机器需求
准备机器。最直接的办法,到公有云上申请几个虚拟机。当然,如果条件允许的话,拿几台本地的物理服务器来组集群是最好不过了。这些机器只要满足如下几个条件即可:
- 满足安装 Docker 项目所需的要求,比如 64 位的 Linux 操作系统、3.10 及以上的内核版本;
- x86 或者 ARM 架构均可;
- 机器之间网络互通,这是将来容器之间网络互通的前提;
- 有外网访问权限,因为需要拉取镜像;
- 能够访问到gcr.io、quay.io这两个 docker registry,因为有小部分镜像需要在这里拉取;
- 单机可用资源建议 2 核 CPU、8 GB 内存最低4GB或以上,再小的话问题也不大,但是能调度的 Pod 数量就比较有限了;
- 30 GB 或以上的可用磁盘空间,这主要是留给 Docker 镜像和日志文件用的。否则会导致Pod因为磁盘不足被驱逐。
部署 Kubernetes 的 Master 节点
kubeadm 可以一键部署 Master 节点。可以通过配置文件来开启一些实验性功能。
这里编写了一个给 kubeadm 用的 YAML 文件(名叫:kubeadm.yaml):
apiVersion: kubeadm.k8s.io/v1alpha1kind: MasterConfigurationcontrollerManagerExtraArgs:horizontal-pod-autoscaler-use-rest-clients: "true"horizontal-pod-autoscaler-sync-period: "10s"node-monitor-grace-period: "10s"apiServerExtraArgs:runtime-config: "api/all=true"kubernetesVersion: "1.23.1"
这个配置中,给 kube-controller-manager 设置了:
horizontal-pod-autoscaler-use-rest-clients: "true"
这意味着,将来部署的 kube-controller-manager 能够使用自定义资源(Custom Metrics)进行自动水平扩展。
