
1.Hive QL的基础功能
Hive QL是Hive支持的类似SQL的查询语言。Hive QL大体可以分成DDL、DML、UDF三种类型。DDL(Data Definition Language)可以创建数据库、创建表、进行数据库、表的删除等操作;DML(Data Manipulation Language)可以进行数据的添加、查询;UDF(User Defined Function)还支持用户自定义查询函数。
操作数据库
使用Hive QL,可以创建数据、显示数据库、打开数据库、删除数据库等。
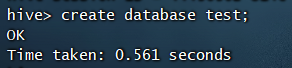
例如,创建数据的命令如下:create database test;
查看数据库信息的命令如下,但无法查看当前数据库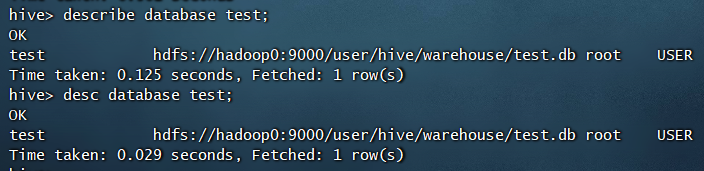
可见新建的数据库在HDFS上的存储路径为上图所示,我们利用插件看一下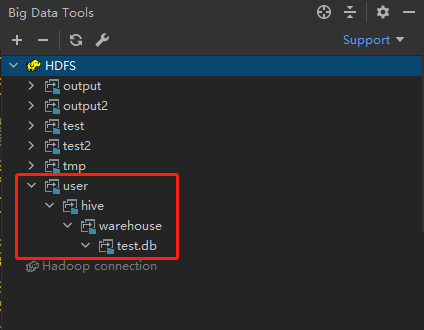
改变数据库、删除数据库的命令如下,这里就不演示了创建表
创建表的通用语句如下。Create [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment],...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment],...)] [CLUSTERED BY (col_name,col_name,...)[SORTED BY (col_name [ASC|DESC])],...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用IF NOT EXIST选项来忽略这个异常。
EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表则只删除元数据,不删除数据。
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用STORED AS SEQUENCE。
有分区的表可以在创建时使用PARTITIONED BY 语句。一个表可以有一个或多个分区,每一个分区单独存在一个目录下。而且,表和分区都可以对某个列进行CLUSTERED BY操作,将若干个列放入一个桶(bucket)中。也可以利用SORT BY对数据进行排序。这样可以为特定应用提高性能。
我们来看个小例子,使用下面的语句创建emp和dept两张表,并且加载/usr/local/hive/examples/files中的emp.txt和dept.txt数据到表中,这两个文本文件都是Hive自带的。
因为示例数据中是以”|”分割字段,所以需要特别指定。加载数据,local字段表示是本机目录,如果不加则表示的是HDFS上的目录;overwrite关键字表示删除目标目录,当没有时则保留,但会覆盖同名旧目录。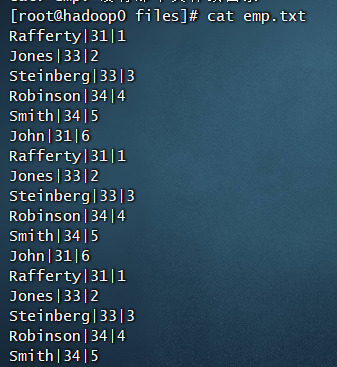
查看表命令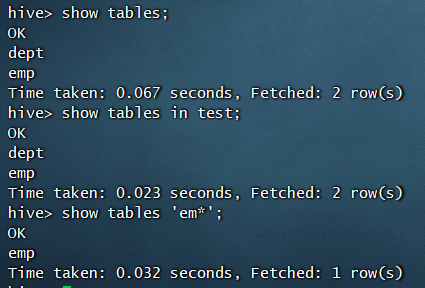
查看表的结构信息
通过插件我们可以看见,Hive将数据文件上传到了HDFS的如下图的目录中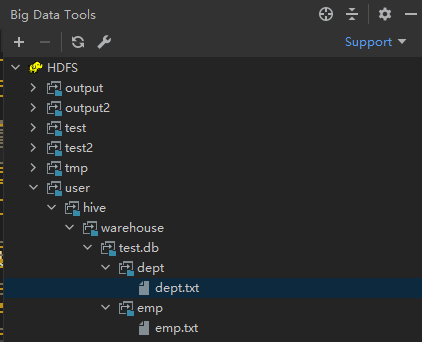
与SQL类似,Hive QL也具有一般查询、聚合函数、distinct去重函数、order排序、连接查询等功能
查询例子如下:
注意:在Hive的早期版本中,只有使用*查询全部字段才不触发MR操作,如果以select后指定查询某些字段,则会出发MR操作。但在Hive新版本中,无论上述哪种查询,都不会触发MR操作。
upper函数的作用是将查询的字段全部变成大写的,该操作不会触发MR操作,例如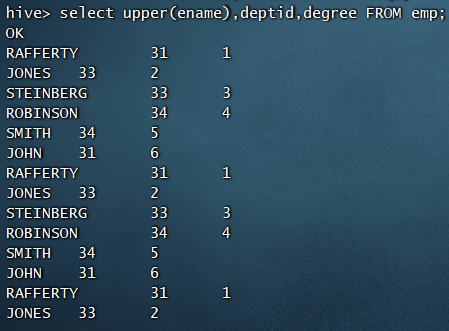
与SQL一样,可以使用count()、max()、min()、sum()、avg()这些统计函数,这些函数都会出发MR操作。例如: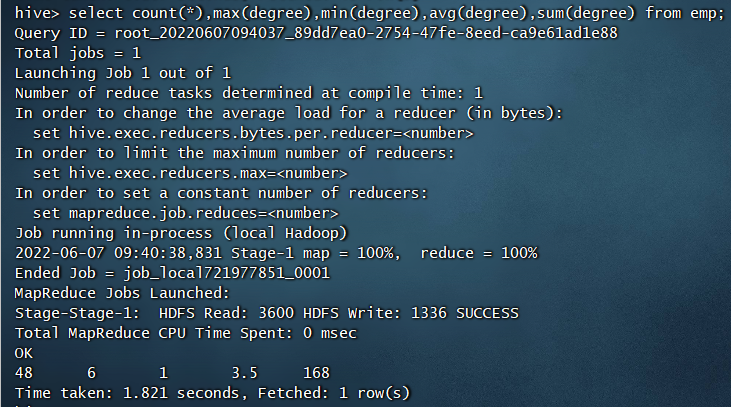
2.Hive QL的高级功能
distinct用于去重,例如:
select distinct(deptid) from emp;

