1.kafka是什么
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
2.相关术语
Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer:负责发布消息到Kafka broker
Consumer:消息消费者,向Kafka broker读取消息的客户端。
Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
3.下载安装
下载地址:http://kafka.apache.org/downloads
我这里下载的是2.6.0版本的,进行解压:
tar -xzf kafka_2.12-2.6.0.tgzcd kafka_2.12-2.6.0
然后我们进行启动:
Kafka 使用 ZooKeeper 如果你还没有ZooKeeper服务器,你需要先启动一个ZooKeeper服务器。
这里使用kafka自带的zookeeper进行启动:
bin/zookeeper-server-start.sh config/zookeeper.properties后台启动:bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
然后我们查看一下zookeeper的配置文件(主要是看端口号,因为我使用的是阿里云的服务器,涉及到开放端口的问题)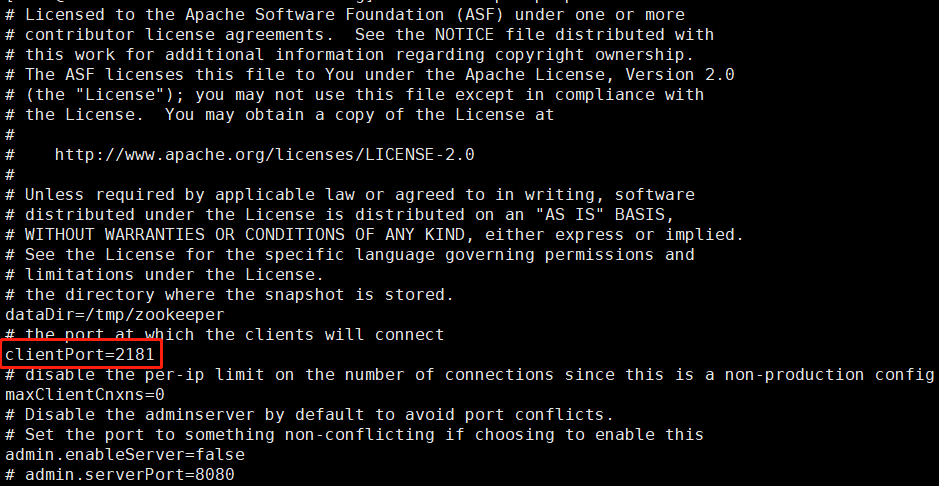
然后我们开放一下2181端口,顺便把生产者、消费者监听的端口开启(默认9092)
现在我们可以启动kafka了
bin/kafka-server-start.sh config/server.properties后台启动:bin/kafka-server-start.sh -daemon config/server.properties
然后报了这个问题:
解决方法:
就是内存不够了,最简单的杀点进程就好
启动后查看/logs/kafkaServer.out文件: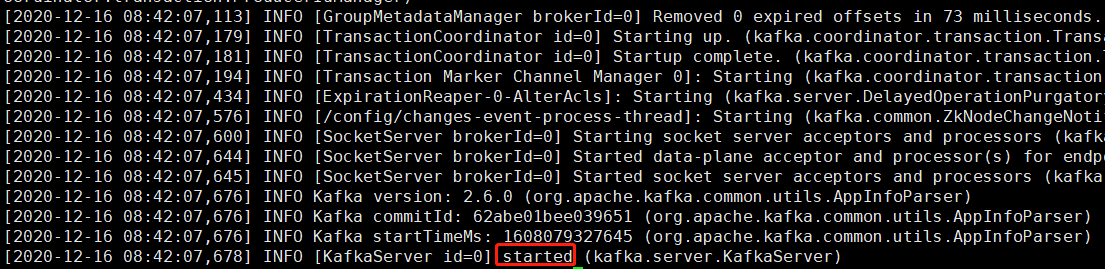
我们看到started说明kafka已经启动成功了
4.测试
我们先来创建一个test的topic,有一个分区和一个副本
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test

—partition 1 表示分区1
—replication-factor 1表示副本因子
broker无主副之分但是partition有主副之分,所以此参数的值不能大于broker数就是kafka服务节点数,我的例子中只有一个节点所以如果指定2会报错的,这个我们深入理解的时候再详细说明
查看所有topic的命令
bin/kafka-topics.sh --list --zookeeper localhost:2181
查看特定主题详情命令
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test

topic已经创建,我们来模拟生成一条消息(当然也可将代理配置为:在发布的topic不存在时,自动创建topic,而不是手动创建。)
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test

然后我们使用消费者将消息转储到标准输出:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning

详细使用在后续我会再写

若有收获,就点个赞吧
0 人点赞