然后,只需要参数指定对应的配置文件:
$ kubeadm init --config kubeadm.yaml
就可以完成 Kubernetes Master 的部署了,这个过程只需要几分钟。部署完成后,kubeadm 会生成一行指令:
kubeadm join 10.168.0.2:6443 --token 00bwbx.uvnaa2ewjflwu1ry --discovery-token-ca-cert-hash sha256:00eb62a2a6020f94132e3fe1ab721349bbcd3e9b94da9654cfe15f2985ebd711
这个 kubeadm join 命令,就是用来给 Master 节点添加更多工作节点(Worker)的命令。在后面部署 Worker 节点的时候马上会用到它,所以找一个地方把这条命令记录下来。
此外,kubeadm 还会提示第一次使用 Kubernetes 集群所需要的配置命令:
mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config
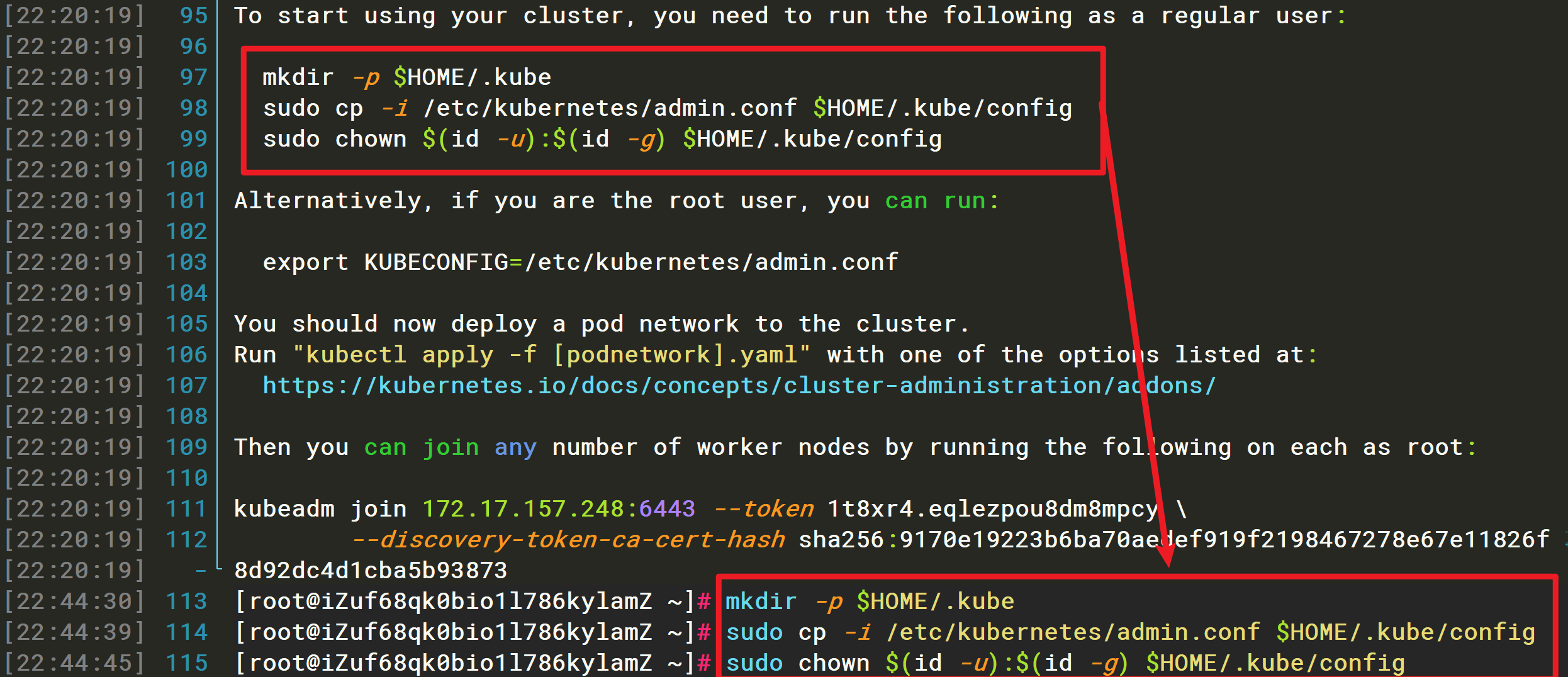
而需要这些配置命令的原因是:Kubernetes 集群默认需要加密方式访问。所以,这几条命令,就是将刚刚部署生成的 Kubernetes 集群的安全配置文件,保存到当前用户的.kube 目录下,kubectl 默认会使用这个目录下的授权信息访问 Kubernetes 集群。
如果不这么做的话,每次都需要通过 export KUBECONFIG 环境变量告诉 kubectl 这个安全配置文件的位置。
现在,就可以使用 kubectl get 命令来查看当前唯一一个节点的状态了:
$ kubectl get nodesNAME STATUS ROLES AGE VERSIONmaster NotReady master 1d v1.11.1

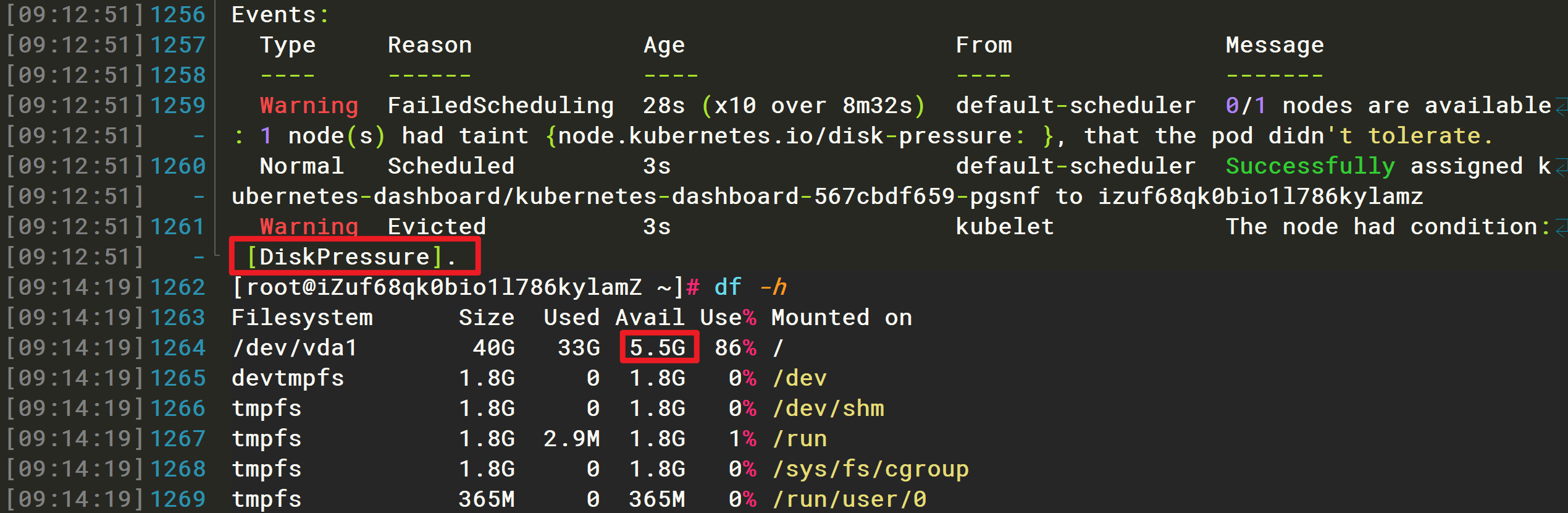
可以看到,这个 get 指令输出的结果里,Master 节点的状态是 NotReady,这是为什么呢?
