前言
Docker集群管理和编排的特性是通过SwarmKit进行构建的, 其中Swarm mode是Docker Engine内置支持的一种默认实现。Docker 1.12以及更新的版本,都支持Swarm mode,可以基于Docker Engine来构建Swarm集群,然后就可以将应用服务(Application Service)部署到Swarm集群中。创建Swarm集群的方式很简单,先初始化一个Swarm集群,然后将其他的Node加入到该集群即可。本文主要基于Docker Swarm官网文档,学习总结。
基本特性
集群管理集成进Docker Engine
使用内置的集群管理功能,可以直接通过Docker CLI命令来创建Swarm集群,然后去部署应用服务,而不再需要其它外部的软件来创建和管理一个Swarm集群。
去中心化设计
Swarm集群中包含Manager和Worker两类Node,可以直接基于Docker Engine来部署任何类型的Node。而且,在Swarm集群运行期间,既可以对其作出任何改变,实现对集群的扩容和缩容等,如添加Manager Node,如删除Worker Node,而做这些操作不需要暂停或重启当前的Swarm集群服务。
声明式服务模型(Declarative Service Model)
在实现的应用栈中,Docker Engine使用了一种声明的方式,可以定义所期望的各种服务的状态,例如,创建了一个应用服务栈:一个Web前端服务、一个后端数据库服务、Web前端服务又依赖于一个消息队列服务。
服务扩容缩容
对于部署的每一个应用服务,可以通过命令行的方式,设置启动多少个Docker容器去运行它。已经部署完成的应用,如果有扩容或缩容的需求,只需要通过命令行指定需要几个Docker容器即可,Swarm集群运行时便能自动地、灵活地进行调整。
协调预期状态与实际状态的一致性
Swarm集群Manager Node会不断地监控集群的状态,协调集群状态使得预期状态和实际状态保持一致。例如启动了一个应用服务,指定服务副本为10,则会启动10个Docker容器去运行,如果某个Worker Node上面运行的2个Docker容器挂掉了,则Swarm Manager会选择集群中其它可用的Worker Node,并创建2个服务副本,使实际运行的Docker容器数仍然保持与预期的10个一致。
多主机网络
可以为待部署应用服务指定一个Overlay网络,当应用服务初始化或者进行更新时,Swarm Manager在给定的Overlay网络中为Docker容器自动地分配IP地址,实际是一个虚拟IP地址(VIP)。
服务发现
Swarm Manager会给集群中每一个服务分配一个唯一的DNS名称,对运行中的Docker容器进行负载均衡。可以通过Swarm内置的DNS Server,查询Swarm集群中运行的Docker容器状态。
负载均衡
在Swarm内部,可以指定如何在各个Node之间分发服务容器(Service Container),实现负载均衡。如果想要使用Swarm集群外部的负载均衡器,可以将服务容器的端口暴露到外部。
安全策略
在Swarm集群内部的Node,强制使用基于TLS的双向认证,并且在单个Node上以及在集群中的Node之间,都进行安全的加密通信。可以选择使用自签名的根证书,或者使用自定义的根CA(Root CA)证书。