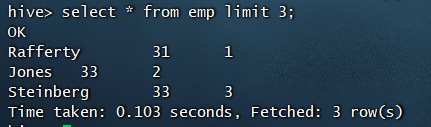
limit限制返回记录条数,例如:
select * from emp limit 3;
类似于Java中的switch…case语法,Hive QL中可以用case when then实现多路分支效果,例如: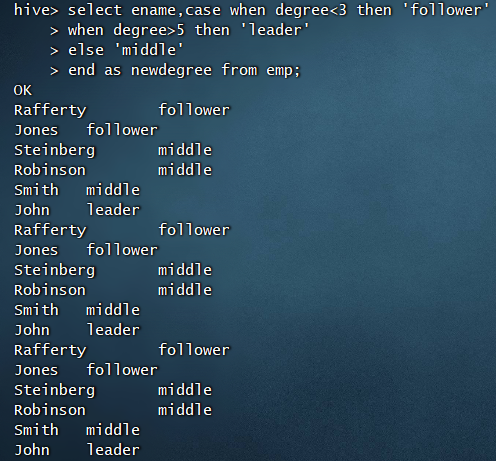
模糊查询与SQL类似,也是like语句,例如:
select * from emp where ename like '%o%';
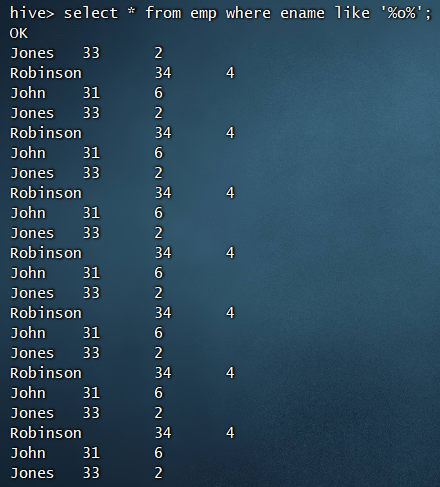
当然左模糊与右模糊也是可以的