在调试 Kubernetes 集群时,最重要的手段就是用 kubectl describe 来查看这个节点(Node)对象的详细信息、状态和事件(Event),来试一下:
$ kubectl describe node master...Conditions:...Ready False ... KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
通过 kubectl describe 指令的输出,可以看到 NodeNotReady 的原因在于,尚未部署任何网络插件。
另外,还可以通过 kubectl 检查这个节点上各个系统 Pod 的状态,其中,kube-system 是 Kubernetes 项目预留的系统 Pod 的工作空间(Namepsace,注意它并不是 Linux Namespace,它只是 Kubernetes 划分不同工作空间的单位):
$ kubectl get pods -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-78fcdf6894-j9s52 0/1 Pending 0 1hcoredns-78fcdf6894-jm4wf 0/1 Pending 0 1hetcd-master 1/1 Running 0 2skube-apiserver-master 1/1 Running 0 1skube-controller-manager-master 0/1 Pending 0 1skube-proxy-xbd47 1/1 NodeLost 0 1hkube-scheduler-master 1/1 Running 0 1s
可以看到,CoreDNS、kube-controller-manager 等依赖于网络的 Pod 都处于 Pending 状态,即调度失败。这当然是符合预期的:因为这个 Master 节点的网络尚未就绪。
部署网络插件
在 Kubernetes 项目“一切皆容器”的设计理念指导下,部署网络插件非常简单,只需要执行一句 kubectl apply 指令,以 Weave 为例:
$ kubectl apply -f weave-daemonset-k8s-1.11.yaml

部署完成后,可以通过 kubectl get 重新检查 Pod 的状态:
$ kubectl get pods -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-78fcdf6894-j9s52 1/1 Running 0 1dcoredns-78fcdf6894-jm4wf 1/1 Running 0 1detcd-master 1/1 Running 0 9skube-apiserver-master 1/1 Running 0 9skube-controller-manager-master 1/1 Running 0 9skube-proxy-xbd47 1/1 Running 0 1dkube-scheduler-master 1/1 Running 0 9sweave-net-cmk27 2/2 Running 0 19s
可以看到,所有的系统 Pod 都成功启动了,而刚刚部署的 Weave 网络插件则在 kube-system 下面新建了一个名叫 weave-net-cmk27 的 Pod,一般来说,这些 Pod 就是容器网络插件在每个节点上的控制组件。
Kubernetes 支持容器网络插件,使用的是一个名叫 CNI 的通用接口,它也是当前容器网络的事实标准,市面上的所有容器网络开源项目都可以通过 CNI 接入 Kubernetes,比如 Flannel、Calico、Canal、Romana 等等,它们的部署方式也都是类似的“一键部署”。