滚动更新(Rolling Update)
对于服务需要更新的场景,可以在多个Node上进行增量部署更新,Swarm Manager支持通过使用Docker CLI设置一个delay时间间隔,实现多个服务在多个Node上依次进行部署。这样可以非常灵活地控制,如果有一个服务更新失败,则暂停后面的更新操作,重新回滚到更新之前的版本。
基本架构
Docker Swarm提供了基本的集群能力,能够使多个Docker Engine组合成一个group,提供多容器服务。Swarm使用标准的Docker API,启动容器可以直接使用docker run命令。Swarm更核心的则是关注如何选择一个主机并在其上启动容器,最终运行服务。
Docker Swarm基本架构,如下图所示: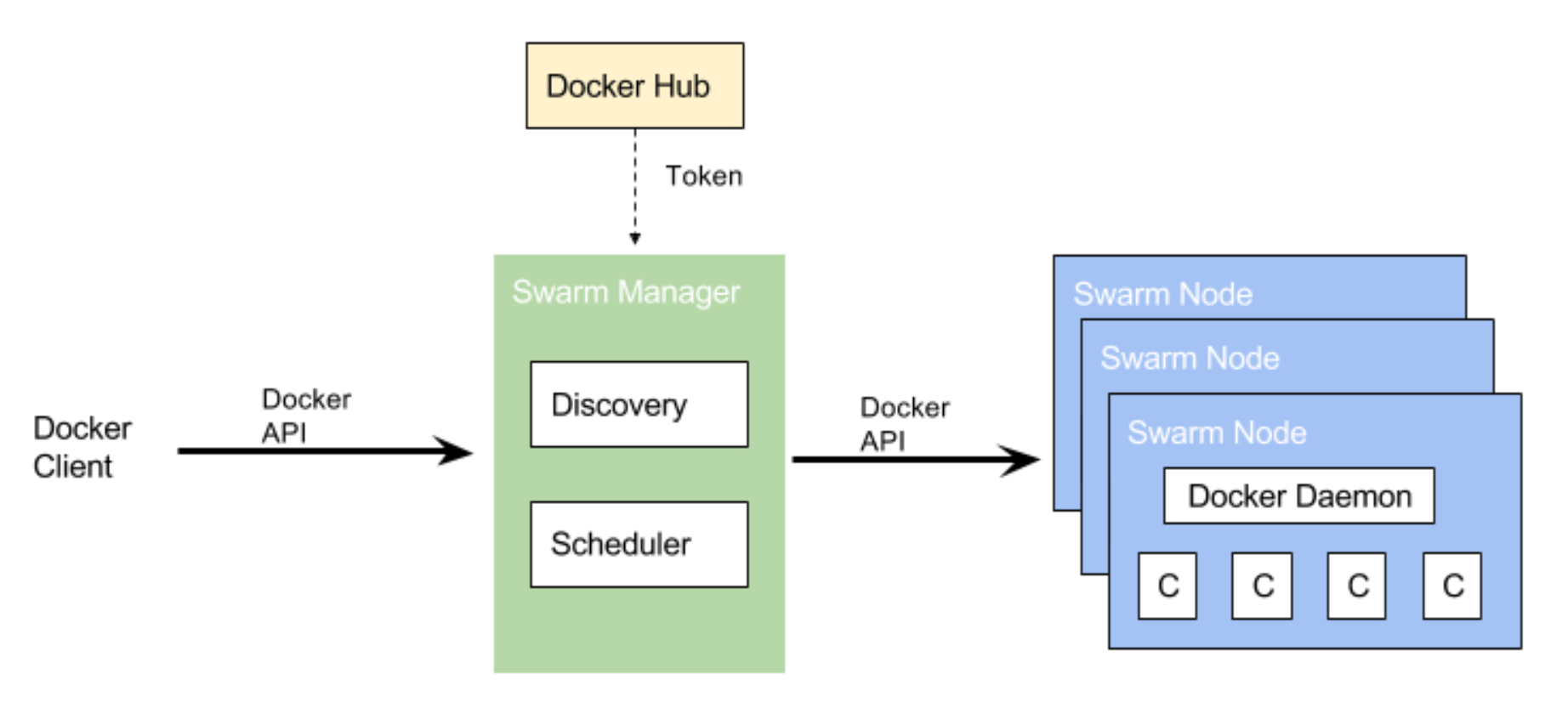
如上图所示,Swarm Node表示加入Swarm集群中的一个Docker Engine实例,基于该Docker Engine可以创建并管理多个Docker容器。其中,最开始创建Swarm集群的时候,Swarm Manager便是集群中的第一个Swarm Node。在所有的Node中,又根据其职能划分为Manager Node和Worker Node,具体分别如下所示:
Manager Node
Manager Node负责调度Task,一个Task表示要在Swarm集群中的某个Node上启动Docker容器,一个或多个Docker容器运行在Swarm集群中的某个Worker Node上。同时,Manager Node还负责编排容器和集群管理功能(或者更准确地说,是具有Manager管理职能的Node),维护集群的状态。需要注意的是,默认情况下,Manager Node也作为一个Worker Node来执行Task。Swarm支持配置Manager只作为一个专用的管理Node,后面会详细说明。
Worker Node
Worker Node接收由Manager Node调度并指派的Task,启动一个Docker容器来运行指定的服务,并且Worker Node需要向Manager Node汇报被指派的Task的执行状态。
构建Swarm集群
实践Swarm集群,包括三个节Node,对应的主机名和IP地址分别如下所示:
manager 192.168.1.107worker1 192.168.1.108worker2 192.168.1.109
首先,需要保证各个Node上,docker daemon进程已经正常启动,如果没有则执行如下命令启动:
systemctl start docker
接下来就可以创建Swarm集群,创建Swarm的命令,格式如下所示:
docker swarm init --advertise-addr <MANAGER-IP>
在准备好的manager Node上,登录到该Node,创建一个Swarm,执行如下命令:
docker swarm init --advertise-addr 192.168.1.107
