
1.利用MapReduce进行数据挖掘
昨天的入门案例我们进行了利用MapReduce进行单词出现次数统计的案例,昨天是一个基础的统计案例,那么MapReduce也可以进行数据挖掘,今天展示一个经典案例(Child-Parent)
2.准备工作
首先创建如下文本文件,并上传到HDFS的test2文件夹中:
Tom LucyTom JackJone LucyJone JackLucy MaryLucy BenJack AliceJack JesseTerry AliceTerry JessePhilip TerryPhilip AlmaMark TerryMark Alma
左侧为child,右侧为parent,我们要利用这些数据挖掘出GrandChild与GrandParent的关系
通过昨天的验视我们知道,MapReduce编写的三大核心:Map、Reduce、Job
ParentMapper.java
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author*/public class ParentMapper extends Mapper<Object,Text,Text,Text> {@Overrideprotected void map(Object key, Text value, Context context) throws IOException, InterruptedException {//输出标识String temp;//读取行String line = value.toString();String words[] = line.split(" ");//输出左表temp = "1";context.write(new Text(words[1]),new Text(temp + "+" + words[0] + "+" + words[1]));//输出右表temp = "2";context.write(new Text(words[0]),new Text(temp + "+" + words[0] + "+" + words[1]));}}
ParentReducer.java
import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;import java.util.ArrayList;import java.util.List;/*** @author*/public class ParentReducer extends Reducer<Text,Text,Text,Text> {@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {List<String> grandChildList = new ArrayList<>();List<String> grandParentList = new ArrayList<>();for (Text value : values) {char temp = (char) value.charAt(0);String[] words = value.toString().split("[+]");if (temp == '1'){grandChildList.add(words[1]);}if (temp == '2'){grandParentList.add(words[2]);}}for (String grandChild : grandChildList) {for (String grandParent : grandParentList) {context.write(new Text(grandChild),new Text(grandParent));}}}}
ParentRunner.java
import com.zym.mapper.ParentMapper;import com.zym.reducer.ParentReducer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @author*/public class ParentRunner {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Job job = Job.getInstance(new Configuration());job.setMapperClass(ParentMapper.class);job.setMapOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);job.setReducerClass(ParentReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job,new Path("hdfs://hadoop0:9000/test2"));FileOutputFormat.setOutputPath(job,new Path("hdfs://hadoop0:9000/output2"));boolean completion = job.waitForCompletion(true);if(completion){System.out.println("Job Success!");}}}
然后运行该main方法,查看结果: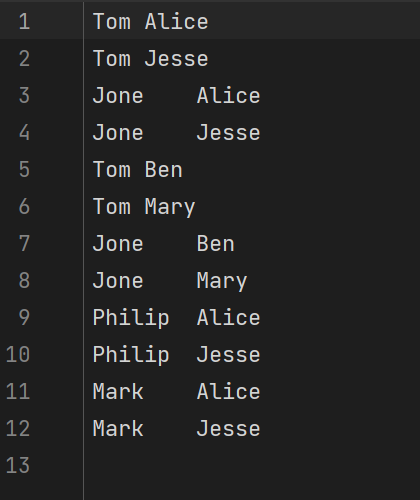
分析:
在Map阶段,我们将孩子、父母的名字都作为key,整行数据作为value(行数据前面加1、2用来区分key是父辈还是子辈),然后交给Reduce。在Reduce阶段,我们读取到某个Map的键值对,拿到里面的value后,首先判断该value的首位是1还是2,如果是1则代表,该行数据中,这个key的名称是作为父辈出现的,所以将该行数据的第一个名称添加到grandChildList中;如果是2则代表,改行数据中,这个key的名称是作为子辈出现的,所以将该行数据的第二个名称添加到grandParentList中。然后我们对这两个集合进行笛卡尔积即可得到该key对应的祖父辈关系。这里以Jack为例,在Map阶段结束后,数据应该是这样的:
<"Jack",["1+Tom+Jack","1+Jone+Jack","2+Jack+Alice","2+Jack+Jesse"] >
所以Tom与Jone被放入了grandChildList中,而Alice与Jesse被放入了grandParentList中,他们之间的关系如图: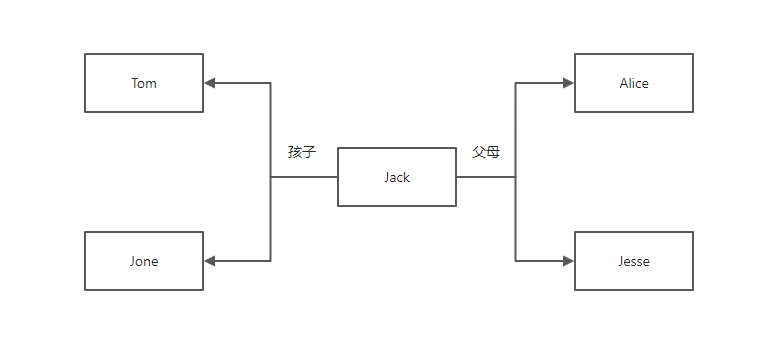
所以对于Tom与Jone来说,他们的祖父辈就是Alice与Jesse,当然对于其他的人来说也是一样的,都可以利用这种方法找到祖父辈与孙子辈的关系。通过这个案例我们更加深刻的理解了Map->Reduce的整个过程数据的变化。
总结:通过这样一个简单的案例不难看出,这样的数据挖掘还是很有必要的,尤其在大批量数据面前,靠人工计算显然是不现实的。自此,整个Hadoop我们可以说是已经入门了,那么接下来我们会继续学习Hadoop的其他组件来更加贴近与我们平时经常使用的框架与技术。

若有收获,就点个赞吧
0 人点赞