至此,Kubernetes 的 Master 节点就部署完成了。如果只需要一个单节点的 Kubernetes,现在就可以使用了。不过,在默认情况下,Kubernetes 的 Master 节点是不能运行用户 Pod 的,所以还需要额外做一个小操作。
部署 Kubernetes 的 Worker 节点
Kubernetes 的 Worker 节点跟 Master 节点几乎是相同的,它们运行着的都是一个 kubelet 组件。唯一的区别在于,在 kubeadm init 的过程中,kubelet 启动后,Master 节点上还会自动运行 kube-apiserver、kube-scheduler、kube-controller-manger 这三个系统 Pod。
所以,相比之下,部署 Worker 节点反而是最简单的,只需要两步即可完成。
第一步,在所有 Worker 节点上执行“安装 kubeadm 和 Docker”。
第二步,执行部署 Master 节点时生成的 kubeadm join 指令:
$ kubeadm join 10.168.0.2:6443 --token 00bwbx.uvnaa2ewjflwu1ry --discovery-token-ca-cert-hash sha256:00eb62a2a6020f94132e3fe1ab721349bbcd3e9b94da9654cfe15f2985ebd711
通过 Taint/Toleration 调整 Master 执行 Pod 的策略
默认情况下 Master 节点是不允许运行用户 Pod 的。而 Kubernetes 做到这一点,依靠的是 Kubernetes 的 Taint/Toleration 机制。
它的原理非常简单:一旦某个节点被加上了一个 Taint,即被“打上了污点”,那么所有 Pod 就都不能在这个节点上运行,因为 Kubernetes 的 Pod 都有“洁癖”。
除非,有个别的 Pod 声明自己能“容忍”这个“污点”,即声明了 Toleration,它才可以在这个节点上运行。
为节点打上“污点”(Taint)的命令是:
$ kubectl taint nodes node1 foo=bar:NoSchedule
这时,该 node1 节点上就会增加一个键值对格式的 Taint,即:foo=bar:NoSchedule。其中值里面的 NoSchedule,意味着这个 Taint 只会在调度新 Pod 时产生作用,而不会影响已经在 node1 上运行的 Pod,哪怕它们没有 Toleration。
污点可选参数:
- NoSchedule: 一定不能被调度
- PreferNoSchedule: 尽量不要调度
- NoExecute: 不仅不会调度, 还会驱逐Node上已有的Pod
Pod 声明 Toleration
只要在 Pod 的.yaml 文件中的 spec 部分,加入 tolerations 字段即可:
这个 Toleration 的含义是,这个 Pod 能“容忍”所有键值对为 foo=bar 的 Taint(apiVersion: v1kind: Pod...spec:tolerations:- key: "foo"operator: "Equal"value: "bar"effect: "NoSchedule"
operator: "Equal",“等于”操作)。
现在回到已经搭建的集群上来。这时,如果通过kubectl describe检查一下 Master 节点的 Taint 字段,就会有所发现了: ```bash $ kubectl describe node master