上面–advertise-addr选项指定Manager Node会publish它的地址为192.168.1.107,后续Worker Node加入到该Swarm集群,必须要能够访问到Manager的该IP地址。可以看到,上述命令执行结果,如下所示:
Swarm initialized: current node (5pe2p4dlxku6z2a6jnvxc4ve6) is now a manager.To add a worker to this swarm, run the following command:docker swarm join \--token SWMTKN-1-4dm09nzp3xic15uebqja69o2552b75pcg7or0g9t2eld9ehqt3-1kb79trnv6fbydvl9vif3fsch \192.168.1.107:2377To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
该结果中给出了后续操作引导信息,告诉我们如何将一个Worker Node加入到Swarm集群中。也可以通过如下命令,来获取该提示信息:
docker swarm join-token worker
在任何时候,如果需要向已经创建的Swarm集群中增加Worker Node,只要新增一个主机(物理机、云主机等都可以),并在其上安装好Docker Engine并启动,然后执行上述docker swarm join命令,就可以加入到Swarm集群中。
这时,也可以查看当前Manager Node的基本信息,执行docker info命令,输出信息中可以看到,包含如下关于Swarm的状态信息:
Swarm: active NodeID: qc42f6myqfpoevfkrzmx08n0rIs Manager: true ClusterID: qi4i0vh7lgb60qxy3mdygb27f Managers: 1Nodes: 1
可以看出,目前Swarm集群只有Manager一个Node,而且状态是active。也可以在Manager Node上执行docker node ls命令查看Node状态,如下所示:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUSqc42f6myqfpoevfkrzmx08n0r * manager Ready Active Leader
接下来,可以根据上面提示信息,分别在worker1、worker2两个Worker Node 上,执行命令将Worker Node加入到Swarm集群中,命令如下所示:
docker swarm join \ --token SWMTKN-1-4dm09nzp3xic15uebqja69o2552b75pcg7or0g9t2eld9ehqt3-1kb79trnv6fbydvl9vif3fsch \192.168.1.107:2377
如果成功,可以看到成功加入Swarm集群的信息。这时,也可以在Manager Node上,查看Swarm集群的信息,示例如下所示:
Swarm: active NodeID: qc42f6myqfpoevfkrzmx08n0rIs Manager: true ClusterID: qi4i0vh7lgb60qxy3mdygb27f Managers: 1Nodes: 3
