李宏毅的课程网页:https://blog.csdn.net/iteapoy/article/details/105382315
一、概述
机器学习三大过程:regression(回归),classification(分类),generation(输出文字/图片)
数据——>label 函数——> function——>loss误差
强化学习——无监督与reward(alpha狗)
训练资料和测试资料的环境不同怎么办(Domain Adeversarial Learning)
Meta learning = Learn to learn
二、安装
pyenv global +ver.
三、第一讲 regression——一个简单的训练过程
- 用处
自动驾驶、预测可能性、预测宝可梦的CP值(战斗力与进化)
- 应用举例:
输入:宝可梦X进化前的cp 输出:进化后的战斗力cp 
① 寻找Model(即函数f)——引出线性回归(w权重,x特征)

② 评估function ——引出Loss Function(衡量一组b与w的好坏) To Pick…



③ Gradient Descent找出最优解即如何使 最小,梯度下降
最小,梯度下降
- 找出初始
 后计算在该点的
后计算在该点的 ,对
,对 进行调整。
进行调整。 - 如何调整? 直至微分为0——local minimum,并不是全局最优。

- 如果有两个参数,就分别计算偏微分

- 如何克服局部最优?
- 对于线性回归,其Loss Function在几何上是covex(凸性的),直接求偏微分即可。
- 非线性在后期课程中涉及。
④ Generalization ——更改model
一次二次三次四次….拟合training data会更好,但apply到testing data误差更多,说明次数高后出现了过拟合(overfitting)。(可以理解为次数高的函数包含次数低的函数)

⑤ Redesign the Model 宝可梦分种类:
引入一个参数,将宝可梦种类分开:
将所有因素都纳入考虑范围内,出现过拟合的情况:
- back to step2:——regularization(本身是不需要考虑bias的,b值与函数的平滑程度无关):

加上标黄的这一项,平滑function,对于噪声将有抵抗作用。 越大,考虑
越大,考虑 原先的值,减少考虑error,导致模型欠拟合,不注重误差。
原先的值,减少考虑error,导致模型欠拟合,不注重误差。
四、第二讲 Basic concept——详细解释拟合与过拟合
- error来源于:bias(函数上下平移),variance(
 ,取决于样本数N,N大更分散),通俗来讲:偏移与散射程度。
,取决于样本数N,N大更分散),通俗来讲:偏移与散射程度。 - 目的:寻找最佳的模型/
 ,但
,但 ,
, 是实际模型。
是实际模型。 
- bias大,variance小:模型简单,欠拟合(redesign,more features);bias小,variance大:模型复杂,过拟合(数量太少导致个体特性太强,more data/regularization但可能会伤害bias)。
- more data:create/collect
- 不能做的事:自己拥有的testing set(public)和从没见过的real testing set(private)存在不可见的bias,解决方法:把training set分为training和validation(选model)——>N-fold Cross Validation,把training分成好几份分别用不同的model跑train和validation,如下图:

求平均发现model1更好!少在意testing set,少根据测试结果调整,在实际应用时才可能更接近真实值。
五、第三讲 Gradient Descent——详细讲解梯度下降
- 在step3中,我们试图寻找使function最优(Loss Function最小)的参数值(此处定为
 )
)



- Gradient:Loss等高线的法线方向。
- 再次形象理解Learning Rate:太小了训练速度太慢、局部最优;太大了步幅太大,反复横跳,Loss太大。

- Loss与parameters的曲线关系
- Adaptive Learning Rate:

- Adagrad(含有time depend):
原先:

更改:

(除以过去所有微分值的均方差的t次)
<br />把直接消掉,得到:<br /><br />**存在问题**:gridient越大,分子越大(意味着步幅越大),分母越大(却意味着步幅越小),为什么?<br />原因是试图突出反差/反映二次微分的大小(不是近似)。_经验证,步幅不能只看一次微分,还得结合二次微分调整步幅。_<br />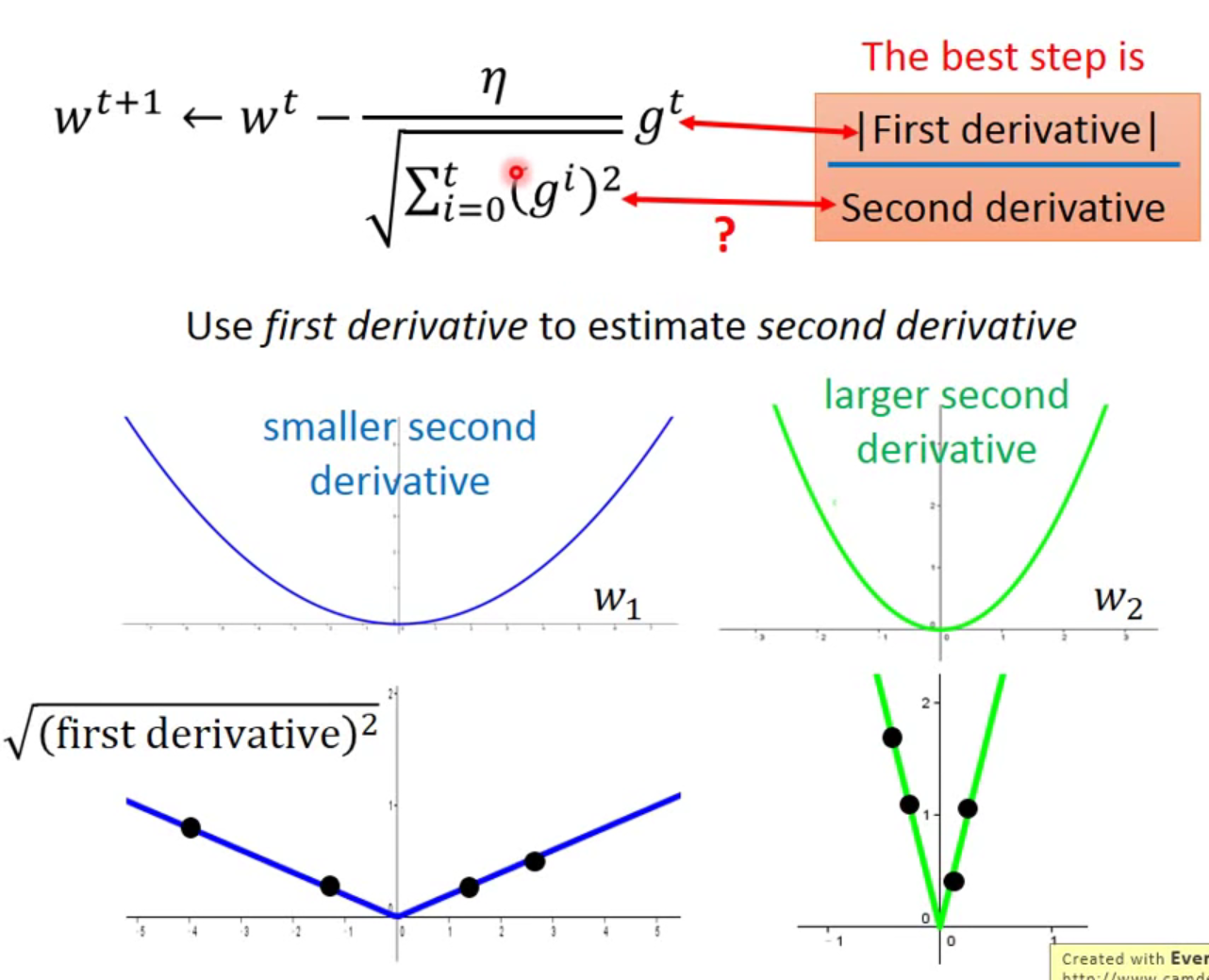
- Stochastic Gradient Descent
- Gradient Descent:

- Stochastic:任取一个变量,只对一个变量、挨个进行梯度下降。(步伐较小,次数多,计算快)
- Gradient Descent:
- Feature Scaling(标准化)
- 让变量分布相同(常见做法:每个例子的相同特征减去各变量均值除以标准差)


- 为什么做梯度下降/理论部分?——泰勒定理
六、第四讲 Classification
- X ===》class N
- Classification和Regresssion的区别:
- 不能拿Regression硬做Classification,不适用
- 例子:拿Regression做二分类:导致的结果是为了减小误差,使输出更贴近两个预定的输出结果,它会调整他整体的模型;但是二分类的目的往往是将两类完整分开即可,没有必要将目光局限在仅有的两个输出数字上去,更不用将误差考虑在可接受范围内。如下图:绿色线为二分类理想,紫色线为Regression理想,有一定差别。

- maximum likelihood
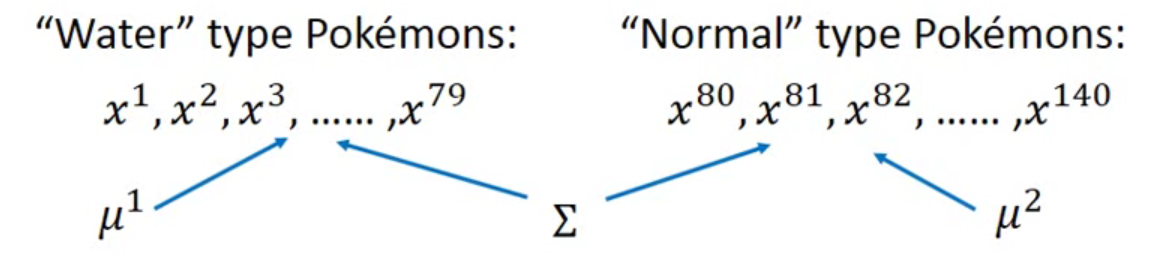
- 将原先的两个高斯分布加权平均,使用共同的高斯分布,得到公用的协方差,而μ不同,boundary变为线性;
- 总结为以下3steps:
- Model:



- 根据参数定义函数好坏
- 寻找最佳函数/使likelihood最大的函数
- 如果假设所有例子之间独立,则可以使用朴素贝叶斯分类。


结合以前在hero学过的神经网络,sigmoid激活函数应运而生,他有这一层含义。使带权输入==》由已知特征得到推理归属类的概率。
https://hitwhlc.yuque.com/hero-rm/fxhbfd/dpgt62
- 朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。
- 如何简化寻找w,b的过程?下一讲。
七、第五讲 Logistic Regression
- step1 Function Set
我们要从样本收集特征后找到成为某一种类的概率 :
:




- step2 Goodness of Function



(交叉熵代表两种分布有多接近,完全一样交叉熵为0)
- step3 Find the Best function/梯度下降
推导算法:

表示方式是一样的。但是f不一样。
- 为什么逻辑回归的损失函数不能使用方差?

以两种待分类的种类为例(0/1),如果计算方差,计算出为0或为1的概率时,损失函数对权重的偏微分接近或等于0,没有办法进行梯度下降或梯度下降速度慢。无法判断在update过程中,我们到底是离目标远还是离目标近。所以,使用交叉熵作为损失函数,更容易得到理想的结果。
- model对比:generative(高斯假设) 和 description(逻辑回归)
后者更好。为什么?前者其实做了脑补,自己假设所获得的数据来自于一种几率模型。事实上我们正常人分类时,不会考虑它来自于一个几率模型,而是从更直观的角度去认识。(数据较少时,就会有如下图的例子出现,generative从朴素贝叶斯的角度去分类,得到的两个红球是属于class2的,因为数据不够多,单从纯概率的角度出发会产生错误),当然,数据不够时,适当的脑补也也会更优。比如语音辨识系统就是generative。
limitation of logistics regression——feature transformation
Logistic regression也会遇到不好分类的情况,这时需要做特征转换,使其可以用logistics regression进行分类。如何做特征转换?
- 人の智能
- 机器学习:把多个logistics regression串起来。(右图是实例,相当于把一维转为二维,就可以分类了)