Name: master Roles: master Taints: node.kubernetes.io/disk-pressure:NoSchedule
可以看到,Master 节点默认被加上了node.kubernetes.io/disk-pressure:NoSchedule这样一个“污点”,其中“键”是node.kubernetes.io/disk-pressure,而没有提供“值”。<br />此时,就需要像下面这样用“Exists”操作符(`operator: "Exists"`,“存在”即可)来说明,该 Pod 能够容忍所有以 foo 为键的 Taint,才能让这个 Pod 运行在该 Master 节点上:```yamlapiVersion: v1kind: Pod...spec:tolerations:- key: "foo"operator: "Exists"effect: "NoSchedule"
允许master节点部署pod
当然,如果就是想要一个单节点的 Kubernetes,删除这个 Taint 才是正确的选择:
注意这里的键是通过kubectl describe node master命令查询出来的Taints键对应的值: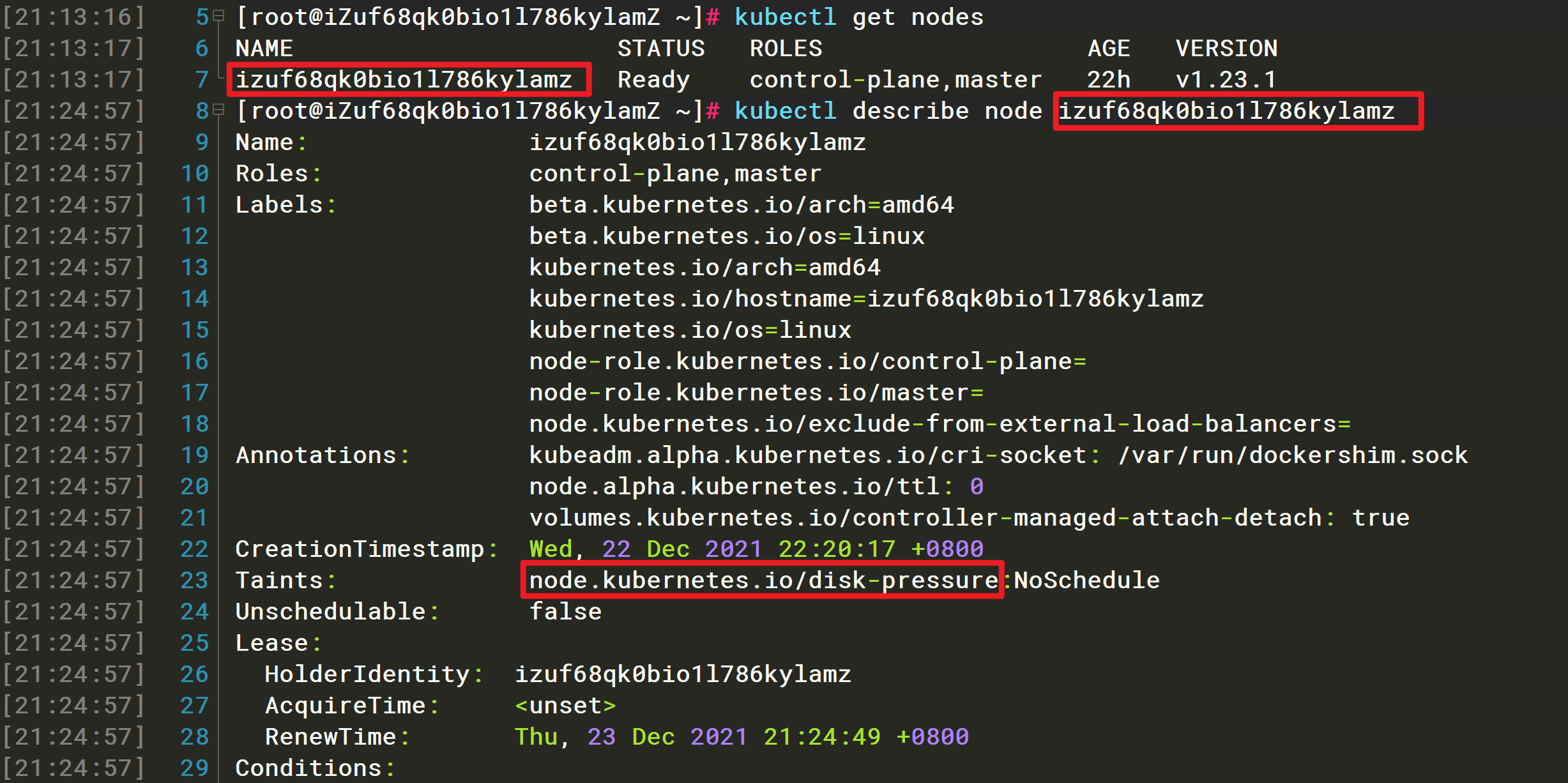
$ kubectl taint nodes --all node.kubernetes.io/disk-pressure-
如上所示,在“node.kubernetes.io/disk-pressure”这个键后面加上了一个短横线“-”,这个格式就意味着移除所有以“node.kubernetes.io/disk-pressure”为键的 Taint。
如果不允许调度,可以执行以下命令进行设置
kubectl taint nodes master1 node.kubernetes.io/disk-pressure=:NoSchedule
到了这一步,一个基本完整的 Kubernetes 集群就部署完毕了。
有了 kubeadm 这样的原生管理工具,Kubernetes 的部署已经被大大简化。更重要的是,像证书、授权、各个组件的配置等部署中最麻烦的操作,kubeadm 都已经完成了。
接下来,再在这个 Kubernetes 集群上安装一些其他的辅助插件,比如 Dashboard 和存储插件。
部署 Dashboard 可视化插件
在 Kubernetes 社区中,有一个很受欢迎的 Dashboard 项目,它可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。毫不意外,它的部署也相当简单:
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc6/aio/deploy/recommended.yaml
部署完成之后,就可以查看 Dashboard 对应的 Pod 的状态了:
$ kubectl get pods -n kube-systemkubernetes-dashboard-6948bdb78-f67xk 1/1 Running 0 1m
需要注意的是,由于 Dashboard 是一个 Web Server,很多人经常会在自己的公有云上无意地暴露 Dashboard 的端口,从而造成安全隐患。所以,1.7 版本之后的 Dashboard 项目部署完成后,默认只能通过 Proxy 的方式在本地访问。具体的操作,可以查看 Dashboard 项目的官方文档。
而如果想从集群外访问这个 Dashboard 的话,就需要用到 Ingress。
部署容器存储插件
很多时候需要用数据卷(Volume)把外面宿主机上的目录或者文件挂载进容器的 Mount Namespace 中,从而达到容器和宿主机共享这些目录或者文件的目的。容器里的应用,也就可以在这些数据卷中新建和写入文件。