想要查看Swarm集群中全部Node的详细状态信息,可以执行如下所示命令:
docker node ls
Swarm集群Node的状态信息,如下所示:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUSoibbiiwrgwjkw0ni38ydrfsre worker1 Ready Activeoocli2uzdt2hy6o50g5z6j7dq worker2 Ready Activeqc42f6myqfpoevfkrzmx08n0r * manager Ready Active Leader
上面信息中,AVAILABILITY表示Swarm Scheduler是否可以向集群中的某个Node指派Task,对应有如下三种状态:
- Active:集群中该Node可以被指派Task
- Pause:集群中该Node不可以被指派新的Task,但是其他已经存在的Task保持运行
- Drain:集群中该Node不可以被指派新的Task,Swarm Scheduler停掉已经存在的Task,并将它们调度到可用的Node上
查看某一个Node的状态信息,可以在该Node上执行如下命令:
docker node inspect self
在Manager Node上执行上述命令,查看的状态信息如下所示:
[{"ID": "qc42f6myqfpoevfkrzmx08n0r","Version": {"Index": 9},"CreatedAt": "2017-03-12T15:25:51.725341879Z","UpdatedAt": "2017-03-12T15:25:51.84308356Z","Spec": {"Role": "manager","Availability": "active"},"Description": {"Hostname": "manager","Platform": {"Architecture": "x86_64","OS": "linux"},"Resources": {"NanoCPUs": 1000000000,"MemoryBytes": 1912082432},"Engine": {"EngineVersion": "17.03.0-ce","Plugins": [{"Type": "Network","Name": "bridge"},{"Type": "Network","Name": "host"},{"Type": "Network","Name": "macvlan"},{"Type": "Network","Name": "null"},{"Type": "Network","Name": "overlay"},{"Type": "Volume","Name": "local"}]}},"Status": {"State": "ready","Addr": "127.0.0.1"},"ManagerStatus": {"Leader": true,"Reachability": "reachable","Addr": "192.168.1.107:2377"}}]
