Docker 网络
在物理机组成的网络里,最基础,最简单的网络连接方式是什么?没错,那就是直接用一根交叉网线把两台电脑的网卡连起来。这样,一台机器发送数据,另外一台就能收到了。
那么,网络虚拟化实现的第一步,就是用软件来模拟这个简单的网络连接实现过程。实现的技术就是 veth,它模拟了在物理世界里的两块网卡,以及一条网线。通过它可以将两个虚拟的设备连接起来,让他们之间相互通信。平时工作中在 Docker 镜像里看到的 eth0 设备,其实就是 veth。

事实上,这种软件模拟硬件方式一点儿也不陌生,本机网络 IO 里的 lo 回环设备也是这样一个用软件虚拟出来设备。Veth 和 lo 的一点区别就是 veth 总是成双成对地出现。
来深入地看看 veth 的工作原理。
一、veth 如何使用
不像回环设备,绝大多数同学在日常工作中可能都没接触过 veth。所以先来看看 veth 是如何使用的。
在 Linux 下,可以通过使用 ip 命令创建一对儿 veth。其中 link 表示 link layer的意思,即链路层。这个命令可以用于管理和查看网络接口,包括物理网络接口,也包括虚拟接口。
# ip link add veth0 type veth peer name veth1
使用 ip link show 来进行查看。
# ip link add veth0 type veth peer name veth1# ip link show1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULTlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:002: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT qlen 1000link/ether 6c:0b:84:d5:88:d1 brd ff:ff:ff:ff:ff:ff3: eth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000link/ether 6c:0b:84:d5:88:d2 brd ff:ff:ff:ff:ff:ff4: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000link/ether 4e:ac:33:e5:eb:16 brd ff:ff:ff:ff:ff:ff5: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000link/ether 2a:6d:65:74:30:fb brd ff:ff:ff:ff:ff:ff
和 eth0、lo 等网络设备一样,veth 也需要为其配置上 ip 后才能够正常工作。为这对儿 veth 分别来配置上 IP。
# ip addr add 192.168.1.1/24 dev veth0# ip addr add 192.168.1.2/24 dev veth1
接下来,把这两个设备启动起来。
# ip link set veth0 up# ip link set veth1 up
当设备启动起来以后,通过熟悉的 ifconfig 就可以查看到它们了。
# ifconfigeth0: ......lo: ......veth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 192.168.1.1 netmask 255.255.255.0 broadcast 0.0.0.0......veth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 192.168.1.2 netmask 255.255.255.0 broadcast 0.0.0.0......
现在,一对儿虚拟设备已经建立起来了。不过需要做一点准备工作,它们之间才可以进行互相通信。首先要关闭反向过滤 rp_filter,该模块会检查 IP 包是否符合要求,否则可能会过滤掉。然后再打开 accept_local,接收本机 IP 数据包。详细准备过程如下:
# echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter# echo 0 > /proc/sys/net/ipv4/conf/veth0/rp_filter# echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter# echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local# echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local
在 veth0 上来 ping 一下 veth1。这两个 veth 之间可以通信了!
# ping 192.168.1.2 -I veth0PING 192.168.1.2 (192.168.1.2) from 192.168.1.1 veth0: 56(84) bytes of data.64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.019 ms64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.010 ms64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.010 ms...
在另外一个控制台上,还启动了 tcpdump 抓包,抓到的结果如下。