可是,如果在某一台机器上启动的一个容器,显然无法看到其他机器上的容器在它们的数据卷里写入的文件。这是容器最典型的特征之一:无状态。
而容器的持久化存储,就是用来保存容器存储状态的重要手段:存储插件会在容器里挂载一个基于网络或者其他机制的远程数据卷,使得在容器里创建的文件,实际上是保存在远程存储服务器上,或者以分布式的方式保存在多个节点上,而与当前宿主机没有任何绑定关系。这样,无论在其他哪个宿主机上启动新的容器,都可以请求挂载指定的持久化存储卷,从而访问到数据卷里保存的内容。这就是“持久化”的含义。
由于 Kubernetes 本身的松耦合设计,绝大多数存储项目,比如 Ceph、GlusterFS、NFS 等,都可以为 Kubernetes 提供持久化存储能力。这里选择部署一个很重要的 Kubernetes 存储插件项目:Rook。
Rook 项目是一个基于 Ceph 的 Kubernetes 存储插件(它后期也在加入对更多存储实现的支持)。不过,不同于对 Ceph 的简单封装,Rook 在自己的实现中加入了水平扩展、迁移、灾难备份、监控等大量的企业级功能,使得这个项目变成了一个完整的、生产级别可用的容器存储插件。
得益于容器化技术,用几条指令,Rook 就可以把复杂的 Ceph 存储后端部署起来:
$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/common.yaml$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/operator.yaml$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/cluster.yaml
在部署完成后,就可以看到 Rook 项目会将自己的 Pod 放置在由它自己管理的两个 Namespace 当中:
$ kubectl get pods -n rook-ceph-systemNAME READY STATUS RESTARTS AGErook-ceph-agent-7cv62 1/1 Running 0 15srook-ceph-operator-78d498c68c-7fj72 1/1 Running 0 44srook-discover-2ctcv 1/1 Running 0 15s$ kubectl get pods -n rook-cephNAME READY STATUS RESTARTS AGErook-ceph-mon0-kxnzh 1/1 Running 0 13srook-ceph-mon1-7dn2t 1/1 Running 0 2s
这样,一个基于 Rook 持久化存储集群就以容器的方式运行起来了,而接下来在 Kubernetes 项目上创建的所有 Pod 就能够通过 Persistent Volume(PV)和 Persistent Volume Claim(PVC)的方式,在容器里挂载由 Ceph 提供的数据卷了。
而 Rook 项目,则会负责这些数据卷的生命周期管理、灾难备份等运维工作。
为什么要选择 Rook 项目呢?
因为这个项目很有前途。
如果去研究一下 Rook 项目的实现,就会发现它巧妙地依赖了 Kubernetes 提供的编排能力,合理的使用了很多诸如 Operator、CRD 等重要的扩展特性。这使得 Rook 项目,成为了目前社区中基于 Kubernetes API 构建的最完善也最成熟的容器存储插件。
备注:其实,在很多时候,所谓的“云原生”,就是“Kubernetes 原生”的意思。而像 Rook、Istio 这样的项目,正是贯彻这个思路的典范。

若有收获,就点个赞吧
0 人点赞