管理Swarm Node
Swarm支持设置一组Manager Node,通过支持多Manager Node实现HA。那么这些Manager Node之间的状态的一致性就非常重要了,多Manager Node的Warm集群架构,如下图所示(出自Docker官网):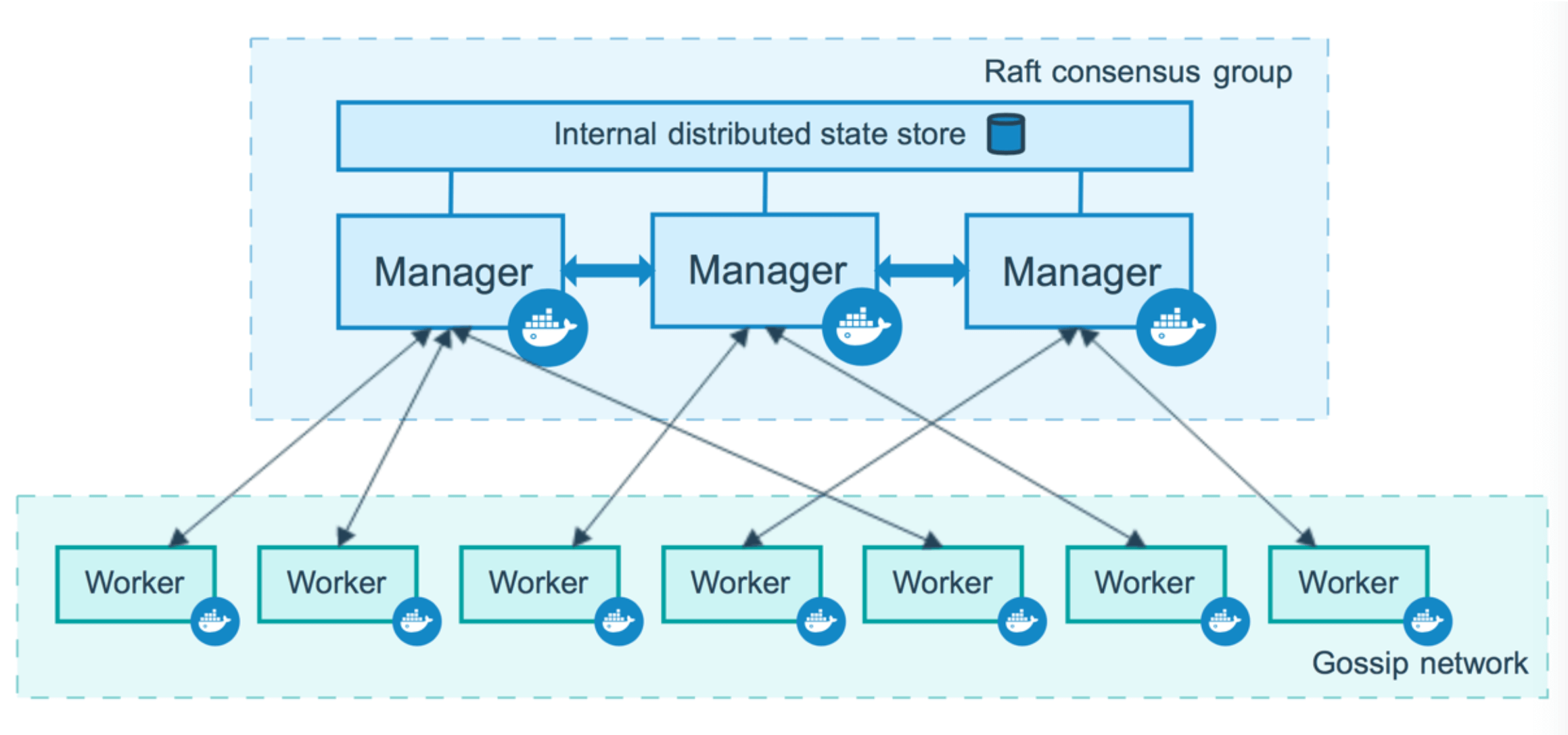
(图源自:https://docs.docker.com/engine/swarm/how-swarm-mode-works/nodes/)
通过上图可以看到,Swarm使用了Raft协议来保证多个Manager之间状态的一致性。基于Raft协议,Manager Node具有一定的容错功能,假设Swarm集群中有个N个Manager Node,那么整个集群可以容忍最多有(N-1)/2个节点失效。如果是一个三Manager Node的Swarm集群,则最多只能容忍一个Manager Node挂掉。
下面,按照对Node的不同操作,通过命令的方式来详细说明:
(1)Node状态变更管理
前面已经提到过,Node的AVAILABILITY有三种状态:Active、Pause、Drain,对某个Node进行变更,可以将其AVAILABILITY值通过Docker CLI修改为对应的状态即可,下面是常见的变更操作:
- 设置Manager Node只具有管理功能
- 对服务进行停机维护,可以修改AVAILABILITY为Drain状态
- 暂停一个Node,然后该Node就不再接收新的Task
- 恢复一个不可用或者暂停的Node
例如,将Manager Node的AVAILABILITY值修改为Drain状态,使其只具备管理功能,执行如下命令:
docker node update --availability drain manager
这样,Manager Node不能被指派Task,也就是不能部署实际的Docker容器来运行服务,而只是作为管理Node的角色。
(2)给Node添加标签元数据
每个Node的主机配置情况可能不同,比如有的适合运行CPU密集型应用,有的适合运行IO密集型应用,Swarm支持给每个Node添加标签元数据,这样可以根据Node的标签,来选择性地调度某个服务部署到期望的一组Node上。
给SWarm集群中的某个Worker Node添加标签,执行如下命令格式如下:
docker node update --label-add 键名称=值例如,worker1主机在名称为bjidc这个数据中心,执行如下命令添加标签:docker node update --label-add datacenter=bjidc
(3)Node提权/降权
改变Node的角色,Worker Node可以变为Manager Node,这样实际Worker Node有工作Node变成了管理Node,对应提权操作,例如将worker1和worker2都升级为Manager Node,执行如下命令:
docker node promote worker1 worker2对上面已提权的worker1和worker2执行降权,需要执行如下命令:docker node demote worker1 worker2
