Kubernetes
kubernetes 已经成为容器编排领域的王者,它是基于容器的集群编排引擎,具备扩展集群、滚动升级回滚、弹性伸缩、自动治愈、服务发现等多种特性能力。
kubernetes 架构
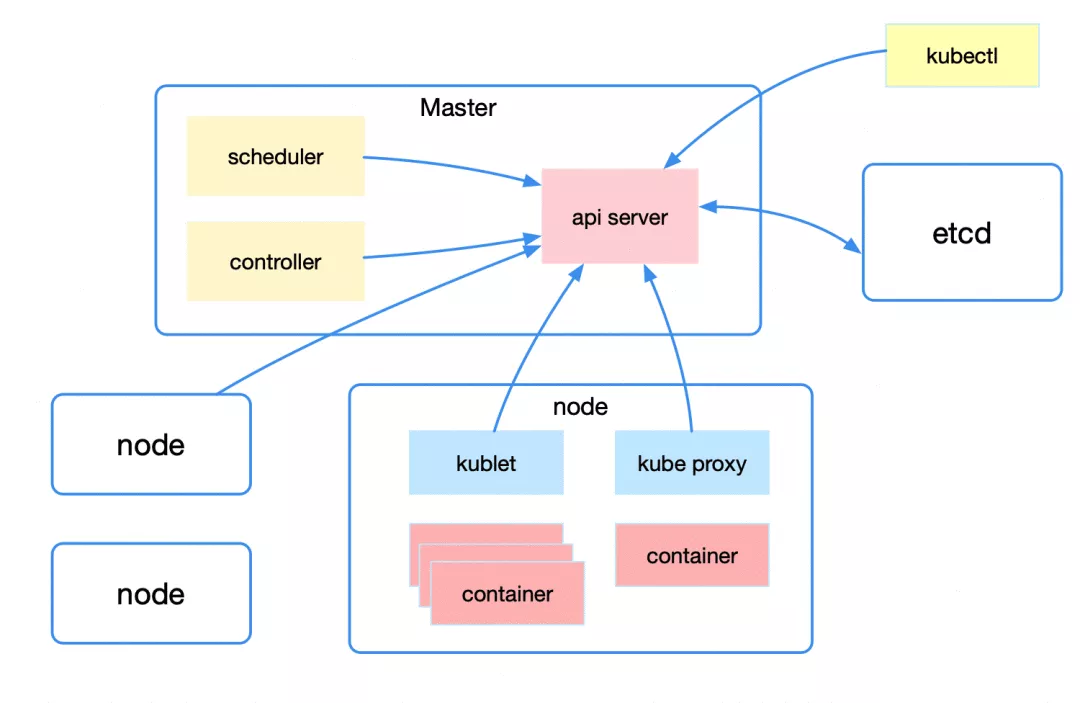
从宏观上来看 kubernetes 的整体架构,包括 Master、Node 以及 Etcd。
Master 即主节点,负责控制整个 kubernetes 集群。它包括 Api Server、Scheduler、Controller 等组成部分。它们都需要和 Etcd 进行交互以存储数据。
- Api Server: 主要提供资源操作的统一入口,这样就屏蔽了与 Etcd 的直接交互。功能包括安全、注册与发现等。
- Scheduler: 负责按照一定的调度规则将 Pod 调度到 Node 上。
- Controller: 资源控制中心,确保资源处于预期的工作状态。
Node 即工作节点,为整个集群提供计算力,是容器真正运行的地方,包括运行容器、kubelet、kube-proxy。
- kubelet: 主要工作包括管理容器的生命周期、结合 cAdvisor 进行监控、健康检查以及定期上报节点状态。
- kube-proxy: 主要利用 service 提供集群内部的服务发现和负载均衡,同时监听 service/endpoints 变化并刷新负载均衡。
从创建 deployment 开始
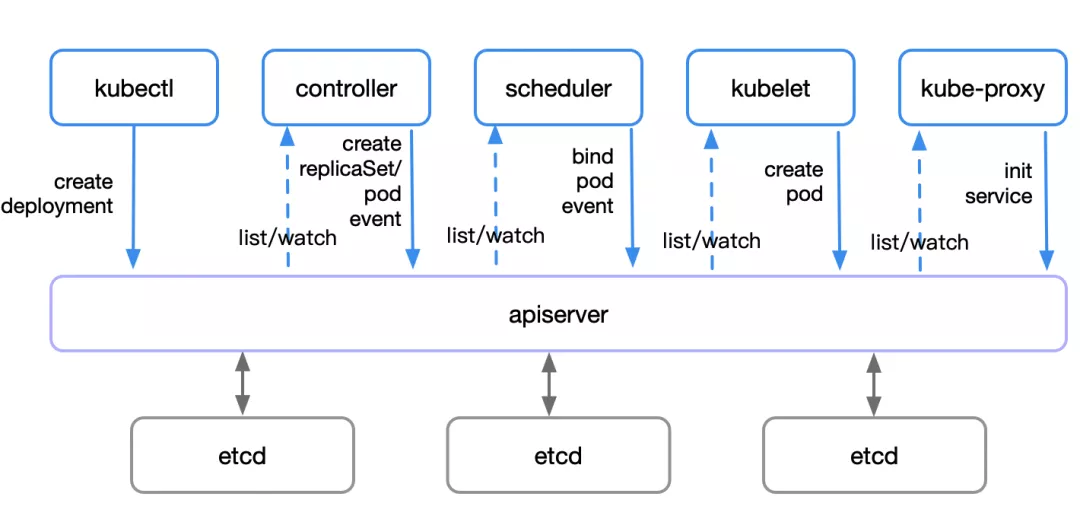
deployment 是用于编排 pod 的一种控制器资源。这里以 deployment 为例,来看看架构中的各组件在创建 deployment 资源的过程中都干了什么。
1、首先是 kubectl 发起一个创建 deployment 的请求
2、apiserver 接收到创建 deployment 请求,将相关资源写入 etcd;之后所有组件与 apiserver/etcd 的交互都是类似的
