Center Loss,用以辅助Softmax Loss进行人脸的训练,主要目的是利用softmax loss来分开不同类别,利用center loss来压缩同一类别,最终获取discriminative features.
人脸识别损失函数,扩大类间距离,缩小类内距离。
一、Center Loss
Center Loss为每一个类别提供一个类别中心,最小化min-batch中每个样本与对应类别中心的距离,这样就可以达到缩小类内距离的目的(特征与同类别的平均特征的距离要足够小,这要求同类特征要接近它们的中心点),因此Center loss 能够直接对样本特征之间的距离进行约束。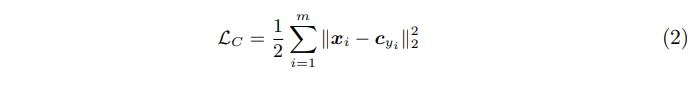
公式解释如下:
其中 表示第i个样本提取到的特征向量(倒数第二个全连接层的输出),C_yi表示样本i所对应的类别的所有样本特征的平均特征,或者说同类样本特征的中心点,m表示mini-batch的大小。因此这个公式就是希望一个batch中的每个样本的feature离feature 的中心的距离的平方和要越小越好,也就是类内距离要越小越好。
表示第i个样本提取到的特征向量(倒数第二个全连接层的输出),C_yi表示样本i所对应的类别的所有样本特征的平均特征,或者说同类样本特征的中心点,m表示mini-batch的大小。因此这个公式就是希望一个batch中的每个样本的feature离feature 的中心的距离的平方和要越小越好,也就是类内距离要越小越好。
Center Loss有一个难点,就是如何计算C_yi。理论上来讲,可以通过所有的样本来为每个类别算一个中心点(即通过计算同一类别所有样本的特征,然后求平均值)。
但是这种方法有以下缺点:
- 我们的训练样本非常庞大;
- 样本统计到的中心点不能代表真正的中心点,这个中心点应该随训练而动态变化(即模型在当前分类能力前提下的中心点)。
因此作者提出使用mini-batch中的每个类别的平均特征来近似不同类别所有样本的平均特征,即在进行类别中心的求导时,只用当前batch中某一类别的图片来获得该类别中心的更新量。即每一个类别中心的变化只用属于这个类别的图片特征来计算。
损失L_c的梯度为公式(3)所示,公式(4)为c_j 梯度公式。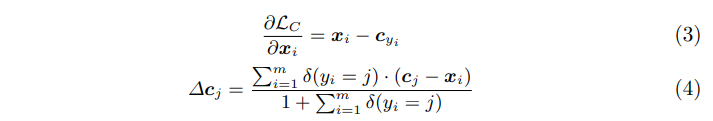
公式解释如下:
m表示mini-batch size,δ(y_i = j)是指示函数,当j是类别类别y_i时,函数返回1,否则返回0,意思就是当y_i(表示y_i类别)和c_j的类别j不一样时,c_j是不需要更新的,只有当y_i和j一样才需要更新。分母的1是防止mini-batch中没有类别j类别的样本而导致分母为0。同时设置了一个c_j的更新速率α,控制c_j的更新速度。
训练是softmax loss结合center loss进行联合训练的,公式如下,loss的权重为lambda,用来控制二者的比重。这里的m表示mini-batch size,n表示类别数。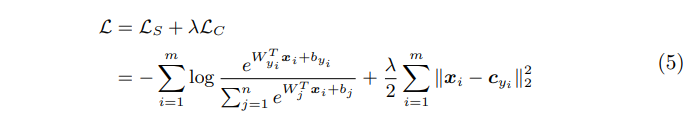
二、算法流程

若有收获,就点个赞吧
0 人点赞