(4)退出Swarm集群
如果Manager想要退出Swarm集群, 在Manager Node上执行如下命令:
docker swarm node leave就可以退出集群,如果集群中还存在其它的Worker Node,还希望Manager退出集群,则加上一个强制选项,命令行如下所示:docker swarm node leave --force同样,如果Worker想要退出Swarm集群,在Worker Node上,执行如下命令:docker swarm node leave
即使Manager已经退出SWarm集群,执行上述命令也可以使得Worker Node退出集群,然后又可以加入到其它新建的Swarm集群中。
管理服务
在Swarm集群上部署服务,必须在Manager Node上进行操作。先说明一下Service、Task、Container(容器)这个三个概念的关系,如下图(出自Docker官网)非常清晰地描述了这个三个概念的含义: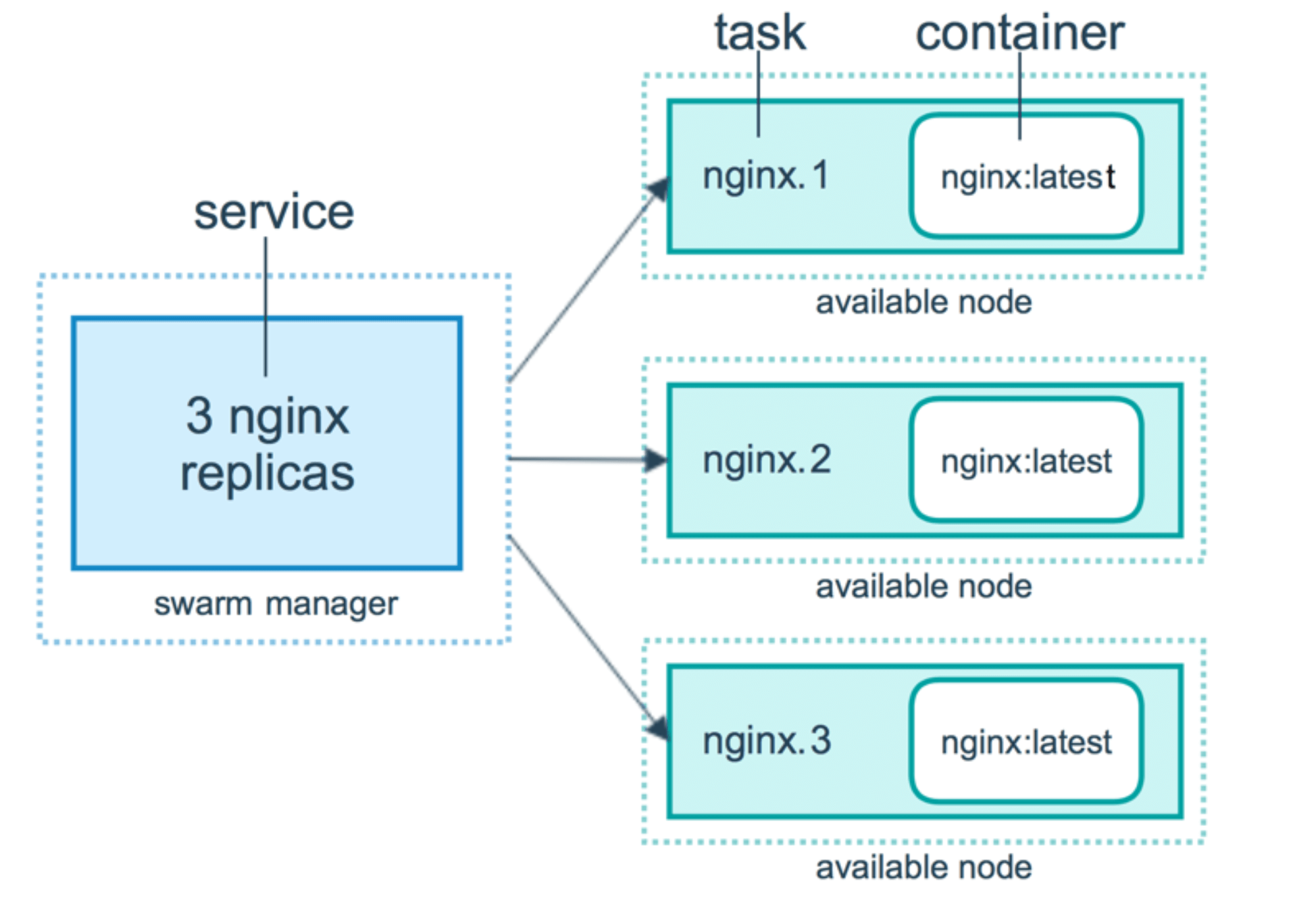
(图源自:https://docs.docker.com/engine/swarm/how-swarm-mode-works/services/)
在Swarm mode下使用Docker,可以实现部署运行服务、服务扩容缩容、删除服务、滚动升级等功能,下面会详细说明。
(1)创建服务
创建Docker服务,可以使用docker service create命令实现,例如,要创建如下两个服务,执行如下命令:
docker service create --replicas 1 --name myapp alpine ping shiyanjun.cndocker service create --replicas 2 --name myredis redis
第一个命令行,从Docker镜像alpine创建了一个名称为myapp的服务,其中指定服务副本数为1,也就是启动一个Docker容器来运行该服务。第二个命令行, 创建一个Redis服务,服务副本数为2,那么会启动两个Docker容器来运行myredis服务。查看当前,已经部署启动的全部应用服务,执行如下命令:
docker service ls
执行结果,如下所示:
ID NAME MODE REPLICAS IMAGEkilpacb9uy4q myapp replicated 1/1 alpine:latestvf1kcgtd5byc myredis replicated 2/2 redis
也可以查询指定服务的详细信息,执行如下命令:
docker service ps myredis
查看结果信息,如下所示:
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS0p3r9zm2uxpl myredis.1 redis manager Running Running 48 seconds ago ty3undmoielo myredis.2 redis worker1 Running Running 44 seconds ago