# tcpdump -i veth009:59:39.449247 ARP, Request who-has *** tell ***, length 2809:59:39.449259 ARP, Reply *** is-at 4e:ac:33:e5:eb:16 (oui Unknown), length 2809:59:39.449262 IP *** > ***: ICMP echo request, id 15841, seq 1, length 6409:59:40.448689 IP *** > ***: ICMP echo request, id 15841, seq 2, length 6409:59:41.448684 IP *** > ***: ICMP echo request, id 15841, seq 3, length 6409:59:42.448687 IP *** > ***: ICMP echo request, id 15841, seq 4, length 6409:59:43.448686 IP *** > ***: ICMP echo request, id 15841, seq 5, length 64
由于两个设备之间是首次通信的,所以 veth0 首先先发出了一个 arp request,veth1 收到后回复了一个 arp reply。然后接下来就是正常的 ping 命令下的 IP 包了。
二、veth 底层创建过程
在上一小节中亲手创建了一对儿 veth 设备,并通过简单的配置就可以让他们之间互相进行通信了。那么在本小节中,看看在内核里,veth 到底是如何创建的。
Veth 相关源码位于 drivers/net/veth.c,其中初始化入口是 veth_init。
//file: drivers/net/veth.cstatic __init int veth_init(void){return rtnl_link_register(&veth_link_ops);}
在 veth_init 中注册了 veth_link_ops(veth 设备的操作方法),它包含了 veth 设备的创建、启动和删除等回调函数。
//file: drivers/net/veth.cstatic struct rtnl_link_ops veth_link_ops = {.kind = DRV_NAME,.priv_size = sizeof(struct veth_priv),.setup = veth_setup,.validate = veth_validate,.newlink = veth_newlink,.dellink = veth_dellink,.policy = veth_policy,.maxtype = VETH_INFO_MAX,};
先来看下 veth 设备的创建函数 veth_newlink,这是理解 veth 的关键之处。
//file: drivers/net/veth.cstatic int veth_newlink(struct net *src_net, struct net_device *dev,struct nlattr *tb[], struct nlattr *data[]){...//创建peer = rtnl_create_link(net, ifname, &veth_link_ops, tbp);//注册err = register_netdevice(peer);err = register_netdevice(dev);...//把两个设备关联到一起priv = netdev_priv(dev);rcu_assign_pointer(priv->peer, peer);priv = netdev_priv(peer);rcu_assign_pointer(priv->peer, dev);}
在 veth_newlink 中,可以看到它通过 register_netdevice 创建了 peer 和 dev 两个网络虚拟设备。接下来的 netdev_priv 函数返回的是网络设备的 private 数据,priv->peer 就是一个指针而已。
//file: drivers/net/veth.cstruct veth_priv {struct net_device __rcu *peer;atomic64_t dropped;};
两个新创建出来的设备 dev 和 peer 通过 priv->peer 指针来完成结对。其中 dev 设备里的 priv->peer 指针指向 peer 设备, peer 设备里的 priv->peer 指向 dev。
接着再看下 veth 设备的启动过程。
//file: drivers/net/veth.cstatic void veth_setup(struct net_device *dev){//veth的操作列表,其中包括veth的发送函数veth_xmitdev->netdev_ops = &veth_netdev_ops;dev->ethtool_ops = &veth_ethtool_ops;......}
其中 dev->netdev_ops = &veth_netdev_ops 这行也比较关键。veth_netdev_ops 是 veth 设备的操作函数。例如发送过程中调用的函数指针 ndo_start_xmit,对于 veth 设备来说就会调用到 veth_xmit。这个在下一个小节里会用到。
//file: drivers/net/veth.cstatic const struct net_device_ops veth_netdev_ops = {.ndo_init = veth_dev_init,.ndo_open = veth_open,.ndo_stop = veth_close,.ndo_start_xmit = veth_xmit,.ndo_change_mtu = veth_change_mtu,.ndo_get_stats64 = veth_get_stats64,.ndo_set_mac_address = eth_mac_addr,};
三、veth 网络通信过程
回顾一下基于回环设备 lo 的本机网络过程。在发送阶段里,流程分别是 send 系统调用 => 协议栈 => 邻居子系统 => 网络设备层 => 驱动。在接收阶段里,流程分别是软中断 => 驱动 => 网络设备层 => 协议栈 => 系统调用返回。过程图示如下: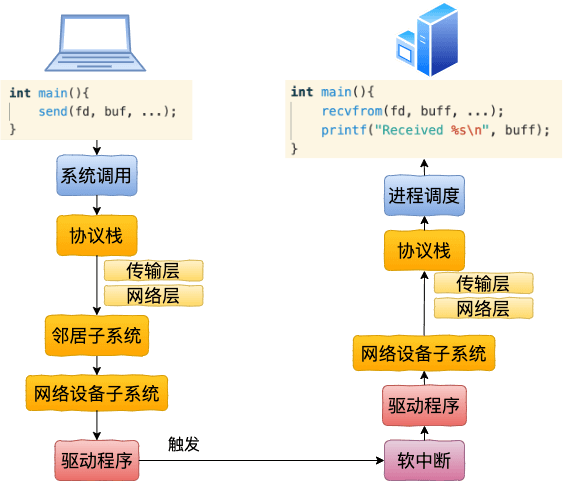
基于 veth 的网络 IO 过程和上面这个过程图几乎完全一样。和 lo 设备所不同的就是使用的驱动程序不一样,马上就能看到。
网络设备层最后会通过 ops->ndo_start_xmit 来调用驱动进行真正的发送。