3、deployment controller list/watch 资源变化并发起创建 replicaSet 请求
4、replicaSet controller list/watch 资源变化并发起创建 pod 请求
5、scheduler 检测到未绑定的 pod 资源,通过一系列匹配以及过滤选择合适的 node 进行绑定
6、kubelet 发现自己 node 上需创建新 pod,负责 pod 的创建及后续生命周期管理
7、kube-proxy 负责初始化 service 相关的资源,包括服务发现、负载均衡等网络规则
至此,经过 kubenetes 各组件的分工协调,完成了从创建一个 deployment 请求开始到具体各 pod 正常运行的全过程。Pod
在 kubernetes 众多的 api 资源中,pod 是最重要和基础的,是最小的部署单元。
首先要考虑的问题是,为什么需要 pod?pod 可以说是一种容器设计模式,它为那些”超亲密”关系的容器而设计,可以想象 servelet 容器部署 war 包、日志收集等场景,这些容器之间往往需要共享网络、共享存储、共享配置,因此有了 pod 这个概念。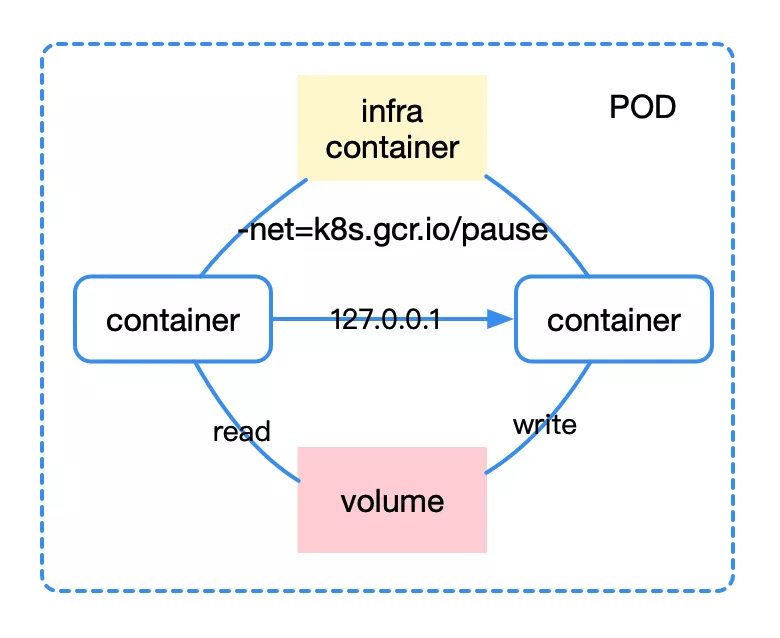
对于 pod 来说,不同 container 之间通过 infra container 的方式统一识别外部网络空间,而通过挂载同一份 volume 就自然可以共享存储了,比如它对应宿主机上的一个目录。容器编排
容器编排是 kubernetes 的看家本领了,所以有必要了解一下。kubernetes 中有诸多编排相关的控制资源,例如编排无状态应用的 deployment,编排有状态应用的 statefulset,编排守护进程 daemonset 以及编排离线业务的 job/cronjob 等等。