上面信息中,在manager和worker1这两个Node上部署了myredis这个应用服务,也包含了它们对应的当前状态信息。此时,也可以通过执行docker ps命令,在Manager Node上查看当前启动的Docker容器:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES07f93f82a407 redis:latest "docker-entrypoint..." 7 minutes ago Up 7 minutes 6379/tcp myredis.1.0p3r9zm2uxple5i1e2mqgnl3r
在Worker1上查看当前启动的Docker容器,也就是另一个myredis实例在该Node上:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES41c31e96cccb redis:latest "docker-entrypoint..." 8 minutes ago Up 8 minutes 6379/tcp myredis.2.ty3undmoielo18g7pnvh0nutz
创建服务时,可以对运行时服务容器进行配置,例如如下命令:
docker service create --name helloworld \--env MYVAR=myvalue \--workdir /tmp \--user my_user \alpine ping docker.com
上面,通过 --env 选项来设置环境变量,通过 --workdir 选项来设置工作目录,通过 --user选项来设置用户信息。
(2)扩容缩容服务
Docker Swarm支持服务的扩容缩容,Swarm通过 --mode 选项设置服务类型,提供了两种模式:一种是replicated,可以指定服务Task的个数(也就是需要创建几个冗余副本),这也是Swarm默认使用的服务类型;另一种是global,这样会在Swarm集群的每个Node上都创建一个服务。如下图所示(出自Docker官网),是一个包含replicated和global模式的Swarm集群: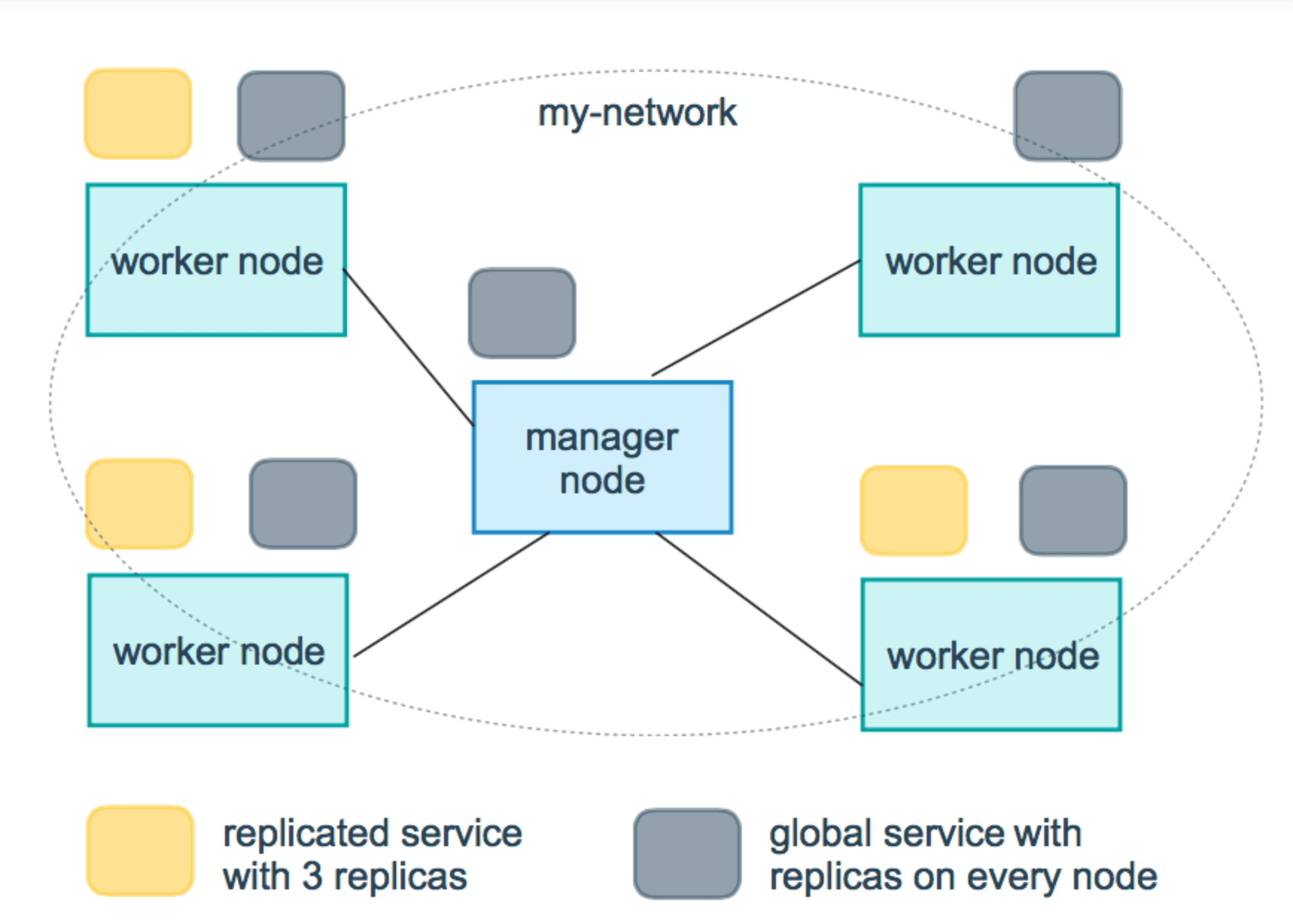
(图源自:https://docs.docker.com/engine/swarm/how-swarm-mode-works/services/)
上图中,黄色表示的replicated模式下的Service Replicas,灰色表示global模式下Service的分布。
服务扩容缩容,在Manager Node上执行命令的格式,如下所示:
docker service scale 服务ID=服务Task总数
例如,将前面部署的2个副本的myredis服务,扩容到3个副本,执行如下命令:
docker service scale myredis=3
通过命令docker service ls 查看,扩容操作结果如下所示:
ID NAME MODE REPLICAS IMAGEkilpacb9uy4q myapp replicated 1/1 alpine:latestvf1kcgtd5byc myredis replicated 3/3 redis