然后:
神经网络他就来了!这老师真的讲的一级棒。
八、第六讲 Introduction of Deep Learning
- 全连接前馈神经网络:w,b如何计算:w是一个matrix,b一个向量,与x分别相乘相加,然后再激活。最后得到的实际就是一个函数,一连串w,b的计算。

- Input layer(维度为输入特征数),hidden layer(feature transformation)(维度无限制!但是要联系输入输出),output layer(维度为分类数).
- 深度学习用在什么问题比较好用?靠直觉和经验多一点,觉得深度学习适合哪一个问题。
- 关于维度无限制的hidden layers,可以使用相应的技术,也可以人为自行设计。
- 整个分类过程让我茅塞顿开的一张图:交叉熵越小越好。


输入是声音特征,输出是属于每一种状态的概率。dnn使用比较有效率的方式使用参数。“任何持续的函数都可以用一层隐藏层的神经网络表示(只要这层隐藏层足够宽)”,但dnn是更有效的方法,所需data会更少,达成同样的训练效果。(折叠空间/剪窗花)
十、第八讲 backpropagation
- 从梯度下降开始:我们要不停地更新使损失函数最小的w,b。但一般求偏导计算新w,b都非常损耗时间,计算量很大。很多个参数,backpropagation只是使梯度下降比较有效的计算法。
- 链式法则(chain rule):
case1: y=g(x),z=h(y)
case2:x=g(s),y=h(s) z=k(x,y)

计算每一笔data中的Cn 
- 前向传播(forward pass):从提取特征到预测值的方向
- 反向传播(backward pass):



