
1.Spark SQL
Spark SQL的前身是Shark,目的是为了给熟悉RDBMS但不理解MapReduce的技术人员提供快速上手的工具。Spark SQL类似于Hive,但Spark SQL可以不依赖与Hadoop,而且运算速度比Hive快。
2.Spark SQL命令
开启Spark SQL,既可以使用和类似Hive的方法进行操作。不同的是,Hive的数据操作被翻译成了MapReduce任务,而Spark SQL的数据操作在Spark中执行。与Hive类似,我们需要将MySQL连接器的jar包放到/usr/local/spark/jars目录下,经过我测试这里其实操作的就是Hive。<br />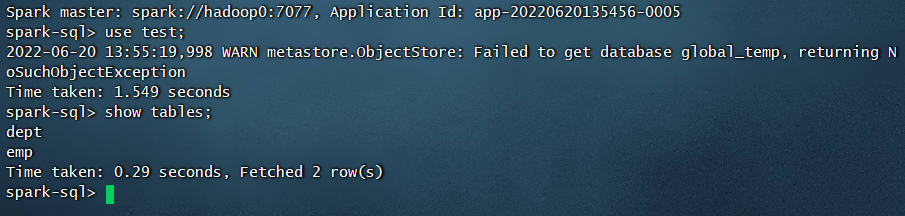<br /> 可以发现库与表还有内容与我们当初搭建Hive的测试数据是一样的,这里操作什么的都类似,不再多列举了。
3.Java操作Spark SQL
接下来我们通过官方实例演示一下通过Spark操作Hive,提前将hive-site.xml、core-site.xml、hdfs-xml文件导入到spark目录的conf中,当然也可以操作JSON、CSV、Text、JDBC等,这里就不一一列举了
参考文档:https://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
导入下面的依赖:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.1</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.2.1</version></dependency>
编写代码:
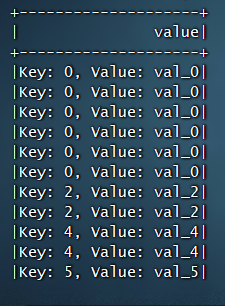
import org.apache.spark.SparkConf;import org.apache.spark.api.java.function.MapFunction;import org.apache.spark.sql.Dataset;import org.apache.spark.sql.Encoders;import org.apache.spark.sql.Row;import org.apache.spark.sql.SparkSession;public class SparkSql {public static void main(String[] args) {SparkConf sparkConf = new SparkConf().setMaster("local[2]").setAppName("SparkSQL");SparkSession spark = SparkSession.builder().enableHiveSupport().appName("sql").config(sparkConf).getOrCreate();spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive");spark.sql("LOAD DATA LOCAL INPATH '/usr/local/spark/examples/src/main/resources/kv1.txt' INTO TABLE src");spark.sql("SELECT * FROM src").show();Dataset<Row> sqlDF = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key");// The items in DataFrames are of type Row, which lets you to access each column by ordinal.Dataset<String> stringsDS = sqlDF.map((MapFunction<Row, String>) row -> "Key: " + row.get(0) + ", Value: " + row.get(1),Encoders.STRING());stringsDS.show();//切换到我们之前学习Hive时候建立的数据库与数据表spark.sql("use test");spark.sql("select * from emp").show();spark.stop();}}
然后打包,上传服务器,执行
spark-submit --class SparkSql --master local[2] /usr/local/spark_sql-1.0.jar
结果: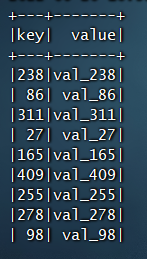


若有收获,就点个赞吧
0 人点赞
