节,排版等成为完整的工作流。

整个图生图实验流程就是参数,模型,修改,生成中不断的循环和调整,直到我对画面满意为止。如上所说,在十分钟左右时其实就已经达到百分之九十的效果,如果看不出画面问题,对结果满意,那么就会停留在这一阶段。其实用Ai和做设计一样,难得是那百分之十的突破。

总结
以上是我从视觉设计师出发对AIGC工作流实验的一些个人经验,分享给大家,欢迎大家留言探讨~本篇是【运用SD细化工具进行高效工作流】第一篇,内容大概8500字,但还是有很多细节限于篇幅无法深入解析,不过没关系,这个可以留给第二篇。最后,分享一张关于本篇文章在构思时的思维导图,对整体内容有一个更概括性的总结。如果本篇内容对你有帮助,请给我点赞支持一下吧~

-卡昂卡昂

若有收获,就点个赞吧
0 人点赞