反向传播只需要走一次就能把各层的权重算出来,但要是正着算计算量会多出指数倍,层数越多越复杂越难算。
- summary

十一、第九讲 Tips for Deep Learning
十二、第十讲 CNN(Convolutional Neural Network)
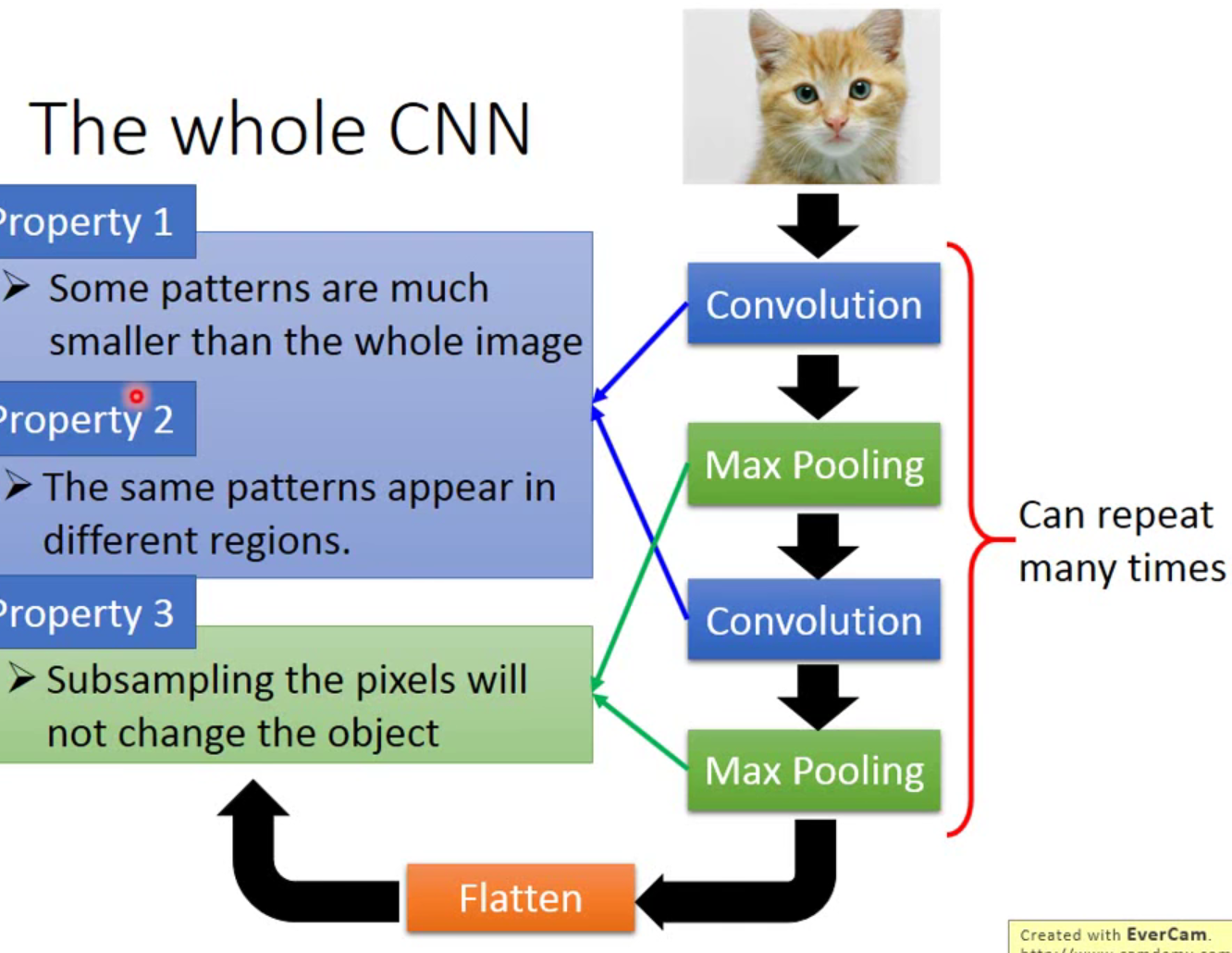
- 一般用CNN处理图片——why?
处理图片的话,一般输入层是图片的像素数量,如果按照普通的神经网络来处理的话,他在隐藏层中的神经元数过于多了(wh3),效率不高。而CNN是用来简化神经网络架构,剔除一些用处较小的权重,让训练更有效的方法。看图片的一部分分辨元素。
- 整个CNN是什么样的?
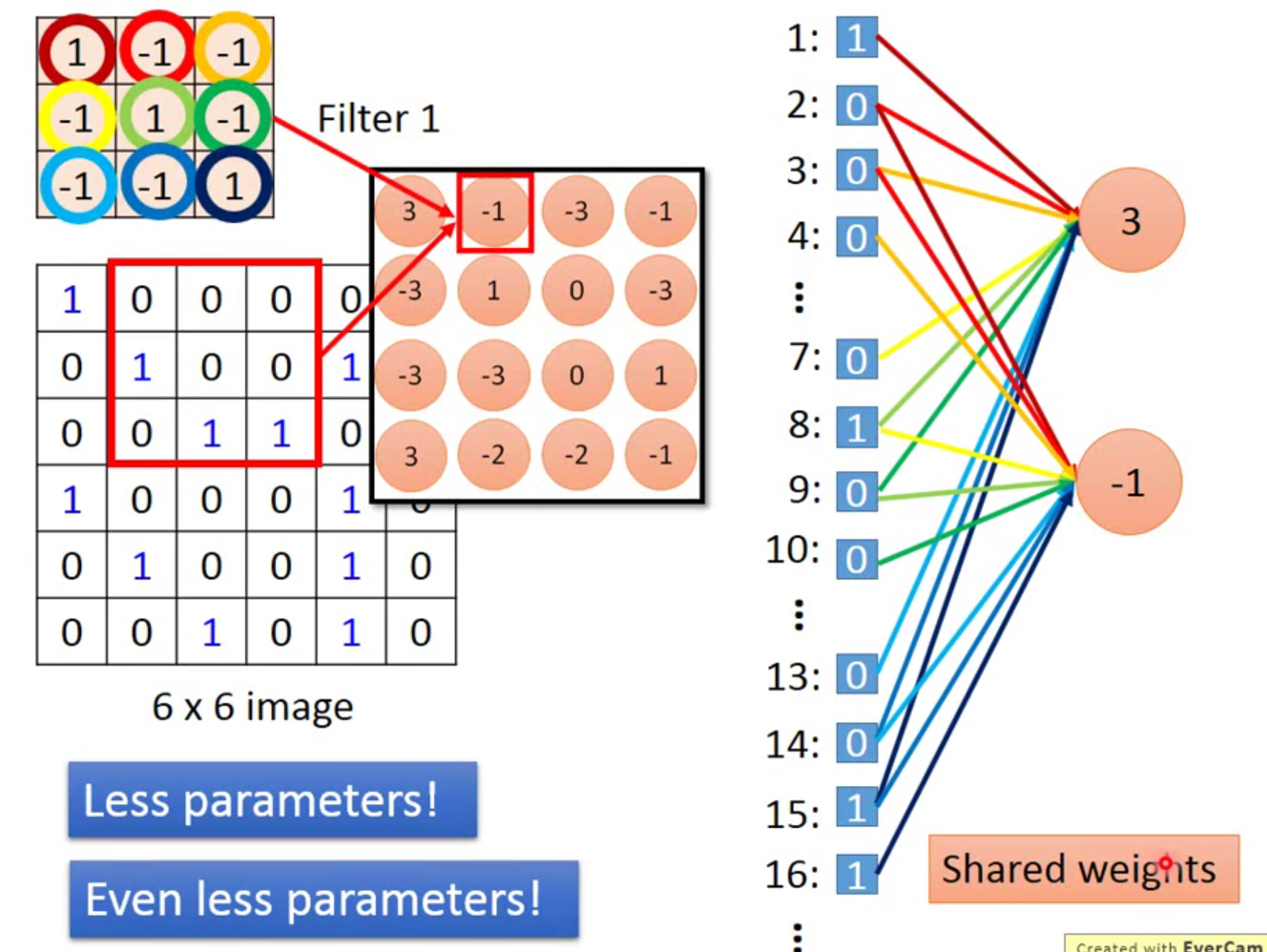
- convolution
- 将filter作为侦测对象,一般一个filter都比较小。
- 设立挪动步幅stride/即设定侦测细度,也关系到计算量

- 如果是bgr,一个filter其实是一个立方体。
- 用卷积对应不同的神经元,这样可以减少特征所用的参数(权重和偏置等)个数。(共享权重)
- 最大池化(max pooling)
把计算过的每个filter都选择一个最大值,可以进一步缩小filter的范围。
- 卷积和最大池化重复多次,可以不断减小检测范围。
- flatten
- Keras



- 即便是某一局部的特征也会被activate
- Deep Dream:他会将机器看到的东西自动添加到照片上去。可以夸大你想突出的特征。
- Deep Style:可以把已有照片按照目标图片的风格进行修改。

更多应用:下围棋

alphago并没有用最大池化,因为最大池化没有办法从围棋的体系解释。
移动其实没什么意义CNN用于声音时,stride可以指考虑纵向频率上的移动,因为横向没有意义。应用CNN的时候要根据实际特性去选择移动方向。

- 用于文字处理:将每一个word用一个vector来表示。

若有收获,就点个赞吧
0 人点赞