还是以应用最广泛的 deployment 为例。deployment、replicatset、pod 之间的关系是一种层层控制的关系。简单来说,replicaset 控制 pod 的数量,而 deployment 控制 replicaset 的版本属性。这种设计模式也为两种最基本的编排动作实现了基础,即数量控制的水平扩缩容、版本属性控制的更新/回滚。水平扩缩容
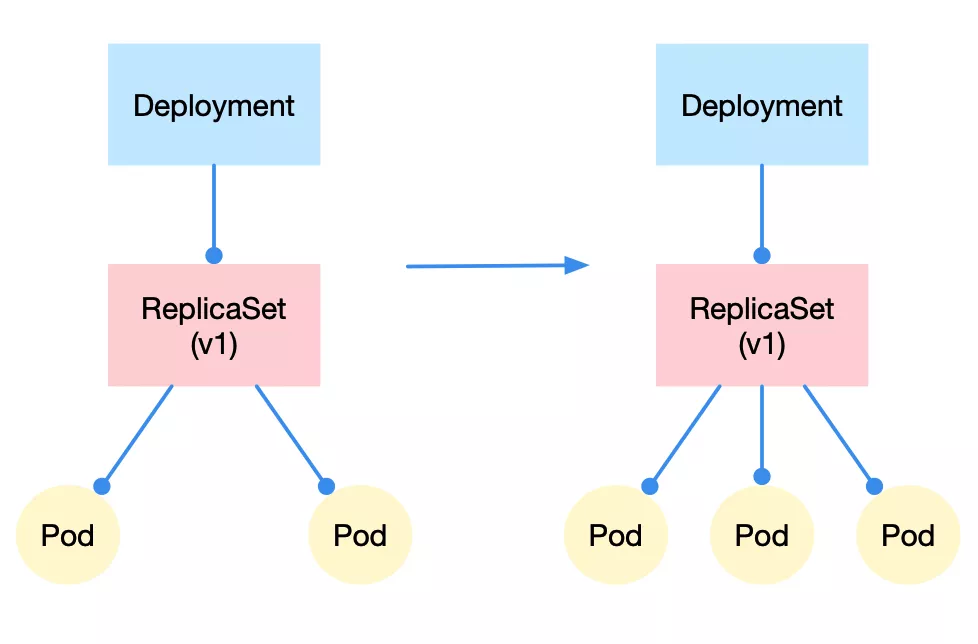
水平扩缩容非常好理解,只需修改 replicaset 控制的 pod 副本数量即可,比如从 2 改到 3,那么就完成了水平扩容这个动作,反之即水平收缩。更新/回滚
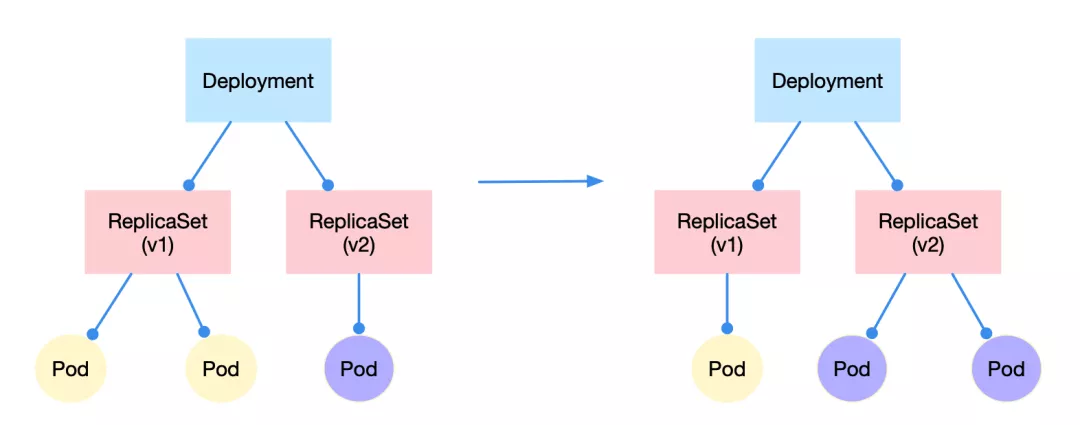
更新/回滚则体现了 replicaset 这个对象的存在必要性。例如需要应用 3 个实例的版本从 v1 改到 v2,那么 v1 版本 replicaset 控制的 pod 副本数会逐渐从 3 变到 0,而 v2 版本 replicaset 控制的 pod 数会注解从 0 变到 3,当 deployment 下只存在 v2 版本的 replicaset 时变完成了更新。回滚的动作与之相反。滚动更新
可以发现,在上述例子中,更新应用,pod 总是一个一个升级,并且最小有 2 个 pod 处于可用状态,最多有 4 个 pod 提供服务。这种”滚动更新”的好处是显而易见的,一旦新的版本有了 bug,那么剩下的 2 个 pod 仍然能够提供服务,同时方便快速回滚。
在实际应用中可以通过配置 RollingUpdateStrategy 来控制滚动更新策略,maxSurge 表示 deployment 控制器还可以创建多少个新 Pod;而 maxUnavailable 指的是,deployment 控制器可以删除多少个旧 Pod。kubernetes 中的网络
了解了容器编排是怎么完成的,那么容器间的又是怎么通信的呢?
