Transformer 目前在 CV 领域愈演愈烈,这份火热促使着优秀学者们思考一个更深层次的问题。部分学者认为 Transformer 之所以 work 更加本质的原因在于其大的感受野。根据有效感受野(ERF)理论,ERF 大小与 kernel 大小成正比关系,与模型深度的平方根也成正比关系。所以通过堆叠层数实现大感受野必然不如增加卷积 kernel 大小更高效。因此有学者提出超大 kernel 卷积的网络结构,并证明在目标检测和语义分割等任务上超过 Swin Transformer 而且远超传统小卷积模型。
大卷积
CNN 中最常见的卷积 kernel 大小有 2x2, 3x3, 5x5, 7x7 等,在本文中我们将卷积 kernel 大小超过 9x9 的视作大 kernel。
我们不难看出随着卷积 kernel 大小的增加,卷积的参数量和计算量都呈平方增长,这往往也是大家不喜欢用大 kernel 卷积的其中一个原因。为了获得大 kernel 卷积带来的收益的同时降低其计算量和参数量,我们一般将大 kernel 卷积设计成 depthwise 卷积。
如下图所示,depthwise 卷积通过逐通道(channel) 做卷积,可以将计算量和参数量降低到 Dense 卷积的 input channel 分之一。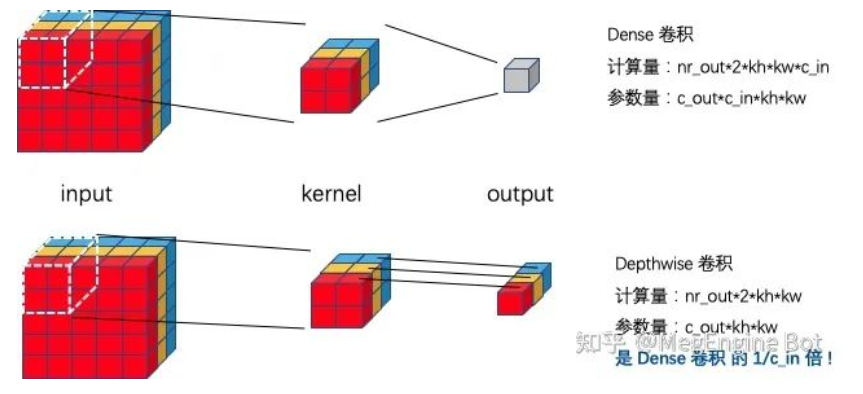
大 kernel depthwise 卷积值得优化的原因
为了解释清楚为什么大 kernel 值得优化这个问题,我们需要借助 Roofline 模型的帮助。如下图所示,Roofline 尝试解释一件非常简单的事情,即模型在特定计算设备下能达到多快的计算速度。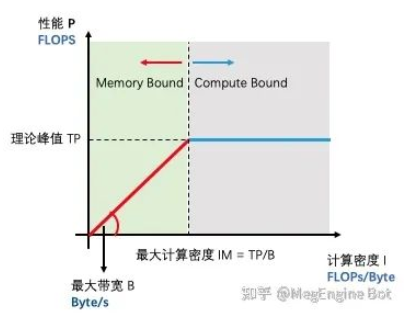
- 理论峰值 TP:描述了计算设备的性能上限,指的是一个计算设备每秒钟最多所能完成的浮点运算数,单位是 FLOPS。
- 最大带宽 B:描述计算设备的带宽上限,指的是一个计算设备每秒最多所能完成的内存交换量,单位是 Byte/s。
- 最大计算密度 IM:描述计算设备单位内存交换最多用来进行多少次运算,单位是 FLOPs/Byte。
“Roofline” 指的是由计算设备理论算力峰值和最大访存带宽这两个参数所决定的“屋顶”形态。其中设备理论峰值决定“屋顶”的高度(蓝色线段),设备最大访存带宽决定了“屋檐”的斜率(红色线段)。Roofline 模型划分出来两个瓶颈区域,分别为 Compute Bound 和 Memory Bound。
当应用的计算密度 I 超过最大计算密度 IM 时,此时无论应用的计算密度多大,它的性能最高只能达到计算设备的理论峰值 TP。此时应用的性能 P 被设备理论峰值限制无法和计算密度 I 成正比,所以叫做 Compute Bound。当应用的计算密度 I 小于最大计算密度 IM 时,此时性能 P 将由设备最大带宽和应用计算密度决定。不难看出对于处在 Memory Bound 区间的应用,增加设备带宽和增加计算密度可以使应用性能达到线性增长的目的。
- 随着 kernel size 的增加计算量会呈平方增长,所以相应的运行时间也会随之增长,这显然是不可接受的。
- depthwise 卷积是一种 Memory Bound 的操作,而随着 kernel size 的增加其计算密度也会增大,所以其运行性能也会随之增大

鉴于以上分析,大 kernel depthwise 卷积有很大的优化潜力,所以 MegEngine 紧跟学界动态对大 kernel depthwise 卷积进行了深度优化。如上图所示,经过我们的优化后,随着 kernel size 的增加,算子性能基本呈现线性增长的趋势,部分情况下算子可以逼近硬件的单精度浮点理论峰值。

若有收获,就点个赞吧
0 人点赞