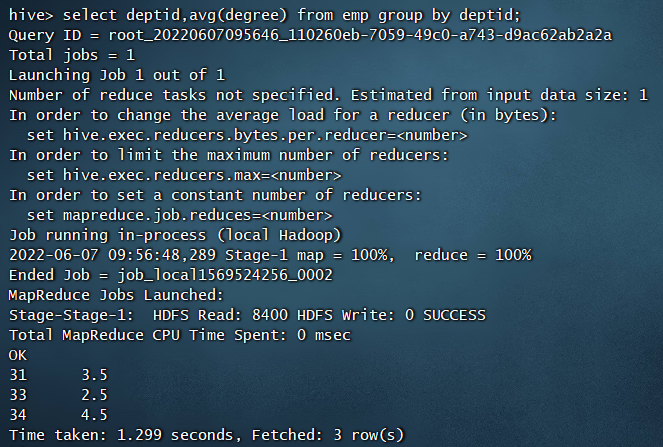
group by用于分组统计,例如:
分部门统计每个部门员工的平均级别
select deptid,avg(degree) from emp group by deptid;
注意:使用group by分组统计的场合,select后只能出现分组字段和聚合函数,而不能有其他字段
对分组统计结果进行过滤,使用having,例如:
select deptid,avg(degree) from emp group by deptid having avg(degree) > 3;

inner join内连接,例如:
select e.*,d.* from emp e inner join dept d on e.deptid=d.deptid;select e.*,d.* from emp e join dept d on e.deptid=d.deptid;

left outer join和right outer join外连接,例如:
select e.*,d.* from emp e left outer join dept d on e.deptid=d.deptid;select e.*,d.* from emp e right outer join dept d on e.deptid=d.deptid;

因为emp表并没有35、36、37这三个部门的员工,所以右外连接的结果,左边全部显示为NULL
full outer join表示完全外部连接
select e.*,d.* from emp e full outer join dept d on e.deptid = d.deptid;
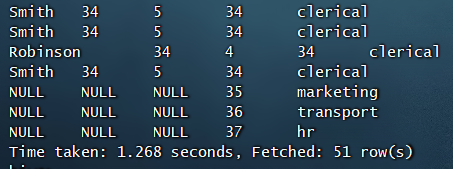
如果左表或右表中没有对应数据,则显示为NULL
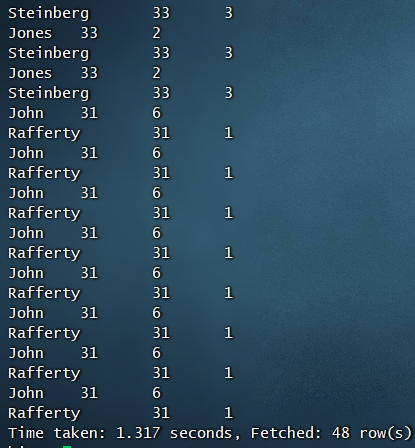
order by 排序,例如:
select * from emp order by deptid;select * from emp order by deptid desc;
按指定条件进行查找使用where,与SQL类似,但要注意的是Hive并不支持SQL中的子查询,例如:
select e.* from emp e where deptid = (select deptid from dept where dname = 'sales');
这样的语句是不支持的,正确的做法是利用联接查询来实现
select e.*,d.dname from emp e join dept d on e.deptid = d.deptid where d.dname = 'sales';
3.总结
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据表,并提供简单的SQL查询功能,可以将SQL语句转换为MR任务进行运行。学习成本低,通过类SQL语句即可快速实现简单的MR统计,而不必开发专门的MR应用。但我们平时也不会在命令行中做这些操作,所以接下来我们学习的就是如何利用Java API去操作Hive。

若有收获,就点个赞吧
0 人点赞