//file: net/core/dev.cint dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,struct netdev_queue *txq){//获取设备驱动的回调函数集合 opsconst struct net_device_ops *ops = dev->netdev_ops;//调用驱动的 ndo_start_xmit 来进行发送rc = ops->ndo_start_xmit(skb, dev);...}
对于回环设备 lo 来说 netdev_ops 是 loopback_ops。那么 ops->ndo_start_xmit 对应的就是 loopback_xmit。
//file:drivers/net/loopback.cstatic const struct net_device_ops loopback_ops = {.ndo_init = loopback_dev_init,.ndo_start_xmit= loopback_xmit,.ndo_get_stats64 = loopback_get_stats64,};
回顾本文上一小节中,对于 veth 设备来说,它在启动的时候将 netdev_ops 设置成了 veth_netdev_ops。那 ops->ndo_start_xmit 对应的具体发送函数就是 veth_xmit。这就是在整个发送的过程中,唯一和 lo 设备不同的地方所在。来简单看一下这个发送函数的代码。
//file: drivers/net/veth.cstatic netdev_tx_t veth_xmit(struct sk_buff *skb, struct net_device *dev){struct veth_priv *priv = netdev_priv(dev);struct net_device *rcv;//获取 veth 设备的对端rcv = rcu_dereference(priv->peer);//调用 dev_forward_skb 向对端发包if (likely(dev_forward_skb(rcv, skb) == NET_RX_SUCCESS)) {}
在 veth_xmit 中主要就是获取一下当前 veth 设备,然后向对端把数据发送过去就行了。发送到对端设备的工作是由 dev_forward_skb 函数来处理的。
//file: net/core/dev.cint dev_forward_skb(struct net_device *dev, struct sk_buff *skb){skb->protocol = eth_type_trans(skb, dev);...return netif_rx(skb);}
先调用了 eth_type_trans 将 skb 的所属设备改为了刚刚取到的 veth 的对端设备 rcv。
//file: net/ethernet/eth.c__be16 eth_type_trans(struct sk_buff *skb, struct net_device *dev){skb->dev = dev;...}
接着调用 netif_rx,这块又和 lo 设备的操作一样了。在该方法中最终会执行到 enqueue_to_backlog 中(netif_rx -> netif_rx_internal -> enqueue_to_backlog)。在这里将要发送的 skb 插入 softnet_data->input_pkt_queue 队列中并调用 ____napi_schedule 来触发软中断,见下面的代码。
//file: net/core/dev.cstatic int enqueue_to_backlog(struct sk_buff *skb, int cpu,unsigned int *qtail){sd = &per_cpu(softnet_data, cpu);__skb_queue_tail(&sd->input_pkt_queue, skb);...____napi_schedule(sd, &sd->backlog);}//file:net/core/dev.cstatic inline void ____napi_schedule(struct softnet_data *sd,struct napi_struct *napi){list_add_tail(&napi->poll_list, &sd->poll_list);__raise_softirq_irqoff(NET_RX_SOFTIRQ);}
当数据发送完唤起软中断后,veth 对端的设备开始接收。和发送过程不同的是,所有的虚拟设备的收包 poll 函数都是一样的,都是在设备层被初始化成了 process_backlog。
//file:net/core/dev.cstatic int __init net_dev_init(void){for_each_possible_cpu(i) {sd->backlog.poll = process_backlog;}}
所以 veth 设备的接收过程和 lo 设备完全一样。大致流程是 net_rx_action 执行到 deliver_skb,然后送到协议栈中。
|--->net_rx_action()|--->process_backlog()|--->__netif_receive_skb()|--->__netif_receive_skb_core()|---> deliver_skb
总结
由于大部分的同学在日常工作中一般不会接触到 veth,所以在看到 Docker 相关的技术文中提到这个技术时总会以为它是多么的高深。
其实从实现上来看,虚拟设备 veth 和日常接触的 lo 设备非常非常的像。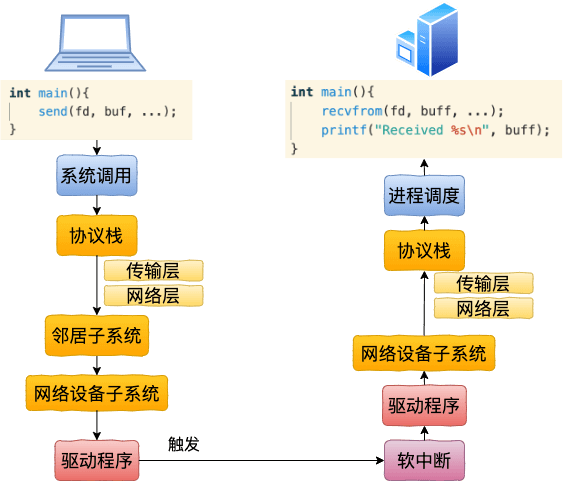
只不过和 lo 设备相比,veth 是为了虚拟化技术而生的,所以它多了个结对的概念。在创建函数 veth_newlink 中,一次性就创建了两个网络设备出来,并把对方分别设置成了各自的 peer。在发送数据的过程中,找到发送设备的 peer,然后发起软中断让对方收取就算完事了。

若有收获,就点个赞吧
0 人点赞