讲到网络通信,kubernetes 首先得有”三通”基础:
1、node 到 pod 之间可以通
2、node 的 pod 之间可以通
3、不同 node 之间的 pod 可以通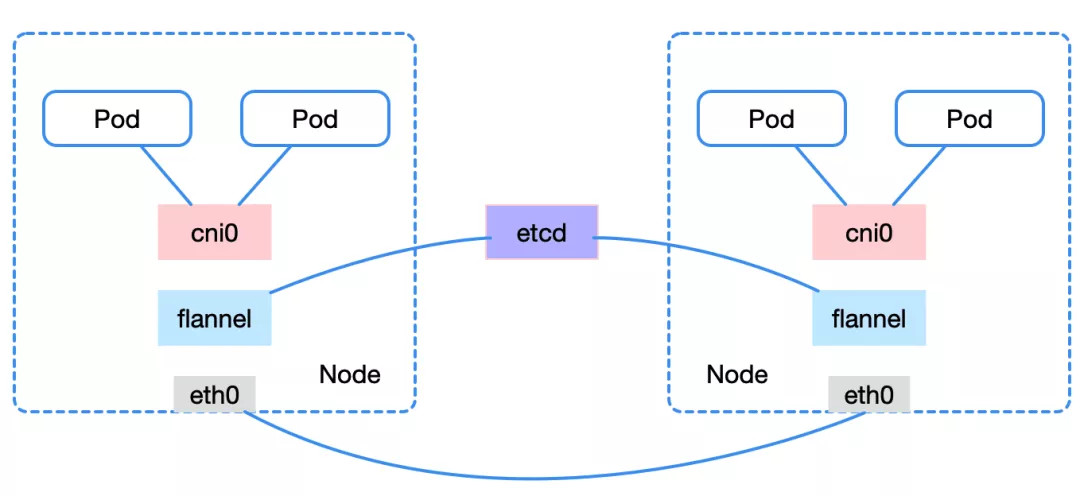
简单来说,不同 pod 之间通过 cni0/docker0 网桥实现了通信,node 访问 pod 也是通过 cni0/docker0 网桥通信即可。而不同 node 之间的 pod 通信有很多种实现方案,包括现在比较普遍的 flannel 的 vxlan/hostgw 模式等。flannel 通过 etcd 获知其他 node 的网络信息,并会为本 node 创建路由表,最终使得不同 node 间可以实现跨主机通信。微服务—service
在了解接下来的内容之前,得先了解一个很重要的资源对象:service。
为什么需要 service 呢?在微服务中,pod 可以对应实例,那么 service 对应的就是一个微服务。而在服务调用过程中,service 的出现解决了两个问题:
1、pod 的 ip 不是固定的,利用非固定 ip 进行网络调用不现实
2、服务调用需要对不同 pod 进行负载均衡
service 通过 label 选择器选取合适的 pod,构建出一个 endpoints,即 pod 负载均衡列表。实际运用中,一般会为同一个微服务的 pod 实例都打上类似app=xxx的标签,同时为该微服务创建一个标签选择器为app=xxx的 service。kubernetes 中的服务发现与网络调用
在有了上述”三通”的网络基础后,可以开始微服务架构中的网络调用在 kubernetes 中是怎么实现的了。
这部分内容其实在说说 Kubernetes 是怎么实现服务发现的(https://fredal.xin/kubertnetes-discovery)已经讲得比较清楚了,比较细节的地方可以参考上述文章,这里做一个简单的介绍。服务间调用
首先是东西向的流量调用,即服务间调用。这部分主要包括两种调用方式,即 clusterIp 模式以及 dns 模式。