进一步通过docker service ps myredis查看一下myredis的各个副本的状态信息,如下所示:
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERRORPORTS0p3r9zm2uxpl myredis.1 redis manager Running Running 14 minutes ago ty3undmoielo myredis.2 redis worker1 Running Running 14 minutes ago zxsvynsgqmpk myredis.3 redis worker2 Running Running less than a second ago
可以看到,目前3个Node的Swarm集群,每个Node上都有一个myredis应用服务的副本,可见也实现了很好的负载均衡。
缩容服务,只需要将副本数小于当前应用服务拥有的副本数即可实现,大于指定缩容副本数的副本会被删除。
(3)删除服务
删除服务,只需要在Manager Node上执行如下命令即可:
docker service rm 服务ID
例如,删除myredis应用服务,执行docker service rm myredis,则应用服务myredis的全部副本都会被删除。
(4)滚动更新
服务的滚动更新,这里参考官网文档的例子说明。在Manager Node上执行如下命令:
docker service create \ --replicas 3 \--name redis \--update-delay 10s \redis:3.0.6
上面通过指定 --update-delay 选项,表示需要进行更新的服务,每次成功部署一个,延迟10秒钟,然后再更新下一个服务。如果某个服务更新失败,则Swarm的调度器就会暂停本次服务的部署更新。
另外,也可以更新已经部署的服务所在容器中使用的Image的版本,例如执行如下命令:
docker service update --image redis:3.0.7 redis
将Redis服务对应的Image版本有3.0.6更新为3.0.7,同样,如果更新失败,则暂停本次更新。
(5)添加Overlay网络
在Swarm集群中可以使用Overlay网络来连接到一个或多个服务。具体添加Overlay网络,首先,需要创建在Manager Node上创建一个Overlay网络,执行如下命令:
docker network create --driver overlay my-network
创建完Overlay网络my-network以后,Swarm集群中所有的Manager Node都可
以访问该网络。然后,在创建服务的时候,只需要指定使用的网络为已存在
的Overlay网络即可,如下命令所示:
docker service create \ --replicas 3 \--network my-network \--name myweb \nginx
这样,如果Swarm集群中其他Node上的Docker容器也使用my-network这个网络,那么处于该Overlay网络中的所有容器之间,通过网络可以连通。

若有收获,就点个赞吧
0 人点赞
