
1.MapReduce简介
MapReduce最早是由谷歌公司研究提出的一种面向大规模数据处理的并行计算模型和方法。谷歌公司设计MapReduce的初衷主要是为了解决其搜索引擎中大规模网页数据的并行化处理问题。谷歌公司发明MapReduce之后,首先用其重新改写了其搜索引擎中的Web文档索引处理系统。但由于MapReduce可以普遍应用于很多大规模数据的计算问题,因此发明MapReduce之后,谷歌公司内部进一步将其广泛应用于很多大规模数据处理。到目前为止,谷歌公司内有上万个各种不同的算法和程序在使用MapReduce进行处理。2003年和2004年,谷歌公司在国际会议上分别发表两篇关于谷歌分布式文件系统GFS和MapReduce的论文,公布了谷歌的GFS和MapReduce的基本原理和主要设计思想。2004年,开源项目Lucene和Nutch的创始人Doug Cutting发现MapReduce正是其所需要的解决大规模Web数据处理的重要技术,因而模仿Google MapReduce,基于Java设计开发了一个称为Hadoop的开源MapReduce并行计算框架和系统。自此,Hadoop称为Apache开源组织下最重要项目,得到了全球学术界和工业界的普遍关注,并得到推广和普及应用。MapReduce的推出给大数据并行处理带来了巨大的革命性影响,使其成为事实上的大数据处理的工业标准,尽管MapReduce还有很多局限性,但普遍认为,MapReduce是目前为止最成功、最广为接受和最易于使用的大数据并行处理技术之一。核心: Map(映射)和Reduce(归约) ,Map进行处理,Reduce进行汇总
2.内置数据类型介绍
Hadoop提供了如下数据类型,这学数据类型都实现了WritableComparable接口,以便于这些类型定义的数据可以被序列化进行网络传输和文件存储以及进行大小比较。
BooleanWritable:标准布尔型数值
ByteWritable:单字节数值
DoubleWritable:双字节数值
FloatWritable:浮点数值
IntWritable:整型数值
LongWritable:长整型数值
Text:使用UTF8格式存储的文本
NullWritable:当
ArrayWritable:存储属于Writable类型的值数组(要使用ArrayWritable类型作为Reduce输入的value类型,需要创建ArrayWritable类型作为Reduce输入的value类型,需要创建ArrayWritable的子类来指定存储在其中的Writable值类型)
3.入门案例-WordCount
TestMapper.java
import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author HappyDragon1994*/public class TestMapper extends Mapper<LongWritable, Text,Text, IntWritable> {/* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>* 它的这个Mapper让你去定义四个泛型,为什么mapper里面需要四个泛型* 其实读文本文件的操作不用你来实现,框架已经帮你实现了,框架可以读这个文件* 然后每读一行,就会发给你这个map,让你去运行一次,所以它读一行是不是把数据传给你,* 那他传给map的时候,这个数据就意味着类型的一个协议,我以什么类型的数据给你,我是不是得事先定好啊* map接收的数据类型得和框架给他的数据类型一致,不然的话就会出现类型转换异常* 所以map里面得定数据类型,前面两个是map拿数据的类型,拿数据是以什么类型拿的,那么框架就是以这个类型传给你* 另外两个泛型是map的输出数据类型,即reduce也得有4个泛型,前面两个是reduce拿数据的泛型得和map输出的泛型类型一致* 剩下两个是reduce再输出的结果时的两个数据类型* 4个泛型,前两个是指定mapper端输入数据的类型,为什么呢,mapper和reducer都一样* 拿数据,输出数据都是以<key,value>的形式进行的--那么key,value都分别有一个数据类型* KEYIN:输入的key的类型* VALUEIN:输入的value的类型* KEYOUT:输出的key的数据类型* VALUEOUT:输出的value的数据类型* map reduce的数据输入输出都是以key,value对封装的* 至于输入的key,value形式我们是不能控制的,是框架传给我们的,* 框架传给我们是什么类型,我们这里就写什么数据类型* 默认情况下框架传给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量* 因为我们的框架是读一行就调用一次我们的偏移量* 那么就把一行的起始偏移量作为key,这一行的内容作为value* 那么输出端的数据类型是什么,由于我们输出的数<hello,1>* 那么它们的数据类型就显而易见了* 初步定义为:* Mapper<Long, String, String, int>*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//读取一行数据String line = value.toString();//按照逗号切割String[] words = line.split(",");//遍历单词数组,输出为<K,V>形式 key是单词,value是1for (String word : words) {context.write(new Text(word),new IntWritable(1));}}}
TestReducer.java
import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @author HappyDragon1994*/public class TestReducer extends Reducer<Text, IntWritable,Text,Text> {//map处理之后,value传过来的是一个value的集合//框架在map处理完成之后,将所有的KV对保存起来,进行分组,然后传递一个组,调用一次reduce//相同的key在一个组@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int count = 0;for (IntWritable value : values) {//get()方法就能拿到里面的值count += value.get();}context.write(key,new Text(String.valueOf(count)));}}
TestRunner.java
import com.zym.mapper.TestMapper;import com.zym.reducer.TestReducer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @author HappyDragon1994*/public class TestRunner {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Job job = Job.getInstance(new Configuration());//job用哪个类作为Mapper 指定输入输出数据类型是什么job.setMapperClass(TestMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//job用哪个类作为Reducer 指定数据输入输出类型是什么job.setReducerClass(TestReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);//指定原始数据存放在哪里//参数1:里面是对哪个参数进行指定//参数2:文件在哪个路径下,这个路径下的所有文件都会去读的FileInputFormat.setInputPaths(job,new Path("hdfs://hadoop0:9000/test"));FileOutputFormat.setOutputPath(job,new Path("hdfs://hadoop0:9000/output"));//提交int isok = job.waitForCompletion(true)?0:-1;System.exit(isok);}}
然后我们先给HDFS下的/test路径上传一个WordCount.txt文件,文件内容如下
hello,worldhello,javahello,mysqlhello,pythonhello,hadoop
然后我们运行main方法,利用BigDataTools插件可以看到生成了output文件夹
生成的结果是名为part-r-00000这个文件,我们打开查看一下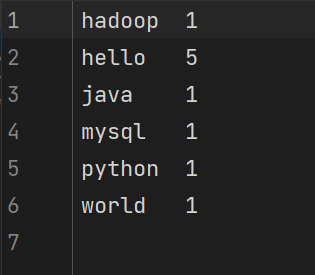
这样,我们一个简单的MapReduce入门案例就完成了
总结:MapReduce将复杂的、运行于大规模集群上的并行计算过程高度抽象为两个函数:Map与Reduce,极大地方便了分布式编程工作,程序员只需将注意力放在Map与Reduce即可,其他的并不需要理会,极大地降低了并行计算的难度。
参考博客:https://blog.csdn.net/qq_35078688/article/details/83240661

若有收获,就点个赞吧
0 人点赞