clusterIp 是 service 的一种类型,在这种类型模式下,kube-proxy 通过 iptables/ipvs 为 service 实现了一种 VIP(虚拟 ip)的形式。只需要访问该 VIP,即可负载均衡地访问到 service 背后的 pod。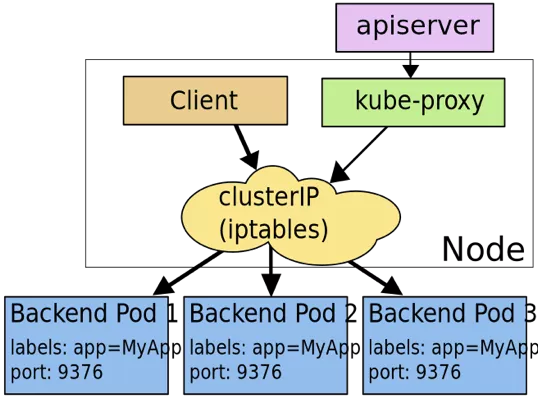
上图是 clusterIp 的一种实现方式,此外还包括 userSpace 代理模式(基本不用),以及 ipvs 模式(性能更好)。
dns 模式很好理解,对 clusterIp 模式的 service 来说,它有一个 A 记录是 service-name.namespace-name.svc.cluster.local,指向 clusterIp 地址。所以一般使用过程中,直接调用 service-name 即可。服务外访问
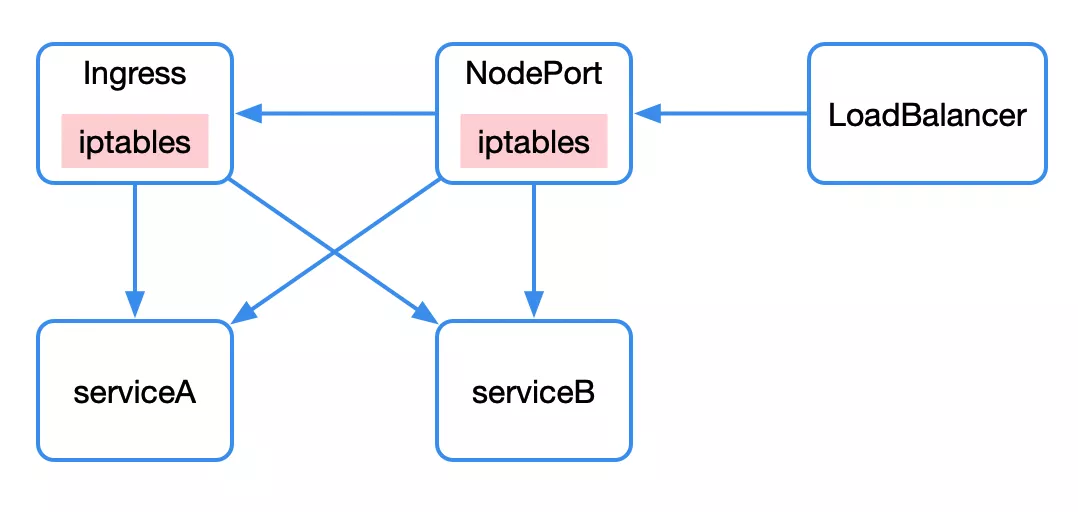
南北向的流量,即外部请求访问 kubernetes 集群,主要包括三种方式:nodePort、loadbalancer、ingress。
nodePort 同样是 service 的一种类型,通过 iptables 赋予了调用宿主机上的特定 port 就能访问到背后 service 的能力。
loadbalancer 则是另一种 service 类型,通过公有云提供的负载均衡器实现。
访问 100 个服务可能需要创建 100 个 nodePort/loadbalancer。希望通过一个统一的外部接入层访问内部 kubernetes 集群,这就是 ingress 的功能。ingress 提供了统一接入层,通过路由规则的不同匹配到后端不同的 service 上。ingress 可以看做是”service 的 service”。ingress 在实现上往往结合 nodePort 以及 loadbalancer 完成功能。
到现在为止,简单了解了 kubernetes 的相关概念,它大致是怎么运作的,以及微服务是怎么运行在 kubernetes 中的。

若有收获,就点个赞吧
0 人点赞
